当前位置:网站首页>ECCV 2022 | Relational Query-Based Temporal Action Detection Methods
ECCV 2022 | Relational Query-Based Temporal Action Detection Methods
2022-08-03 15:32:00 【I love computer vision】
关注公众号,发现CV技术之美

Hope that through this work encoder-decoder 的框架(如 DETR 类方法),To solve the temporal motion detection(TAD)问题.但是,Direct application of these methods to TAD Task will face three problems:1. decoder 中的 query Relationship modeling inadequate exploration; 2. A limited number of training data classification of lead to inadequate training; 3. When predicting classification score is not reliable.
为了解决这三个问题,We is presented based on the relationship between attention mechanism,Two enhancement and stability classification method to predict the fragment quality score is head losses and training.ReAct 在 THUMOS14 On the performance of advanced,同时,Compared to before the method,With lower computation.This work by the jingdong exploration institute,北京航空航天大学,美团,悉尼大学联合完成,已被 ECCV2022 接收.
01
研究背景
Due to the deep learning age,时序动作检测(TAD)Has become one of the hot research fields.Inspired by the image target detection,One-stage Detection method can in a relatively simple network structure showed excellent 性能.同时,DETR[2]The emergence of class methods,提出了一种基于 Transformer 的 encoder-decoder 框架,The study of the method also attracted a large number of researchers.Our work also reference DETR 的训练范式,Fragments will detect motion modeling into a fixed number of query vector can learn(queries).The query vector as input to the decoder,And through the step by step Cross-attention,Using encoder features updated values.Finally through a simple query vector fully connected network to predict the location of the motion segment and categories.
然而,直接将 DETR Class methods applied to TAD 任务时,会面临几个问题.第一,decoder In the denseself-attention Module has not been fully explore.Compared with image target detection,在 TAD 任务里,Data has a larger variance:The length of each action in the video and quantity differences.Short length for the action、Number of video,需要用到大量的 queries Predict segments of each action;For the amount less action video,Only need less effective queries 来预测,剩余的 queries Will help predict as background information,但在实际中,这部分 queriesIn the presence of more noise pieces(无实际意义,Or no help to predict the fragment,如图 1 所示),Easy to interfere with some actual forecast.第二,Classification learning don't fully.由于视频数据的复杂性,To obtain accurate classification scores more difficult.与部分 Anchor-based/free Method of densely press frame supervision and training in different,DETR Methods every time will only training and Ground-truth Matching motion clips,Is less sample size,So easily lead to inaccurate classification prediction.第三,Inaccurate prediction score.当多个 queries Predict the same fragment,Have a higher classification scoresquery Fragments of forecast more accurate positioning is not necessarily.
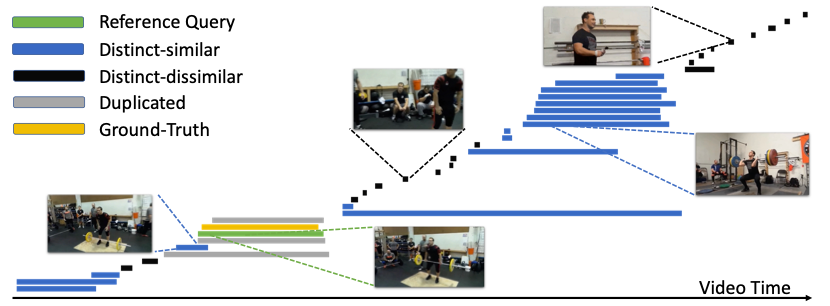
图 1 THUMOS14Test set a videoQueries可视化
针对第一个问题,We put forward a kind of based on the relationship between self-attention 机制.We build the relationship between the three,分别为:Significant similarity relation、Significant similarity relation和重复关系.We have similar or segments of the same kind of action is defined asSignificant similarity relation,Noise or not the same kind of action is defined asSignificant similarity relation,Will point to the same action queries 定义成重复关系.每条 query Will only and has significant similarity relation queries 计算 self-attention,At the same time we also to add an extra IoU Decay 的约束项,The constraint term encourage repeat queriesBe different between each other,To get more diversity of prediction.
对于第二个问题,We put forward two kinds of training to enhance the accuracy of the classification of head loss,分别为 Ace-enc 和ACE-dec 损失.第一个 Ace-enc Loss of application in encoder 之前,We added a single layer of all connection layer characteristics of video projection,And encourage closer to segments of the same kind of action characteristics,Increase the variance of similar clip features of.而ACE-dec Loss of application in decoder 中.We use the predicted fragments and ground-truth Fragment to train classification head,Increasing the training sample and stability classification of training signal.
And for the third question,When we were in the test additional assessment every movement fragment positioning quality score,And get each fragment and classification score combined with the final score.
实验表明,我们的方法在 THUMOS14 On the performance of the most advanced at the same time,Also are lower than the previous methods of calculation.
02
方法
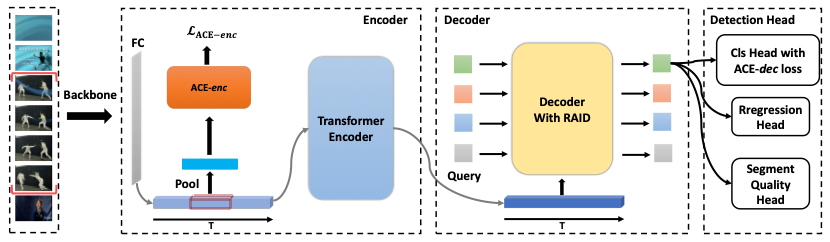
图 2 方法框架图
1、 Attention to theIoU衰减
对于每个query,We through characteristics between similarity and sectionIoUValue of two attributes set to build a relationship.具体来说,我们基于Queries Characteristics of computing a similarity matrix ,这里 是Queries的数量,Each element of the matrix are the twoQueries特征的余弦相似度.We based on threshold Build a significant similarity relation set
同时,我们构建IoU矩阵 ,Each element is twoQueries对应的Segment之间的IoU值.根据阈值 τ ,We build the repeat relationship set
Then the reference section 加入集合,We can build eachQuerySignificant similarity relation set
构建完成后,每个QueryOnly significant similarity relation and its corresponding set of elements to calculateself-attention.
除此以外,In order to prevent the repeat relationship set the number of,We introduced a penalty termIoU Decay,The penalty term punishmentqueryThe corresponding segments betweenIoU值
2、 Classification of action to enhance
In order to solve the problem of insufficient classification learning,We put forward two improve classification performance of the,分别为Ace-enc损失和ACE-dec损失.
对于Ace-enc损失,我们在encoderBefore joining a full connection layer,Projection of input video features are,And use of each movement fragmentRoI PoolingGet fragment features.We for the segment within the data set to collect the other segments of the same category of action as ZhengYang cases,采样kThe segments of different categories of action,Similar or other actions within the fragment length less than a certain threshold of fragments as negative sample,And then we build contrast loss
我们的decoder使用类似deformable DETR[3]的cross-attention方法,This method every layer can be predicted a snippet range,And in section interval sampling a fixed number of points to updatequery特征(如图3左所示).And in order to increase the training sample,对于每个被ground-truth匹配的Query,We are additional to its correspondingground-truth片段(作为新的分支)Into each layerdecoder中,Make it as a reference section interval,And use it to updateQuery,新更新的QueryWill eventually been classified into the head of the training.因此,我们的ACE-dec损失定义为
这里,The classification of the original loss andground-truthLosses we all usefocal loss[4]To calculate the classification loss.
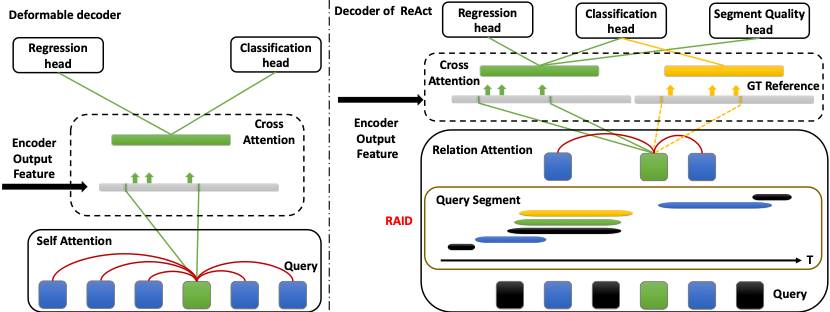
图 3 原始的Deformable decoder结构(左)与ReAct的Decoder结构(右)
3、 Fragments quality prediction
In addition to the return of the original head and classification,We've added a section quality head to estimate the quality of the clips,在实现上,Given a prediction of a segment and its correspondingquery特征 ,我们定义 ,Which is a single full connection layer.而Segment Quality定义为 .在训练时,We use forecast fragment midpoint andground-truthFragment offset and midpoint between themIoUValue to supervise,整体损失定义为
在预测时,We will classification score and the quality ζ 得分相乘,得到每个QueryPredicting fragment final score.
03
实验结果
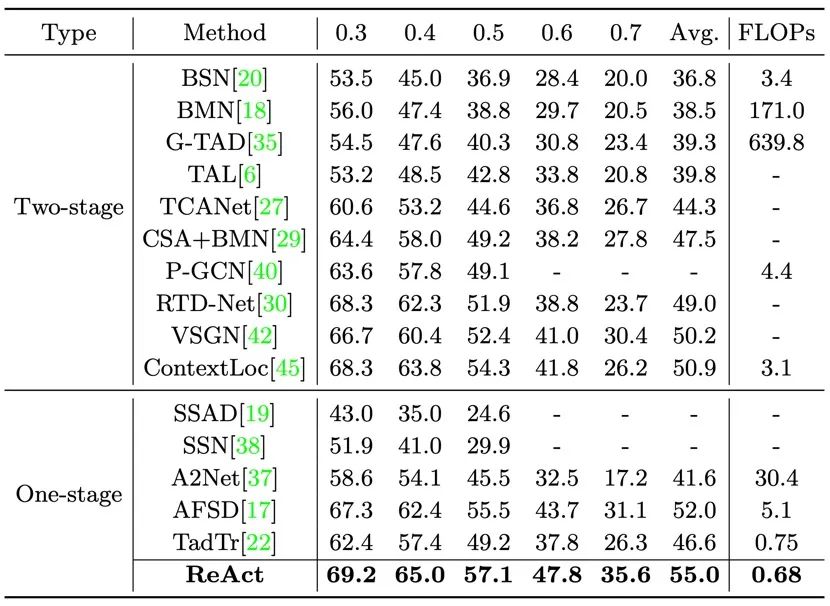
表 1 在THUMOS14数据集上的表现
We use different thresholdmAP,And floating-point computationFLOPs(G)作为评价指标
如表1所示,在THUMOS14上,Our methods in differentmAPOn the threshold is more than the advancedone-stage和two-stage方法,同时,In the test when you have less amount of calculation.
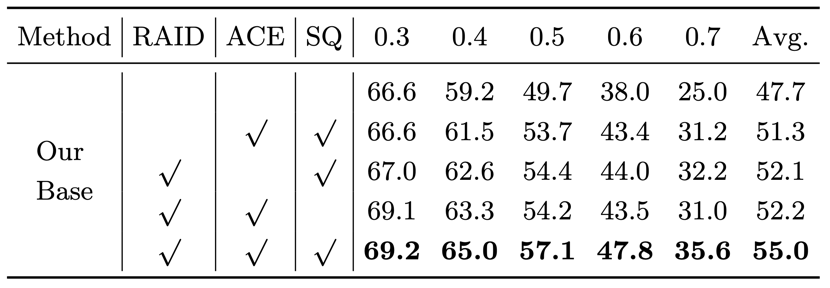
表 2 Different parts of ablation experiment
表2Also by ablation experiments verified the effect of three different parts we.Our attention on the relationship between modules can effectively improve the network performance,And the other two modules also has a good effect.
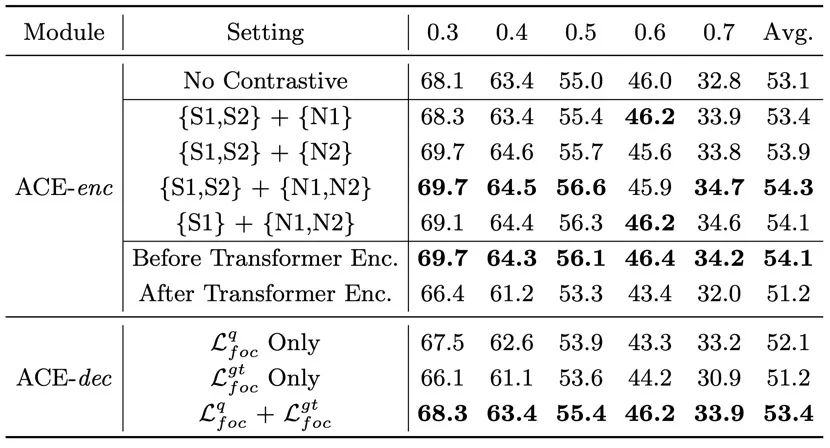
表 3 关于ACE模块的消融实验
而表3也提供了关于ACEModules in the two losses more detailed experimental results,Including the positive and negative selection of the sample,The location of the damage,And the function of the two classification loss.其中值得注意的是,我们发现ACE-encLosses on theTransformer EncoderAfter the performance loss a lot,And in a single connection layer after all,Transformer EncoderBefore there will be a good effect.A more intuitive explanation is that,经过Transformer Encoder后,Each time already contains the characteristics of the positionlocal的信息,因此,poolingThe features can't precisely means the action.除此以外,We found that training only original classification of head loss and onlyground-truthFragments from the classification of head loss has the effect not beautiful,But after will be a combination of training can bring effectively improve.
04
结论
在这个工作中,我们提出了一个基于DETRClass learning paradigm ofTAD框架,And through the three ways to relieve directlyDETRMethods applied toTADThe problem of task,Including attention module based on the relationship between,Classification of action to enhance loss prediction and section quality.我们的方法在THUMOS14上取得了SOTA的性能,At the same time with less computational complexity.We further ablation experiments verified the effectiveness of each method.
论文链接:
https://arxiv.org/abs/2207.07097
代码链接:
https://github.com/sssste/React
参考文献
[1]. Shi, Dingfeng, etal. "ReAct: Temporal Action Detection with Relational Queries." arXive- prints (2022): arXiv-2207.
[2]. Carion, Nicolas, et al. "End-to-end object detection with transformers." European conference on computer vision. Springer, Cham, 2020.
[3]. Zhu, Xizhou, et al. "Deformable DETR: Deformable Transformers for End-to-End Object Detection." International Conference on Learning Representations. 2020.
[4]. Lin, Tsung-Yi, et al. "Focal loss for dense object detection." Proceedings of the IEEE international conference on computer vision. 2017.
本文转自京东探索研究院 .

END
欢迎加入「动作检测」交流群备注:动作

边栏推荐
猜你喜欢



随机推荐
问题7:功能测试花瓶用例
如何用二分法搜索、查找旋转数组中是否含有某个(目标)值? leetcode 81.搜索旋转排序数组
Js array method is summarized
Detailed explanation of cloud hard disk EVS and how to use and avoid pits [HUAWEI CLOUD is simple and far]
5v充8.4v1A电流充电管理ic
一通骚操作,我把SQL执行效率提高了10000000倍!
【FPGA教程案例44】图像案例4——基于FPGA的图像中值滤波verilog实现,通过MATLAB进行辅助验证
简单理解try catch和try finally
问题1:批量测试(正式测试)之前应该怎么做?
文件包含之伪协议的使用
内心的需求
苹果开发「AI 建筑师」GAUDI:根据文本生成超逼真 3D 场景!
php类的析构函数:__destruct
问题4:什么是缺陷?你们公司缺陷的优先级是怎样划分的?
2021年12月电子学会图形化四级编程题解析含答案:新冠疫苗接种系统
JS每晚24:00更新某方法
您的移动端app安全吗
How to play deep paging with hundreds of millions of data?Compatible with MySQL + ES + MongoDB
扫雷?拿来吧你(递归展开+坐标标记)
PWA 应用 Service Worker 缓存的一些可选策略和使用场景