当前位置:网站首页>吴恩达机器学习[11]-机器学习性能评估、机器学习诊断
吴恩达机器学习[11]-机器学习性能评估、机器学习诊断
2022-08-04 15:35:00 【踏归1234】
机器学习性能评估、机器学习诊断
本节学习目标:帮助我们在面对机器学习系统开发或改进机器学习系统性能时,选择接下来该走哪条路
决定下一步做什么
下面继续使用预测房价的学习例子。你可能遇到模型在测试集上的预测效果不好的情况,此时可选择下例五种方法来解决。但如何决定该用哪种方法呢?
接下来的内容,将围绕如何评估机器学习算法的性能、机器学习诊断法(Machine learning diagnostic)展开。
评估假设 Evaluating a hypothesis
学习目标:学习如何评价机器学习算法学习到的假设,涉及到过拟合、欠拟合问题
之前讲过,仅靠假设函数的训练误差小,不能说明它一定是一个好假设。
那么如何判断是否过拟合呢?对于简单的例子,可以通过画出它的假设函数判断;但对于特征不止一个的例子,画图法就用不上了。
下面展示评价假设函数的方法。
将训练集划分为两部分:训练集、测试集(一般按照7:3的比例随机划分)。前者用于训练,后者用于测试假设算法性能。
- 我们以线性回归算法的例子,展示这种方法。

- 然后展示它在逻辑回归算法的运用。
判断假设函数性能方法包括两种。1、计算代价函数 J t e s t ( θ ) J_{test}(\theta) Jtest(θ)。2、错误分类(Misclassification error),又称0/1分类(0/1 Misclassification error)
模型选择和训练、验证、测试集
引入:对于实际问题,我们将如何确定一个数据集最合适的多项式次数、如何选择正确的特征来构造学习算法、以及如何为代价函数选择合适的 λ \lambda λ值呢,这类问题统称为模型选择问题(model selection problems)。对于这类问题,我们需要将数据集划分为训练集、验证集、测试集(train, validation, test sets)。
学习目标:认识训练集、验证集、测试集(train, validation, test sets)、以及如何使用它们进行模型选择。
还是使用过拟合的例子,仅靠假设函数的训练误差小,不能说明它一定是一个好假设。这就是为什么训练误差小,不能用于判断对该样本的拟合好坏,也不能用于判断该假设函数对新样本的泛化能力。

下面回归 模型选择问题。可以建立一系列假设函数,然后分别训练它们,在测试集上计算误差。
然后如何判断模型的泛化能力呢?此时不能再使用测试集了。
- 如果我们用训练集来拟合参数 θ 0 、 θ 1 \theta_0、\theta_1 θ0、θ1等,那么拟合后的模型在训练集上的效果是不能预测出假设函数对于新样本的泛化能力的好坏了。因为这些参数能很好地拟合训练集,因此很有可能在训练集上表现得很好,但对于其他新样本则不然。
- 测试集不能再判断模型泛化能力的原因也是同理。因为我们是对测试集进行拟合,通过拟合测试集得到参数d(选择哪个假设模型)。这意味着假设函数在测试集上的效果,并不能用来公正地估计这个假设对于从未见过的新样本的效果。

为了解决上述模型选择中出现的问题,通常采用如下方法评估假设函数。 - 给定一个数据集,将它划分为三个部分:训练集(train sets)、交叉验证集(或称 验证集 ( validation sets))、测试集(test sets),划分比例一般为6:2:2。
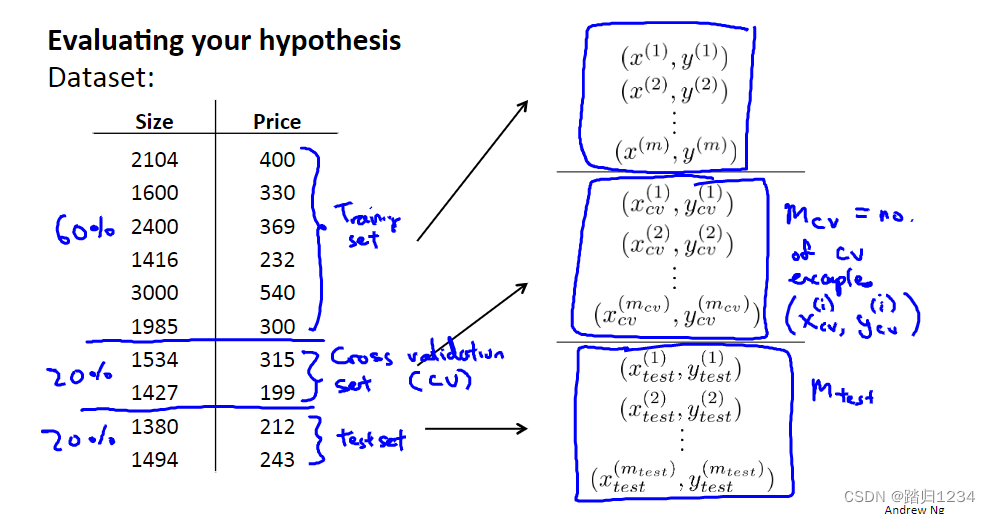
- 相应地,分别定义不同数据集的误差:训练误差、验证误差、测试误差。

- 面对模型选择问题时。
我们使用验证集来选择模型。也就是说,对于每种假设函数,分别训练得到最小代价函数对应的 θ \theta θ值。然后用验证集测试,计算得到 J c v J_{cv} Jcv,来观察这些假设函数在交叉验证集上的效果如何。最后,选择交叉验证误差最小的假设作为我们的模型(也就是选出了合适的多项式次数d)。
此后,使用测试集来估计算法选出的模型的泛化误差。
诊断偏差与方差 Diagnosing bias vs. variance
引入:学习算法表现不理想的原因,一般是偏差比较大(high bias problem)、或方差比较大(high variance problem)。换句话来说,要么是欠拟合、要么是过拟合。此时,找到问题的原因,能帮助找到改进算法效果的有效途径。
学习目标:学会如何观察算法,然后判断问题在于偏差还是方差。
从欠拟合和过拟合图引入。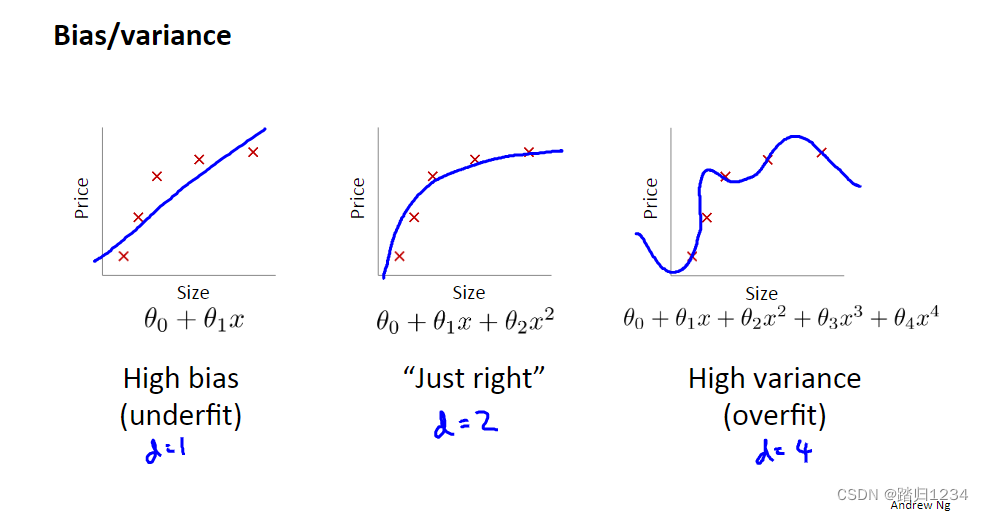
中间大图的玫红曲线 表示训练误差随着d的变化的变化趋势。
中间大图的红线 表示测试误差随着d的变化的变化趋势。交叉验证误差的对应变化趋势类似。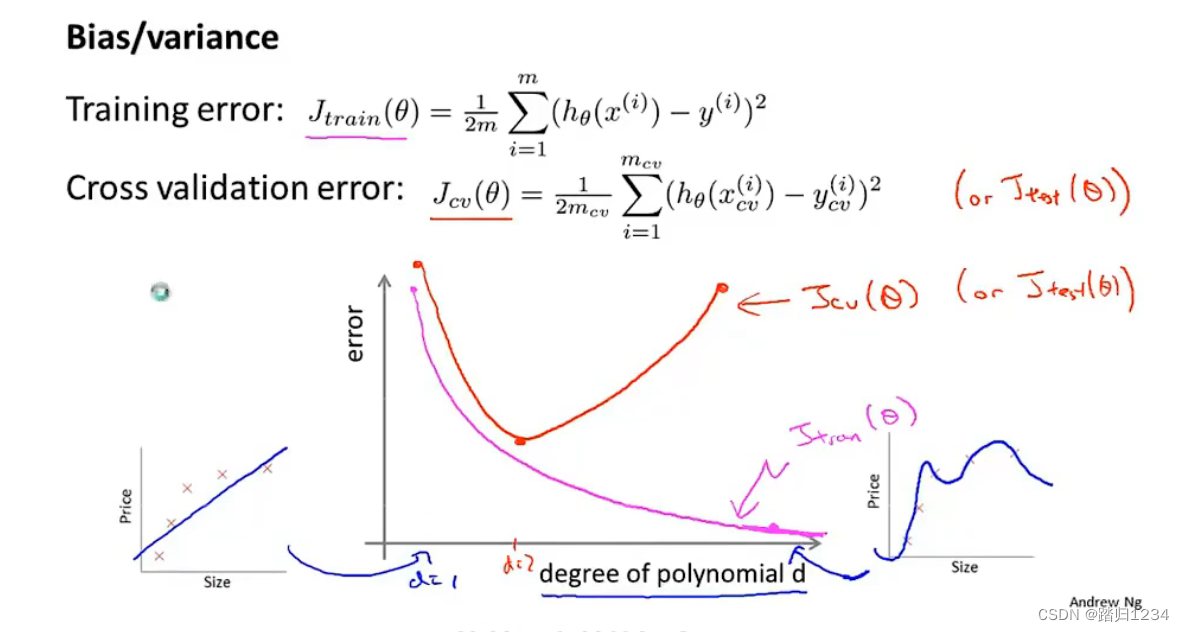
下图能很好展示出高方差和高偏差的区别。漏斗形曲线的左右两侧,分别代表高偏差问题和高方差问题。
- 对于高偏差(Bias)问题,交叉验证误差和训练误差都很大。
- 对于高方差(Variance)问题,交叉验证误差远大于训练误差小。
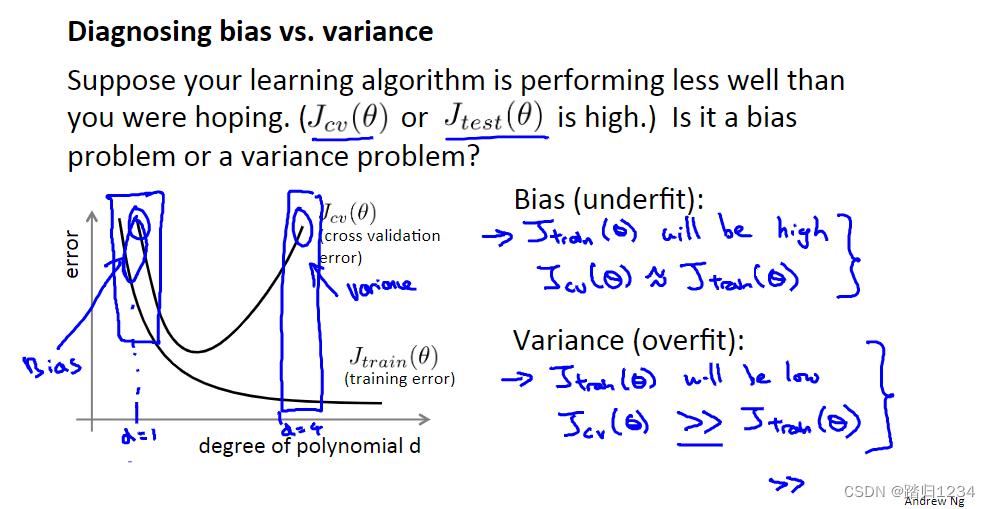
正则化和偏差、方差 Regularization and bias/variance
引入:正则化与方差、偏差直接有什么关系呢?
学习目标:深入讨论偏差、方差的问题,研究它们和算法的正则化之间的关系、以及正则化是如何影响偏差和方差。
下图展示线性回归正则化代价函数,那么如何自动选择出一个最合适的正则化参数 λ \lambda λ的值呢?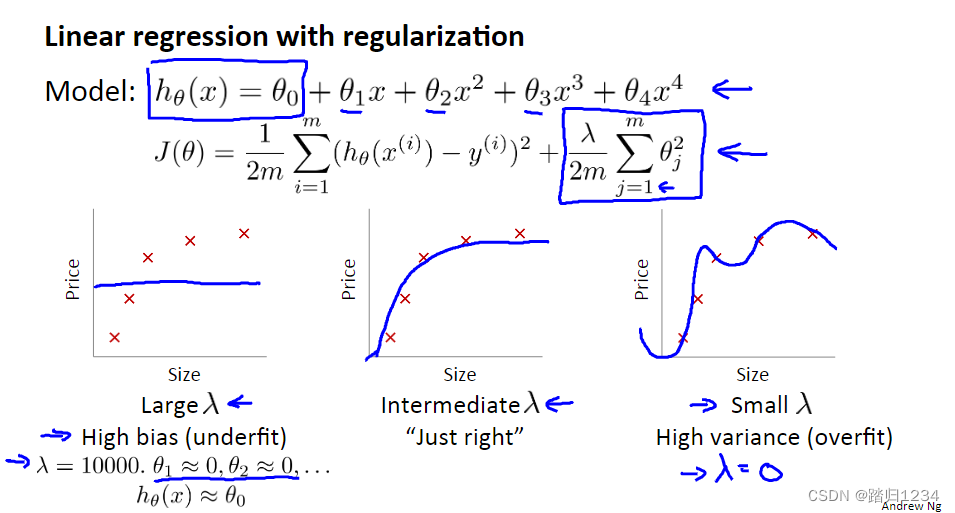
对于假设函数 h θ ( x ) h_\theta(x) hθ(x),定义代价函数 J ( θ ) J(\theta) J(θ)(带正则化项),以及训练集、交叉验证集、测试集的代价函数。
注意:在没有使用正则化时,定义训练集、验证集、测试集的代价函数(误差)等同于 J ( θ ) J(\theta) J(θ)。使用正则化时,定义训练集、验证集、测试集的代价函数等同于 J ( θ ) J(\theta) J(θ)去掉正则化项。
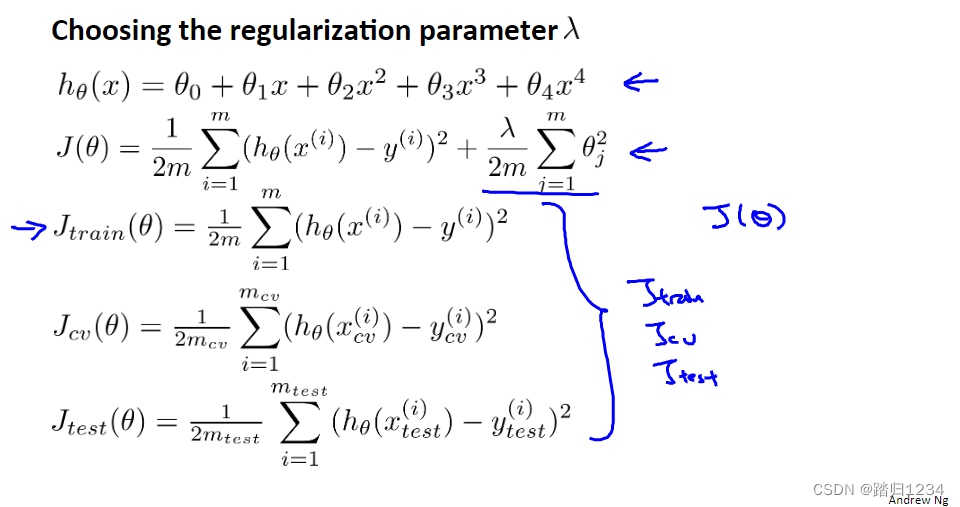
下面展示自动选择 λ \lambda λ步骤。
- 取一系列 λ \lambda λ值。一般首先取 λ \lambda λ为0,然后依次让 λ \lambda λ以两倍速度增长,直到一个比较大的值。
- 分别进行训练,获得代价函数取最小值时的 λ \lambda λ。
- 利用交叉验证集进行评价。分别计算交叉验证集的误差,取误差最小的模型作为最终选择。
- 用选出来 λ \lambda λ对应的 θ \theta θ值,在测试集上测试。观察假设函数在测试集的表现,从而判断模型泛化能力优劣。

那么,改变 λ \lambda λ值时,交叉验证误差和训练误差怎么变化呢? - 对于训练误差。当 λ \lambda λ很小时, J t r a i n ( θ ) J_{train}(\theta) Jtrain(θ)可能很小。但 λ \lambda λ很大时,出现高偏差问题,拟合效果变差, J t r a i n ( θ ) J_{train}(\theta) Jtrain(θ)很大。
- 对于交叉验证误差。当 λ \lambda λ很小时,可能出现过拟合问题, J t r a i n ( θ ) J_{train}(\theta) Jtrain(θ)可能很大。但 λ \lambda λ很大时,出现高偏差问题,拟合效果变差, J t r a i n ( θ ) J_{train}(\theta) Jtrain(θ)很大。会存在一个最小值,此时偏差、误差达到一个平衡点。
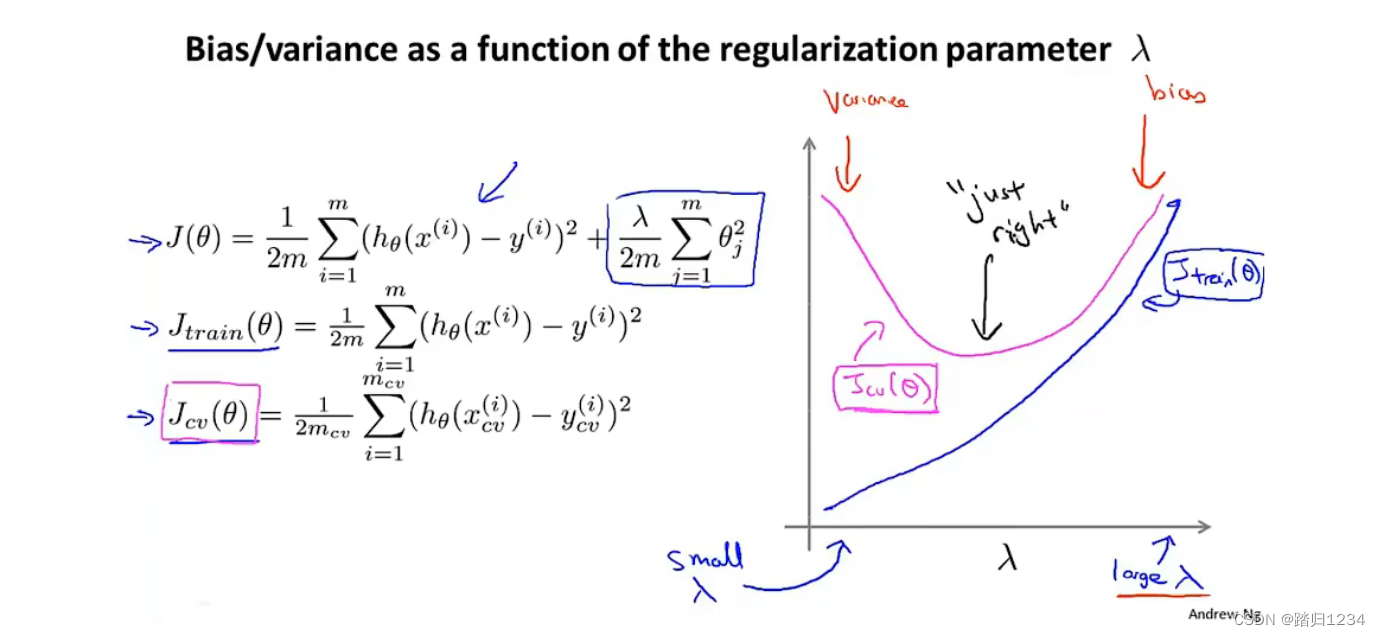
学习曲线 Learning curves
学习目标:结合所学知识,设计出一个方法-学习曲线,从而对学习算法进行诊断。学习曲线能检查学习算法是否正常运行,以及改进算法的表现。检查偏差、方差问题。
学习曲线(learning curve)介绍。
横坐标:训练集样本总数m。纵坐标:训练误差 J t r a i n ( θ ) J_{train}(\theta) Jtrain(θ), 交叉验证误差 J c v ( θ ) J_{cv}(\theta) Jcv(θ)。
- 训练误差变化:m很小时,假设能很好地拟合曲线;m变大,假设拟合效果会可能会慢慢变差。
- 交叉验证误差变化:m很小时,假设的泛化能力差;m越大,假设往往越能获得更好地泛化表现。
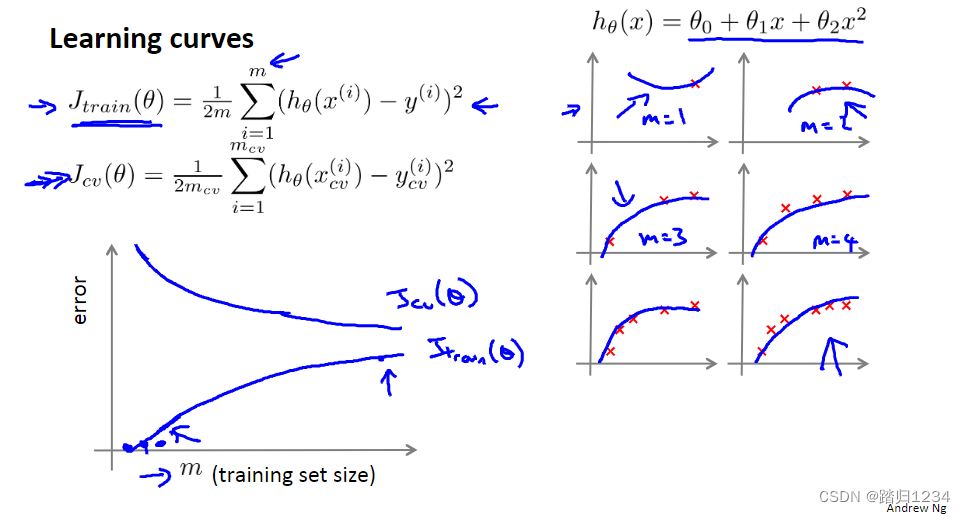
下面展示高偏差、高方差时,学习曲线的效果。
对于高偏差。训练样本数m增加到一定程度时,训练集误差与交叉验证误差会非常接近,且变化趋势近乎直线。 - 训练误差变化:m很小时,假设能很好地拟合曲线。随着m的增加,训练误差会逐渐增加,最后接近交叉验证误差。因为此时假设的参数很少(假设能力有限),又有很多数据,当m很大的时候,训练集和交叉验证集的误差将会非常接近。
- 交叉验证误差变化:m很小时,假设的泛化能力差。m越大,假设往往越能获得更好地泛化表现。当m增加到一定程度时,往往能找到最可能拟合数据的直线。此时,即使再增加m值,验证误差也基本不变。
- 结论:当学习算法存在高偏差问题时,使用更多的训练样本数据对于改善算法表现无益。
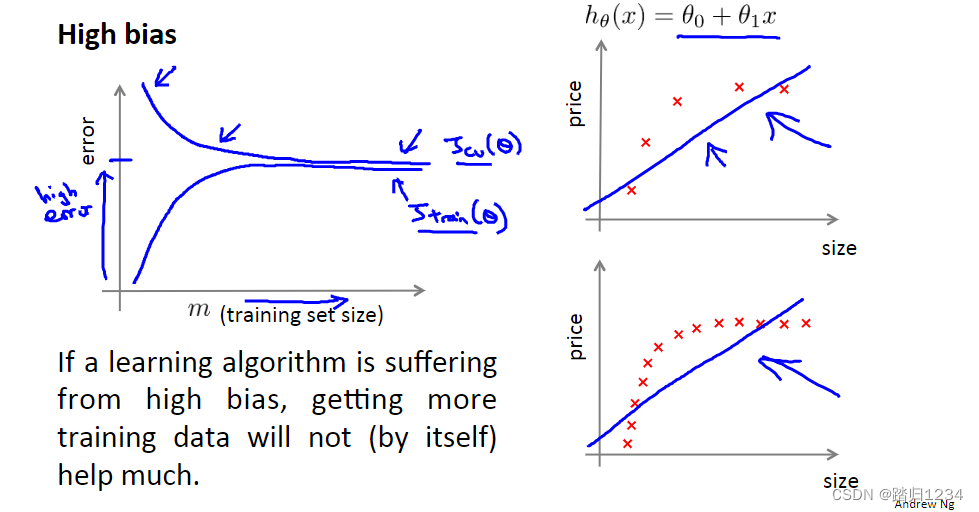
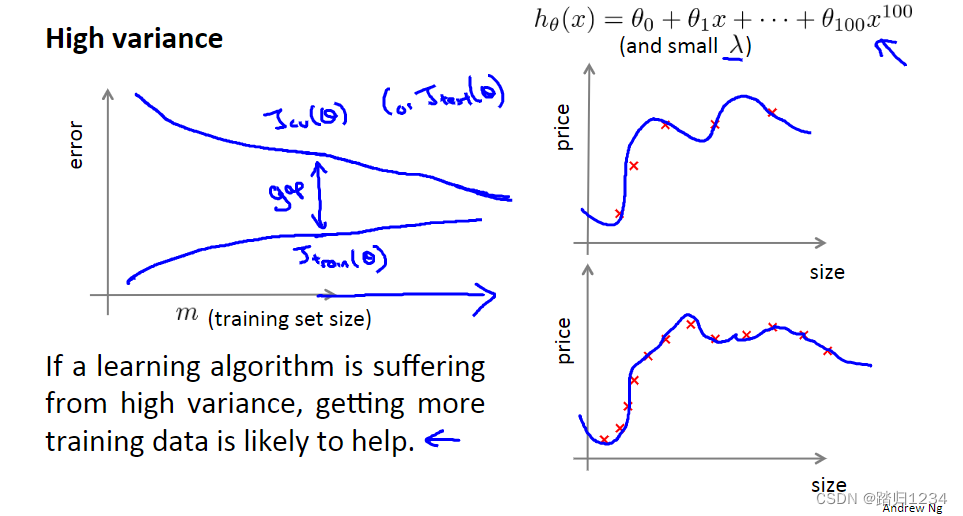
对于高方差。训练样本数m增加,训练集误差与交叉验证误差之间仍存在一段很大的差距。 - 训练误差变化:m很小时,假设能很好地拟合曲线。随着m的增加,可能仍然会有些过拟合,但完全拟合变得更加困难。相应地,训练误差变大,但总体训练集误差还是很小。
- 交叉验证误差变化:因为存在过拟合,因此交叉验证误差一直很大。即使m很小,交叉验证误差也会很大。
- 结论:当学习算法存在高偏差问题时,使用更多的训练样本数据对于改善算法表现有益。
决定接下来做什么 revisited
引入:我们已经学习过了机器学习评价方法、讨论了模型选择以及偏差和方差的问题。那么,这些算法将怎样帮助我们弄清改进方法是否有用呢?
下面回到最初的例子,模型性能不好该怎么办呢。
| 解决方法 | 适用范围 | 识别方法 |
|---|---|---|
| 增加训练样本数 | 高方差问题 | 过拟合。学习曲线中,m很大时 J t r a i n ( θ ) , J c v ( θ ) J_{train}(\theta),J_{cv}(\theta) Jtrain(θ),Jcv(θ)差值很大 |
| 减小特征数 | 高方差问题 | 过拟合。学习曲线中,m很大时 J t r a i n ( θ ) , J c v ( θ ) J_{train}(\theta),J_{cv}(\theta) Jtrain(θ),Jcv(θ)差值很大 |
| 增加特征数 | 高偏差问题 | 欠拟合。学习曲线中,m很大时 J t r a i n ( θ ) , J c v ( θ ) J_{train}(\theta),J_{cv}(\theta) Jtrain(θ),Jcv(θ)接近 |
| 增加多项式 | 高偏差问题 | 欠拟合。学习曲线中,m很大时 J t r a i n ( θ ) , J c v ( θ ) J_{train}(\theta),J_{cv}(\theta) Jtrain(θ),Jcv(θ)接近 |
| 减小 λ \lambda λ | 高偏差问题 | 欠拟合。 |
| 增加 λ \lambda λ | 高方差问题 | 过拟合 。 |

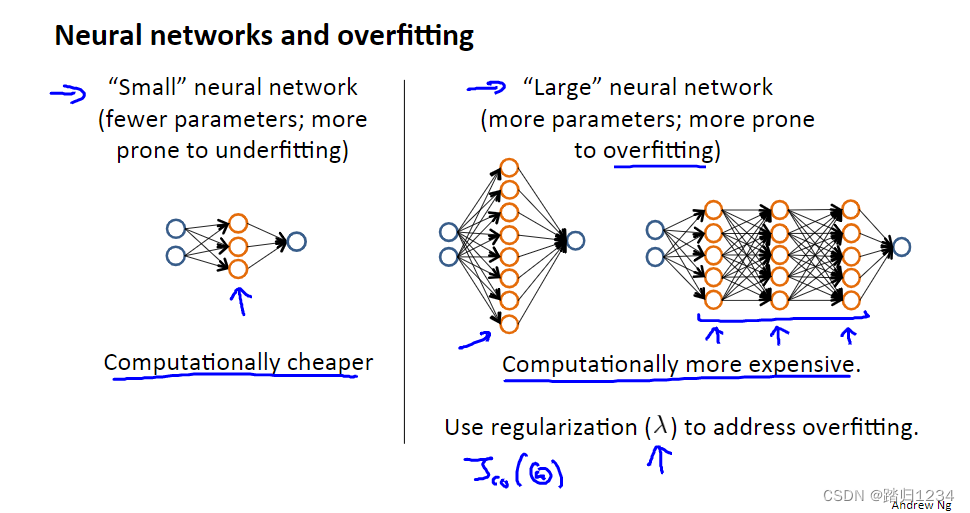
上述知识与神经网络联系如何呢?
| 神经网络特征 | 优势 | 劣势 |
|---|---|---|
| 简单的神经网络模型。隐藏层很少,隐藏单元数少。 | 模型计算量小。 | 此时模型参数不多,容易出现欠拟合 |
| 较大型神经网络。隐藏层单元数很多,或者隐藏层多。 | 模型性能较好,过拟合可以用正则化方法修正。 | 此时模型参数很多,容易出现过拟合(主要潜在问题)。模型计算量很大。 |
一般来说,正则化修正后的大型神经网络,比小型神经网络效果更好。但计算量相对较大。此外,隐藏层层数一般选择1。
边栏推荐
猜你喜欢

"Research Report on the Development of Global Unicorn Enterprises in the First Half of 2022" released - DEMO WORLD World Innovation Summit ended successfully
为什么Redis默认序列化器处理之后的key会带有乱码?
如何防止重复下单?
卖家寄卖流程梳理

#夏日挑战赛# HarmonyOS 实现一个滑块验证

性能提升400倍丨外汇掉期估值计算优化案例
实战:10 种实现延迟任务的方法,附代码!
小程序|炎炎夏日、清爽一夏、头像大换装
不需要服务器,教你仅用30行代码搞定实时健康码识别

Online Excel based on Next.js
随机推荐
有哪些好用的IT资产管理平台?
Taurus.MVC WebAPI 入门开发教程2:添加控制器输出Hello World。
保证通信的机制有哪些
Http-Sumggling缓存漏洞分析
A detailed explanation of what is software deployment
Xi'an Zongheng Information × JNPF: Adapt to the characteristics of Chinese enterprises, fully integrate the cost management and control system
Why, when you added a unique index or create duplicate data?
IP第十八天笔记
全球电子产品需求放缓,三星手机越南工厂每周只需要干 3~4 天
OGG判断mgr状态并自动启动脚本
C# 判断文件编码
FTP协议抓包-工具wireshark与filezilla
Redis-主从复制
附加:自定义注解(参数校验注解);(写的不好,别看…)
基于 Next.js实现在线Excel
图解 SQL,这也太形象了吧!
IP第十五天笔记
从-99打造Sentinel高可用集群限流中间件
爬虫小白笔记(昨天的对于注意解析数据的补充)
RepVGG学习笔记