当前位置:网站首页>27.降维
27.降维
2022-08-04 21:00:00 【WuJiaYFN】
一、降维的两大主要动机
1.1 动机一:数据压缩
降维也是一种无监督学习问题,降维的一个作用是数据压缩
数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快我们的学习算法
具体例子一:从二维降到一维
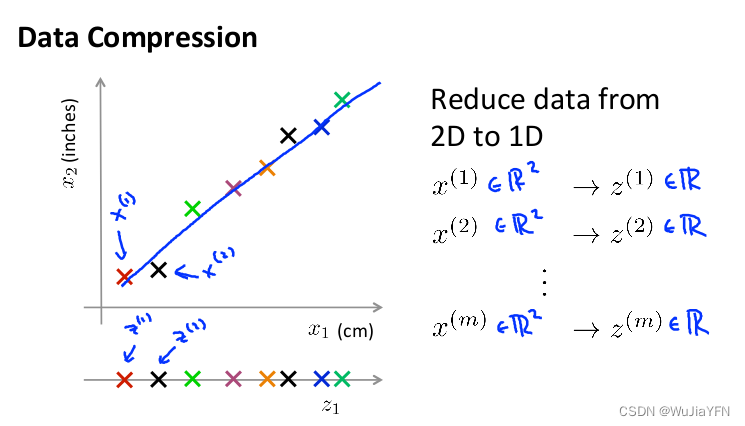
- 假设用两个特征描述同一个物品的长度,x1单位是厘米cm,x2单位是英寸inches。这将导致高度冗余,所以需要减到一维
- 即将二维数据都投影到 Z 直线上变成一维的
具体例子二:从三维降到二维
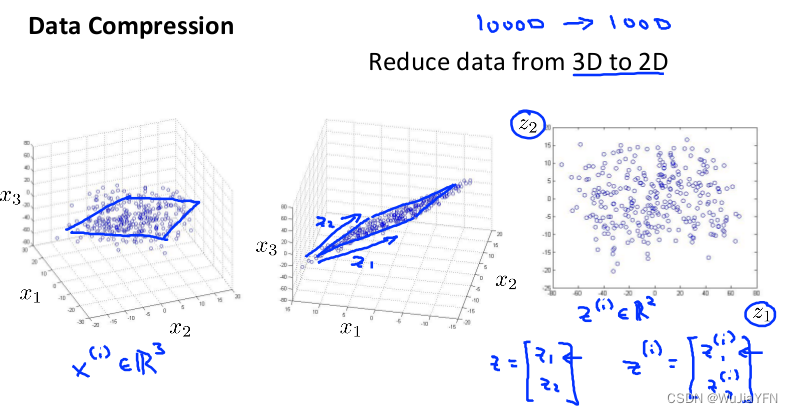
- 将数据从三维降至二维: 将三维向量投射到一个二维的平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量
这样的降维处理数据过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000维的特征降至100维
1.2 动机二:数据可视化
降维可以帮我们将数据可视化,我们便能寻找到一个更好的解决方案
具体例子:
假使有关于许多不同国家的数据,每一个特征向量都有 50 个特征(如 GDP,人均 GDP,平均寿命等)。如果要将这个 50 维的数据可视化是不可能的
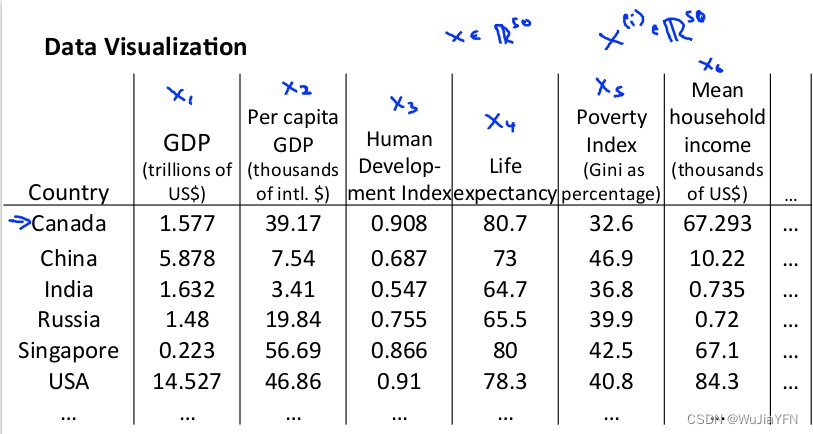
将其降至 2 维,便可将其可视化了
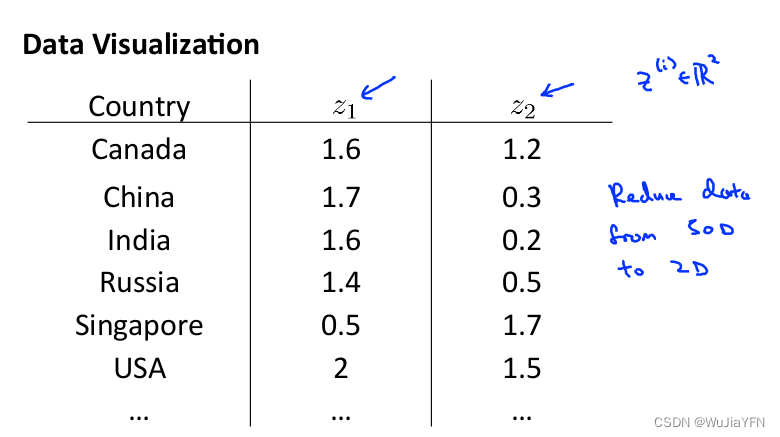
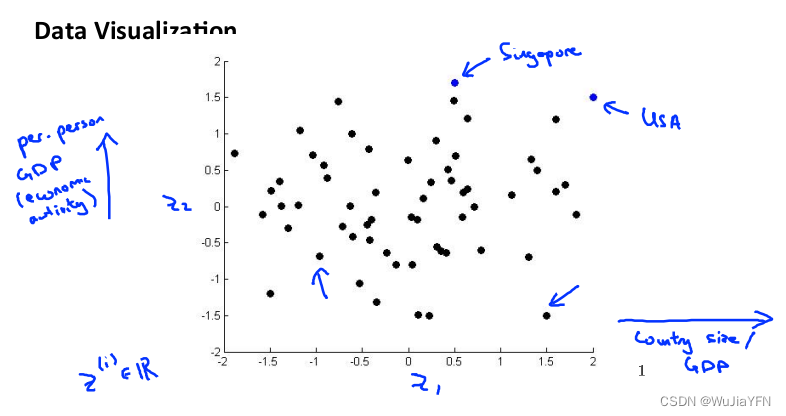
这样做的问题在于,降维算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现
二、主成分分析PCA问题描述
2.1 PCA的介绍
主成分分析(PCA)是最常见且有效的降维算法
PCA将相关性高的变量转变为较少的独立新变量,实现用较少的综合指标分别代表存在于各个变量中的各类信息,既减少高维数据的变量维度,又尽量降低原变量数据包含信息的损失程度,是一种典型的数据降维方法
PCA保留了高维数据最重要的一部分特征,去除了数据集中的噪声和不重要特征,这种方法在承受一定范围内的信息损失的情况下节省了大量时间和资源,是一种应用广泛的数据预处理方法
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小
方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度
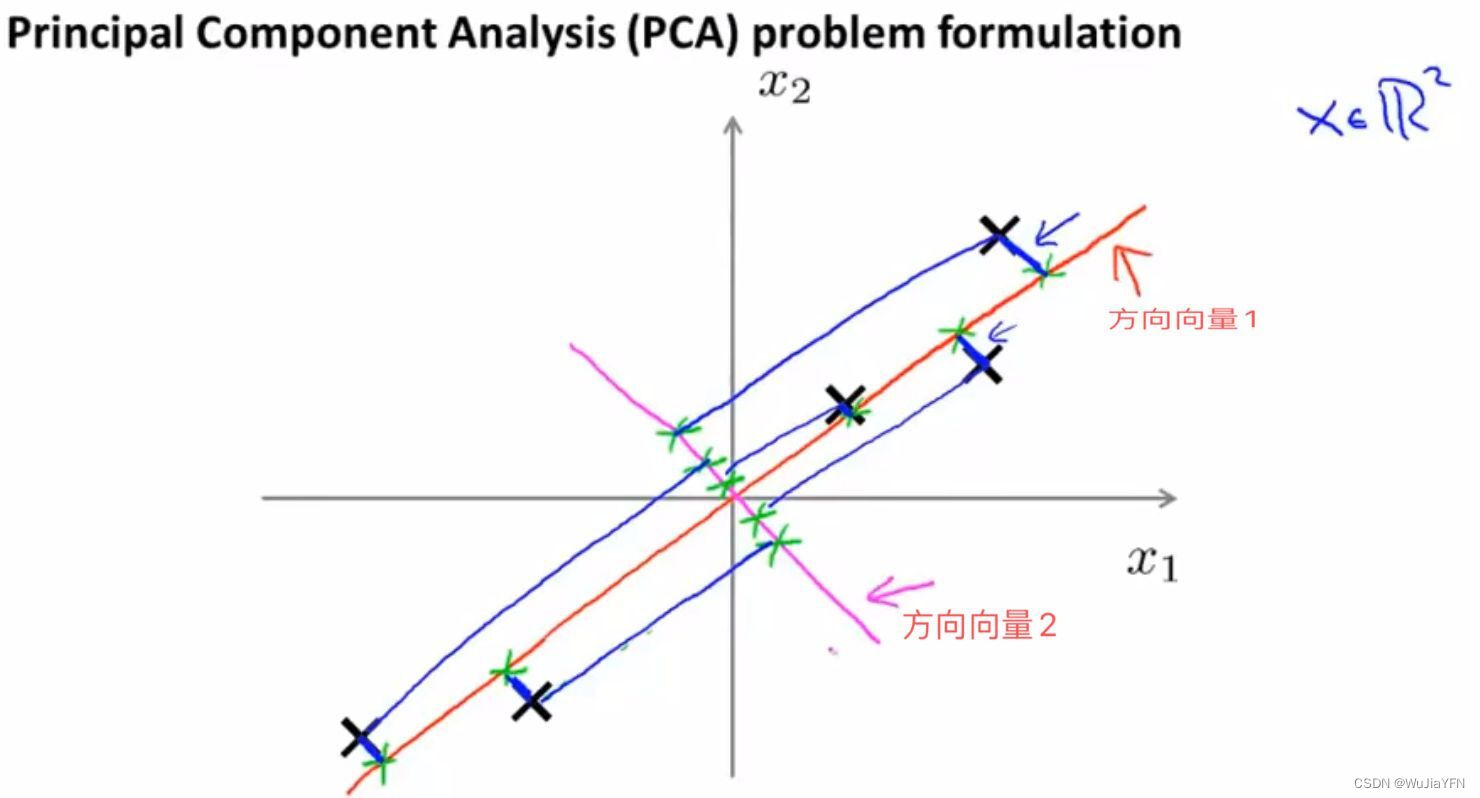
如上图所示,可以由两条方向向量,PCA会选择方向向量1,因为所有数据的投射平均均方误差更小,直观看就图中的蓝线长度更短
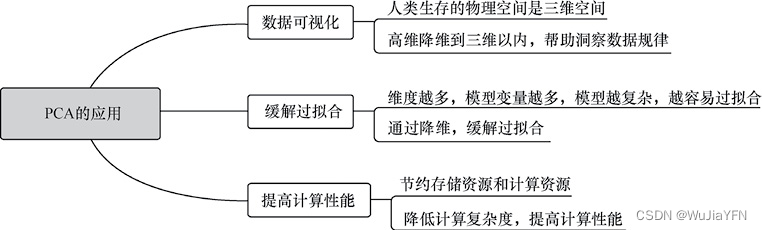
PCA 在数据挖掘和机器学习实践中的主要应用:
2.2 主成分分析问题的描述
- 主成分分析 试图找一个投影(可以是平面可以是线)来把数据投影到上面,使投影误差(点到直线的距离)最小
- 主成分分析降维的同时,也带来一定的误差,即与原始数据相比,数据可靠性降低;看取舍 ;假设常数项为0,直线过原点更容易观察
- 问题是要将 n n n维数据降至 k k k维,目标是找到向量 u ( 1 ) u^{(1)} u(1), u ( 2 ) u^{(2)} u(2),…, u ( k ) u^{(k)} u(k)使得总的投射误差最小
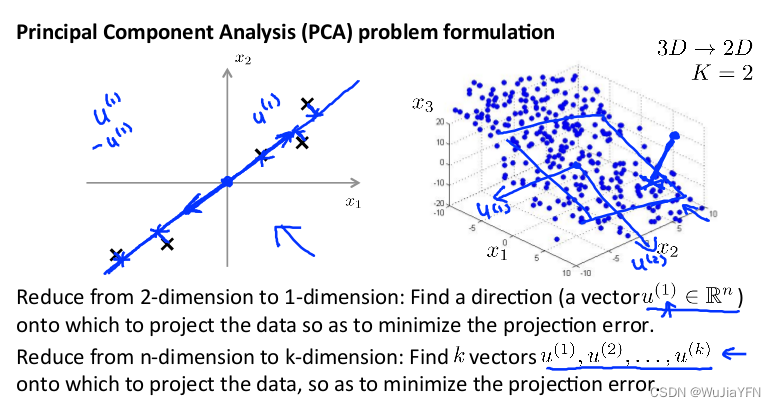
- 若是2维平面,距离就是原3维空间上的点到二维平面的距离
2.3 主成分分析与线性回顾的比较
主成分分析与线性回归是两种不同的算法
主成分分析最小化的是投射误差(Projected Error)
线性回归尝试的是最小化预测误差
线性回归的目的是预测结果,而主成分分析不作任何预测
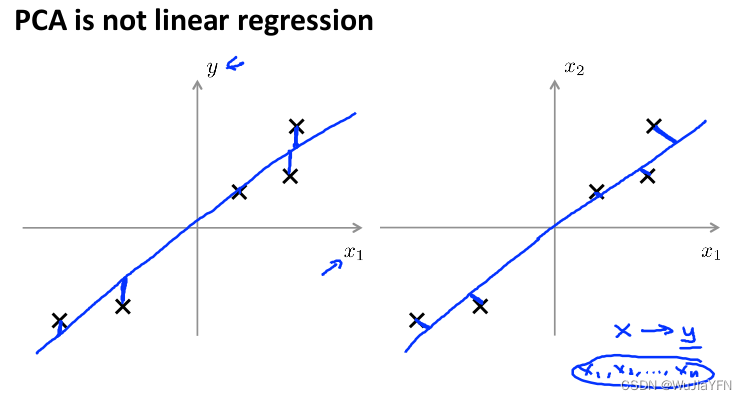
- 上图中,左边的是线性回归的误差(垂直于横轴投影),
- 右边则是主要成分分析的误差(垂直于红线投影)
2.4 PCA的优点分析
- PCA 将n个特征降维到k个,可以用来进行数据压缩,PCA 要保证降维后,还要保证数据的特性损失最小
- PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
- PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的
- 但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高
三、主成分分析算法
PCA 减少 n n n维到 k k k维:
第一步:均值归一化
计算出所有特征的均值,然后令 x j = x j − μ j x_j= x_j-μ_j xj=xj−μj
如果特征是在不同的数量级上,我们还需要将其除以标准差 σ 2 σ^2 σ2

第二步:计算协方差矩阵(covariance matrix) Σ Σ Σ:
∑ = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T \sum=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T} ∑=m1∑i=1n(x(i))(x(i))T
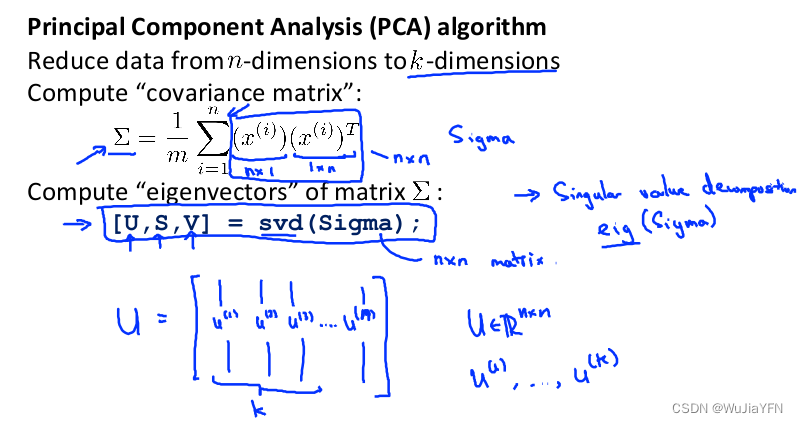
第三步:计算协方差矩阵 Σ Σ Σ的特征向量(eigenvectors):
在 Octave 里我们可以利用奇异值分解来求解,
[U, S, V]= svd(sigma)S i g m a = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T Sigma=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T} Sigma=m1i=1∑n(x(i))(x(i))T
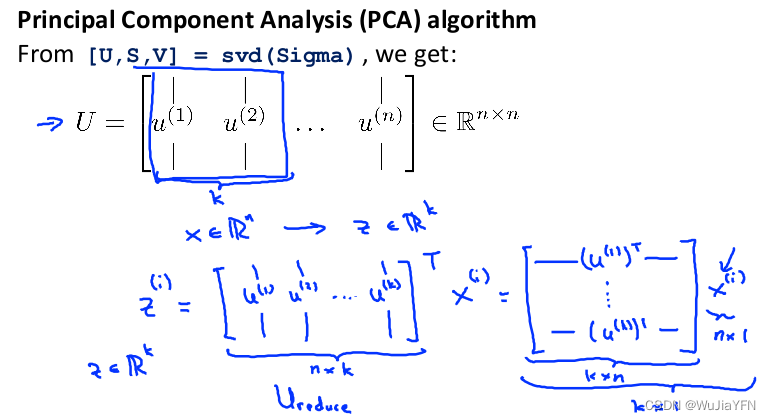
对于一个 n × n n×n n×n维度的矩阵,上式中的** U U U是一个具有与数据之间最小投射误差的方向向量构成的矩阵**
如果我们希望将数据从 n n n维降至 k k k维,我们只需要从 U U U中选取前 k k k个向量,获得一个 n × k n×k n×k维度的矩阵,我们用 U r e d u c e U_{reduce} Ureduce表示,然后通过如下计算获得要求的新特征向量 z ( i ) z^{(i)} z(i): z ( i ) = U r e d u c e T ∗ x ( i ) z^{(i)}=U^{T}_{reduce}*x^{(i)} z(i)=UreduceT∗x(i)
其中 x x x是 n × 1 n×1 n×1维的,因此结果为 k × 1 k×1 k×1维度。注,我们不对方差特征进行处理

四、原始数据的重构方法
在上面的介绍中,我们已经知道了PCA作为压缩算法,由给定压缩后的低维数据$ z^{(i)} 反向得到高维的 反向得到高维的 反向得到高维的 x^{(i)} $数据的过程称为重建原始数据
**具体方法:**我们假设 x x x为2维, z z z为1维, z = U r e d u c e T x z=U^{T}_{reduce}x z=UreduceTx,相反的方程为: x a p p o x = U r e d u c e ⋅ z x_{appox}=U_{reduce}\cdot z xappox=Ureduce⋅z, x a p p o x ≈ x x_{appox}\approx x xappox≈x。如图:
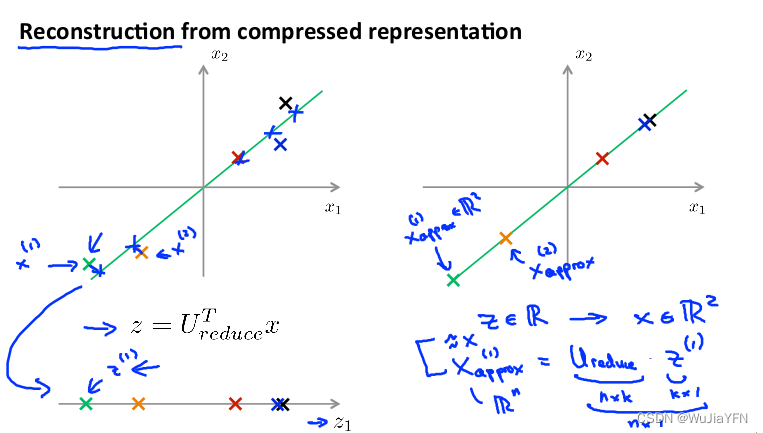
- 对于U矩阵,它是正交矩阵,转置等于逆,所以这里直接 x a p p o x = U r e d u c e ⋅ z x_{appox}=U_{reduce}\cdot z xappox=Ureduce⋅z
- 求出来的 X a p p r o x X_{approx} Xapprox和以前的 X X X会有一定的误差,因为存在投影误差;
五、选择主成分的数量
主要成分分析是减少投射的平均均方误差:
训练集的方差为: 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 \dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{\left( i\right) }\right\| ^{2} m1∑i=1m∥∥x(i)∥∥2
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 k k k值
如果希望比例小于 1%, 就意味着原本数据的偏差有 99% 都保留下来了。 另外,还可以使用5%(对应95%的偏差), 10%(对应90%的偏差) 这些比例
通常95%到99%是最常用的取值范围。(注:对于许多数据集,通常可以在保留大部分差异性的同时大幅降低数据的维度。这是因为大部分现实数据的许多特征变量都是高度相关的)

5.1 选择主成分数量的具体办法:
先令 k = 1,然后进行主要成分分析,获得 U r e d u c e U_{reduce} Ureduce 和 z z z,然后计算比例是否小于1%
如果不是的话,再令k = 2,如此类推,直到找到可以使得比例小于 1%的最小 k k k值

5.2 更好的方式选择K——调用“svd”函数
SVD代表为奇异值分解,函数调用 [U, S, V] = svd(sigma) 返回一个与 Σ(即Sigma) 同大小的对角矩阵 S(由Σ的特征值组成),两个矩阵 U 和 V ,且满足 Σ = U * S * V’。
若 A 为 m×n 矩阵,则 U 为 m×m 矩阵,V 为 n×n 矩阵
奇异值在 S 的对角线上,非负且按降序排列,对角线之外的其它元素都是 0
我们的目的是从 n 维降到 k 维,也就是选出这 n 个特征中最重要的 k 个,也就是选出特征值最大的 k 个
所以得到矩阵 S 后,我们可以直接用它来计算平均均方误差与训练集方差的比例,而不用一遍遍重复计算误差和方差:
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 = 1 − Σ i = 1 k S i i Σ i = 1 m S i i ≤ 1 % \dfrac {\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{\left( i\right) }-x^{\left( i\right) }_{approx}\right\| ^{2}}{\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{(i)}\right\| ^{2}}=1-\dfrac {\Sigma^{k}_{i=1}S_{ii}}{\Sigma^{m}_{i=1}S_{ii}}\leq 1\% m1∑i=1m∥∥x(i)∥∥2m1∑i=1m∥∥x(i)−xapprox(i)∥∥2=1−Σi=1mSiiΣi=1kSii≤1%
也就是: Σ i = 1 k s i i Σ i = 1 n s i i ≥ 0.99 \frac {\Sigma^{k}_{i=1}s_{ii}}{\Sigma^{n}_{i=1}s_{ii}}\geq0.99 Σi=1nsiiΣi=1ksii≥0.99
六、主成分分析法的应用建议
6.1 PCA具体使用例子
- 假使我们正在针对一张 100×100 像素的图片进行某个计算机视觉的机器学习,即总共有 10000 个特征。使用 PCA 算法的步骤如下:
运用 PCA 将数据压缩至 1000 个特征
对训练集运行学习算法
在预测时,采用之前学习得到的 Ureduce 将输入的特征 x 转换成特征向量 z ,然后再进行预测

- 注:如果我们有交叉验证集合测试集,也采用对训练集学习而来的 U r e d u c e U_{reduce} Ureduce
6.2 正确的主要成分分析PCA情况
- 压缩和可视化:

6.3 错误的主要成分分析PCA情况
错误使用PCA情况之一:将其用于减少过拟合(减少了特征的数量
这样做非常不好,不如使用正则化处理。原因在于 PCA 只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征
而当进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。

错误使用PCA情况之二:默认地将主要成分分析作为学习过程中的一部分
- 导致算法运行太慢或者占用太多内存

6.4 建议
不要一开始就使用PCA,最好先使用原始数据,只有当原始数据进行不下去了才考虑PCA
与其考虑降低维度,不如想想如何优化算法;
边栏推荐
猜你喜欢
![[TypeScript] In-depth study of TypeScript enumeration](/img/27/4836e59528bb5a51ffc1cf9961c6b6.png)
[TypeScript] In-depth study of TypeScript enumeration
【一起学Rust | 进阶篇 | Service Manager库】Rust专用跨平台服务管理库
Zero-knowledge proof - zkSNARK proof system

如何用好建造者模式
Tear down the underlying mechanism of the five JOINs of SparkSQL

面试官:索引为什么会失效?

经验分享|盘点企业进行知识管理时的困惑类型
LINQ to SQL (Group By/Having/Count/Sum/Min/Max/Avg操作符)
js数据类型、节流/防抖、点击事件委派优化、过渡动画
帝国CMS仿核弹头H5小游戏模板/92game帝国CMS内核仿游戏网整站源码

随机推荐
帝国CMS仿核弹头H5小游戏模板/92game帝国CMS内核仿游戏网整站源码
链队
三种方式设置特定设备UWP XAML view
c语言小项目(三子棋游戏实现)
推荐系统_刘老师
uwp ScrollViewer content out of panel when set the long width
【PCBA方案设计】握力计方案
ts集成和使用
【编程思想】
深度解析:为什么跨链桥又双叒出事了?
[AGC] Build Service 1 - Cloud Function Example
二叉搜索树解决硬木问题
vs Code runs a local web server
3、IO流之字节流和字符流
Configure laravel queue method using fort app manager
jekyll adds a flowchart to the blog
[2022 Hangzhou Electric Power Multi-School 5 1012 Questions Buy Figurines] Application of STL
无代码平台字段设置:基础设置入门教程
Common methods of js's new Function()
【数据挖掘】搜狐公司数据挖掘工程师笔试题