当前位置:网站首页>New work of "the father of LSTM": a new method towards self correcting neural network
New work of "the father of LSTM": a new method towards self correcting neural network
2022-06-11 18:14:00 【Data realist】

The process of neural network includes its weight matrix (Weight Matrix:WM) Update .
Once the network training is over , The weight matrix will be permanently fixed , Then the effectiveness of the network is evaluated according to the generalization results of the network on the test data . However , Many environments will continue to evolve after training , The test data may deviate from the training , Beyond the generalization ability of neural networks .
This requires human intervention , To retrain or adjust the model . contrary , A fully autonomous system should learn to operate without intervention , Update your program based on new experience . Especially in multitasking (Multi-task learning) And meta learning (Meta-learning, Learn how to learn ) in , It is important to learn how to keep the model updated and fine tuned , This can help the network quickly adapt to various situations and new challenges .
stay A Modern Self-Referential Weight Matrix That Learns to Modify Itself In this study ,“LSTM The father of ”Jürgen Schmidhuber Et al. Based on modern techniques for updating and generating weights , Reexamine 90 Self correcting weight matrix proposed since s (self-referential WM), Especially the use of Fast Weight Programmers(FWPs) Mechanisms established in the context of , A new self - correcting weight matrix is derived (self-referential WM:SRWM).
This study has made a study of SRWM To assess the :
First , The model achieves competitive performance in standard small sample learning , It is proved that the proposed model can effectively generate useful self correction ;
secondly , By extending the small sample learning setup to the continuous multi task learning setup , Tested SRWM The ability to adapt to real-time changes in tasks at runtime ;
Last , stay ProcGen Multi task reinforcement learning of game environment settings (RL) It was evaluated in the environment , This includes the programmatically generated game environment . in general , The practical applicability and strong performance of the proposed method are proved .
New self correcting weight matrix
A new self - correcting weight matrix is proposed in this paper (SRWM) With the recently proposed FWPs Variants are similar , By learning the keys you invented / It's worth it “ Training ” Pattern and learning rate for self training , Call is based on outer product (outer products) and delta Basic programming instructions for function update rules .
The specific steps are as follows :
Given t Time input xt∈Rdin, In this paper, the SRWM Wt−1∈R(dout+2*din+1)×din Four variables will be generated [yt,qt,kt,βt].
among ,yt∈Rdout Is the output of this layer in the current time step ,qt∈Rdin and kt∈Rdin Are query vectors and key vectors ,βt∈R It's based on delta The self created learning rate used by the function . And 90 The original idea put forward in the s SRWM The terms introduced in this paper are similar to ,kt∈Rdin Is the correction key vector , Represents the bond vector , Its current value is SRWM Must be corrected ;qt∈Rdin It's a query vector , It is fed again SRWM, To retrieve a new “ value ” vector , And associated with the correction key vector .
The overall dynamics can be simply expressed as follows :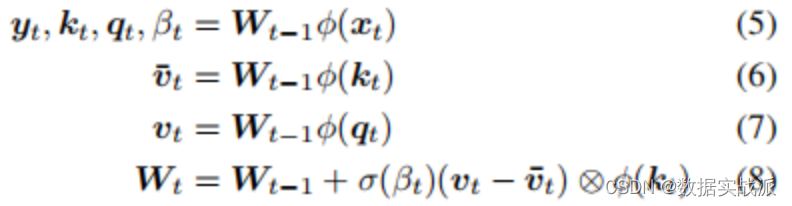
among , The value vector has dimensions :vt ,∈R(dout+2*din+1). Model diagram 1 Shown .

chart 1 One “ modern ” Self reference weight matrix (SRWM)
It is important to ,SRWM in W0 The initial value of is the only parameter in this layer that needs gradient descent training .
In practice , In this paper, the output dimension of matrix is changed from “3D+1”(dout+2din+1) Extended to “3D+4”(dout+2din+4) To generate 4 Different 、 Self invented time-varying learning rate βt∈R4, For formula (8) Medium Wt−1=[Wyt−1,Wqt−1,Wtk−1,Wβt−1] The calculation of four submatrixes of , Then it is used to generate (5) Medium yt, qt, kt and β. In order to improve the calculation efficiency , This article also makes use of the common Transformers Multi head calculation in the model .
Aforementioned SRWM It can be used to replace any conventional weight matrix . This article focuses on a model , It can be done by using the corresponding SRWM The formula in (5)-(8) Replace the benchmark model DeltaNet The formula in (1)-(4) And get .
experimental result
The overall objective of the experiment is to evaluate the proposed SRWM In all kinds of needs “ good ” Performance on self modifying tasks , So a small sample of standard supervision (few-shot) Learning task and multi task reinforcement learning in the game environment .
1. Standard small sample (Few-Shot) Study
The small sample image classification task is also called inclusion based C Class data set N-way K-shot Image classification task , It is organized through so-called scenarios .
In every scene , from C Class N Different classes , The resulting N Class is relabeled , take N One of the different random tag indexes is assigned to each class . For this N Each of these classes , Random sampling K Samples . From this N×K A set of tag images is called a support set . The goal of this task is based on the information available in the support set , Forecast from N Another image sampled in one of the classes ( The query image in the set is not supported ) The label of .
Although there are several ways to solve this problem , However, this paper uses the sequential learning method to evaluate the SRWM. in other words , Images that will support the set / Random sorting of tag pairs , Form a neural network by sequence processing ( for example , Cyclic neural network ) Read sequence . The corresponding neural network predicts the label of the query image by encoding the support set information into its internal state . In this paper SRWM in , The model generates its own update weights when reading the sequences that support set items , The generated weights are used to calculate the final prediction of the query image . To illustrate this method in detail , You also need to explain how the input image / Label pairs are input into the model .
Here, this paper adopts Mishra The method used by et al , It's called graph 2 Synchronization label settings shown in , This is for N-way K-shot Learn design strategies . That is, it supports centralized N×K A project , At the same time, the input and its label are transmitted to the model . This model only predicts the (N×K+1) Input tags , That is, query images without labels . Another method is called delay label setting ( Pictured 3 Shown ).
in fact , because Mishra Et al SNAIL The model is similar to transformer Model of ( The regular feedforward block is replaced by one-dimensional convolution ), Therefore, it is used as the benchmark model of this experiment , Also introduced in the benchmark model Oreshkin Et al TADAM Method .
However , This paper notes that ,TADAM It is a method specially designed for small sample learning , With the model and SNAIL Dissimilarity ,SNAIL It is a general sequence processing neural network which is suitable for small sample learning .

chart 2 N-way K-shot Sync tab settings for learning . Correct label with front N×K Mark the corresponding input together as input . Only for the second (NK+1) Prediction of tags without tag input .
chart 3 Delay label setting . The correct label is entered in the next step after the corresponding input . Make predictions at each step .
The final performance is directly affected by the selection of visual feature extractors , The visual feature extractor uses the visual model to transform the input image into a compact feature vector , It is then provided to the sequence processing module .
ad locum , This paper shows the results of using two popular feature extractors on these benchmark models :Conv-4 and Res-12. Results such as table 1 Shown .
Overall speaking , The proposed SRWM Good performance . take SRWM With general SNAIL Model comparison ,SRWM stay Mini-ImageNet2 It is independent of the visual backend (Conv-4 or Res12) Competitive performance .
DeltaNet and SRWM With similar performance . This is a satisfactory result , Because it shows a single self correcting WM( Instead of a separate slow and fast network ) Still competitive in this single task scenario .

surface 1 stay Omniglot、Mini-ImageNet and FC100 Upper use Conv4 or Res-12 The visual feature extractor performs a single task 、 5-way、 Accuracy of small sample classification test (%).
This paper finds that although TADAM stay 5-shot Mini-ImageNet Better than SRWM, But in 1-shot、5-shot FC100 as well as 1-shot MiniImangeNet On the performance and SRWM Be roughly the same . Even though SRWM Is a very general method , But its overall performance is very competitive , This shows the effectiveness of the proposed self - correcting weight matrix ( The main objective of this experiment ).
2. Continuous multi task adaptability
This section needs to test its adaptability on the task of adapting to environmental changes at run time . This paper makes two modifications to the above small sample learning .
First , Do not use sync tab settings ( chart 2) On the model N-way K-shot Specialized training in classification , But in the picture 3 The model in this paper is trained in the delay label setting shown in . here , Model at each time step , By receiving an input image to be classified and the correct label of the previous input ( So the label transport is moved / Delay by one time step ) To make predictions . This setting facilitates continuous prediction / Solution flow assessment model . secondly , By combining two image sequences from two different data sets (Omniglot and Mini-ImageNet) In series , Construct the image sequence to be predicted . The model first receives an image stream from one of the data sets , At some point , Make the data set change suddenly , To simulate changes in the environment . The model must learn to operate without human intervention , Adapt to this shift in the ongoing execution of the program .
Be careful , The goal of this article is to construct a task , It needs to adapt to sudden changes during model operation . This is different from the goal of continuous small sample learning , That is, meta learning is performed continuously on multiple small sample learning tasks .
therefore , This paper is based on an example 5-way Experiment in classification settings , take Omniglot and Mini-ImageNet The pieces are strung together , Each class in each fragment contains up to 15 Example .
Every batch The connection sequence of is alternating , The length of the training segment is cut randomly . Regardless of the model type , This paper finds that the training model with delayed label setting is more difficult than that with synchronous label setting . It is observed that , In many configurations , The model is stuck in a suboptimal behavior , In this behavior , It learns to improve zero samples (zero-shot) Class average precision of ( Obviously by learning an unused tag of the new class that first appears in the output sequence ), But you can't learn correctly at every step of the feedback . The most critical superparameter identified in this paper is a large enough batch size .
Last , This paper has successfully trained on this continuous adaptive task DeltaNet Benchmark model and SRWM. chart 4 Shows SRWM The test time accuracy changes with the increase of input . In this test setup , The model receives from Omniglot A series of samples of the data set begin . In the 74 Generation task changes ; At this point, the model must be aligned to the slave Mini-ImageNet The data set samples the images for classification . This change leads to a significant decline in the accuracy of the model , This is because the model does not know which class the new data point belongs to , But it can adapt itself effectively , Start learning the second task . surface 2 Comparison of the DeltaNet and SRWM. Although they are based on Omniglot The performance of the first part of the test sequence is similar ,SRWM stay Mini-ImageNet A higher precision is achieved in the second part of the sampling , Shows its ability to adapt quickly .
chart 4 be based on SRWM Test accuracy of (%)( Use Conv4 Back end ), The model is a function of the number of forwarding steps in the continuous multi task adaptation setup ( The first 4.2 section ). The stream of data points is provided to the model in the form of delay labels ( chart 3). Data points from Omniglot Take samples until the 74 Step ( The accuracy is reduced ), And then from Mini-ImageNet sampling .

surface 2 The total accuracy and instance level accuracy of continuous multi task small sample learning experiment (%)( The first 4.2 section ). For instance level precision , Column k∈{1,2,3,5,10} Represents the... In each class k Percentage of correct predictions for instances . The model under the test time scenario is first required to learn prediction Omniglot and Mini-ImageNet.Conv4 The back end is used for both models .
3. Multi task reinforcement learning (RL)
Last , In this paper, the ProcGen Multi tasking of game environment settings RL Evaluate the proposed model . The corresponding settings are shown in the figure 5 Shown .

chart 5 multitasking RL Illustration of . Initial weight matrix W0 It is the same for all tasks and scenarios . An effective weight matrix is task specific / Functions of the input stream of events .

surface 3 Shows the normalized fraction of the aggregation .
Compared to the benchmark model ,SRWM Performance improvement in Bigfish and Starpilot These two environments are especially large . This paper studies these two cases separately . As shown in the table , This paper compares the above multi task training with the training in one environment 50M The expert training of step is compared .
stay Starpilot On , In this paper, we observe that the self correction mechanism is improved even in the case of a single task .Bigfish Is more interesting : In expert training cases , The performance of the model with and without self correction ability is close to . However , The self - correcting model gets better scores in multi - task settings , In multitasking settings , The performance of the benchmark model has been greatly reduced . This proves that SRWM The ability to adapt to each environment in a multitasking scenario .

surface 4 Performance comparison between multi task and expert training model . stay ProcGen The original score obtained from the simple distribution of .
As an ablation study , In this paper, at each fixed time span ( Its length is the back propagation span ) Then reset the weight update to train and evaluate SRWM. Compare it to models that don't self correct ( surface 3) And fail to take advantage of SRWM Mechanism model , The model is obtained on the training and testing branches respectively 28.5(1.2) and 16.1(2.2) The scores of .
In three experiments , It is proved that the SRWM It's practical , And in supervised small sample learning and multi task reinforcement learning , And the game environment generated by the program performs well . It is hoped that the results of this paper can encourage the further study of self - correcting neural networks .
https://arxiv.org/abs/2202.05780
边栏推荐
- 【新手上路常见问答】关于项目管理
- [collect first and use it sooner or later] 49 Flink high-frequency interview questions series (I)
- 智能化整体图例,布线、安防、广播会议、电视、楼宇、消防、电气图的图例【转自微信公众号弱电课堂】
- spawn ./ gradlew EACCES at Process. ChildProcess._ handle. onexit
- Sqli labs customs clearance hey hey~
- 【实用脚本】获取某个文件的行号,然后删除文件内容。
- SQL statement when the query condition is blank, all data will be queried by default. If it is not blank, the query will be performed according to the condition
- Comparison of mongoose in express, KOA and egg
- The maximum (minimum, latest and top n) records are taken for MySQL grouping
- Global and Chinese markets for ultra high speed printers 2022-2028: Research Report on technology, participants, trends, market size and share
猜你喜欢
![Acwing game 40 [End]](/img/6b/a9ea5e1f9578d21219c69571e8b0f8.jpg)
Acwing game 40 [End]
Upload labs failed to pass the customs halfway and the middle road collapsed

vulhub

Getting started with Wireshark
![Spring 2021 daily question [week7 not finished]](/img/93/582608e18bf6d78c552fa9478cdd77.jpg)
Spring 2021 daily question [week7 not finished]

SQL error injection 1

Three steps of ffmpeg CBR precise bitstream control
![Codeworks round 479 (Div. 3) [done]](/img/a0/f3c6989d8f755c03076b237514ee64.jpg)
Codeworks round 479 (Div. 3) [done]

Bracket generation ---2022/02/25

Why is the UDP stream set to 1316 bytes
随机推荐
Experiment 3: design and verify all operations represented by linear table sequence on the computer
神经网络与深度学习-2- 机器学习简单示例-PyTorch
How ZABBIX can customize MySQL monitoring items and trigger alarms
社会工程学实战入门
Merge K ascending linked lists ---2022/02/26
Understanding of distributed transactions
Expérience initiale du moteur de segmentation de l'araignée mariadb
TestPattern error
Intelligent overall legend, legend of wiring, security, radio conference, television, building, fire protection and electrical diagram [transferred from wechat official account weak current classroom]
Hello go (XI). Go language common standard library I
[collect first and use it sooner or later] 100 Flink high-frequency interview questions series (II)
Global and Chinese market of high frequency bipolar junction transistors 2022-2028: Research Report on technology, participants, trends, market size and share
“LSTM之父”新作:一种新方法,迈向自我修正的神经网络
6-7 file read / write operation
6-3 reading articles (*)
Upload labs failed to pass the customs halfway and the middle road collapsed
Système d'information sur les menaces à la sécurité des réseaux
【先收藏,早晚用得到】100个Flink高频面试题系列(二)
Spring 2021 daily question [week7 not finished]
光纤熔接知识汇总【转载自微信公众号弱电智能化工程2018】