当前位置:网站首页>YOLOv3详解:从零开始搭建YOLOv3网络
YOLOv3详解:从零开始搭建YOLOv3网络
2022-08-04 05:34:00 【热血厨师长】
因为YOLO系列有不同版本,分为v1,v2,v3,v4四个版本,从论文上分析需要从头开始,本文从实战入手,分析YOLOv3的原理。
代码地址:https://github.com/Runist/YOLOv3
1、YOLOv3网络结构
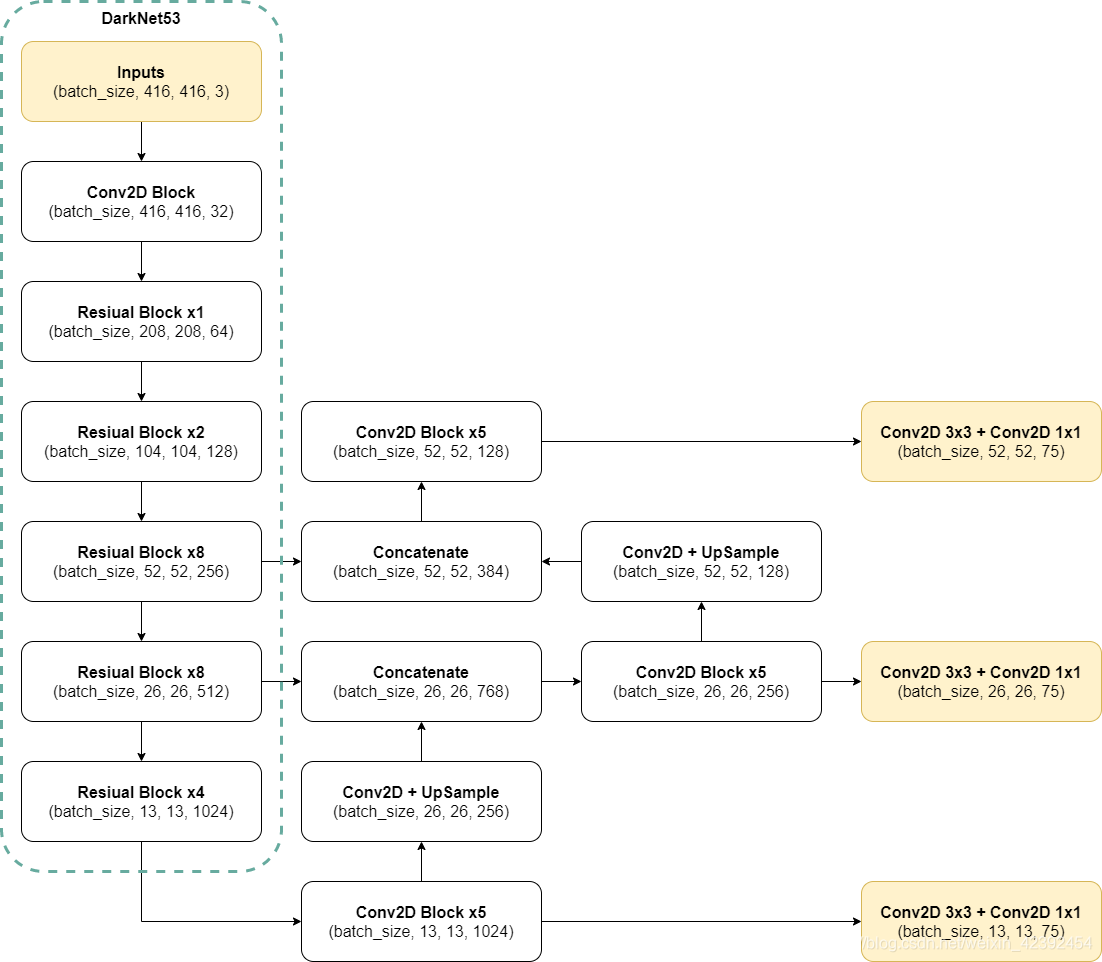
骨干网络(backbone)——特征提取
- YOLOv2的backbone采用的是DarkNet19 ,而YOLOv3采用的是DarkNet53。
- DarkNet53中无池化层,全连接层,特征图的缩小是通过增加卷积核的步长实现的。
- DarkNet53的每一个卷积部分使用了特有的Conv2D Block结构,每一次卷积的时候进行l2正则化,完成卷积后进行。BatchNormalization标准化与LeakyReLU。
- 采用FPN的思想,输出三个尺度的特征层,13x13,26x26,52x52。其中13x13适用于检测大目标,52x52适用于检测小目标。但相比与YOLOv2将所有特征层融合后只输出一个预测结果不同,v3三个特征层都会输出结果。
FPN——多尺度预测结果
- 13x13的特征层,首先经过1x1的卷积修正通道数,然后通过上采样修正空间维度的尺寸。使得输出的结果能够与26x26的特征层叠加。
- 融合之后还会再采用3x3的卷积对每个融合结果进行5次卷积,目的是消除上采样的混叠效应。
- 最后经过一个3x3和1x1的卷积完成三个尺度的预测特征图构建。
预测特征图
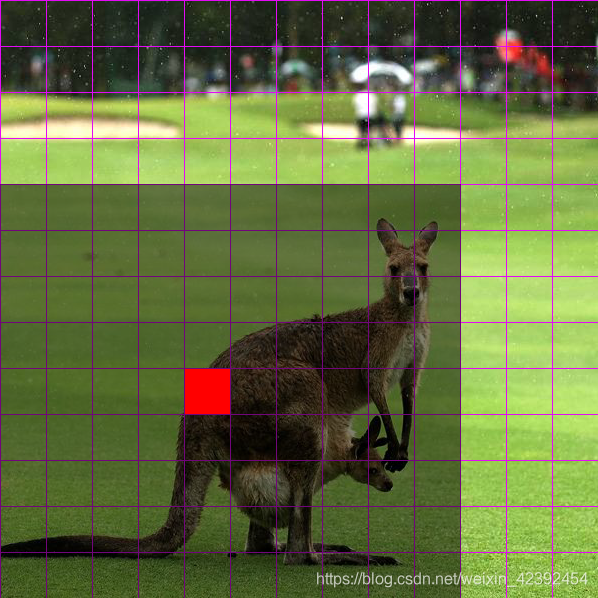
很多初学者不清楚特征图是一个什么概念,我们以13x13大小的特征图为例,如下图所示:

因为输入图片的大小为416x416,这里我们忽略卷积的实际感受野,按照输入宽高除以特征图宽高来计算 416 13 = 32 \frac{416}{13} = 32 13416=32,那么特征图上一个格点则包含了周围32个像素点的信息。
那么图中灰色的框则代表在特征层上与真实框有关的格点。但实际上并非所有格点都有用,对于这张图而言,坐标信息只存储在红色格点内,也就是框的最中心的格点。所以可以看出YOLOv3对目标检测的标准是:物体中心落在那个格点上,这个格点就负责识别存储它。所以在数据输入的时候,例如真实框坐标为:(100,100),(200,200)那么我们需要根据YOLOv3的要求将它转为特征层上对应的格点。
先验框(Anchor)
Anchor是提前设定好的检测框(大小与尺寸都是设定好的),所以中文译为先验框。如果检测器去学习任意形状或大小的物体或许很难,但检测器仅仅只预测基于先验框的偏移值,相比起来就更加容易,因为预测值全为0的时候,等价于输出先验框,平均上更加接近真实物体。如果从没有先验框开始训练,必须从头开始学习不同边界框的形状。
而YOLOv3的先验框策略是:在所有训练图像的所有边框上进行K-Means聚类来选择先验框,论文中建议一个格点上先验框的数量为5个,这是速度和精度之间折中的结果。
2、预测结果的解析
输出维度
从YOLOv3输出的三个特征图shape可以看到,都是(batch_size, xxx, xxx, 75)。我们知道这里第2、3维度是指预测特征层的宽和高,那这个75是什么呢?
- 75可以看成3 x 25
- 25又可以拆分成20 + 4 + 1
首先3 x 25的3是指:每个特征层上的一个单元格内,将会有3个先验框来预测是否有物体。其次,20 + 4 + 1,20是指,VOC中,有20个种类的目标需要预测。而4是指预测框的四个数据x,y,w,h。1则是指这个框内框到了物体的置信度。所以其实75可以继续拆分,有的代码上就会说(batch_size, xxx, xxx, 3, 25),在实现上都是非常灵活的。
如果你的数据集不是20个分类,而是2、3个这样的,输出特征层的维度自然不一样。如:当只有2个类别的时候,维度就是(batch_size, xxx, xxx, 21=3*(4+1+2))
物体分类、识别分数
以VOC为例,输出有20个,与图像分类中的one-hot类似。在预测阶段,用sigmoid激活。但有所不同的是,它还需要乘上物体的置信度才能作为最后的输出。而从20个结果中取出最大值和最大值的索引,得出预测的分数和具体的物体分类。
预测框回归
预测框回归的思想有点难理解,但懂了之后还是觉得很简单的。边框回归最简单的想法就是通过平移加尺度缩放进行微调。边框回归为何只能微调?当预测框与真实框相差不大的时候,让预测框通过平移+变换就可以认为这种变换是一种线性变换。我们可以从下面这张图看一下YOLO的预测框回归。
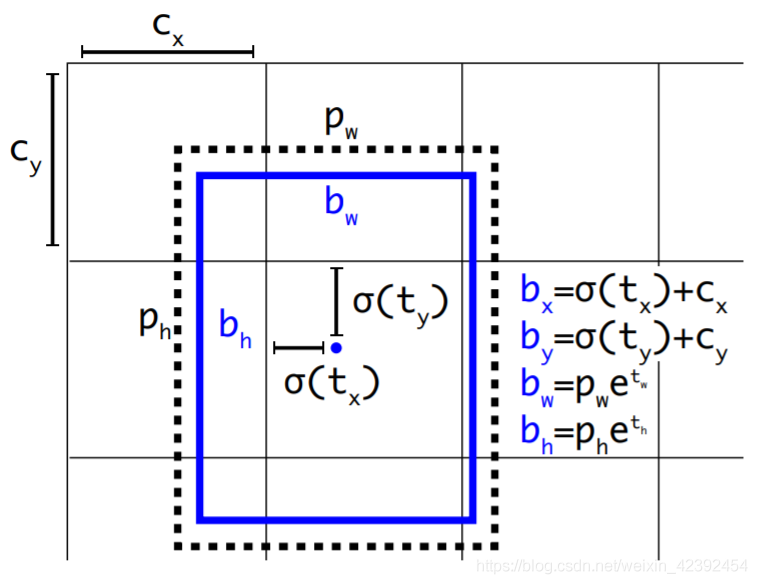
在YOLO9000后,神经网络会为每个边界框预测4个系数: t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th,对应着输出维度中4+1的4。光有这四个系数是不够的。现在我们还需要其他一些参数:
- p w , p h p_w,p_h pw,ph:为先验框的宽和高
- c x , c y c_x,c_y cx,cy:这两个是相对于左上角坐标的偏移值,框的中心在哪个格点,偏移就为多少个格点
图中 b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh是预测框的结果。而 σ ( x ) \sigma(x) σ(x)是指激活函数sigmoid, e e e则是指数学自然常数的2.718281828459045。用sigmoid将tx,ty压缩到[0,1]区间內,可以有效的确保目标中心处于执行预测的网格单元中,防止偏移过多。
我们不直接拿预测框和真实框的实际宽高来计算边界框回归,是因为物体分类和识别分数的预测值都是在0-1之间的,如果不对bounding box做归一化处理,那么bounding box loss值将非常大,在整个yolo loss中占主导地位,且会导致训练不稳定。
3、损失函数
YOLOv3的loss function分为3个部分,一个是回归框的损失,第二个是置信度的损失,第三个是分类损失。其中回归框的损失又分为坐标点的损失和回归框的宽高损失。
回归框的损失
首先,我们要知道xy经过神经网络输出是没有经过激活函数的,也就是说输出并不一定在0-1区间,所以我们需要用带有sigmoid激活的损失函数。其次,由于是一个微调的线性回归问题,因此可以选用均方误差,但在复现代码中也可以使用交叉熵损失(tf.nn.sigmoid_cross_entropy_with_logits)。
而wh的输出则没有取值范围的限定,因此我们可以直接使用均方误差(tf.nn.square)进行计算。
值得注意的一点是,因为大框的loss在总的loss中会占比较大比重,所以我们需要使用加权平均法平衡一下回归框的损失,而加权因子:
b o x _ l o s s _ s c a l e = 2 − w × h box\_loss\_scale = 2 - w \times h box_loss_scale=2−w×h
置信度损失、分类损失
这两个比较简单,直接采用交叉熵损失即可。
4、总结
本文基于代码实现进行讲解,并未对论文中一些细节和公式进行展开讨论,但在代码中也有实现,请读者自行查阅相关论文。
边栏推荐
- Shell基础
- 普通用户 远程桌面连接 服务器 Remote Desktop Service
- RuntimeError: You called this URL via POST, but the URL doesn‘t end in a slash and you have APPEND_S
- 如何在Excel 里倒序排列表格数据 || csv表格倒序排列数据
- 网络安全求职指南
- 基于Webrtc和Janus的多人视频会议系统开发4 - 改造信令交互系统完成sdp交换过程
- Socket编程详解
- 让src文件夹能读取xml文件
- vs2017 redist 下载地址
- Scheduler (Long-term,Short-term, Medium-term Scheduler) & Dispatcher
猜你喜欢



随机推荐
IE8 打开速度慢的解决办法
JUC并发容器——跳表
为什么不使用VS管理QT项目
学好网络安全看这篇文章让你少走弯路
golang chan
怎样才能转行成功?
ffmpeg打开rtsp流应该设置的几个参数
通过socks5代理下载webrtc源码错误:curl: (7) Can't complete SOCKS5 connection xx.xx.xx.xx
杰哥带大家做一次meterpreter内网渗透模拟
并发概念基础:线程,死锁
C# 剪裁图片内容区域
IDEA中创建web项目实现步骤
【HIT-SC-MEMO1】哈工大2022软件构造 复习笔记1
沉浸式体验参加网络安全培训班,学习过程详细到底!
网络通信与Socket编程概述
【HIT-SC-MEMO6】哈工大2022软件构造 复习笔记6
【HIT-SC-LAB1】哈工大2022软件构造 实验1
桌面右键的NVIDIA去除与恢复
Memory limit should be smaller than already set memoryswap limit, update the memoryswap at the same
你要悄悄学网络安全,然后惊艳所有人