当前位置:网站首页>Text classification still stays at Bert? The dual contrast learning framework is too strong
Text classification still stays at Bert? The dual contrast learning framework is too strong
2022-07-06 05:27:00 【To great】
Brief introduction of the paper : Dual contrast learning : How to apply contrastive learning to supervised text classification
Paper title :Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
Thesis link :https://arxiv.org/abs/2201.08702
Code link :https://github.com/hiyouga/dual-contrastive-learning
Author of the paper :{Qianben Chen}
Zhihu notes :https://zhuanlan.zhihu.com/p/466685216
Abstract of paper
Contrastive learning has achieved remarkable success in representational learning through self-supervision in an unsupervised environment . However , Effectively adapting contrastive learning to supervised learning tasks is still a challenge in practice . In this work , The author proposes a dual contrastive learning (DualCL) frame , Simultaneously learn the features of input samples and the parameters of classifier in the same space . say concretely ,DualCL The parameters of the classifier are treated as enhanced samples associated with different tags , Then it is used for comparative learning between input samples and enhancement samples . Yes 5 The experimental study of a benchmark text classification dataset and its corresponding low resource version dataset shows that ,DualCL The classification accuracy has been significantly improved , And confirmed that DualCL It can realize the effect of sample discriminant representation .
DualCL brief introduction
Representation learning is the core of deep learning . In the context of unsupervised learning , Contrastive learning has recently been proved to be an effective method to obtain the general representation of downstream tasks . In short , Unsupervised contrastive learning uses a loss function , It forces differences in the same sample “ visual angle ” The representation vectors of are similar , The representation vectors of different samples are different . Recently, the effectiveness of comparative learning has been proved to be due to the simultaneous realization of “ Alignment ”【alignment】 and “ Uniformity ”【uniformity】.
The contrastive learning method is also suitable for supervised representation learning , Similar comparative losses have been used in previous studies , The basic principle is to insist that the representation of samples in the same class is similar , The sample representations of different classes are similar . Clear . However , Despite the success , But compared with unsupervised comparative learning , The principle of this method seems to be much worse . for example , The unity of representation is no longer valid ; It's not necessary either , Generally speaking, the spatial distribution of features is no longer uniform , Therefore, we believe that the standard supervised contrastive learning method is not natural for supervised representation learning . Another fact is that , That is, the result of this comparative learning method does not directly give us a classifier , Another classification algorithm needs to be developed to solve the classification task .
Let's talk about DualCL Proposed motivation , The author aims to develop a more natural method to realize comparative learning under supervised tasks . The author's key motivation is that supervised representation learning should include learning two parameters : One is input x x x In appropriate spatial features z z z, Used to meet the needs of classification tasks , The other is the parameters of the classifier , Or the parameters acting on the classifier space θ \theta θ; We call this classifier x x x Of “one example” classifier . In this view , Natural sample x x x Think of two parameters : One dimension is d d d Of z ∈ R d z\in \mathbb{R}^d z∈Rd, Used to represent a feature ; One is the classifier parameter θ ∈ R d × K \theta \in \mathbb{R}^{d \times K} θ∈Rd×K, among K K K Represents the total number of classifications in the sample . Then supervised representation learning can be considered as input samples x x x Generate ( z , θ ) (z,\theta) (z,θ).
To ensure that the classifier θ \theta θ For features z z z It works , Just make sure that θ T z \theta^Tz θTz With samples x x x Keep your labels aligned , Can pass softmax The normalized probability is constrained by cross entropy . besides , In contrast, learning methods can be used to enforce these ( z , θ ) (z,θ) (z,θ) Means to constrain , In particular , We will θ ∗ \theta^* θ∗ Record as sample x x x The real label corresponds to the classifier θ \theta θ Ideal parameter of , Here we can design two kinds of contrast loss . first loss To compare ( z , θ ∗ ) (z,\theta^*) (z,θ∗) With many ( z ′ , θ ∗ ) (z',\theta^*) (z′,θ∗), among z ′ z' z′ Representative and sample x x x Sample characteristics of different categories ; the second loss To compare ( z , θ ∗ ) (z,\theta^*) (z,θ∗) With many ( z , θ ′ ∗ ) (z,\theta'^*) (z,θ′∗), among θ ′ \theta' θ′ Different categories representing samples correspond to classifier parameters , The author calls this learning framework dual contrastive learning(DualCL), Dual contrast learning .
On the basis of comparative learning , As the title of the paper ,DualCL It can be considered as a unique data enhancement method . say concretely , For each sample x x x, Its θ θ θ Each column of can be regarded as “ Tag inspired input represents ”, Or the feature space is filled with label information x x x Enhanced view of . surface 1 The power of this approach is illustrated in , As can be seen from the two pictures on the left , Standard contrastive learning cannot use label information . contrary , From the two figures on the right ,DualCL Effectively use the label information to classify the input samples in its class .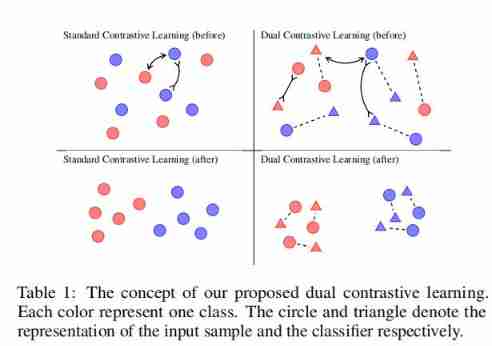
In the paper experiment , The author in 5 It is verified on a benchmark text classification data set DualCL The effectiveness of the . By using the dual ratio loss to the pre trained language model (BERT and RoBERTa) Fine tuning ,DualCL The best performance is obtained compared with the existing baseline of comparative learning supervision . The author also found that ,DualCL The classification accuracy is improved , Especially in low resource scenarios . In addition, by visualizing the learned representation and attention map , Yes DualCL Some interpretability analyses are given .
The contributions of this paper can be summarized as follows :
- 1) Double contrast learning is proposed (DualCL), Naturally combine comparative losses with supervised tasks ;
- 2) Tag aware data enhancement is introduced to obtain multiple views of input samples , be used for DualCL Training for ;
- 3) stay 5 It is empirically verified on a benchmark text classification data set DualCL The effectiveness of the framework ;
DualCL principle
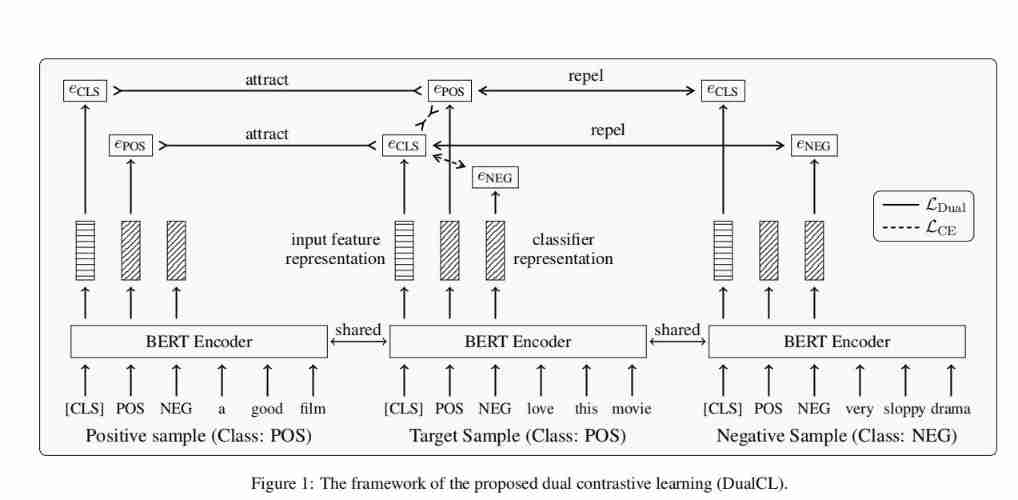
“ dual ” The purpose of supervised contrastive learning is : The first is to discriminate the input of the classification task in an appropriate space , The second is to build a classifier for supervisory tasks , Learn the parameters of the classifier in the classifier space . Now let's see DualCL The core of .
Data enhancement of tag heuristics
In order to obtain different views of training samples (views) Express , The author uses the idea of data enhancement to obtain features z i z_{i} zi And classifiers θ i \theta_{i} θi It means . Specifically, the corresponding parameters of each category of the classifier θ i \theta_{i} θi As z i z_{i} zi A unique representation of , Write it down as θ i k \theta_{i}^{k} θik, Called tag aware input representation , Label k k k Information is injected into x i x_{i} xi, As an additional enhanced view .
In practice , Set tags { 1 , . . . , K } \{1,...,K\} { 1,...,K} Insert into input sequence x i x_{i} xi, A new input sequence can be obtained r i ∈ R L + K r_{i}\in \mathbb{R}^{L+K} ri∈RL+K, And then through PLMS(Bert perhaps Roberta) Model as encoder f f f, To get each of the input sequences token features , among [CLS] Characteristics as samples x i x_{i} xi Characteristics of z i z_{i} zi, The inserted tag corresponds to the tag inspired input representation θ i k \theta_{i}^{k} θik. The name of the tag is used as a marker , Form a sequence r i r_{i} ri, Such as “positive”、“negative” etc. . For tags that contain multiple words , We use token Average pooling of features to obtain a tag aware input representation . This operation is very similar to the previous paper , If you are interested, you can read :Bert It can also be used in this way : Fuse the label vector to BERT
Dual contrast loss
Using input samples x i x_{i} xi Feature representation of z i z_{i} zi And classifiers θ i θ_{i} θi,DualCL What it does is it takes θ i T z i θ_{i}^{T}z_{i} θiTzi Of softmax Normalized probability and x i x_{i} xi Alignment of labels . take θ i ∗ θ^∗_{i} θi∗ Express θ i θ_{i} θi A column of , Corresponding to x i x_{i} xi Real label index ,DualCL expect θ i ∗ T z i θ_{i}^{*T}z_{i} θi∗Tzi The dot product is maximized . In order to learn better z i z_{i} zi and θ i θ_{i} θi,DualCL The dual contrast loss is defined by using the relationship between different training samples , If x j x_{j} xj And x i x_{i} xi Have the same label , Then try to maximize θ i ∗ T z j θ_{i}^{*T}z_{j} θi∗Tzj, And if the x j x_{j} xj And x i x_{i} xi There are different labels , Minimize θ i ∗ T z j θ_{i}^{*T}z_{j} θi∗Tzj.
Given a sample from the input x i x_{i} xi The anchor point z i z_{i} zi, { θ j ∗ } j ∈ P i \{ \theta^*_j \}_j\in P_{i} { θj∗}j∈Pi It's a positive sample set , { θ j ∗ } j ∈ A i ∣ P i \{ \theta^*_j \}_j\in A_i \ | P_i { θj∗}j∈Ai ∣Pi It's a negative sample set , About z The comparative loss can be defined as follows :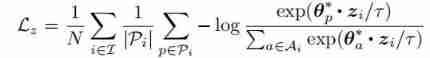
Empathy , Given a sample from the input x i x_{i} xi The anchor point θ i ∗ \theta_{i}^* θi∗, { z j } j ∈ P i \{ z_j \}_j\in P_{i} { zj}j∈Pi It's a positive sample set , { z j } j ∈ A i ∣ P i \{ z_j \}_j\in A_i \ | P_i { zj}j∈Ai ∣Pi It's a negative sample set , About z The comparative loss can be defined as follows :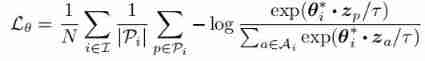
The dual ratio loss is the combination of the above two comparative loss terms :
L D u a l = L z + L θ \mathcal{L_{Dual}}= \mathcal{L_{z}}+ \mathcal{L_{ \theta }} LDual=Lz+Lθ
Compare training with supervised prediction
In order to make full use of the supervision signal ,DualCL Also expected θ i θ_{i} θi It's a very good z i z_{i} zi classifier . Therefore, the author uses an improved version of cross entropy loss to maximize each input sample x i x_i xi Of θ i ∗ T z i θ_{i}^{*T}z_{i} θi∗Tzi: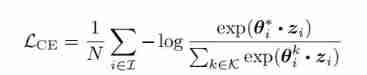
Last , Minimize these two training objectives to train the encoder f f f. These two goals improve both the representation quality of features and the representation quality of classifiers . The total loss should be :
L o v e r a l l = L C E + λ L D u a l \mathcal{L_{overall}}= \mathcal{L_{CE}}+\lambda \mathcal{L_{ Dual }} Loverall=LCE+λLDual
among , λ λ λ It is a super parameter that controls the weight of double contrast loss term .
In the process of classification , We use trained encoders f f f To generate input sentences x i x_i xi Feature representation of z i z_i zi And classifiers θ i θ_i θi. there θ i θ_i θi Can be seen as a “one-example” Classifier , for example x i x_i xi, We will θ i T z i θ_{i}^{T}z_{i} θiTzi Of argmax The results are predicted as a model :
y ^ i = a r g m a x ( θ i k ⋅ z i ) \widehat{y}_i=argmax(\theta_i^k ·z_{i}) yi=argmax(θik⋅zi)
chart 1 The framework of dual contrast learning is explained , among e C L S e_{CLS} eCLS It's a feature representation , e P O S e_{POS} ePOS and e N E G e_{NEG} eNEG Is the classifier representation . In this particular case , We assume to have “positive” Class as an anchor , And there is a positive sample with the same class label , There is a negative sample with different class labels . The dual contrast loss aims to attract the feature representation to the classifier representation between positive samples at the same time , The feature representation is excluded to the classifier between negative samples .
Duality between representations
The comparison loss adopts the point product function as the measure of similarity between , This makes DualCL Feature representation in z z z And classifiers represent θ θ θ There is a dual relationship between . In linear classifier , A similar phenomenon occurs in the relationship between input features and parameters . Then we can put θ θ θ As a parameter of a linear classifier , Such a pre trained encoder f f f A linear classifier can be generated for each input sample . therefore ,DualCL Naturally learn how to generate a linear classifier for each input sample to perform the classification task .
Experimental setup
Data sets
The paper adopts SST-2、SUBJ、TREC、PC and CR Four data sets , The relevant statistics of the data set are as follows :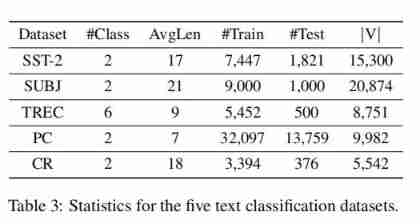
experimental result
As can be seen from the results , Besides using RoBERTa Of TREC Outside the data set , Use at the same time BERT and RoBERTa The encoder achieves the best classification performance in almost all settings . With complete training data CE+CL comparison ,DualCL Yes BERT and RoBERTa The average improvement rates are 0.46% and 0.39%. Besides , We observed that , stay 10% Training data ,DualCL The performance of is significantly greater than CE+CL Method , stay BERT and RoBERTa Above each other 0.74% and 0.51%. meanwhile ,CE and CE+SCL The performance cannot exceed DualCL. This is because CE The method ignores the relationship between samples ,CE+SCL Method can not directly learn the classifier of classification task .
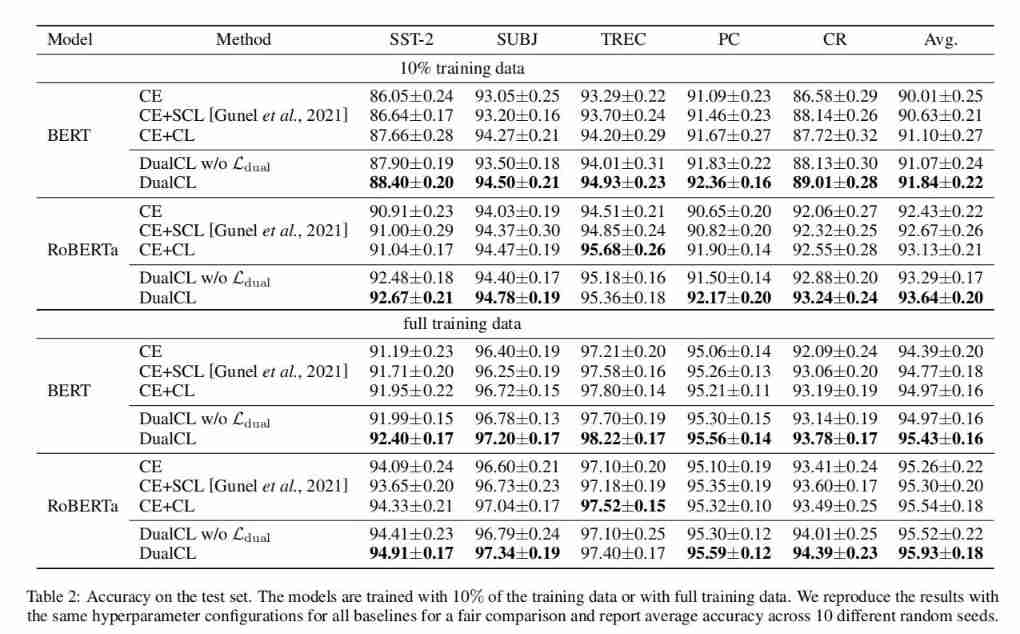
In addition, the paper finds that the double contrast loss term helps the model achieve better performance on all five data sets . It shows that using the relationship between samples is helpful for the model to learn better representation in comparative learning .

case analysis
In order to verify DualCL Is it possible to capture information characteristics , The author also calculated [CLS] The marked features and the attention score between each word in the sentence . First, fine tune the whole training set RoBERTa Encoder . Then we calculate the between features l 2 l_2 l2 distance , And visualize 4 Notice the figure in . It turns out that , When classifying emotions , The captured features are different . The above example comes from SST-2 Data sets , We can see that our model focuses more on expression “ positive ” Emotional sentences “predictably heart warming”. The following example comes from CR Data sets , We can see that our model expresses “ negative ” Emotional sentences pay more attention to “small”. contrary ,CE The method does not focus on these distinguishing features . It turns out that DualCL Be able to successfully deal with informative keywords in sentences .

A summary of the paper
- In this study , From the perspective of text classification task , A dual contrast learning method is proposed DualCL, To solve the task of supervised learning .
- stay DualCL in , Author use PLMs Learn both expressions at the same time . One is the identification feature of the input example , The other is the classifier of this example . We introduce tag aware data enhancement to generate different views of input samples , It contains features and classifiers . Then a dual contrast loss is designed , Make the classifier valid for the input features .
- Dual contrast loss uses the supervision signals between training samples to learn better representation , The effectiveness of dual contrast learning is verified by a large number of experiments .
Core code
About Dual-Contrastive-Learning Realization , You can check the open source code :
https://github.com/hiyouga/Dual-Contrastive-Learning/blob/main/main_polarity.py
def _contrast_loss(self, cls_feature, label_feature, labels):
normed_cls_feature = F.normalize(cls_feature, dim=-1)
normed_label_feature = F.normalize(label_feature, dim=-1)
list_con_loss = []
BS, LABEL_CLASS, HS = normed_label_feature.shape
normed_positive_label_feature = torch.gather(normed_label_feature, dim=1,
index=labels.reshape(-1, 1, 1).expand(-1, 1, HS)).squeeze(1) # (bs, 768)
if "1" in self.opt.contrast_mode:
loss1 = self._calculate_contrast_loss(normed_positive_label_feature, normed_cls_feature, labels)
list_con_loss.append(loss1)
if "2" in self.opt.contrast_mode:
loss2 = self._calculate_contrast_loss(normed_cls_feature, normed_positive_label_feature, labels)
list_con_loss.append(loss2)
if "3" in self.opt.contrast_mode:
loss3 = self._calculate_contrast_loss(normed_positive_label_feature, normed_positive_label_feature, labels)
list_con_loss.append(loss3)
if "4" in self.opt.contrast_mode:
loss4 = self._calculate_contrast_loss(normed_cls_feature, normed_cls_feature, labels)
list_con_loss.append(loss4)
return list_con_loss
def _calculate_contrast_loss(self, anchor, target, labels, mu=1.0):
BS = len(labels)
with torch.no_grad():
labels = labels.reshape(-1, 1)
mask = torch.eq(labels, labels.T) # (bs, bs)
# compute temperature using mask
temperature_matrix = torch.where(mask == True, mu * torch.ones_like(mask),
1 / self.opt.temperature * torch.ones_like(mask)).to(self.opt.device)
# # mask-out self-contrast cases, That is, you don't take yourself into account
# logits_mask = torch.scatter(
# torch.ones_like(mask),
# 1,
# torch.arange(BS).view(-1, 1).to(self.opt.device),
# 0
# )
# mask = mask * logits_mask
# compute logits
anchor_dot_target = torch.multiply(torch.matmul(anchor, target.T), temperature_matrix) # (bs, bs)
# for numerical stability
logits_max, _ = torch.max(anchor_dot_target, dim=1, keepdim=True)
logits = anchor_dot_target - logits_max.detach() # (bs, bs)
# compute log_prob
exp_logits = torch.exp(logits) # (bs, bs)
exp_logits = exp_logits - torch.diag_embed(torch.diag(exp_logits)) # Subtract diagonal elements , You can't
log_prob = logits - torch.log(exp_logits.sum(dim=1, keepdim=True) + 1e-12) # (bs, bs)
# in case that mask.sum(1) has no zero
mask_sum = mask.sum(dim=1)
mask_sum = torch.where(mask_sum == 0, torch.ones_like(mask_sum), mask_sum)
# compute mean of log-likelihood over positive
mean_log_prob_pos = (mask * log_prob).sum(dim=1) / mask_sum.detach()
loss = - mean_log_prob_pos.mean()
return loss
Reference material
ICML 2020: from Alignment and Uniformity Understanding contrastive representation learning from the perspective of
https://blog.csdn.net/c2a2o2/article/details/117898108
边栏推荐
- 备忘一下jvxetable的各种数据集获取方法
- Huawei equipment is configured with OSPF and BFD linkage
- Select knowledge points of structure
- [QNX Hypervisor 2.2用户手册]6.3.3 使用共享内存(shmem)虚拟设备
- Simple understanding of interpreters and compilers
- Easy to understand IIC protocol explanation
- Mysql高级篇学习总结9:创建索引、删除索引、降序索引、隐藏索引
- Unity gets the width and height of Sprite
- MySQL advanced learning summary 9: create index, delete index, descending index, and hide index
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
猜你喜欢
Microblogging hot search stock selection strategy
Implementing fuzzy query with dataframe

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Using stopwatch to count code time

Yyds dry inventory SSH Remote Connection introduction

Codeforces Round #804 (Div. 2) Editorial(A-B)

Configuration file converted from Excel to Lua
Please wait while Jenkins is getting ready to work

Ad20 is set with through-hole direct connection copper sheet, and the bonding pad is cross connected
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
随机推荐
GAMES202-WebGL中shader的編譯和連接(了解向)
Principle and performance analysis of lepton lossless compression
UCF (2022 summer team competition I)
JS array list actual use summary
Vulhub vulnerability recurrence 72_ uWSGI
Huawei equipment is configured with OSPF and BFD linkage
Oracle deletes duplicate data, leaving only one
02. Develop data storage of blog project
【华为机试真题详解】检查是否存在满足条件的数字组合
Pix2pix: image to image conversion using conditional countermeasure networks
[detailed explanation of Huawei machine test] check whether there is a digital combination that meets the conditions
Mongodb basic knowledge summary
Mysql高级篇学习总结9:创建索引、删除索引、降序索引、隐藏索引
[leetcode daily question] number of enclaves
01. 开发博客项目之项目介绍
Self built DNS server, the client opens the web page slowly, the solution
[leetcode16] the sum of the nearest three numbers (double pointer)
HAC集群修改管理员用户密码
[effective Objective-C] - memory management
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower