当前位置:网站首页>GCC编译器技术解析
GCC编译器技术解析
2022-08-02 05:39:00 【wujianming_110117】
GCC编译器技术解析
参考文献链接
https://mp.weixin.qq.com/s/-MhkY2FLZ3Tn4eWZZrZ2Ww
https://mp.weixin.qq.com/s/BaATGUQJii_YPwXpc5Dzow
https://mp.weixin.qq.com/s/Y3xyHoMmES_skOHgteB41g
https://mp.weixin.qq.com/s/1g4i64UklWybygT4CR5MTA
https://mp.weixin.qq.com/s/8QXCSrGdOrdzIcTa6VG1Hw
https://mp.weixin.qq.com/s/h6NY1aaxzBcws0c28cbrdQ
GCC安装详解
一.准备工作
linux一般可以从软件包等方式直接安装gcc,但不一般不是最新版,比如需要支持C++11
等原因,则需要安装最新版gcc。
先查看已有的gcc版本
witch gcc g++ …gcc -v …g+±v
如果系统还没有任何gcc被安装,则需要从开发包中先安装默认的低版本的gcc
centos下也可以安装带gcc的开发工具:yum groupinstall “Development Tools”
若不先安装旧版本的话安装可能会出现如下错误:
configure: error: no acceptable C compiler found in $PATH
二.安装
若直接安装会出现如下错误:
configure: error: Building GCC requires GMP 4.2+, MPFR 2.3.1+ and MPC 0.8.0+. Try the --with-gmp, --with-mpfr and/or --with-mpc options to specify their locations.
因为缺少gcc依赖的gmp、mpfr、mpc三个软件。同时gmp与mpfr及mpc之间还有相互依赖关系,所以
要按下面顺序安装,并在 configure后面的选项后面带上所依赖软件的路径.
1.解压
t a r − z x f g c c − 10.2.0. t a r . g z tar -zxf gcc-10.2.0.tar.gz tar−zxfgcc−10.2.0.tar.gztar -jxvf gmp-4.3.2.tar.bz2 t a r − j x v f m p f r − 3.1.4. t a r . b z 2 tar -jxvf mpfr-3.1.4.tar.bz2 tar−jxvfmpfr−3.1.4.tar.bz2tar -zxf mpc-1.0.3.tar.gz
2.新及安装目录(root)
mkdir /usr/local/gcc-10.2.0mkdir /usr/local/gmp-4.3.2mkdir /usr/local/mpfr-3.1.4mkdir /usr/local/mpc-1.0.3
3.安装依赖
KaTeX parse error: Expected 'EOF', got '#' at position 15: cd gmp-4.3.2 #̲ gmp安装路径./configure --prefix=/usr/local/gmp-4.3.2 $make $make check $sudo make install
$cd mpfr-3.1.4 // congfigure后面是mpfr安装路径及依赖的gmp路径 $./configure --prefix=/usr/local/mpfr-3.1.4 --with-gmp=/usr/local/gmp-4.3.2 $make $make check $sudo make install
$cd mpc-1.0.3 // congfigure后面是mpc安装路径及依赖的gmp和mpfr路径 $./configure --prefix=/usr/local/mpc-1.0.3 --with-gmp=/usr/local/gmp-4.3.2 --with-mpfr=/usr/local/mpfr-3.1.4 $make $make check KaTeX parse error: Expected 'EOF', got '#' at position 62: …等等,所以需要进行一系列配置 #̲vi /etc/profile…LD_LIBRARY_PATH:/usr/local/gmp-4.3.2/lib: /usr/local/mpfr-3.1.4/lib:/usr/local/mpc-1.0.3/lib #source /etc/profile //使其立即生效 #echo $LD_LIBRARY_PATH //查看配置是否成功 /usr/local/gmp-4.3.2/lib:/usr/local/mpfr-3.1.4/lib:/usr/local/mpc-1.0.3/lib //显示这个表示成功 #vi /etc/ld.so.conf //编辑这个文件,添加下面路径 /usr/local/mpc-1.0.3/lib /usr/local/gmp-4.3.2/lib /usr/local/mpfr-3.1.4/lib $sudo ldconfig
4.安装gcc
c d g c c − 4.8.2 cd gcc-4.8.2 cdgcc−4.8.2./configure --prefix=/usr/local/gcc-10.2.0 --enable-threads=posix --disable-checking --disable-multilib --enable-languages=c,c++ --with-gmp=/usr/local/gmp-4.3.2 --with-mpfr=/usr/local/mpfr-3.1.4 --with-mpc=/usr/local/mpc-1.0.3 $make KaTeX parse error: Expected 'EOF', got '#' at position 27: …nstall 5.配置gcc #̲vi /etc/profile…PATH:/usr/local/gcc-10.2.0 #source /etc/profile //使其立即生效 #rm /usr/bin/gcc //删除旧的软连接 #ln -s /usr/local/gcc4.8.2/bin/gcc /usr/bin/gcc //使新版本建立软连接 //下面的同理 #rm /usr/bin/g++ #ln -s /usr/local/gcc-10.2.0/bin/g++ /usr/bin/g++
6.检查
查看是否安装更新成功:
witch gcc g++ …gcc -v …g+±v
三.关于sudo
有些软件安装时如果是在root下安装,在一般用户下有可能无法使用,所以一般在普通用户下安装,
这就用到sudo了
用一般用户登录,然后su 切换到root下
chmod 744 /etc/sudoersvi /etc/sudoers
找到 :
root ALL(ALL) ALL
这一行,在下面添加
一般用户名 ALL(ALL) ALL
保存
然后再exit退出到一般用户下进行安装即可。
GCC基本使用
介绍GCC的概念和嵌入式环境下GCC的基本使用。
- GCC工具
GCC编译器:
GCC(GNU Compiler Collection)是由 GNU 开发的编程语言编译器。GCC支持C、 C++、Java 等多种语言。
Ubuntu下系统默认已经安装好GCC编译器,可以通过如下命令查看系统中GCC编译器的版本及安装路径: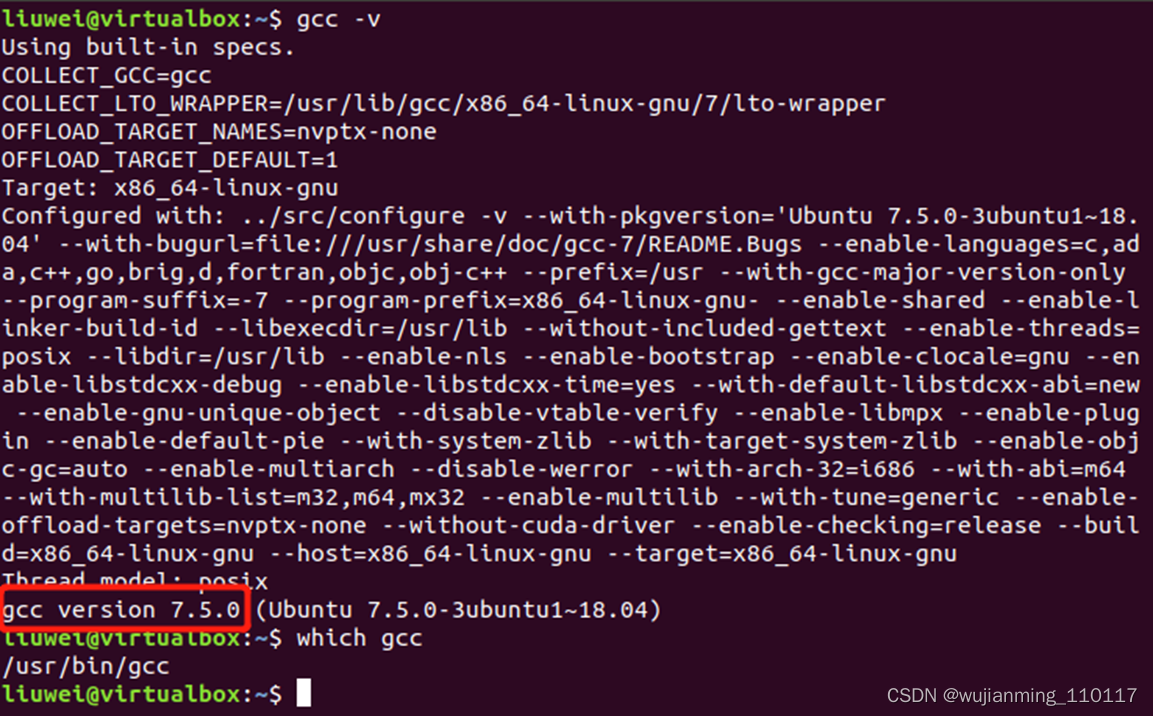
GCC编译工具链:
GCC编译工具链,是指以GCC编译器为核心的一整套工具。主要包含以下三部分内容:
• gcc-core:GCC编译器,把C转换成汇编。
• Binutils :除GCC编译器外的一系列小工具。
• glibc:主要中 C语言标准函数库。
在很多场合下会直接用GCC编译器来指代整套GCC编译工具链。
Binutils工具集:
Binutils(bin utility),是GNU二进制工具集,通常跟GCC编译器一起打包安装到系统 。
系统默认的Binutils工具集位于/usr/bin目录下,可使用如下命令查看系统中存在的Binutils工具集:
在Ubantu上执行如下命令 ls /usr/bin/ | grep linux-gnu-
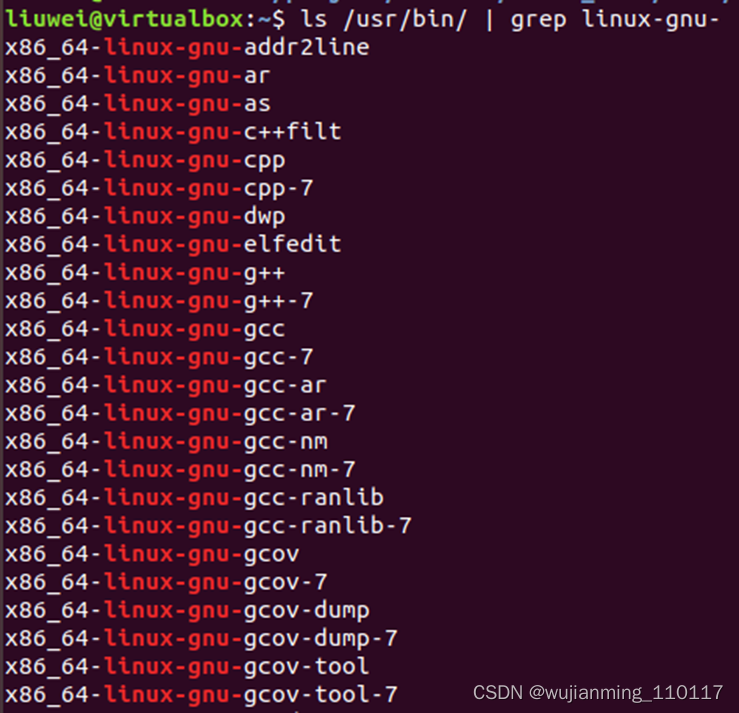
glibc库:
glibc库是GNU组织编写的C语言标准库,绝大部分C程序都依赖该函数库。
在Ubuntu系统下,libc.so.6是glibc的库文件,可直接执行该库文件查看版本:
在Ubantu上执行如下命令 /lib/x86_64-linux-gnu/libc.so.6
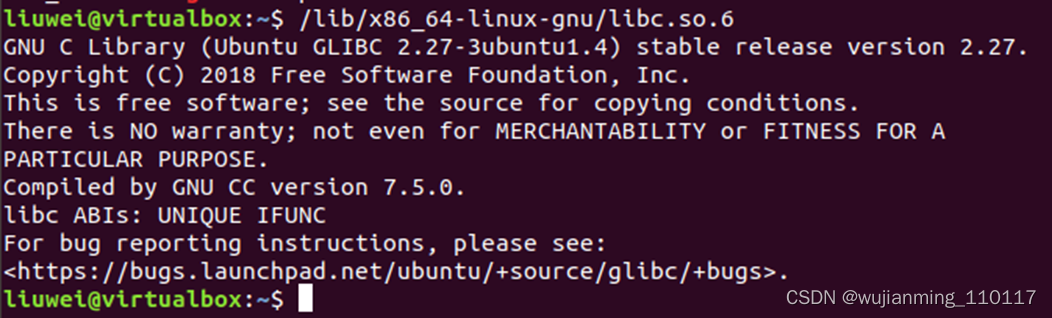
2. GCC编译
编写HelloWorld文件:
#include <stdio.h>int main() { printf(“hello, world! \n”); return 0;}
编译并执行:
写好程序后可以直接进行编译,执行以下命令:
在Ubantu下执行如下命令 gcc hello.c –o hello ls ./hello #执行生成的程序
GCC 编译工具链在编译一个C源文件时需要经过以下 4 步:
• 预处理
• 编译
• 汇编
• 链接
(1)预处理阶段
预处理过程中,可理解为把头文件的代码、宏之类的内容转换成更纯粹的C代码,不过生成的文件以.i为后缀。
使用GCC的参数 “-E”,可以让编译器生成 .i 文件,参数 “-o”,可以指定输出文件的名字。
预处理 gcc –E hello.c –o hello.i
编译生成的hello.i文件内容如下: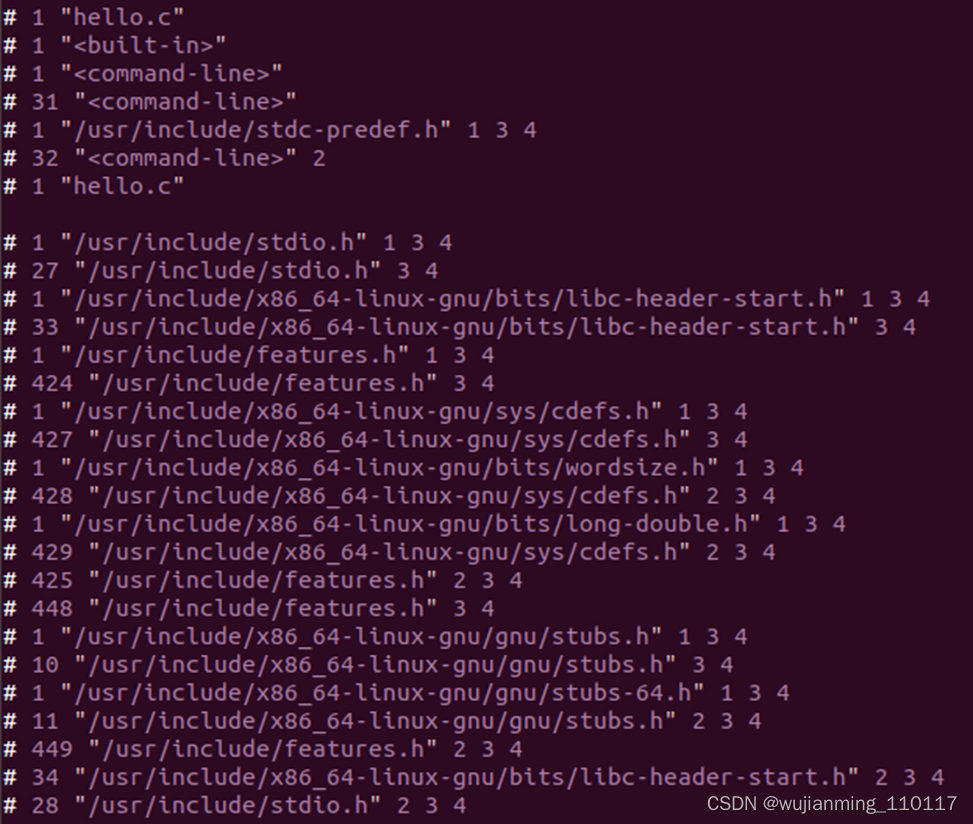
相当于把原C代码中包含的头文件中引用的内容汇总到一处, 如果原C代码有宏定义,把宏定义展开成具体的内容。
(2)编译阶段
把预处理后的.i文件通过编译成为汇编语言,生成.s文件。
GCC可以使用-S选项,让编译程序生成汇编语言的代码文件(.s后缀)。
编译 gcc –S hello.i –o hello.s # 与上面的命令是等价的 gcc –S hello.c –o hello.s
编译生成的hello.s文件内容如下:
汇编语言是跟平台相关的,由于本示例的GCC目标平台是x86,所以此处生成的汇编文件是x86的汇编代码。
(3)汇编阶段
将汇编语言文件经过汇编,生成目标文件.o文件。
GCC的参数 “c” 表示只编译(compile)源文件但不链接,会将源程序编译成目标文件(.o后缀)。
汇编 gcc –c hello.s –o hello.o # 与上面的命令是等价的 gcc –c hello.c –o hello.o
Linux下生成的 *.o目标文件、*so动态库文件都是elf格式的, 可以使用 “readelf” 工具来查看内容。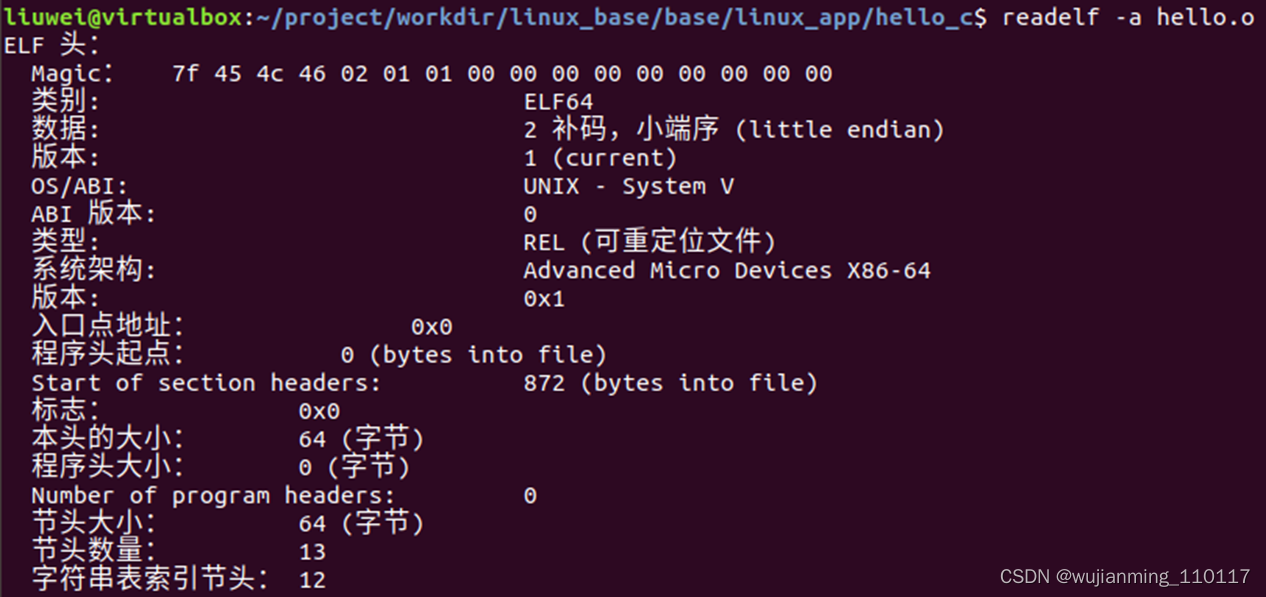
(4)链接阶段
最后将每个源文件对应的目标.o文件链接起来,就生成一个可执行程序文件,这是链接器ld完成的工作。
链接分为两种:
• 动态链接:动态是指在应用程序运行时才去加载外部的代码库,所以动态链接生成的程序比较小。
• 静态链接:在编译阶段就会把所有用到的库打包到自己的可执行程序中,生成的程序比较大。
执行如下命令体验静态链接与动态链接的区别:
动态链接,生成名为hello的可执行文件 gcc hello.o –o hello # 也可以直接一步生成 gcc hello.c -o hello # 静态链接,使用–static参数 gcc hello.o –o hello_static --static # 也可以直接一步生成 gcc hello.c -o hello_static --static
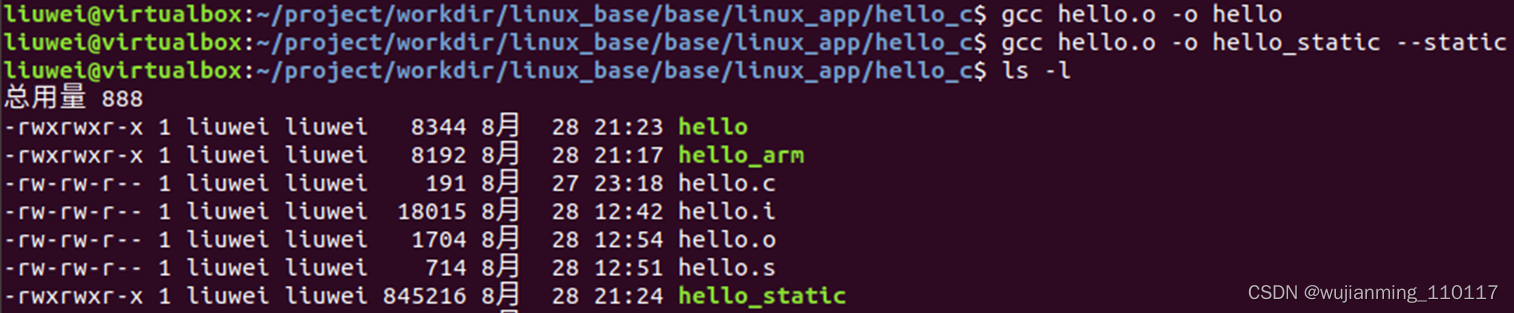
从图中可以看到,使用动态链接生成的hello程序才8.3KB, 而使用静态链接生成的hello_static程序则高达845KB。
在Ubuntu下,可以使用 ldd 工具查看动态文件的库依赖,尝试执行如下命令:
可以看到,动态链接生成的hello程序依赖于库文件:
linux-vdso.so.1、libc.so.6 以及ld-linux-x86-64.so.2,其中的libc.so.6就是C标准代码库。
静态链接生成的hello_static没有依赖外部库文件。
3. 交叉编译
嵌入式开发中一般编译在x86架构平台上,运行在ARM开发板上,这种编译器和目标程序运行在不同架构的编译过程,被称为 交叉编译。
(1)安装ARM-GCC
在主机上执行如下命令 sudo apt install gcc-arm-linux-gnueabihf # 安装完成后使用如下命令查看版本 arm-linux-gnueabihf-gcc –v
安装完成后可以查看ARM-GCC工具链Binutils的各种工具:
(2)交叉编译程序
交叉编译器与本地编译器使用起来并没有多大区别。
执行编译命令arm-linux-gnueabihf-gcc hello.c –o hello_arm
同样的C代码文件,使用交叉编译器编译后,就可以在ARM平台上运行。
可以通过readelf工具来查看具体的程序信息:
以下命令在主机上运行 readelf -a hello_arm
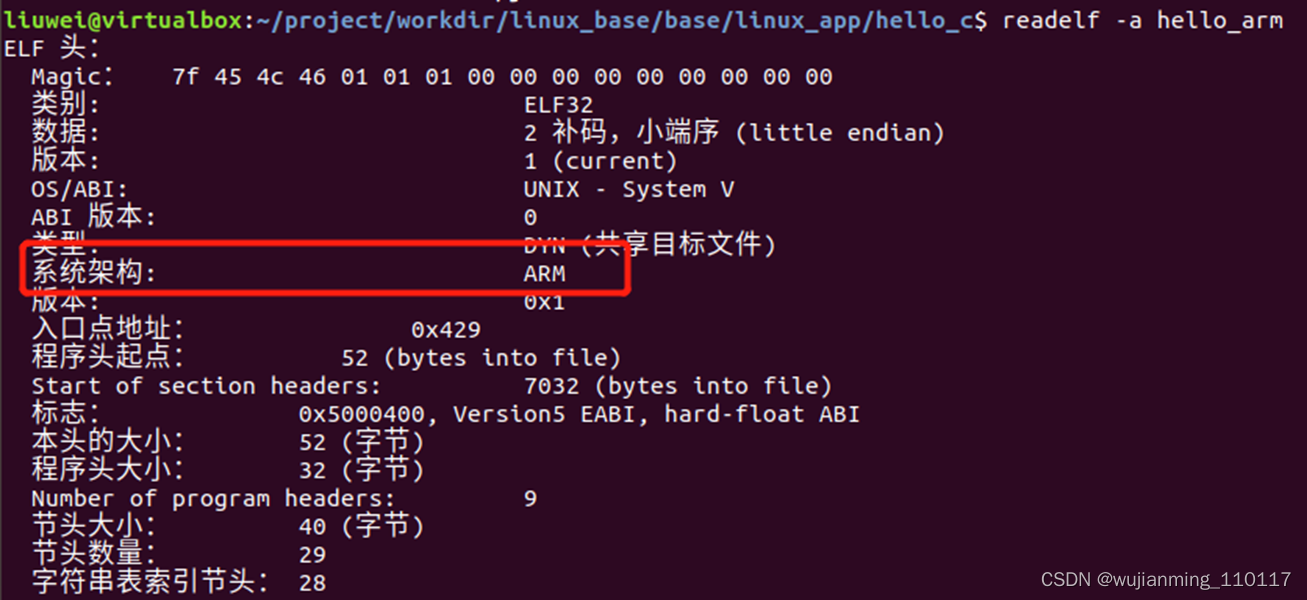
最后把hello_arm通过NFS拷贝到开发板上,就能手动运行了。
(3)GCC编译器命名格式
以上安装的是:arm-linux-gnueabihf-gcc编译器,编译器还有很多版本如:arm-linux-gnueabi-gcc。
编译器有一定的命名规则:
arch [-os] [-(gnu)eabi(hf)] -gcc
其中的各字段如下表所示:
字段 含义
arch 目标芯片架构
os 操作系统
gnu C标准库类型
eabi 应用二进制接口
hf 浮点模式
以 arm-linux-gnueabihf-gcc 编译器为例:
• arm:表示目标芯片架构为ARM
• linux:目标操作系统为Linux
• gnu:使用GNU的C标准库即glibc
• eabi:使用嵌入式应用二进制接口(eabi)
• hf:编译器的浮点模式为硬浮点hard-float
以上是GCC的概念和基本使用。
理解 GCC
一、GPL 的诞生直到 1985 年由 MIT 教授理查德·斯托曼(Richard Stallman)提出应将软件源码看成人类共同拥有的知识财富,应该公开地自由交换、修改,提出了 GNU 计划(因英文名相同,GNU 的 logo 就是一只牛羚),并建立了自由软件基金会;同时,发布了一份举足轻重的法律文件,GNU 通用公共授权书(GNU GPL,GNU General Public License)。
GPL 协议的核心就是要对源码进行公开,并且允许任何人修改源码,但是只要使用了 GPL 协议的软件源码,其衍生软件也必须公开源码,准许其他人阅读和修改源码,即 GPL 协议具有继承性。
另一个问题就是 GPL 软件并非就是免费软件,这里所说的自由软件是指对软件源码的自由获得与自由使用、修改,软件开发者不但可以通过服务来收费,而且还可以通过出售 GPL 软件来获利。
适应 GPL 协议的软件一般都是自由软件,自由软件是指一件可以让用户自由复制、使用、研究、修改、分发等,而不附带任何条件的软件。
至此,在 GPL 下人们就可以自由交流、修改软件源码了,这一协议极大地推动了整个计算机软件行业的发展。
二、COPYLEFT 授权Stallman 为了停止中间人对自由软件权利的侵害,提出了 COPYLEFT 授权,因为自由软件在发布过程中可能会有一些不合作的人通过对程序的修改而将软件变成私有软件,将程序变成 COPYLEFT 授权。首先声明是有版权的,而后加入了分发条款,这些条款是法律指导,使得任何人都拥有对这一程序代码或者任何这一程序的衍生品的使用、修改和重新发布的权力,但前提是这些发布条款不能被改变。这样在法律上,代码和自由就不可分割了。
三、GNU项目
GNU 项目计划的主要目的是创建一个名叫 GNU’s Not Unix(GNU) 的完全免费的操作系统。该操作系统将包括绝大多数自由软件基金会所开发的其他软件,以对抗所有商业软件,而这个操作系统的核心(kernel)就叫 HURD。但是 GNU 在开发完全免费的操作系统上并未取得成功,直到 20 世纪 90 年代由林纳斯·本纳第克特·托瓦兹(Linus Benedict Torvalds)开发了 Linux 操作系统,GNU 才算在免费操作系统上完成了任务。虽然 GNU 计划在开发操作系统上不成功,但是却开发出了很多系统级的自由软件,其中最著名的是 GNU C Complier(gcc)。
四、关于 GCCGCC 的与一般的编译器相比平均执行效率要高出 20%~30%。这使得那些靠贩卖编译器的公司大吃苦头,因为无法研制出与 GCC 同样优秀,却又完全免费、并开放源代码的编译器来。同时,GCC使用的是 COPYLEFT 授权。当然,最具有意义和特殊的还是几乎所有的自由软件都是通过编译的。可以说,是自由软件发展的基石与标杆。截止到2021年8月, GCC 最新的释出版本是 11.2 。现在编译性能会直接影响到 Linux、Firefox、OpenOffice.org、Apache 以及一些数不清的各种开源项目的开发。GCC 不仅功能非常强大,结构也异常灵活。最值得称道的一点就是,可以通过不同的前端模块来支持各种语言,如 Java、Fortran、Pascal、Modula-3 和 Ada 语言等。
五、GCC编译器套件
自从面世后,GCC 逐渐扩充、发展,现在不仅仅支持 C 语言,还支持其他很多语言,包括 C++、Objective-C、Fortran、Ada、Go、D和 Java等。因此,GCC 的意思被重新定义为“GNU Compiler Collection”,也即“GUN 编译器套件”。GUN 编译器套件包含多种前端处理器,以翻译各种不同语言。GCC 也是一种多目标(multitarget)编译器;换句话说,通过使用可互换的后端处理器,为多种不同的计算机架构生成相应的可执行程序。正如模块化概念所提倡的,GCC 可被用作交互式编译器;也就是说,可以使用 GCC 对所有设备与操作系统创建可执行程序,不需要局限于仅仅是运行 GCC 的平台。然而,这么做需要特殊的配置和安装,大多数 GCC 的安装,仅能针对宿主系统编译程序。GCC 不仅支持C的许多“方言”,也可以区别不同的C语言标准;也就是说,可以使用命令行选项来控制编译器在翻译源代码时应该遵循哪个C标准。例如,当使用命令行参数 -std=c99 启动 GCC 时,编译器支持 C99 标准。GCC 对 C11 标准的支持是不完整的,尤其是涉及定义在头文件 threads.h 中的多线程函数。这是因为,GCC 的C链接库长期以来支持 POSIX 标准下与 C11 标准非常相似的多线程功能。
六、GCC编译器使用
$ sudo apt install gcc //安装gcc
$ gcc --version //查看gcc版本
$ gedit main.c //编写c
#include <stdio.h>
int main(){ puts(“这个是demo”); return 0;}
$ gcc -g -o main main.c //编译源码为可执行文件,参数g表示生成调试信息,该程序可以被调试器调试,这样可以保留源码文字信息,便于调试,参数o表示输出
详解命令-GCC
gcc命令使用GNU推出的基于C/C++的编译器,是开放源代码领域应用最广泛的编译器,具有功能强大,编译代码支持性能优化等特点。现在很多程序员都应用GCC,怎样才能更好的应用GCC。目前,GCC可以用来编译C/C++、FORTRAN、JAVA、OBJC、ADA等语言的程序,可根据需要选择安装支持的语言。
语法
gcc(选项)(参数)
选项
-o:指定生成的输出文件;
-E:仅执行编译预处理;
-S:将C代码转换为汇编代码;
-wall:显示警告信息;
-c:仅执行编译操作,不进行连接操作。
参数
C源文件:指定C语言源代码文件。
实例
常用编译命令选项
假设源程序文件名为test.c
无选项编译链接
gcc test.c
将test.c预处理、汇编、编译并链接形成可执行文件。这里未指定输出文件,默认输出为a.out。
选项 -o
gcc test.c -o test
将test.c预处理、汇编、编译并链接形成可执行文件test。-o选项用来指定输出文件的文件名。
选项 -E
gcc -E test.c -o test.i
将test.c预处理输出test.i文件。
选项 -S
gcc -S test.i
将预处理输出文件test.i汇编成test.s文件。
选项 -c
gcc -c test.s
将汇编输出文件test.s编译输出test.o文件。
无选项链接
gcc test.o -o test
将编译输出文件test.o链接成最终可执行文件test。
选项 -O
gcc -O1 test.c -o test
使用编译优化级别1编译程序。级别为1~3,级别越大优化效果越好,但编译时间越长。
多源文件的编译方法
如果有多个源文件,基本上有两种编译方法:
假设有两个源文件为test.c和testfun.c
多个文件一起编译
gcc testfun.c test.c -o test
将testfun.c和test.c分别编译后链接成test可执行文件。
分别编译各个源文件,之后对编译后输出的目标文件链接。
gcc -c testfun.c #将testfun.c编译成testfun.o
gcc -c test.c #将test.c编译成test.o
gcc -o testfun.o test.o -o test #将testfun.o和test.o链接成test
以上两种方法相比较,第一中方法编译时需要所有文件重新编译,而第二种方法可以只重新编译修改的文件,未修改的文件不用重新编译。
关于GCC 的介绍
一、什么是Gcc
Linux系统下的Gcc(GNU C Compiler)是GNU推出的功能强大、性能优越的多平台编译器,是GNU的代表作品之一。gcc是可以在多种硬体平台上编译出可执行程序的超级编译器,其执行效率与一般的编译器相比平均效率要高20%~30%。
Gcc编译器能将C、C++语言源程序、汇程式化序和目标程序编译、连接成可执行文件,如果没有给出可执行文件的名字,gcc将生成一个名为a.out的文件。在Linux系统中,可执行文件没有统一的后缀,系统从文件的属性来区分可执行文件和不可执行文件。
二、gcc所遵循的部分约定规则
前面提到便宜的后缀问题,而gcc则通过后缀来区别输入文件的类别,下面来介绍gcc所遵循的部分约定规则。
• .c为后缀的文件,C语言源代码文件;
• .a为后缀的文件,是由目标文件构成的档案库文件;
• .C或.cc或.cxx为后缀的文件,是C++源代码文件;
• .h为后缀的文件,是程序所包含的头文件;
• .i为后缀的文件,是已经预处理过的C源代码文件;
• .ii为后缀的文件,是已经预处理过的C++源代码文件;
• .m为后缀的文件,是Objective-C源代码文件;
• .o为后缀的文件,是编译后的目标文件;
• .s为后缀的文件,是汇编语言源代码文件;
• .S为后缀的文件,是经过预编译的汇编语言源代码文件。
三、Gcc的执行过程
虽然称Gcc是C语言的编译器,但使用gcc由C语言源代码文件生成可执行文件的过程不仅仅是编译的过程,而是要经历四个相互关联的步骤∶预处理(也称预编译,Preprocessing)、编译(Compilation)、汇编(Assembly)和连接(Linking)。
• 命令gcc首先调用cpp进行预处理,在预处理过程中,对源代码文件中的文件包含(include)、预编译语句(如宏定义define等)进行分析。
• 接着调用cc1进行编译,这个阶段根据输入文件生成以.o为后缀的目标文件。汇编过程是针对汇编语言的步骤,调用as进行工作,一般来讲,.S为后缀的汇编语言源代码文件和汇编、.s为后缀的汇编语言文件经过预编译和汇编之后都生成以.o为后缀的目标文件。
• 当所有的目标文件都生成之后,gcc就调用ld来完成最后的关键性工作,这个阶段就是连接。在连接阶段,所有的目标文件被安排在可执行程序中的恰当的位置,同时,该程序所调用到的库函数也从各自所在的档案库中连到合适的地方。
四、Gcc的基本用法和选项
在使用Gcc编译器的时候,必须给出一系列必要的调用参数和文件名称。Gcc编译器的调用参数大约有100多个,其中多数参数可能根本就用不到,这里只介绍其中最基本、最常用的参数
Gcc最基本的用法是∶gcc[options] [filenames] ,其中options就是编译器所需要的参数,filenames给出相关的文件名称。
五、Gcc的参数选项
-c,只编译,不连接成为可执行文件,编译器只是由输入的.c等源代码文件生成.o为后缀的目标文件,通常用于编译不包含主程序的子程序文件。
-o output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出预设的可执行文件a.out。
-g,产生符号调试工具(GNU的gdb)所必要的符号资讯,要想对源代码进行调试,就必须加入这个选项。
-O,对程序进行优化编译、连接,采用这个选项,整个源代码会在编译、连接过程中进行优化处理,这样产生的可执行文件的执行效率可以提高,但是,编译、连接的速度就相应地要慢一些。
-O2,比-O更好的优化编译、连接,当然整个编译、连接过程会更慢。
-Idirname,将dirname所指出的目录加入到程序头文件目录列表中,是在预编译过程中使用的参数。
汇编语言—GCC内联汇编
GCC支持在C/C++代码中嵌入汇编代码,这些代码被称作是"GCC Inline ASM"(GCC内联汇编);
一、基本内联汇编
GCC中基本的内联汇编非常易懂,格式如下:
asm [volatile] (“instruction list”);
其中,
1.asm:
是GCC定义的关键字asm的宏定义(#define asm asm),用来声明一个内联汇编表达式,所以,任何一个内联汇编表达式都以此开头,是必不可少的;如果要编写符合ANSI C标准的代码(即:与ANSI C兼容),那就要使用__asm__;
2.volatile:
是GCC关键字volatile的宏定义;这个选项是可选的;向GCC声明"不要动所写的instruction list,需要原封不动地保留每一条指令";如果不使用__volatile__,则当使用了优化选项-O进行优化编译时,GCC将会根据自己的判断来决定是否将这个内联汇编表达式中的指令优化掉;如果要编写符合ANSI C标准的代码(即:与ANSI C兼容),那就要使用__volatile__;
3.instruction list:
是汇编指令列表;可以是空列表,比如:asmvolatile(“”);或__asm__(“”);都是合法的内联汇编表达式,只不过这两条语句什么都不做,没有什么意义;但并非所有"instruction list"为空的内联汇编表达式都是没意义的,比如:asm(“”:::“memory”);就是非常有意义的,向GCC声明:“对内存做了改动”,这样,GCC在编译的时候,就会将此因素考虑进去;
例如:
asm(“movl %esp,%eax”);
或者是
asm(“movl $1,%eax xor %ebx,%ebx int $0x80”);
或者是
asm(“movl $1,%eax\n\t”\ “xor %ebx,%ebx\n\t”\ “int $0x80”);
instruction list的编写规则:当指令列表里面有多条指令时,可以在一对双引号中全部写出,也可将一条或多条指令放在一对双引号中,所有指令放在多对双引号中;如果是将所有指令写在一对双引号中,那么,相邻俩条指令之间必须用分号";"或换行符(\n)隔开,如果使用换行符(\n),通常\n后面还要跟一个\t;或者是相邻两条指令分别单独写在两行中;
规则1:任意两条指令之间要么被分号(;)或换行符(\n)或(\n\t)分隔开,要么单独放在两行;
规则2:单独放在两行的方法既可以通过\n或\n\t的方法来实现,也可以真正地放在两行;
规则3:可以使用1对或多对双引号,每1对双引号里面可以放1条或多条指令,所有的指令都要放在双引号中;
例如,下面的内联汇编语句都是合法的:
asm(“movl %eax,%ebx sti popl %edi subl %ecx,%ebx”);asm(“movl %eax,%ebx; sti popl %edi; subl %ecx,%ebx”);asm(“movl %eax,%ebx; sti\n\t popl %edi subl %ecx,%ebx”);
如果将指令放在多对双引号中,则,除了最后一对双引号之外,前面的所有双引号里的最后一条指令后面都要有一个分号(;)或(\n)或(\n\t);比如,下面的内联汇编语句都是合法的:
asm(“movl %eax,%ebx sti\n” “popl %edi;” “subl %ecx,%bx”);asm(“movl %eax,%ebx; sti\n\t” “popl %edi; subl %ecx,%ebx”);asm(“movl %eax,%ebx; sti\n\t popl %edi\n” “subl %ecx,%ebx”);
二、带有C/C++表达式的内联汇编
GCC允许通过C/C++表达式指定内联汇编中"instruction list"中的指令的输入和输出,甚至可以不关心到底使用哪些寄存器,完全依靠GCC来安排和指定;这一点可以让程序员免去考虑有限的寄存器的使用,也可以提高目标代码的效率;
1.带有C/C++表达式的内联汇编语句的格式:
asm [volatile](“instruction list”:Output:Input:Clobber/Modify);
圆括号中的内容被冒号":“分为四个部分:
A.如果第四部分的"Clobber/Modify"可以为空;如果"Clobber/Modify"为空,则其前面的冒号(:)必须省略;比如:语句__asm__(“movl %%eax,%%ebx”:”=b"(foo):“a”(inp);是非法的,而语句__asm__(“movl %%eax,%%ebx”:“=b”(foo):“a”(inp));则是合法的;
B.如果第一部分的"instruction list"为空,则input、output、Clobber/Modify可以为空,也可以不为空;比如,语句__asm__(“”:::“memory”);和语句__asm__(“”:;都是合法的写法;
C.如果Output、Input和Clobber/Modify都为空,那么,Output、Input之前的冒号(:)可以省略,也可以不省略;如果都省略,则此汇编就退化为一个基本汇编,否则,仍然是一个带有C/C++表达式的内联汇编,此时"instruction list"中的寄存器的写法要遵循相关规定,比如:寄存器名称前面必须使用两个百分号(%%);基本内联汇编中的寄存器名称前面只有一个百分号(%);比如,语句__asm__(“movl %%eax,%%ebx”:;asm(“movl %%eax,%%ebx”;和语句__asm__(“movl %%eax,%%ebx”);都是正确的写法,而语句__asm__(“movl %eax,%ebx”:;asm(“movl %eax,%ebx”;和语句__asm__(“movl %%eax,%%ebx”);都是错误的写法;
D.如果Input、Clobber/Modify为空,但Output不为空,则,Input前面的冒号(:)可以省略,也可以不省略;比如,语句__asm__(“movl %%eax,%%ebx”:“=b”(foo);和语句__asm__(“movl %%eax,%%ebx”:“=b”(foo));都是正确的;
E.如果后面的部分不为空,而前面的部分为空,则,前面的冒号(:)都必须保留,否则无法说明不为空的部分究竟是第几部分;比如,Clobber/Modify、Output为空,而Input不为空,则Clobber/Modify前面的冒号必须省略,而Output前面的冒号必须保留;如果Clobber/Modify不为空,而Input和Output都为空,则Input和Output前面的冒号都必须保留;比如,语句__asm__(“movl %%eax,%%ebx”::“a”(foo));和__asm__(“movl %%eax,%%ebx”:::“ebx”);
注意:基本内联汇编中的寄存器名称前面只能有一个百分号(%),而带有C/C++表达式的内联汇编中的寄存器名臣前面必须有两个百分号(%%);
2.Output:
Output部分用来指定当前内联汇编语句的输出,称为输出表达式;
格式为: “操作约束”(输出表达式)
例如:
asm(“movl %%rc0,%1”:“=a”(cr0));
这个语句中的Output部分就是(“=a”(cr0)),是一个操作表达式,指定了一个内联汇编语句的输出部分;
Output部分由两个部分组成:由双引号括起来的部分和由圆括号括起来的部分,这两个部分是一个Output部分所不可缺少的部分;
用双引号括起来的部分就是C/C++表达式,用于保存当前内联汇编语句的一个输出值,其操作就是C/C++赋值语句"=“的左值部分,因此,圆括号中指定的表达式只能是C/C++中赋值语句的左值表达式,即:放在等号=左边的表达式;也就是说,Output部分只能作为C/C++赋值操作左边的表达式使用;
用双引号括起来的部分就指定了C/C++中赋值表达式的右值来源;这个部分被称作是"操作约束”(Operation Constraint),也可以称为"输出约束";在这个例子中的操作约束是"=a",这个操作约束包含两个组成部分:等号(=)和字母a,其中,等号(=)说明圆括号中的表达式cr0是一个只写的表达式,只能被用作当前内联汇编语句的输出,而不能作为输入;字母a是寄存器EAX/AX/AL的缩写,说明cr0的值要从寄存器EAX中获取,也就是说cr0=eax,最终这一点被转化成汇编指令就是:movl %eax,address_of_cr0;
注意:很多文档中都声明,所有输出操作的的操作约束都必须包含一个等号(=),但是GCC的文档中却明确地声明,并非如此;因为等号(=)约束说明当前的表达式是一个只写的,但是还有另外一个符号:加号(+),也可以用来说明当前表达式是可读可写的;如果一个操作约束中没有给出这两个符号中的任何一个,则说明当前表达式是只读的;因此,对于输出操作来说,肯定必须是可写的,而等号(=)和加号(+)都可表示可写,只不过加号(+)同时也可以表示可读;所以,对于一个输出操作来说,其操作约束中只要包含等号(=)或加号(+)中的任意一个就可以了;
等号(=)与加号(+)的区别:等号(=)表示当前表达式是一个纯粹的输出操作,而加号(+)则表示当前表达式不仅仅是一个输出操作,还是一个输入操作;但无论是等号(=)还是加号(+),所表示的都是可写,只能用于输出,只能出现在Output部分,而不能出现在Input部分;
在Output部分可以出现多个输出操作表达式,多个输出操作表达式之间必须用逗号(,)隔开;
3、Input:
Input部分用来指定当前内联汇编语句的输入;称为输入表达式;
格式为: “操作约束”(输入表达式)
例如:
asm(“movl %0,%%db7”::“a”(cpu->db7));
其中,表达式"a"(cpu->db7)就称为输入表达式,用于表示一个对当前内联汇编的输入;
Input同样也由两部分组成:由双引号括起来的部分和由圆括号括起来的部分;这两个部分对于当前内联汇编语句的输入来说也是必不可少的;
在这个例子中,由双引号括起来的部分是"a",用圆括号括起来的部分是(cpu->db7);
用双引号括起来的部分就是C/C++表达式,为当前内联汇编语句提供一个输入值;在这里,圆括号中的表达式cpu->db7是一个C/C++语言的表达式,不必是左值表达式,也就是说,不仅可以是放在C/C++赋值操作左边的表达式,还可以是放在C/C++赋值操作右边的表达式;所以,Input可以是一个变量、一个数字,还可以是一个复杂的表达式(如:a+b/c*d);
比如,上例还可以这样写:
asm(“movl %0,%%db7”::“a”(foo));asm(“movl %0,%%db7”::“a”(0x12345));asm(“movl %0,%%db7”::“a”(va:vb/vc));
用双引号括起来的部分就是C/C++中赋值表达式的右值表达式,用于约束当前内联汇编语句中的当前输入;这个部分也成为"操作约束",也可以成为是"输入约束";与输出表达式中的操作约束不同的是,输入表达式中的操作约束不允许指定等号(=)约束或加号(+)约束,也就是说,只能是只读的;约束中必须指定一个寄存器约束;例子中的字母a表示当前输入变量cpu->db7要通过寄存器EAX输入到当前内联汇编语句中;
三、操作约束:Operation Constraint
操作约束只会出现在带有C/C++表达式的内联汇编语句中;
每一个Input和Output表达式都必须指定自己的操作约束Operation Constraint;约束的类型有:寄存器约束、内存约束、立即数约束、通用约束;
操作表达式的格式:
“约束”(C/C++表达式)
即:“Constraint”(C/C++ expression)
1.寄存器约束:
当输入或输出需要借助于一个寄存器时,需要为其指定一个寄存器约束;
可以直接指定一个寄存器名字;比如:
asmvolatile(“movl %0,%%cr0”::“eax”(cr0));
也可以指定寄存器的缩写名称;比如:
asmvolatile(“movl %0,%%cr0”::“a”(cr0));
如果指定的是寄存器的缩写名称,比如:字母a;那么,GCC将会根据当前操作表达式中C/C++表达式的宽度来决定使用%eax、%ax还是%al;比如:
unsigned short __shrt;asmvolatile(“movl %0,%%bx”::“a”(__shrt));
由于变量__shrt是16位无符号类型m大小是两个字节,所以,编译器编译出来的汇编代码中,则会让此变量使用寄存器%ax;
无论是Input还是Output操作约束,都可以使用寄存器约束;
常用的寄存器约束的缩写:
r:I/O,表示使用一个通用寄存器,由GCC在%eax/%ax/%al、%ebx/%bx/%bl、%ecx/%cx/%cl、%edx/%dx/%dl中选取一个GCC认为是合适的;
q:I/O,表示使用一个通用寄存器,与r的意义相同;
g:I/O,表示使用寄存器或内存地址;
m:I/O,表示使用内存地址;
a:I/O,表示使用%eax/%ax/%al;
b:I/O,表示使用%ebx/%bx/%bl;
c:I/O,表示使用%ecx/%cx/%cl;
d:I/O,表示使用%edx/%dx/%dl;
D:I/O,表示使用%edi/%di;
S:I/O,表示使用%esi/%si;
f:I/O,表示使用浮点寄存器;
t:I/O,表示使用第一个浮点寄存器;
u:I/O,表示使用第二个浮点寄存器;
A:I/O,表示把%eax与%edx组合成一个64位的整数值;
o:I/O,表示使用一个内存位置的偏移量;
V:I/O,表示仅仅使用一个直接内存位置;
i:I/O,表示使用一个整数类型的立即数;
n:I/O,表示使用一个带有已知整数值的立即数;
F:I/O,表示使用一个浮点类型的立即数;
2.内存约束:
如果一个Input/Output操作表达式的C/C++表达式表现为一个内存地址(指针变量),不想借助于任何寄存器,则可以使用内存约束;比如:
asm(“lidt %0”:“=m”(idt_addr));或__asm(“lidt %0”::“m”(__idt_addr));
内存约束使用约束名"m",表示的是使用系统支持的任何一种内存方式,不需要借助于寄存器;
使用内存约束方式进行输入输出时,由于不借助于寄存器,所以,GCC不会按照声明对其做任何的输入输出处理;GCC只会直接拿来使用,对这个C/C++表达式而言,究竟是输入还是输出,完全依赖于写在"instruction list"中的指令对其操作的方式;所以,不管把操作约束和操作表达式放在Input部分还是放在Output部分,GCC编译生成的汇编代码都是一样的,程序的执行结果也都是正确的;本来将一个操作表达式放在Input或Output部分是希望GCC能为自动通过寄存器将表达式的值输入或输出;既然对于内存约束类型的操作表达式来说,GCC不会为做任何事情,那么放在哪里就无所谓了;但是从程序员的角度来看,为了增强代码的可读性,最好能够放在符合实际情况的地方;
3.立即数约束:
如果一个Input/Output操作表达式的C/C++表达式是一个数字常数,不想借助于任何寄存器或内存,则可以使用立即数约束;
由于立即数在C/C++表达式中只能作为右值使用,所以,对于使用立即数约束的表达式而言,只能放在Input部分;比如:
asmvolatile(“movl %0,%%eax”::“i”(100));
立即数约束使用约束名"i"表示输入表达式是一个整数类型的立即数,不需要借助于任何寄存器,只能用于Input部分;使用约束名"F"表示输入表达式是一个浮点数类型的立即数,不需要借助于任何寄存器,只能用于Input部分;
4.通用约束:
约束名"g"可以用于输入和输出,表示可以使用通用寄存器、内存、立即数等任何一种处理方式;
约束名"0,1,2,3,4,5,6,7,8,9"只能用于输入,表示与第n个操作表达式使用相同的寄存器/内存;
通用约束"g"是一个非常灵活的约束,当程序员认为一个C/C++表达式在实际操作中,无论使用寄存器方式、内存方式还是立即数方式都无所谓时,或者程序员想实现一个灵活的模板,以让GCC可以根据不同的C/C++表达式生成不同的访问方式时,就可以使用通用约束g;
例如:
#define JUST_MOV(foo) asm(“movl %0,%%eax”::“g”(foo))
则,JUST_MOV(100)和JUST_MOV(var)就会让编译器产生不同的汇编代码;
对于JUST_MOV(100)的汇编代码为:
#APP
movl $100,%eax #立即数方式;
#NO_APP
对于JUST_MOV(var)的汇编代码为:
#APP
movl 8(%ebp),%eax #内存方式;
#NO_APP
像这样的效果,就是通用约束g的作用;
5.修饰符:
等号(=)和加号(+)作为修饰符,只能用于Output部分;等号(=)表示当前输出表达式的属性为只写,加号(+)表示当前输出表达式的属性为可读可写;这两个修饰符用于约束对输出表达式的操作,俩被写在输出表达式的约束部分中,并且只能写在第一个字符的位置;
符号&也写在输出表达式的约束部分,用于约束寄存器的分配,但是只能写在约束部分的第二个字符的位置上;
用符号&进行修饰时,等于向GCC声明:“GCC不得为任何Input操作表达式分配与此Output操作表达式相同的寄存器”;
其原因是修饰符&意味着被其修饰的Output操作表达式要在所有的Input操作表达式被输入之前输出;
即:GCC会先使用输出值对被修饰符&修饰的Output操作表达式进行填充,然后,才对Input操作表达式进行输入;
这样的话,如果不使用修饰符&对Output操作表达式进行修饰,一旦后面的Input操作表达式使用了与Output操作表达式相同的寄存器,就会产生输入输出数据混乱的情况;相反,如果没有用修饰符&修饰输出操作表达式,那么,就意味着GCC会先把Input操作表达式的值输入到选定的寄存器中,然后经过处理,最后才用输出值填充对应的Output操作表达式;
所以,修饰符&的作用就是要求GCC编译器为所有的Input操作表达式分配别的寄存器,而不会分配与被修饰符&修饰的Output操作表达式相同的寄存器;修饰符&也写在操作约束中,即:&约束;由于GCC已经规定加号(+)或等号(=)占据约束的第一个字符,那么&约束只能占用第二个字符;
例如:
int __out, __in1, __in2;asm(“popl %0\n\t” “movl %1,%%esi\n\t” “movl %2,%%edi\n\t” :“=&a”(__out) :“r”(__in1),“r”(__in2));
注意:如果一个Output操作表达式的寄存器约束被指定为某个寄存器,只有当至少存在一个Input操作表达式的寄存器约束为可选约束(意思是GCC可以从多个寄存器中选取一个,或使用非寄存器方式)时,比如"r"或"g"时,此Output操作表达式使用符号&修饰才有意义;如果为所有的Input操作表达式指定了固定的寄存器,或使用内存/立即数约束时,则此Output操作表达式使用符号&修饰没有任何意义;
比如:
asm(“popl %0\n\t” “movl %1,%esi\n\t” “movl %2,%edi\n\t” :“=&a”(__out) :“m”(__in1),“c”(__in2));
此例中的Output操作表达式完全没有必要使用符号&来修饰,因为__in1和__in2都已经被指定了固定的寄存器,或使用了内存方式,GCC无从选择;
如果已经为某个Output操作表达式指定了修饰符&,并指定了固定的寄存器,那么,就不能再为任何Input操作表达式指定这个寄存器了,否则会出现编译报错;
比如:
asm(“popl %0; movl %1,%%esi; movl %2,%%edi;”:“=&a”(__out):“a”(__in1),“c”(__in2));
对这条语句的编译就会报错;
相反,也可以为Output指定可选约束,比如"r"或"g"等,让GCC为此Output操作表达式选择合适的寄存器,或使用内存方式,GCC在选择的时候,会排除掉已经被Input操作表达式所使用过的所有寄存器,然后在剩下的寄存器中选择,或者干脆使用内存方式;
比如:
asm(“popl %0; movl %1,%%esi; movl %2,%%edi;”:“=&r”(__out):“a”(__in1),“c”(__in2));
这三个修饰符只能用在Output操作表达式中,而修饰符%则恰恰相反,只能用在Input操作表达式中;
修饰符%用于向GCC声明:“当前Input操作表达式中的C/C++表达式可以与下一个Input操作表达式中的C/C++表达式互换”;这个修饰符一般用于符合交换律运算的地方;比如:加、乘、按位与&、按位或|等等;
例如:
asm(“addl %1,%0\n\t”:“=r”(__out):“%r”(__in1),“0”(__in2));
其中,“0”(__in2)表示使用与第一个Input操作表达式(“r”(__in1))相同的寄存器或内存;
由于使用符号%修饰__in1的寄存器方式r,那么就表示,__in1与__in2可以互换位置;加法的两个操作数交换位置之后,和不变;
修饰符 I/O 意义
= O 表示此Output操作表达式是只写的
O 表示此Output操作表达式是可读可写的
& O 表示此Output操作表达式独占为其指定的寄存器
% I 表示此Input操作表达式中的C/C++表达式可以与下一个Input操作表达式中的C/C++表达式互换
四、占位符
每一个占位符对应一个Input/Output操作表达式;
带C/C++表达式的内联汇编中有两种占位符:序号占位符和名称占位符;
1.序号占位符:
GCC规定:一个内联汇编语句中最多只能有10个Input/Output操作表达式,这些操作表达式按照被列出来的顺序依次赋予编号0到9;对于占位符中的数字而言,与这些编号是对应的;比如:占位符%0对应编号为0的操作表达式,占位符%1对应编号为1的操作表达式,依次类推;
由于占位符前面要有一个百分号%,为了去边占位符与寄存器,GCC规定:在带有C/C++表达式的内联汇编语句的指令列表里列出的寄存器名称前面必须使用两个百分号(%%),一区别于占位符语法;
GCC对占位符进行编译的时候,会将每一个占位符替换为对应的Input/Output操作表达式所指定的寄存器/内存/立即数;
例如:
asm(“addl %1,%0\n\t”:“=a”(__out):“m”(__in1),“a”(__in2));
这个语句中,%0对应Output操作表达式"=a"(__out),而"=a"(__out)指定的寄存器是%eax,所以,占位符%0被替换为%eax;占位符%1对应Input操作表达式"m"(__in1),而"m"(__in1)被指定为内存,所以,占位符%1被替换位__in1的内存地址;
用一句话描述:序号占位符就是前面描述的%0、%1、%2、%3、%4、%5、%6、%7、%8、%9;其中,每一个占位符对应一个Input/Output的C/C++表达式;
2.名称占位符:
由于GCC中限制这种占位符的个数最多只能由这10个,这也就限制了Input/Output操作表达式中C/C++表达式的数量做多只能有10个;如果需要的C/C++表达式的数量超过10个,那么,这些需要占位符就不够用了;
GCC内联汇编提供了名称占位符来解决这个问题;即:使用一个名字字符串与一个C/C++表达式对应;这个名字字符串就称为名称占位符;而这个名字通常使用与C/C++表达式中的变量完全相同的名字;
使用名字占位符时,内联汇编的Input/Output操作表达式中的C/C++表达式的格式如下:
[name] “constraint”(变量)
此时,指令列表中的占位符的书写格式如下:
%[name]
这个格式等价于序号占位符中的%0,%1,$2等等;
使用名称占位符时,一个name对应一个变量;
例如:
asm(“imull %[value1],%[value2]” :[value2] “=r”(data2) :[value1] “r”(data1),“0”(data2));
此例中,名称占位符value1就对应变量data1,名称占位符value2对应变量data2;GCC编译的时候,同样会把这两个占位符分别替换成对应的变量所使用的寄存器/内存地址/立即数;而且也增强了代码的可读性;
这个例子,使用序号占位符的写法如下:
asm(“imull %1,%0” :“=r”(data2) :“r”(data1),“0”(data2));
五、寄存器/内存修改标示(Clobber/Modify)
有时候,当想通知GCC当前内联汇编语句可能会对某些寄存器或内存进行修改,希望GCC在编译时能够将这一点考虑进去;那么就可以在Clobber/Modify部分声明这些寄存器或内存;
1.寄存器修改通知:
这种情况一般发生在一个寄存器出现在指令列表中,但又不是Input/Output操作表达式所指定的,也不是在一些Input/Output操作表达式中使用"r"或"g"约束时由GCC选择的,同时,此寄存器被指令列表中的指令所修改,而这个寄存器只供当前内联汇编语句使用的情况;比如:
asm(“movl %0,%%ebx”::“a”(__foo):“bx”);
//这个内联汇编语句中,%ebx出现在指令列表中,并且被指令修改了,但是却未被任何Input/Output操作表达式是所指定,所以,需要在Clobber/Modify部分指定"bx",以让GCC知道这一点;
因为在Input/Output操作表达式中指定的寄存器,或当为一些Input/Output操作表达式使用"r"/“g"约束,让GCC为选择一个寄存器时,GCC对这些寄存器的状态是非常清楚的,知道这些寄存器是被修改的,根本不需要在Clobber/Modify部分声明;但除此之外,GCC对剩下的寄存器中哪些会被当前内联汇编语句所修改则一无所知;所以,如果真的在当前内联汇编指令中修改了,那么就最好在Clobber/Modify部分声明,让GCC针对这些寄存器做相应的处理;否则,有可能会造成寄存器不一致,从而造成程序执行错误;
在Clobber/Modify部分声明这些寄存器的方法很简单,只需要将寄存器的名字用双引号括起来就可以;如果要声明多个寄存器,则相邻两个寄存器名字之间用逗号隔开;
例如:
asm(“movl %0,%%ebx; popl %%ecx”::“a”(__foo):“bx”,“cx”);
这个语句中,声明了bx和cx,告诉GCC:寄存器%ebx和%ecx可能会被修改,要求GCC考虑这个因素;
寄存器名称串:
“al”/“ax”/“eax”:代表寄存器%eax
“bl”/“bx”/“ebx”:代表寄存器%ebx
“cl”/“cx”/“ecx”:代表寄存器%ecx
“dl”/“dx”/“edx”:代表寄存器%edx
“si”/“esi”:代表寄存器%esi
“di”/“edi”:代表寄存器%edi
所以,只需要使用"ax”,“bx”,“cx”,“dx”,“si”,“di"就可以了,因为都代表对应的寄存器;
如果在一个内敛汇编语句的Clobber/Modify部分向GCC声明了某个寄存器内存发生了改变,GCC在编译时,如果发现这个被声明的寄存器的内容在此内联汇编之后还要继续使用,那么,GCC会首先将此寄存器的内容保存起来,然后在此内联汇编语句的相关代码生成之后,再将其内容回复;
另外需要注意的是,如果在Clobber/Modify部分声明了一个寄存器,那么这个寄存器将不能再被用作当前内敛汇编语句的Input/Output操作表达式的寄存器约束,如果Input/Output操作表达式的寄存器约束被指定为"r”/“g”,GCC也不会选择已经被声明在Clobber/Modify部分中的寄存器;
例如:
asm(“movl %0,%%ebx”::“a”(__foo):“ax”,“bx”);
这条语句中的Input操作表达式"a"(__foo)中已经指定了寄存器%eax,那么在Clobber/Modify部分中个列出的"ax"就是非法的;编译时,GCC会报错;
2.内存修改通知:
除了寄存器的内容会被修改之外,内存的内容也会被修改;如果一个内联汇编语句的指令列表中的指令对内存进行了修改,或者在此内联汇编出现的地方,内存内容可能发生改变,而被改变的内存地址没有在其Output操作表达式中使用"m"约束,这种情况下,需要使用在Clobber/Modify部分使用字符串"memory"向GCC声明:“在这里,内存发生了,或可能发生了改变”;
例如:
void* memset(void* s, char c, size_t count){ asm(“cld\n\d” “rep\n\t” “stosb” no output/ :“a",“D”(s),“c”(count) :“cx”,“di”,“memory”); return s;}
如果一个内联汇编语句的Clobber/Modify部分存在"memory”,那么GCC会保证在此内联汇编之前,如果某个内存的内容被装入了寄存器,那么,在这个内联汇编之后,如果需要使用这个内存处的内容,就会直接到这个内存处重新读取,而不是使用被存放在寄存器中的拷贝;因为这个时候寄存器中的拷贝很可能已经和内存处的内容不一致了;
3.标志寄存器修改通知:
当一个内联汇编中包含影响标志寄存器eflags的条件,那么也需要在Clobber/Modify部分中使用"cc"来向GCC声明这一点;
参考文献链接
https://mp.weixin.qq.com/s/-MhkY2FLZ3Tn4eWZZrZ2Ww
https://mp.weixin.qq.com/s/BaATGUQJii_YPwXpc5Dzow
https://mp.weixin.qq.com/s/Y3xyHoMmES_skOHgteB41g
https://mp.weixin.qq.com/s/1g4i64UklWybygT4CR5MTA
https://mp.weixin.qq.com/s/8QXCSrGdOrdzIcTa6VG1Hw
https://mp.weixin.qq.com/s/h6NY1aaxzBcws0c28cbrdQ
边栏推荐
- Redis(十一) - 异步优化秒杀
- Technology empowers Lhasa's "lungs", Huawei helps Lalu Wetland Smart Management to protect lucid waters and lush mountains
- HCIP第十七天
- Double for loop case (use js jiujiu printing multiplication table)
- 科技赋能拉萨之“肺”,华为助力拉鲁湿地智慧管理守护绿水青山
- APT + Transform 实现多模块应用Application生命周期分发
- Nodejs installation tutorial
- MySQL高级语句(一)
- Point Density-Aware Voxels for LiDAR 3D Object Detection Paper Notes
- Ant three sides: MQ message loss, duplication, backlog problem, what are the solutions?
猜你喜欢
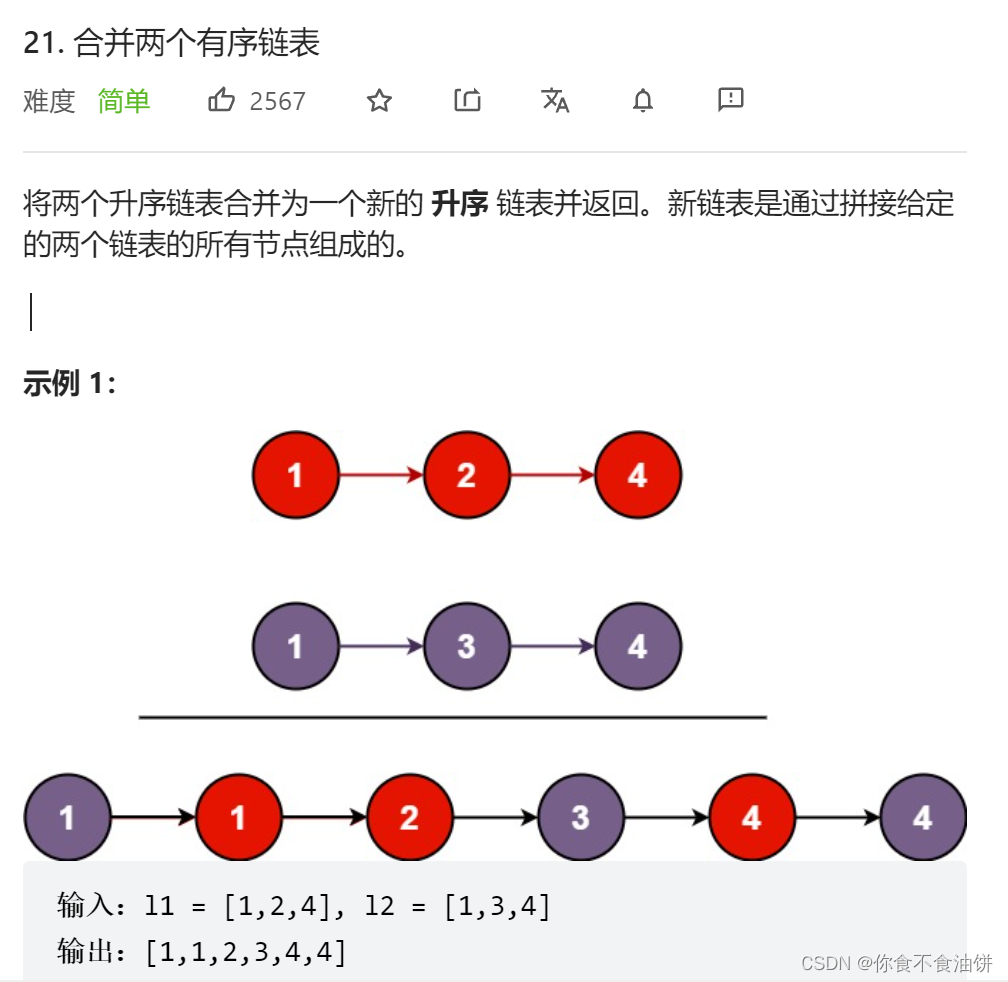
leetcode solves the linked list merge problem in one step

Xgboost报错ValueError:无效的形状:标签(1650 2)

The advantages of making web3d dynamic product display

MySQL 5.7 安装教程(全步骤、保姆级教程)
MySQL 5.7 installation tutorial (full-step, nanny-level tutorial)

npm、nrm两种方式查看源和切换镜像
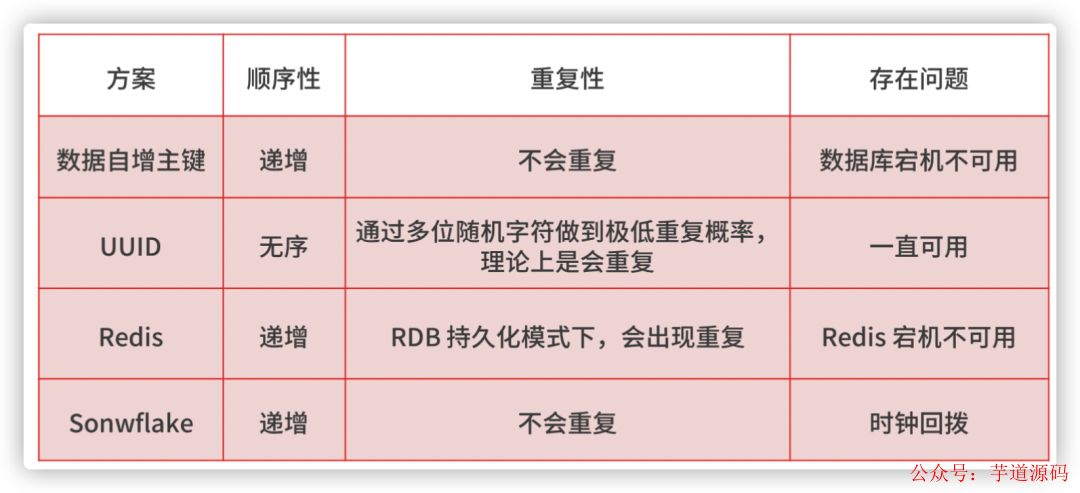
蚂蚁三面:MQ 消息丢失、重复、积压问题,有哪些解决方案?

zabbix邮件报警和微信报警
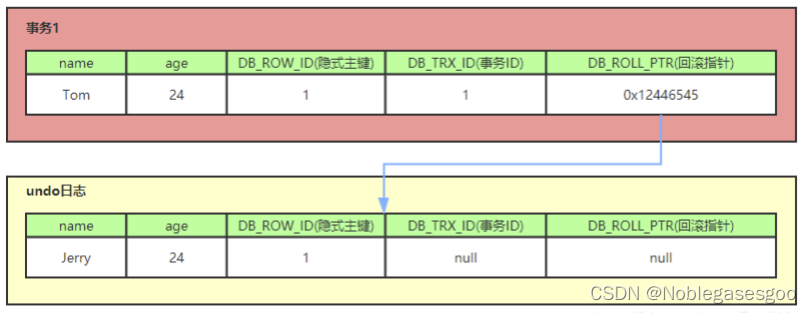
MySQL高级-MVCC(超详细整理)

Node installation and configuration (node-v12.20.2-x64 ) and introduction to node version switching
随机推荐
MySQL(3)
npm 无法将“npm”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。
MarkDown Formula Instruction Manual
node安装及环境变量配置
点云旋转到参考坐标系方向(最小方向包围盒方法)
MySql COUNT statistics function explanation
APP专项测试:流量测试
zabbix email alarm and WeChat alarm
BGP+MPLS Comprehensive Experiment
有人开源全凭“为爱发电”,有人却用开源“搞到了钱”
MySQL Advanced Study Notes
MySQL high-level statements (1)
node安装和配置(node-v12.20.2-x64 ) 以及node版本切换介绍
SphereEx苗立尧:云原生架构下的Database Mesh研发实践
MySql -- 不存在则插入,存在则更新或忽略
nacos安装配置和单机部署教程
Deep learning - CNN realizes the recognition of MNIST handwritten digits
Difference between npm and yarn
Understand C operators in one article
推出 Space On-Premises (本地部署版) Beta 版!