当前位置:网站首页>机器学习2-线性回归
机器学习2-线性回归
2022-06-21 11:05:00 【只是甲】
一. 线性回归概述
1.1 关系
函数关系:确定性关系,y=3+10*x
相关关系:非确定性关系
如下图是一个函数关系
1.2 相关系数
我们使用相关系数去衡量线性相关性的强弱。
下图相关系数为0.9930858:
下图相关系数为0.9573288:
二. 一元线性回归模型
若X与Y之间存在着较强的相关关系,则我们有Y≈α+βX
若α和β的值已知,则给出相应的X值,我们可以根据Y≈α+βX得到相应的Y的预测值

参数:
2.1 如何确定参数
其实就是最小二乘法


2.2 例子
x=c(1,2,3,4),y=c(6,5,7,10)。构建y关于x的回归方程y=α+βx
使用最小二乘法求解参数:
得到y=3.5+1.4x
如果有新的点x=2.5,则我们预测相应的y值为3.5+1.4*2.5=7
2.3 一元线性回归分析
原理:最小二乘法
步骤:建立回归模型,求解回归模型中的参数,对回归模型迚行检验
数据:身高-体重
h=c(171,175,159,155,152,158,154,164,168,166,159,164)
w=c(57,64,41,38,35,44,41,51,57,49,47,46)
plot(w~h+1)

2.3.1 自定义函数关系
假设w=a+bh
自定义函数:
lxy<-function(x,y){n=length(x);sum(x*y)-sum(x)*sum(y)/n}
b=lxy(h,w)/lxy(h,h)
a=mean(w)-b*mean(h)
a
b
# 作回归直线
lines(h,a+b*h)

2.3.2 回归系数的假设检验
建立线性模型
a = lm(w~1+h)
a

线性模型的汇总数据,t检验,summary()函数
汇总数据的解释:
- Residuals:参差分析数据
- Coefficients:回归方程的系数,以及推算的系数的标准差,t值,P-值
- F-statistic:F检验值
- Signif:显著性标记,***极度显著,**高度显著,*显著,圆点不太显著,没有记号不显著
2.3.3 方差分析
函数anova()
2.3.4 预测
预测:一个身高185的人,体重大约是多少?
# 重置一次a的状态
a=mean(w)-b*mean(h)
a+b*185

2.4 lm()线性模拟函数

y~1+x 或 y~x 均表示 y=a+bx 有截距形式的线性模型
通过原点的线性模型可以表达为:y ~ x -1 或y ~ x + 0 或y ~ 0 + x
建立数据及模型:
# 1. 身高-体重
x=c(171,175,159,155,152,158,154,164,168,166,159,164)
y=c(57,64,41,38,35,44,41,51,57,49,47,46)
# 2. 建立线性模型
a=lm(y~x)
# 3. 求模型系数
> coef(a)
(Intercept) x
-140.36436 1.15906
# 4. 提取模型公式
> formula(a)
y ~ x
# 5. 计算残差平方和(什么是残差平方和)
> deviance(a)
[1] 64.82657
# 6. 绘画模型诊断图(很强大,显示残差、拟合值和一些诊断情况)
> plot(a)
# 7. 计算残差
> residuals(a)
1 2 3 4 5 6 7
-0.8349544 1.5288044 -2.9262307 -1.2899895 -0.8128086 1.2328296 2.8690708
8 9 10 11 12
1.2784678 2.6422265 -3.0396529 3.0737693 -3.7215322
# 8. 打印模型信息
> print(a)
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-140.364 1.159
# 9. 计算方差分析表
anova(a)
# 10. 提取模型汇总数据
summary(a)
## 11. 做出预测
z=data.frame(x=185)
predict(a,z)
predict(a,z,interval="prediction", level=0.95)


三.多元线性回归模型
3.1 内推插值不外推归纳
在身高不体重的例子中,我们注意到得到的回归方程中的截距项为-140.364 ,这表示身高为0的人的体重是负值,这明显是不可能的。所以这个回归模型对于儿童和身高特别矮的人不适用。
回归问题擅长于内推插值,而不擅长于外推归纳。在使用回归模型做预测时要注意x适用的取值范围。
销售业绩预测适合使用回归吗?
3.2 多元线性回归模型
当Y值的影响因素不唯一时,采用多元线性回归模型
3.2.1 参数估计
最小二乘法:
不一元回归方程的算法相似
3.2.2 例子
数据集:
Swiss数据集:Swiss Fertility and Socioeconomic Indicators (1888) Data
swiss.lm=lm(Fertility~.,data=swiss)
summary(swiss.lm)

3.2.3 虚拟变量
Boston数据集
Boston数据中,chas是一个虚拟变量,Charles River dummy variable (= 1 if tract bounds river; 0 otherwise).
构建medv关于lstat与chas的回归模型
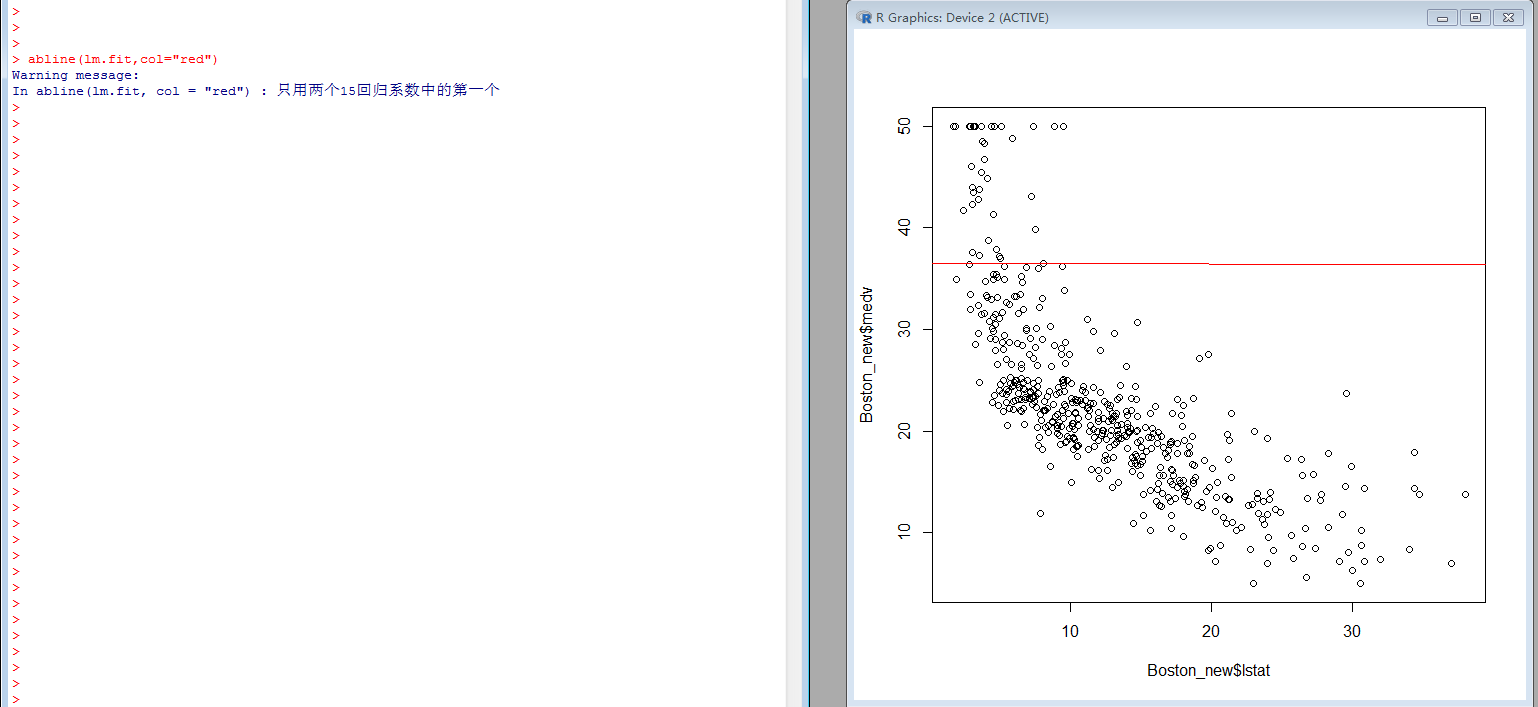
Boston_new <- read.csv("D:/work/Boston.csv", header = TRUE)
lm.fit = lm(medv~., data=Boston_new); summary (lm.fit)
plot(Boston_new$lstat,Boston_new$medv)
abline(lm.fit,col="red")

3.2.4 应该选择哪些变量
多元线性回归的核心问题:应该选择哪些变量?
RSS(残差平方和)与R2(相关系数平方)选择法:遍历所有可能的组合,选出使RSS最小,R2最大的模型
逐步回归:
- 向前引入法:从一元回归开始,逐步增加变量,使指标值达到最优为止
- 向后剔除法:从全变量回归方程开始,逐步删去某个变量,使指标值达到最优为止
- 逐步筛选法:综合上述两种方法
s =lm(Fertility~.,data=swiss)
s1=step(s,direction="forward")
s1=step(s,direction="backward")
s1=step(s,direction="both")

是否还有优化余地?
使用drop1作删除试探,使用add1函数作增加试探
drop(s1)

3.2.5 回归诊断
- 样本是否符合正态分布假设?
- 是否存在离群值导致模型产生较大误差?
- 线性模型是否合理?
- 误差是否满足独立性、等方差、正态分布等假设条件?
- 是否存在多重共线性?
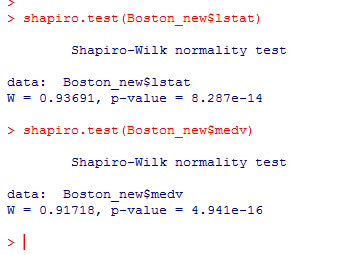
正态性检验:
函数shapiro.test( )
P>0.05,正态性分布
shapiro.test(Boston_new$lstat)
shapiro.test(Boston_new$medv)
残差:
残差计算函数residuals( )
对残差作正态性检验
残差图
多重共线性
多重共线性对回归模型的影响
利用计算特征根发现多重共线性
Kappa()函数
四. 逻辑回归
线性回归和逻辑回归的区别:
线性回归要求因变量必须是连续性数据变量;逻辑回归要求因变量必须是分类变量,二分类或者多分类的;比如要分析性别、年龄、身高、饮食习惯对于体重的影响,如果这个体重是属于实际的重量,是连续性的数据变量,这个时候就用线性回归来做;如果将体重分类,分成了高、中、低这三种体重类型作为因变量,则采用logistic回归。延展回答:逻辑回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w’x+e,e为误差服从均值为0的正态分布。回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
逻辑回归概述:
目标:求出电流强度与牛是否张嘴之间的关系
困难:牛是否张嘴,是0-1变量,不是变量,无法建立线性回归模型
矛盾转化:牛张嘴的概率是连续变量
当要预测的y值不是连续的实数,而是定性变量,例如某个客户是否购买某件商品,这时线性回归模型不能直接应用。
为了让模型适用,我们对p做logistic变换,得到
(其中p表示Y=1的概率)

五. 非线性模型
一个简单的例子
销售额x与流通费率y
x=c(1.5,2.8,4.5,7.5,10.5,13.5,15.1,16.5,19.5,22.5,24.5,26.5)
y=c(7.0,5.5,4.6,3.6,2.9,2.7,2.5,2.4,2.2,2.1,1.9,1.8)
plot(x,y)

5.1 直线回归
( R 2 R^2 R2值不理想)
lm.1=lm(y~x)
summary(lm.1)

5.2 多项式回归
假设用二次多项式方程 y = a + b x + c x 2 y=a+bx+cx^2 y=a+bx+cx2
x1=x
x2=x^2
lm.2=lm(y~x1+x2)
summary(lm.2)
plot(x,y)
lines(x,fitted(lm.2))

5.3 对数法
y=a+b logx
lm.log=lm(y~log(x))
summary(lm.log)
plot(x,y)
lines(x,fitted(lm.log))

5.4 指数法
y = a e b x y=a e^{bx} y=aebx
lm.exp=lm(log(y)~x)
summary(lm.exp)
plot(x,y)
lines(x,exp(fitted(lm.exp)))

5.5 幂函数法
y = a x b y=a x^b y=axb
lm.pow=lm(log(y)~log(x))
summary(lm.pow)
plot(x,y)
lines(x,exp(fitted(lm.pow)))

对比以上各种拟合回归过程得出结论是幂函数法为最佳
六. 案例分析-预测网页流量
6.1 数据源
使用互联网排名前1000的网站的数据:
Rank:排名
PageViews:网站访问量
UniqueVisitor:访问用户数目
HasAdvertising:是否有广告
IsEnglish:主要使用的语言是否为英语
6.2 实际预测
6.2.1 初步预测
install.packages(ggplot2”)
top.1000.sites <- read.csv('E:/top_1000_sites.tsv', sep = '\t', stringsAsFactors = FALSE)
library(ggplot2)
ggplot(top.1000.sites, aes(x = PageViews, y = UniqueVisitors)) + geom_point()
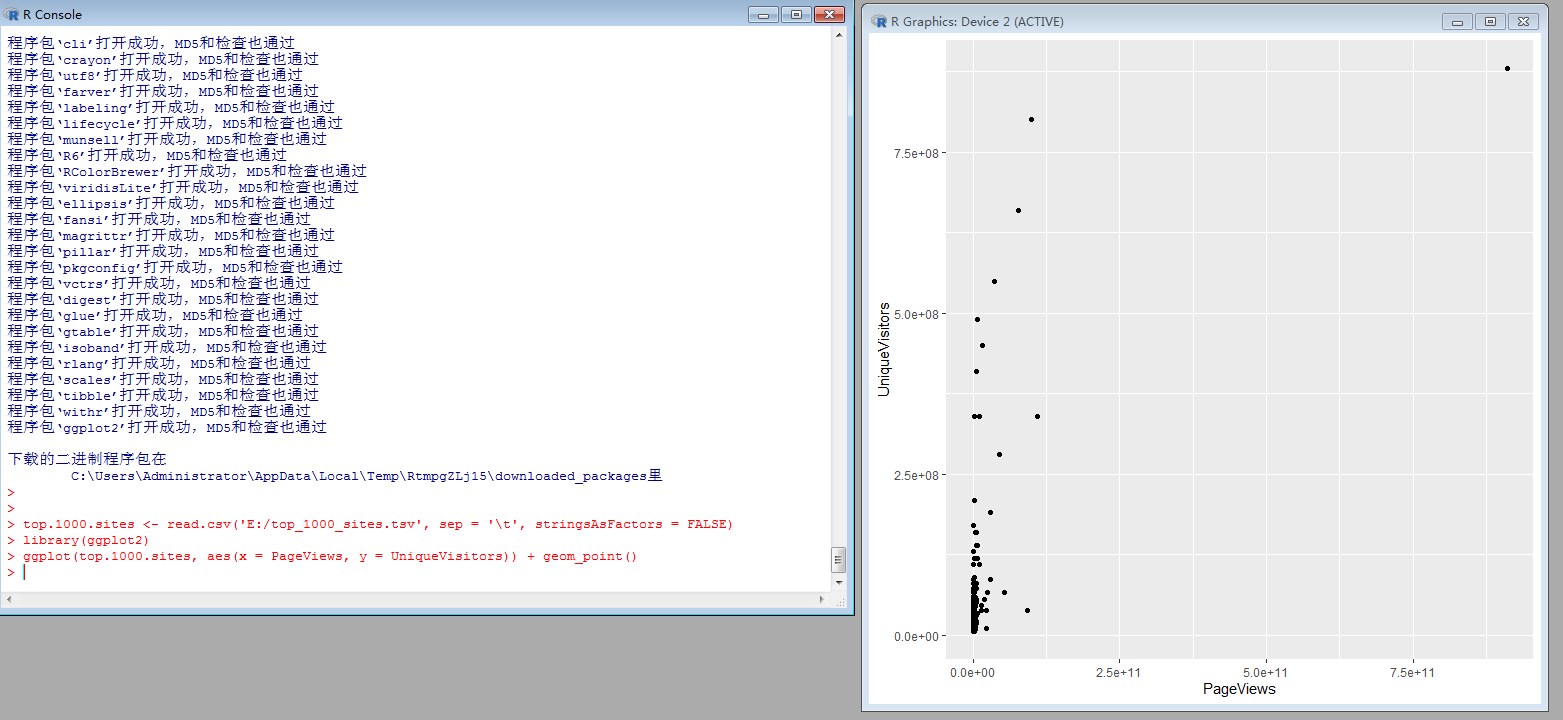
可以看到数据分布很不均匀,集中在左下角坐标原点附近。数据间差异太大时,可以考虑对数据迚行log变换。
ggplot(top.1000.sites, aes(x = log(PageViews), y = log(UniqueVisitors))) + geom_point()

可以看到经过对数变换后问题得到了改善
6.2.2 一元线性回归分析
先对单一一个变量做一元线性回归分析
lm.fit <- lm(log(PageViews) ~ log(UniqueVisitors), data = top.1000.sites)
summary(lm.fit)

6.2.3 多元线性回归
对多个变量做多元线性回归分析
lm.fit <- lm(log(PageViews) ~ HasAdvertising + log(UniqueVisitors) + InEnglish, data = top.1000.sites)
summary(lm.fit)

参考:
- http://www.dataguru.cn/article-4063-1.html
- https://blog.csdn.net/Together_CZ/article/details/78973252
边栏推荐
- Record an SVN error assertion `svn_ uri_ is_ canonical(child_uri, NULL)‘ failed.
- Summary of embedded development -- General Catalog
- 15+城市道路要素分割应用,用这一个分割模型就够了!
- 基于QtQuick的QCustomPlot实现
- Do you understand the capacity expansion mechanism of ArrayList?
- Software architecture discussion
- 15+ urban road element segmentation application, this segmentation model is enough!
- DevSecOps:S-SDLC企业最佳实践
- 《Feature-metric Loss for Self-supervised Learning of Depth and Egomotion》论文笔记
- QT operation on SQLite database multithreading
猜你喜欢
leetcode 第一题——两数之和

The most powerful eight part essay in 2022, "code out eight part essay - cut out the offer line"

Mqtt of NLog custom target

高性能并行编程与优化 | 第01讲回家作业

The advanced process resistance of Intel and TSMC is increasing, and Chinese chips are expected to shorten the gap

03. Redis actual battle: meeting goddess nearby by geo type

Swift 之返回按钮

qmlbook学习总结

CAS central certification service

Citus 11 for Postgres is completely open source and can be queried from any node (citus official blog)

随机推荐
Record an SVN error assertion `svn_ uri_ is_ canonical(child_uri, NULL)‘ failed.
年轻人不愿换手机,因选择了更耐用的iPhone,国产手机参数论失效
基于QtQuick的QCustomPlot实现
WPF DataContext 使用
15+城市道路要素分割应用,用这一个分割模型就够了!
告别无尽盛夏
Is it cool to be a programmer abroad?
618掘金数字藏品?Burberry等奢侈品牌鏖战元宇宙
QML introduction to advanced
[Architect (Part 38)] locally install the latest version of MySQL database developed by the server
Compilation principle knowledge points sorting
秘密法宝
请教下。使用mysql-cdc需要mysql启用什么设置或者功能的保障么,还是说只要有mysql的i
C语言初阶(八)联合体
Swift 之返回按钮
Map集合遍历,添加替换,删除元素
失控玩家
is not allowed to connect to this mysql server
送分题,ArrayList 的扩容机制了解吗?
On the corners of const