当前位置:网站首页>Spark 结构化流写入Hudi 实践
Spark 结构化流写入Hudi 实践
2022-07-03 09:00:00 【小胡今天有变强吗】
概述
整合Spark StructuredStreaming与Hudi,实时将流式数据写入Hudi表中,对每批次数据batch DataFrame,采用
Spark DataSource方式写入数据。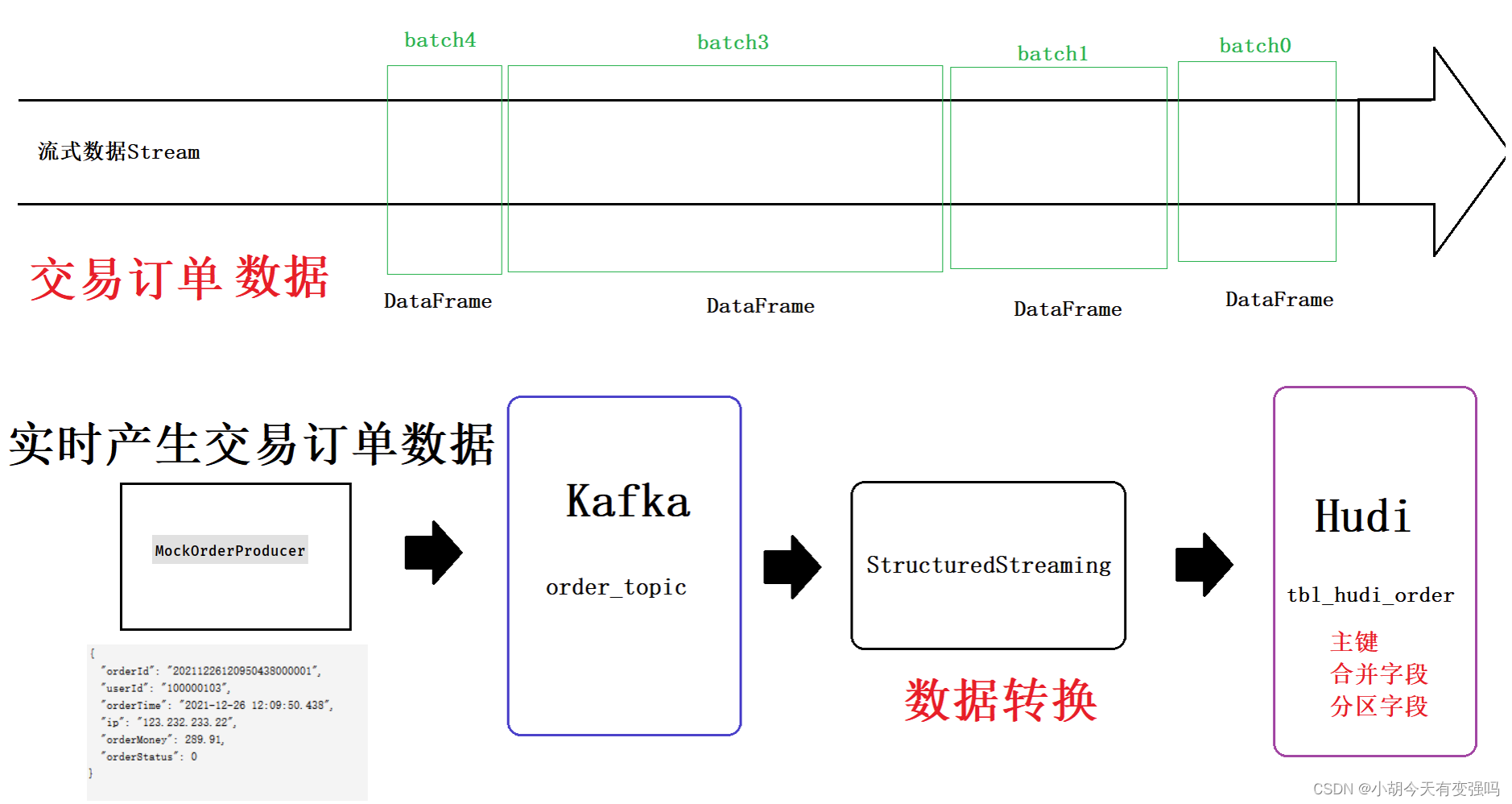
流程与前一篇博客https://blog.csdn.net/hshudoudou/article/details/125303310?spm=1001.2014.3001.5501的配置文件一致。
项目结构如下图所示:
主要是 stream 包下的两个 spark 代码。
代码
- MockOrderProducer.scala
模拟订单产生实时产生交易订单数据,使用Json4J转换数据为JSON字符,发送Kafka Topic中。
import java.util.Properties
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{
KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import org.json4s.jackson.Json
import scala.util.Random
/** * 订单实体类(Case Class) * * @param orderId 订单ID * @param userId 用户ID * @param orderTime 订单日期时间 * @param ip 下单IP地址 * @param orderMoney 订单金额 * @param orderStatus 订单状态 */
case class OrderRecord(
orderId: String,
userId: String,
orderTime: String,
ip: String,
orderMoney: Double,
orderStatus: Int
)
/** * 模拟生产订单数据,发送到Kafka Topic中 * Topic中每条数据Message类型为String,以JSON格式数据发送 * 数据转换: * 将Order类实例对象转换为JSON格式字符串数据(可以使用json4s类库) */
object MockOrderProducer {
def main(args: Array[String]): Unit = {
var producer: KafkaProducer[String, String] = null
try {
// 1. Kafka Client Producer 配置信息
val props = new Properties()
props.put("bootstrap.servers", "hadoop102:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
// 2. 创建KafkaProducer对象,传入配置信息
producer = new KafkaProducer[String, String](props)
// 随机数实例对象
val random: Random = new Random()
// 订单状态:订单打开 0,订单取消 1,订单关闭 2,订单完成 3
val allStatus = Array(0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
while (true) {
// 每次循环 模拟产生的订单数目
val batchNumber: Int = random.nextInt(1) + 20
(1 to batchNumber).foreach {
number =>
val currentTime: Long = System.currentTimeMillis()
val orderId: String = s"${
getDate(currentTime)}%06d".format(number)
val userId: String = s"${
1 + random.nextInt(5)}%08d".format(random.nextInt(1000))
val orderTime: String = getDate(currentTime, format = "yyyy-MM-dd HH:mm:ss.SSS")
val orderMoney: String = s"${
5 + random.nextInt(500)}.%02d".format(random.nextInt(100))
val orderStatus: Int = allStatus(random.nextInt(allStatus.length))
// 3. 订单记录数据
val orderRecord: OrderRecord = OrderRecord(
orderId, userId, orderTime, getRandomIp, orderMoney.toDouble, orderStatus
)
// 转换为JSON格式数据
val orderJson = new Json(org.json4s.DefaultFormats).write(orderRecord)
println(orderJson)
// 4. 构建ProducerRecord对象
val record = new ProducerRecord[String, String]("order-topic", orderId, orderJson)
// 5. 发送数据:def send(messages: KeyedMessage[K,V]*), 将数据发送到Topic
producer.send(record)
}
// Thread.sleep(random.nextInt(500) + 5000)
Thread.sleep(random.nextInt(500))
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (null != producer) producer.close()
}
}
/** =================获取当前时间================= */
def getDate(time: Long, format: String = "yyyyMMddHHmmssSSS"): String = {
val fastFormat: FastDateFormat = FastDateFormat.getInstance(format)
val formatDate: String = fastFormat.format(time) // 格式化日期
formatDate
}
/** ================= 获取随机IP地址 ================= */
def getRandomIp: String = {
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792, 608174079), //36.56.0.0-36.63.255.255
(1038614528, 1039007743), //61.232.0.0-61.237.255.255
(1783627776, 1784676351), //106.80.0.0-106.95.255.255
(2035023872, 2035154943), //121.76.0.0-121.77.255.255
(2078801920, 2079064063), //123.232.0.0-123.235.255.255
(-1950089216, -1948778497), //139.196.0.0-139.215.255.255
(-1425539072, -1425014785), //171.8.0.0-171.15.255.255
(-1236271104, -1235419137), //182.80.0.0-182.92.255.255
(-770113536, -768606209), //210.25.0.0-210.47.255.255
(-569376768, -564133889) //222.16.0.0-222.95.255.255
)
// 随机数:IP地址范围下标
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
// 转换Int类型IP地址为IPv4格式
number2IpString(ipNumber)
}
/** =================将Int类型IPv4地址转换为字符串类型================= */
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// 返回IPv4地址
buffer.mkString(".")
}
}
注意修改 Kafka Client Producer 中的服务器配置信息。
- HudiStructuredDemo.scala
Structured Streaming Application应用,实时从Kafka的【order-topic】消费JSON格式数据,经过ETL转换后,存储到Hudi表中。
import com.tianyi.hudi.didi.SparkUtils
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{
DataFrame, Dataset, Row, SaveMode, SparkSession}
/** * 基于StructuredStreaming结构化流实时从Kafka消费数据,经过ETL转换后,存储至Hudi表 */
object HudiStructuredDemo {
/** * 指定Kafka Topic名称,实时消费数据 */
def readFromKafka(spark: SparkSession, topicName: String): DataFrame = {
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "hadoop102:9092")
.option("subscribe", topicName)
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", "false")
.load()
}
def process(streamDF: DataFrame): DataFrame = {
streamDF
// 选择字段
.selectExpr(
"CAST(key AS STRING) order_id",
"CAST(value AS STRING) AS message",
"topic", "partition", "offset", "timestamp"
)
//解析Message数据,提取字段值
.withColumn("user_id", get_json_object(col("message"), "$.userId"))
.withColumn("order_time", get_json_object(col("message"), "$.orderTime"))
.withColumn("ip", get_json_object(col("message"), "$.ip"))
.withColumn("order_money", get_json_object(col("message"), "$.orderMoney"))
.withColumn("order_status", get_json_object(col("message"), "$.orderStatus"))
//删除message字段
.drop(col("message"))
// 转换订单日期时间格式为Long类型,作为hudi表中合并数据字段
.withColumn("ts", to_timestamp(col("order_time"), "yyyy-MM-dd HH:mm:ss.SSS"))
// 订单日期时间提取分区日志:yyyyMMdd
.withColumn("day", substring(col("order_time"), 0, 10))
}
/** * 将流式数据DataFrame保存到Hudi表中 */
def saveToHudi(streamDF: DataFrame) = {
streamDF.writeStream
.outputMode(OutputMode.Append())
.queryName("query-hudi-streaming")
.foreachBatch((batchDF: Dataset[Row], batchId: Long) => {
println(s"============== BatchId: ${
batchId} start ==============")
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.keygen.constant.KeyGeneratorOptions._
batchDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(RECORDKEY_FIELD.key(), "order_id")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(PARTITIONPATH_FIELD.key(), "day")
.option(TBL_NAME.key(), "tbl_hudi_order")
.option(TABLE_TYPE.key(), "MERGE_ON_READ")
// 分区值对应目录格式,与Hive分区策略一致
.option(HIVE_STYLE_PARTITIONING_ENABLE.key(), "true")
.save("/hudi-warehouse/tbl_hudi_order")
})
.option("checkpointLocation", "/datas/hudi-spark/struct-ckpt-1001")
.start()
}
def main(args: Array[String]): Unit = {
//设置服务器用户名
System.setProperty("HADOOP_USER_NAME","hty")
// step1、构建SparkSession实例对象
val spark: SparkSession = SparkUtils.createSpakSession(this.getClass)
//step2、从Kafka实时消费数据
val kafkaStreamDF: DataFrame = readFromKafka(spark, "order-topic")
// step3、提取数据,转换数据类型
val streamDF: DataFrame = process(kafkaStreamDF)
// step4、保存数据至Hudi表中:MOR类型表,读取表数据合并文件
saveToHudi(streamDF)
// step5、流式应用启动以后,等待终止
spark.streams.active.foreach(query => println(s"Query: ${
query.name} is Running .........."))
spark.streams.awaitAnyTermination()
}
}
注意修改代码中服务器的相关配置。
测试
- 模拟数据生成的测试
启动 MockOrderProducer.scala 代码,产生模拟的订单数据。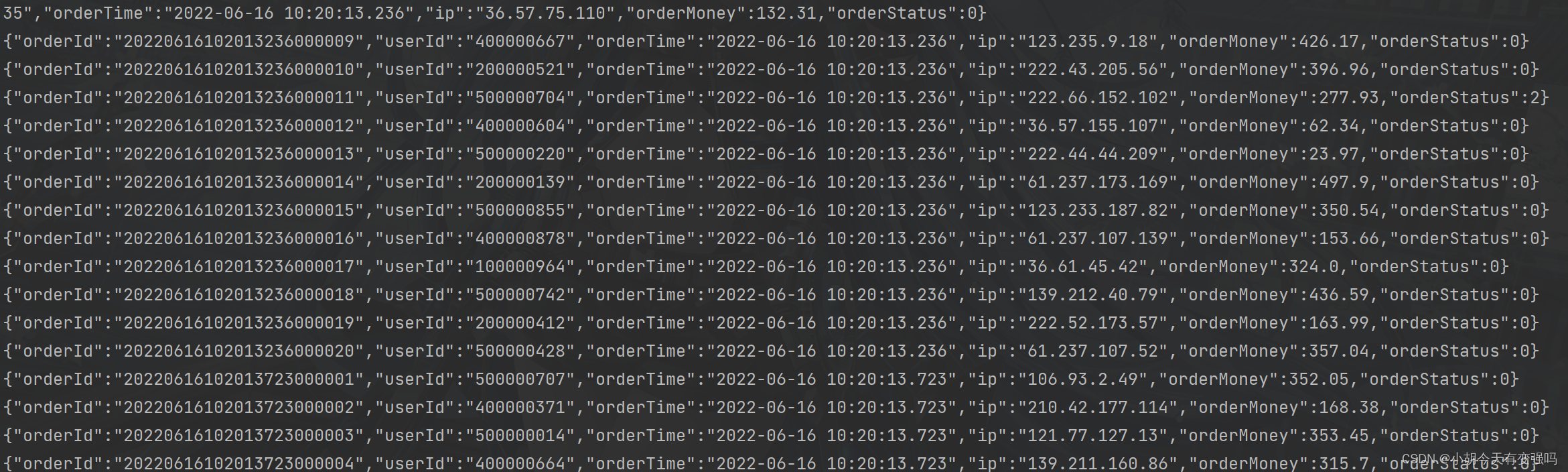
- 创建与代码中一致的 topic: order_topic
下图所示软件为kafka连接器Offset ,对于创建和管理Topic非常的方便,可以自行从网上下载并连接测试。
可以看到Kafka中已经接收到了数据。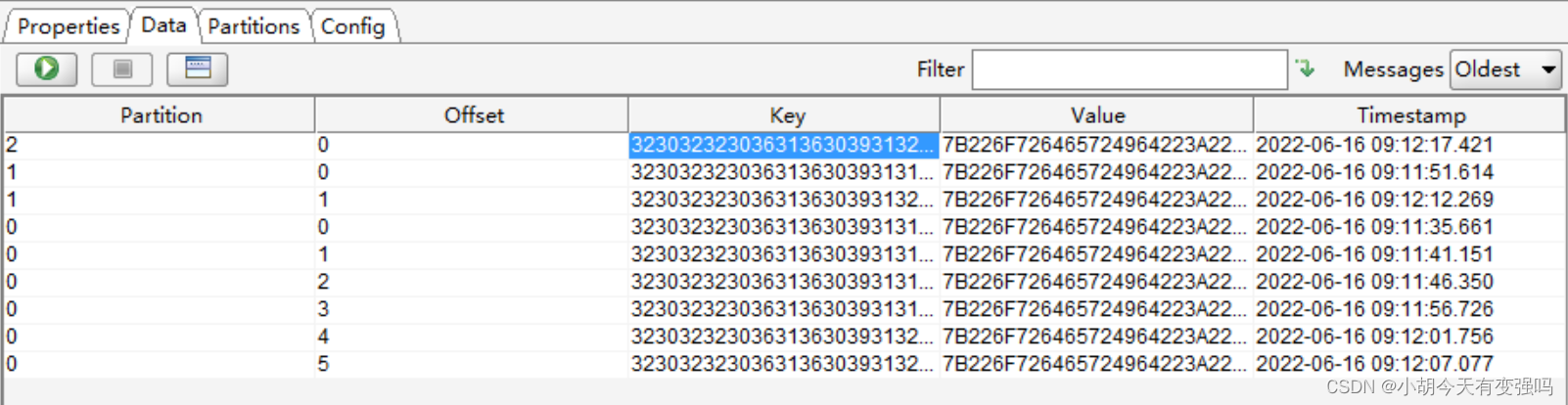
- HudiStructuredDemo.scala测试,启动主方法,从 Kafka 的 order_topic 中消费数据,并以Hudi 表的形式存入HDFS 中。
检查HDFS下的存储情况,所消费的数据都已成功写入。
产生了许多parquet文件,这正是Hudi的存储形式。而parquet文件增长到一定的数量之后便不会继续再增长,而是维持在一个特定的范围,这是Hudi可以自行合并小文件机制的体现。
Spark Shell查询
- 启动Spark-shell
./spark-shell --master local[2] \
--jars /opt/module/jars/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar,\
--jars /opt/module/jars/hudi-jars/spark-avro_2.12-3.0.1.jar,\
--jars /opt/module/jars/hudi-jars/spark_unused-1.0.0.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
- 创建orderDF
val orderDF = spark.read.format("hudi").load("/hudi-warehouse/tbl_hudi_order")
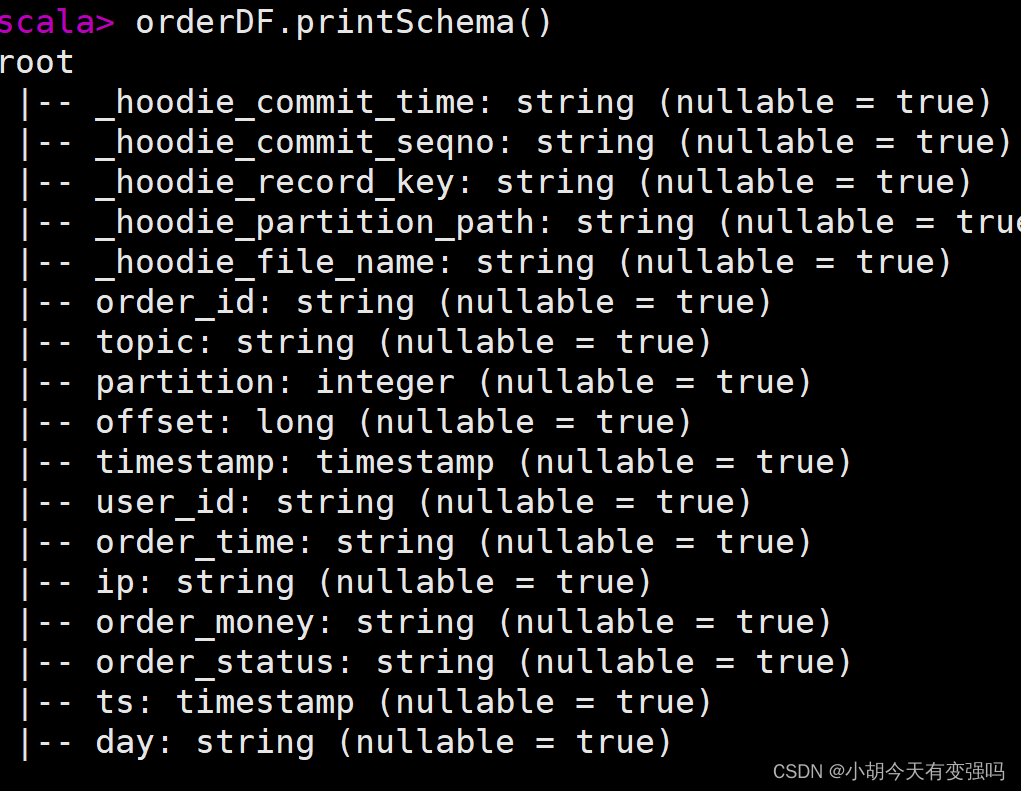
- 查看表结构
orderDF.printSchema()
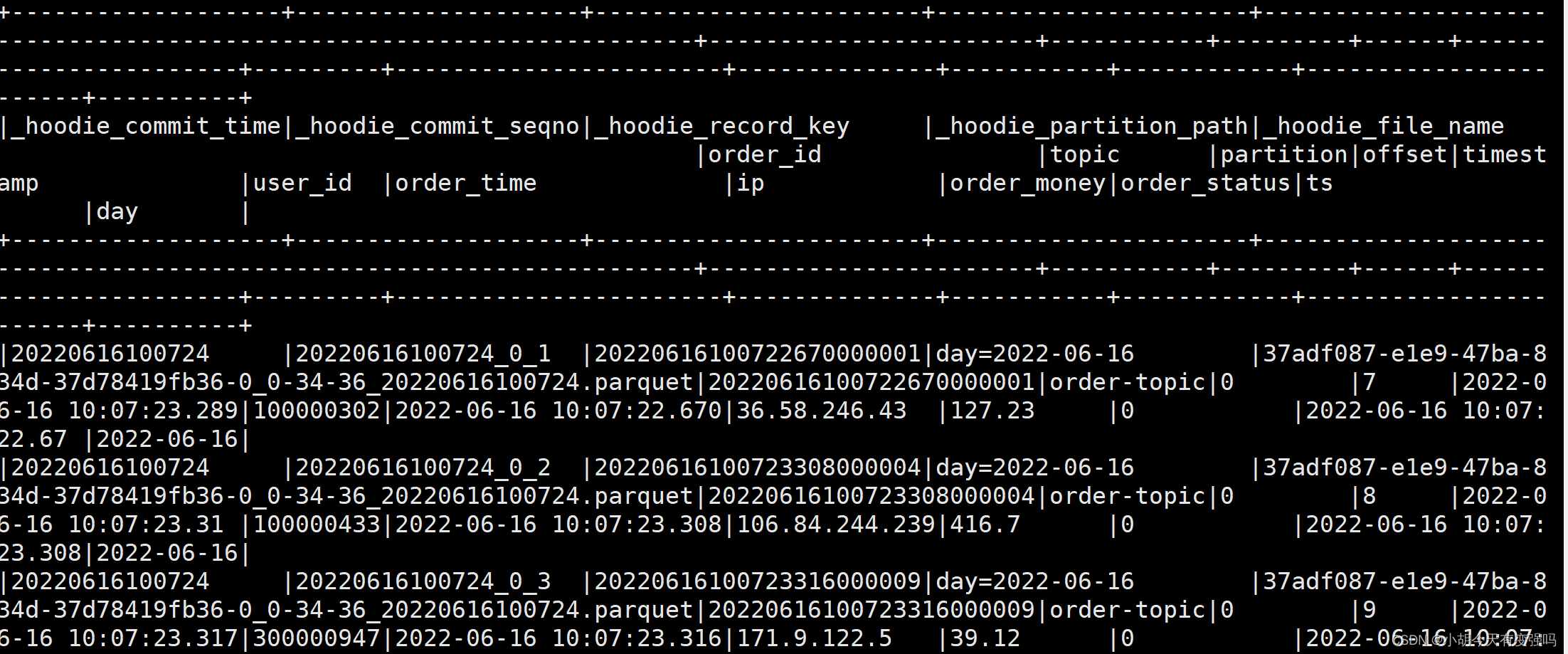
- 展示前10条数据
orderDF.show(10, false)
- 选择特定字段
orderDF.select("order_id", "user_id", "order_time", "ip", "order_money", "order_status", "day").show(false)

- 利用函数进行聚合统计
//注册成为临时视图
orderDF.createOrReplaceTempView("view_tmp_orders")
//执行SQL进行统计
spark.sql(""" with tmp AS ( select CAST(order_money AS DOUBLE) from view_tmp_orders where order_status = '0' ) select max(order_money) as max_money, min(order_money) as min_money, round(avg(order_money), 2) as avg_money from tmp """).show

至此整个流程结束。
总结
本示例通过spark程序产生模拟的订单交易数据,实时由Spark进行消费,再由 Spark 进行消费,写入到Hudi表中。
边栏推荐
- LeetCode 75. 颜色分类
- Install third-party libraries such as Jieba under Anaconda pytorch
- npm install安装依赖包报错解决方法
- AcWing 788. 逆序对的数量
- 低代码前景可期,JNPF灵活易用,用智能定义新型办公模式
- Methods of using arrays as function parameters in shell
- Explanation of the answers to the three questions
- 精彩回顾|I/O Extended 2022 活动干货分享
- LeetCode 532. 数组中的 k-diff 数对
- Principles of computer composition - cache, connection mapping, learning experience
猜你喜欢

State compression DP acwing 91 Shortest Hamilton path

网络安全必会的基础知识

Wonderful review | i/o extended 2022 activity dry goods sharing
![[kotlin learning] classes, objects and interfaces - define class inheritance structure](/img/66/34396e51c59504ebbc6b6eb9831209.png)
[kotlin learning] classes, objects and interfaces - define class inheritance structure

Save the drama shortage, programmers' favorite high-score American drama TOP10

图像修复方法研究综述----论文笔记

LeetCode 715. Range 模块

一个优秀速开发框架是什么样的?

【Kotlin疑惑】在Kotlin类中重载一个算术运算符,并把该运算符声明为扩展函数会发生什么?

Education informatization has stepped into 2.0. How can jnpf help teachers reduce their burden and improve efficiency?
随机推荐
Windows安装Redis详细步骤
How to check whether the disk is in guid format (GPT) or MBR format? Judge whether UEFI mode starts or legacy mode starts?
PIC16F648A-E/SS PIC16 8位 微控制器,7KB(4Kx14)
Wonderful review | i/o extended 2022 activity dry goods sharing
2022-2-14 learning xiangniuke project - generate verification code
Vscode编辑器右键没有Open In Default Browser选项
Go language - JSON processing
In the digital transformation, what problems will occur in enterprise equipment management? Jnpf may be the "optimal solution"
Low code momentum, this information management system development artifact, you deserve it!
【Kotlin疑惑】在Kotlin类中重载一个算术运算符,并把该运算符声明为扩展函数会发生什么?
String splicing method in shell
[set theory] order relation (eight special elements in partial order relation | ① maximum element | ② minimum element | ③ maximum element | ④ minimum element | ⑤ upper bound | ⑥ lower bound | ⑦ minimu
Explanation of the answers to the three questions
LeetCode 715. Range 模块
[point cloud processing paper crazy reading classic version 11] - mining point cloud local structures by kernel correlation and graph pooling
[untitled] use of cmake
Jenkins learning (III) -- setting scheduled tasks
Recommend a low code open source project of yyds
LeetCode 515. 在每个树行中找最大值
[kotlin learning] operator overloading and other conventions -- overloading the conventions of arithmetic operators, comparison operators, sets and intervals