当前位置:网站首页>Data warehouse construction -dim floor
Data warehouse construction -dim floor
2022-07-26 05:24:00 【Silky】
1 Commodity dimension table ( Total quantity )
Create table statement
DROP TABLE IF EXISTS dim_sku_info;
CREATE EXTERNAL TABLE dim_sku_info (
`id` STRING COMMENT ' goods id',
`price` DECIMAL(16,2) COMMENT ' commodity price ',
`sku_name` STRING COMMENT ' Name of commodity ',
`sku_desc` STRING COMMENT ' Commodity Description ',
`weight` DECIMAL(16,2) COMMENT ' weight ',
`is_sale` BOOLEAN COMMENT ' Are you selling ',
`spu_id` STRING COMMENT 'spu Number ',
`spu_name` STRING COMMENT 'spu name ',
`category3_id` STRING COMMENT ' Three levels of classification id',
`category3_name` STRING COMMENT ' The name of the third level classification ',
`category2_id` STRING COMMENT ' Secondary classification id',
`category2_name` STRING COMMENT ' Secondary classification name ',
`category1_id` STRING COMMENT ' First level classification id',
`category1_name` STRING COMMENT ' First class classification name ',
`tm_id` STRING COMMENT ' brand id',
`tm_name` STRING COMMENT ' The brand name ',
`sku_attr_values` ARRAY<STRUCT<attr_id:STRING,value_id:STRING,attr_name:STRING,value_name:STRING>> COMMENT ' Platform properties ',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id:STRING,sale_attr_value_id:STRING,sale_attr_name:STRING,sale_attr_value_name:STRING>> COMMENT ' Sales attributes ',
`create_time` STRING COMMENT ' Creation time '
) COMMENT ' Commodity dimension table '
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_sku_info/'
TBLPROPERTIES ("parquet.compression"="lzo");

Data loading ideas


Load statement :
First day loading
with
sku as
(
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
category3_id,
tm_id,
create_time
from ods_sku_info
where dt='2020-06-14'
),
spu as
(
select
id,
spu_name
from ods_spu_info
where dt='2020-06-14'
),
c3 as
(
select
id,
name,
category2_id
from ods_base_category3
where dt='2020-06-14'
),
c2 as
(
select
id,
name,
category1_id
from ods_base_category2
where dt='2020-06-14'
),
c1 as
(
select
id,
name
from ods_base_category1
where dt='2020-06-14'
),
tm as
(
select
id,
tm_name
from ods_base_trademark
where dt='2020-06-14'
),
attr as
(
select
sku_id,
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrs
from ods_sku_attr_value
where dt='2020-06-14'
group by sku_id
),
sale_attr as
(
select
sku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrs
from ods_sku_sale_attr_value
where dt='2020-06-14'
group by sku_id
)
insert overwrite table dim_sku_info partition(dt='2020-06-14')
select
sku.id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.is_sale,
sku.spu_id,
spu.spu_name,
sku.category3_id,
c3.name,
c3.category2_id,
c2.name,
c2.category1_id,
c1.name,
sku.tm_id,
tm.tm_name,
attr.attrs,
sale_attr.sale_attrs,
sku.create_time
from sku
left join spu on sku.spu_id=spu.id
left join c3 on sku.category3_id=c3.id
left join c2 on c3.category2_id=c2.id
left join c1 on c2.category1_id=c1.id
left join tm on sku.tm_id=tm.id
left join attr on sku.id=attr.sku_id
left join sale_attr on sku.id=sale_attr.sku_id;

First create a product dimension table , Then execute the load statement :

View the results in the product dimension table

The cause of the abnormality : First, the index file will be merged as a small file , Treat it as a normal file . More serious , This can lead to LZO File cannot be sliced .

Solve the problem that index files are merged by mistake :( close hive Of mat End of the small file merge )
terms of settlement : modify CombineHiveInputFormat by HiveInputFormat
hive (gmall)>
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;

Execute the load statement again
(insert overwrite The original data will be overwritten , So you can execute the load statement multiple times )

2 Coupon dimension table ( Total quantity )
Create table statement
DROP TABLE IF EXISTS dim_coupon_info;
CREATE EXTERNAL TABLE dim_coupon_info(
`id` STRING COMMENT ' Shopping voucher No ',
`coupon_name` STRING COMMENT ' Name of the shopping voucher ',
`coupon_type` STRING COMMENT ' Type of shopping voucher 1 cash coupon 2 coupon 3 Full discount 4 Full discount coupons ',
`condition_amount` DECIMAL(16,2) COMMENT ' Full amount ',
`condition_num` BIGINT COMMENT ' Full number ',
`activity_id` STRING COMMENT ' Activity number ',
`benefit_amount` DECIMAL(16,2) COMMENT ' Less amount ',
`benefit_discount` DECIMAL(16,2) COMMENT ' discount ',
`create_time` STRING COMMENT ' Creation time ',
`range_type` STRING COMMENT ' Range type 1、 goods 2、 category 3、 brand ',
`limit_num` BIGINT COMMENT ' Maximum collection times ',
`taken_count` BIGINT COMMENT ' Number of times received ',
`start_time` STRING COMMENT ' Start date of claim ',
`end_time` STRING COMMENT ' End date of claim ',
`operate_time` STRING COMMENT ' Modification time ',
`expire_time` STRING COMMENT ' Expiration time '
) COMMENT ' Coupon dimension table '
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_coupon_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
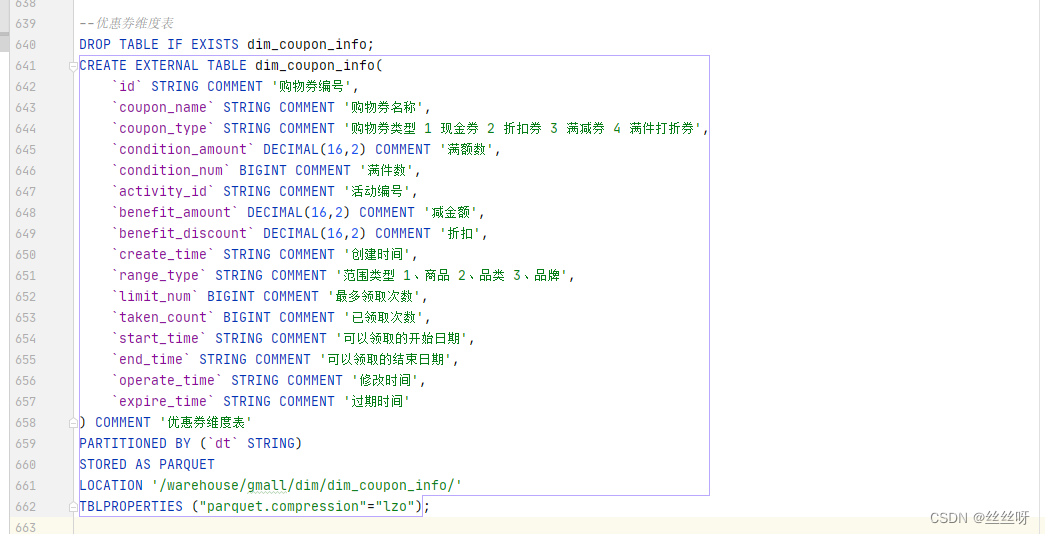
Data loading

Load statement
insert overwrite table dim_coupon_info partition(dt='2020-06-14')
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from ods_coupon_info
where dt='2020-06-14';

3 Activity dimension table ( Total quantity )
Create table statement
DROP TABLE IF EXISTS dim_activity_rule_info;
CREATE EXTERNAL TABLE dim_activity_rule_info(
`activity_rule_id` STRING COMMENT ' Activity rules ID',
`activity_id` STRING COMMENT ' Activities ID',
`activity_name` STRING COMMENT ' The name of the event ',
`activity_type` STRING COMMENT ' Type of activity ',
`start_time` STRING COMMENT ' Starting time ',
`end_time` STRING COMMENT ' End time ',
`create_time` STRING COMMENT ' Creation time ',
`condition_amount` DECIMAL(16,2) COMMENT ' Full reduction amount ',
`condition_num` BIGINT COMMENT ' Full reduction of pieces ',
`benefit_amount` DECIMAL(16,2) COMMENT ' Preferential amount ',
`benefit_discount` DECIMAL(16,2) COMMENT ' Discount ',
`benefit_level` STRING COMMENT ' Discount level '
) COMMENT ' Activity information table '
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_activity_rule_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
Data loading

insert overwrite table dim_activity_rule_info partition(dt='2020-06-14')
select
ar.id,
ar.activity_id,
ai.activity_name,
ar.activity_type,
ai.start_time,
ai.end_time,
ai.create_time,
ar.condition_amount,
ar.condition_num,
ar.benefit_amount,
ar.benefit_discount,
ar.benefit_level
from
(
select
id,
activity_id,
activity_type,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from ods_activity_rule
where dt='2020-06-14'
)ar
left join
(
select
id,
activity_name,
start_time,
end_time,
create_time
from ods_activity_info
where dt='2020-06-14'
)ai
on ar.activity_id=ai.id;
4 Regional dimension table ( special )
Create table statement
DROP TABLE IF EXISTS dim_base_province;
CREATE EXTERNAL TABLE dim_base_province (
`id` STRING COMMENT 'id',
`province_name` STRING COMMENT ' Provincial and municipal name ',
`area_code` STRING COMMENT ' Area code ',
`iso_code` STRING COMMENT 'ISO-3166 code , For visualization ',
`iso_3166_2` STRING COMMENT 'IOS-3166-2 code , For visualization ',
`region_id` STRING COMMENT ' region id',
`region_name` STRING COMMENT ' Area name '
) COMMENT ' Regional dimension table '
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_base_province/'
TBLPROPERTIES ("parquet.compression"="lzo");
Data loading
The data of regional dimension table is relatively stable , Low probability of change , Therefore, there is no need to load every day .

insert overwrite table dim_base_province
select
bp.id,
bp.name,
bp.area_code,
bp.iso_code,
bp.iso_3166_2,
bp.region_id,
br.region_name
from ods_base_province bp
join ods_base_region br on bp.region_id = br.id;
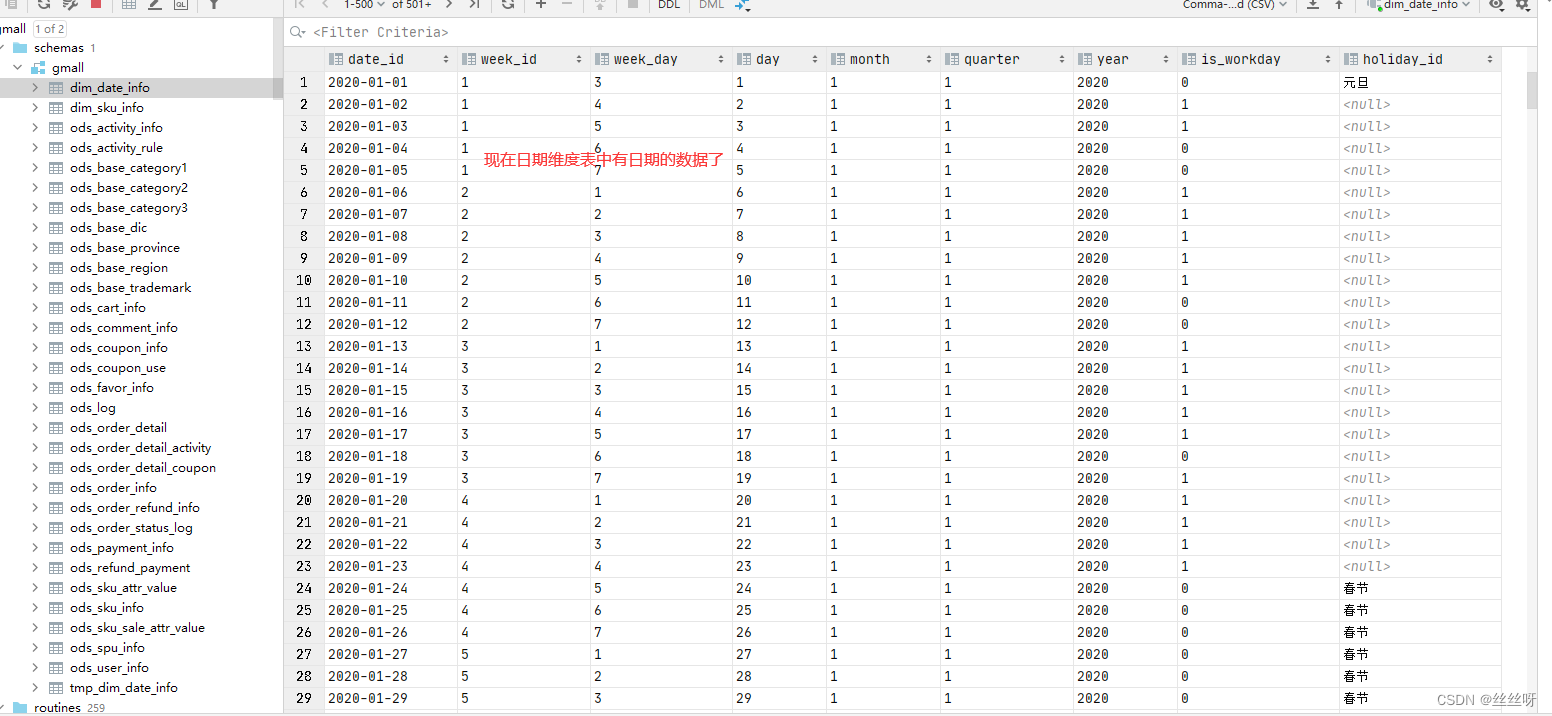
5 Time dimension table ( special )
Create table statement
DROP TABLE IF EXISTS dim_date_info;
CREATE EXTERNAL TABLE dim_date_info(
`date_id` STRING COMMENT ' Japan ',
`week_id` STRING COMMENT ' Zhou ID',
`week_day` STRING COMMENT ' What day of the week ',
`day` STRING COMMENT ' The day of the month ',
`month` STRING COMMENT ' What month ',
`quarter` STRING COMMENT ' What quarter ',
`year` STRING COMMENT ' year ',
`is_workday` STRING COMMENT ' Is it a working day ',
`holiday_id` STRING COMMENT ' The holiday season '
) COMMENT ' Time dimension table '
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_date_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
Data loading
Usually , The data of the time dimension table does not come from the business system , Instead, write it manually , And due to the predictability of time dimension table data , There is no need to import , Generally, the data of one year can be imported at one time .
Create a temporary table
DROP TABLE IF EXISTS tmp_dim_date_info;
CREATE EXTERNAL TABLE tmp_dim_date_info (
`date_id` STRING COMMENT ' Japan ',
`week_id` STRING COMMENT ' Zhou ID',
`week_day` STRING COMMENT ' What day of the week ',
`day` STRING COMMENT ' The day of the month ',
`month` STRING COMMENT ' What month ',
`quarter` STRING COMMENT ' What quarter ',
`year` STRING COMMENT ' year ',
`is_workday` STRING COMMENT ' Is it a working day ',
`holiday_id` STRING COMMENT ' The holiday season '
) COMMENT ' Time dimension table '
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/tmp/tmp_dim_date_info/';
Executable files

Select the file in this directory , Upload files


Data already exists in the temporary table

Now write data into the real time dimension table

Load statement
insert overwrite table dim_date_info select * from tmp_dim_date_info;
6 User dimension table ( Zipper table )
Zipper table : Record the lifecycle of each piece of information , Once the life cycle of a record ends , Just start a new record , And put the current date into the effective start date .
Create table statement
DROP TABLE IF EXISTS dim_user_info;
CREATE EXTERNAL TABLE dim_user_info(
`id` STRING COMMENT ' user id',
`login_name` STRING COMMENT ' User name ',
`nick_name` STRING COMMENT ' The user nickname ',
`name` STRING COMMENT ' User name ',
`phone_num` STRING COMMENT ' Phone number ',
`email` STRING COMMENT ' mailbox ',
`user_level` STRING COMMENT ' User level ',
`birthday` STRING COMMENT ' Birthday ',
`gender` STRING COMMENT ' Gender ',
`create_time` STRING COMMENT ' Creation time ',
`operate_time` STRING COMMENT ' Operating time ',
`start_date` STRING COMMENT ' Start date ',
`end_date` STRING COMMENT ' End date '
) COMMENT ' User table '
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_user_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
Data loading

First day loading
Zipper watch first day loading , Initialization is required , The specific work is to import all historical users up to the initialization day into the zipper table at one time . current ods_user_info The first partition of the table , namely 2020-06-14 All historical users are in the partition , Therefore, the partition data is imported into the zipper table after certain processing 9999-99-99 Partition can .
insert overwrite table dim_user_info partition(dt='9999-99-99')
select
id,
login_name,
nick_name,
md5(name),
md5(phone_num),
md5(email),
user_level,
birthday,
gender,
create_time,
operate_time,
'2020-06-14',
'9999-99-99'
from ods_user_info
where dt='2020-06-14';
Daily load
with
tmp as
(
select
old.id old_id,
old.login_name old_login_name,
old.nick_name old_nick_name,
old.name old_name,
old.phone_num old_phone_num,
old.email old_email,
old.user_level old_user_level,
old.birthday old_birthday,
old.gender old_gender,
old.create_time old_create_time,
old.operate_time old_operate_time,
old.start_date old_start_date,
old.end_date old_end_date,
new.id new_id,
new.login_name new_login_name,
new.nick_name new_nick_name,
new.name new_name,
new.phone_num new_phone_num,
new.email new_email,
new.user_level new_user_level,
new.birthday new_birthday,
new.gender new_gender,
new.create_time new_create_time,
new.operate_time new_operate_time,
new.start_date new_start_date,
new.end_date new_end_date
from
(
select
id,
login_name,
nick_name,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
start_date,
end_date
from dim_user_info
where dt='9999-99-99'
)old
full outer join
(
select
id,
login_name,
nick_name,
md5(name) name,
md5(phone_num) phone_num,
md5(email) email,
user_level,
birthday,
gender,
create_time,
operate_time,
'2020-06-15' start_date,
'9999-99-99' end_date
from ods_user_info
where dt='2020-06-15'
)new
on old.id=new.id
)
insert overwrite table dim_user_info partition(dt)
select
nvl(new_id,old_id),
nvl(new_login_name,old_login_name),
nvl(new_nick_name,old_nick_name),
nvl(new_name,old_name),
nvl(new_phone_num,old_phone_num),
nvl(new_email,old_email),
nvl(new_user_level,old_user_level),
nvl(new_birthday,old_birthday),
nvl(new_gender,old_gender),
nvl(new_create_time,old_create_time),
nvl(new_operate_time,old_operate_time),
nvl(new_start_date,old_start_date),
nvl(new_end_date,old_end_date),
nvl(new_end_date,old_end_date) dt
from tmp
union all
select
old_id,
old_login_name,
old_nick_name,
old_name,
old_phone_num,
old_email,
old_user_level,
old_birthday,
old_gender,
old_create_time,
old_operate_time,
old_start_date,
cast(date_add('2020-06-15',-1) as string),
cast(date_add('2020-06-15',-1) as string) dt
from tmp
where new_id is not null and old_id is not null;
7 DIM Layer first day data loading script
stay /home/zhang/bin Create script in directory ods_to_dim_db_init.sh
[[email protected] bin]$ vim ods_to_dim_db_init.sh
Fill in the script as follows
#!/bin/bash
APP=gmall
if [ -n "$2" ] ;then
do_date=$2
else
echo " Please pass in the date parameter "
exit
fi
dim_user_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dim_user_info partition(dt='9999-99-99')
select
id,
login_name,
nick_name,
md5(name),
md5(phone_num),
md5(email),
user_level,
birthday,
gender,
create_time,
operate_time,
'$do_date',
'9999-99-99'
from ${APP}.ods_user_info
where dt='$do_date';
"
dim_sku_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
with
sku as
(
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
category3_id,
tm_id,
create_time
from ${APP}.ods_sku_info
where dt='$do_date'
),
spu as
(
select
id,
spu_name
from ${APP}.ods_spu_info
where dt='$do_date'
),
c3 as
(
select
id,
name,
category2_id
from ${APP}.ods_base_category3
where dt='$do_date'
),
c2 as
(
select
id,
name,
category1_id
from ${APP}.ods_base_category2
where dt='$do_date'
),
c1 as
(
select
id,
name
from ${APP}.ods_base_category1
where dt='$do_date'
),
tm as
(
select
id,
tm_name
from ${APP}.ods_base_trademark
where dt='$do_date'
),
attr as
(
select
sku_id,
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrs
from ${APP}.ods_sku_attr_value
where dt='$do_date'
group by sku_id
),
sale_attr as
(
select
sku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrs
from ${APP}.ods_sku_sale_attr_value
where dt='$do_date'
group by sku_id
)
insert overwrite table ${APP}.dim_sku_info partition(dt='$do_date')
select
sku.id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.is_sale,
sku.spu_id,
spu.spu_name,
sku.category3_id,
c3.name,
c3.category2_id,
c2.name,
c2.category1_id,
c1.name,
sku.tm_id,
tm.tm_name,
attr.attrs,
sale_attr.sale_attrs,
sku.create_time
from sku
left join spu on sku.spu_id=spu.id
left join c3 on sku.category3_id=c3.id
left join c2 on c3.category2_id=c2.id
left join c1 on c2.category1_id=c1.id
left join tm on sku.tm_id=tm.id
left join attr on sku.id=attr.sku_id
left join sale_attr on sku.id=sale_attr.sku_id;
"
dim_base_province="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dim_base_province
select
bp.id,
bp.name,
bp.area_code,
bp.iso_code,
bp.iso_3166_2,
bp.region_id,
br.region_name
from ${APP}.ods_base_province bp
join ${APP}.ods_base_region br on bp.region_id = br.id;
"
dim_coupon_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dim_coupon_info partition(dt='$do_date')
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from ${APP}.ods_coupon_info
where dt='$do_date';
"
dim_activity_rule_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dim_activity_rule_info partition(dt='$do_date')
select
ar.id,
ar.activity_id,
ai.activity_name,
ar.activity_type,
ai.start_time,
ai.end_time,
ai.create_time,
ar.condition_amount,
ar.condition_num,
ar.benefit_amount,
ar.benefit_discount,
ar.benefit_level
from
(
select
id,
activity_id,
activity_type,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from ${APP}.ods_activity_rule
where dt='$do_date'
)ar
left join
(
select
id,
activity_name,
start_time,
end_time,
create_time
from ${APP}.ods_activity_info
where dt='$do_date'
)ai
on ar.activity_id=ai.id;
"
case $1 in
"dim_user_info"){
hive -e "$dim_user_info"
};;
"dim_sku_info"){
hive -e "$dim_sku_info"
};;
"dim_base_province"){
hive -e "$dim_base_province"
};;
"dim_coupon_info"){
hive -e "$dim_coupon_info"
};;
"dim_activity_rule_info"){
hive -e "$dim_activity_rule_info"
};;
"all"){
hive -e "$dim_user_info$dim_sku_info$dim_coupon_info$dim_activity_rule_info$dim_base_province"
};;
esac

stay /home/zhang/bin Create script in directory ods_to_dim_db.sh
[[email protected] bin]$ vim ods_to_dim_db.sh
Fill in the script as follows
#!/bin/bash
APP=gmall
# If it is the entered date, the entered date shall be taken ; If no date is entered, take the day before the current time
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
dim_user_info="
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
with
tmp as
(
select
old.id old_id,
old.login_name old_login_name,
old.nick_name old_nick_name,
old.name old_name,
old.phone_num old_phone_num,
old.email old_email,
old.user_level old_user_level,
old.birthday old_birthday,
old.gender old_gender,
old.create_time old_create_time,
old.operate_time old_operate_time,
old.start_date old_start_date,
old.end_date old_end_date,
new.id new_id,
new.login_name new_login_name,
new.nick_name new_nick_name,
new.name new_name,
new.phone_num new_phone_num,
new.email new_email,
new.user_level new_user_level,
new.birthday new_birthday,
new.gender new_gender,
new.create_time new_create_time,
new.operate_time new_operate_time,
new.start_date new_start_date,
new.end_date new_end_date
from
(
select
id,
login_name,
nick_name,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
start_date,
end_date
from ${APP}.dim_user_info
where dt='9999-99-99'
and start_date<'$do_date'
)old
full outer join
(
select
id,
login_name,
nick_name,
md5(name) name,
md5(phone_num) phone_num,
md5(email) email,
user_level,
birthday,
gender,
create_time,
operate_time,
'$do_date' start_date,
'9999-99-99' end_date
from ${APP}.ods_user_info
where dt='$do_date'
)new
on old.id=new.id
)
insert overwrite table ${APP}.dim_user_info partition(dt)
select
nvl(new_id,old_id),
nvl(new_login_name,old_login_name),
nvl(new_nick_name,old_nick_name),
nvl(new_name,old_name),
nvl(new_phone_num,old_phone_num),
nvl(new_email,old_email),
nvl(new_user_level,old_user_level),
nvl(new_birthday,old_birthday),
nvl(new_gender,old_gender),
nvl(new_create_time,old_create_time),
nvl(new_operate_time,old_operate_time),
nvl(new_start_date,old_start_date),
nvl(new_end_date,old_end_date),
nvl(new_end_date,old_end_date) dt
from tmp
union all
select
old_id,
old_login_name,
old_nick_name,
old_name,
old_phone_num,
old_email,
old_user_level,
old_birthday,
old_gender,
old_create_time,
old_operate_time,
old_start_date,
cast(date_add('$do_date',-1) as string),
cast(date_add('$do_date',-1) as string) dt
from tmp
where new_id is not null and old_id is not null;
"
dim_sku_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
with
sku as
(
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
category3_id,
tm_id,
create_time
from ${APP}.ods_sku_info
where dt='$do_date'
),
spu as
(
select
id,
spu_name
from ${APP}.ods_spu_info
where dt='$do_date'
),
c3 as
(
select
id,
name,
category2_id
from ${APP}.ods_base_category3
where dt='$do_date'
),
c2 as
(
select
id,
name,
category1_id
from ${APP}.ods_base_category2
where dt='$do_date'
),
c1 as
(
select
id,
name
from ${APP}.ods_base_category1
where dt='$do_date'
),
tm as
(
select
id,
tm_name
from ${APP}.ods_base_trademark
where dt='$do_date'
),
attr as
(
select
sku_id,
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrs
from ${APP}.ods_sku_attr_value
where dt='$do_date'
group by sku_id
),
sale_attr as
(
select
sku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrs
from ${APP}.ods_sku_sale_attr_value
where dt='$do_date'
group by sku_id
)
insert overwrite table ${APP}.dim_sku_info partition(dt='$do_date')
select
sku.id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.is_sale,
sku.spu_id,
spu.spu_name,
sku.category3_id,
c3.name,
c3.category2_id,
c2.name,
c2.category1_id,
c1.name,
sku.tm_id,
tm.tm_name,
attr.attrs,
sale_attr.sale_attrs,
sku.create_time
from sku
left join spu on sku.spu_id=spu.id
left join c3 on sku.category3_id=c3.id
left join c2 on c3.category2_id=c2.id
left join c1 on c2.category1_id=c1.id
left join tm on sku.tm_id=tm.id
left join attr on sku.id=attr.sku_id
left join sale_attr on sku.id=sale_attr.sku_id;
"
dim_base_province="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dim_base_province
select
bp.id,
bp.name,
bp.area_code,
bp.iso_code,
bp.iso_3166_2,
bp.region_id,
bp.name
from ${APP}.ods_base_province bp
join ${APP}.ods_base_region br on bp.region_id = br.id;
"
dim_coupon_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dim_coupon_info partition(dt='$do_date')
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from ${APP}.ods_coupon_info
where dt='$do_date';
"
dim_activity_rule_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dim_activity_rule_info partition(dt='$do_date')
select
ar.id,
ar.activity_id,
ai.activity_name,
ar.activity_type,
ai.start_time,
ai.end_time,
ai.create_time,
ar.condition_amount,
ar.condition_num,
ar.benefit_amount,
ar.benefit_discount,
ar.benefit_level
from
(
select
id,
activity_id,
activity_type,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from ${APP}.ods_activity_rule
where dt='$do_date'
)ar
left join
(
select
id,
activity_name,
start_time,
end_time,
create_time
from ${APP}.ods_activity_info
where dt='$do_date'
)ai
on ar.activity_id=ai.id;
"
case $1 in
"dim_user_info"){
hive -e "$dim_user_info"
};;
"dim_sku_info"){
hive -e "$dim_sku_info"
};;
"dim_base_province"){
hive -e "$dim_base_province"
};;
"dim_coupon_info"){
hive -e "$dim_coupon_info"
};;
"dim_activity_rule_info"){
hive -e "$dim_activity_rule_info"
};;
"all"){
hive -e "$dim_user_info$dim_sku_info$dim_coupon_info$dim_activity_rule_info"
};;
esac

Add authority
[[email protected] bin]$ chmod +x ods_to_dim_db*

Now you can use scripts to load DIM Layer data
Be careful : load
Make sure two things before :(1)DIM All tables of layer should be created ( Before that datagrip Has been created in )
(2) Notice which script to use , At first, you should use the script loaded on the first day
Little details : The data of the time dimension table needs to be loaded manually , There is no loading statement of time dimension table in the first day loading script and daily loading script .( Before that datagrip Has been loaded in )

Execute the script
[[email protected] bin]$ ./ods_to_dim_db_init.sh all 2020-06-14

View data in table
Prove that the first day of loading is completed !!!
边栏推荐
- flex布局原理及常见的父项元素
- Hack The Box -SQL Injection Fundamentals Module详细讲解中文教程
- SAP报表开发步骤
- Real scientific weight loss
- C语言力扣第41题之缺失的第一个正数。两种方法,预处理快排与原地哈希
- Embedded sharing collection 20
- Trend of the times - the rise of cloud native databases
- 517. 超级洗衣机
- Migrate the server and reconfigure the database (the database has no monitoring, and the monitoring starts with tns-12545, tns-12560, tns-00515 errors)
- 元宇宙为服装设计展示提供数字化社交平台
猜你喜欢

代码审计之百家cms

Do you really understand fiddler, a necessary tool for testing?

C language - Advanced pointer

Recommended reading: how can testers get familiar with new businesses quickly?

Embedded development notes, practical knowledge sharing

普林斯顿微积分读本02第一章--函数的复合、奇偶函数、函数图像

Leetcode linked list problem - 206. reverse linked list (learn linked list by one question and one article)

Black eat black? The man cracked the loopholes in the gambling website and "collected wool" for more than 100000 yuan per month

Development to testing: a six-year road to automation from scratch

Attack and defense world flatscience
随机推荐
Security permission management details
Hack The Box - Web Requests Module详细讲解中文教程
Home VR panoramic display production to improve customer transformation
Embedded development notes, practical knowledge sharing
Princeton calculus reader 02 Chapter 1 -- composition of functions, odd and even functions, function images
测试必备工具之Fiddler,你真的了解吗?
高分子物理知识点
ALV程序收集
Meta analysis [whole process, uncertainty analysis] method based on R language and meta machine learning
Earth system model (cesm) practical technology
Full analysis of domain name resolution process means better text understanding
Your understanding of the "happen before principle" may be wrong?
SSH远程管理
提升命令行效率的 Bash 快捷键 [完整版]
NetCore MySql The user specified as a definer (‘admin‘@‘%‘) does not exist
IVR在voip电话系统的应用与价值
ABAP grammar learning (ALV)
SSTI-payload和各种绕过方法
Why is the value represented by a negative number greater than an integer by 1?
如何从内存解析的角度理解“数组名实质是一个地址”?