当前位置:网站首页>4 custom model training
4 custom model training
2022-06-26 15:58:00 【X1996_】
Build the model ( Forward propagation of neural networks ) --> Define the loss function --> Define optimization functions --> Definition tape --> The model gets the predicted value --> Forward propagation gets loss --> Back propagation --> Use the optimization function to update the calculated gradient to the variable
Custom model training No evaluation function
import numpy as np
import tensorflow as tf
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# Define the layers you need
self.dense_1 = tf.keras.layers.Dense(32, activation='relu')
self.dense_2 = tf.keras.layers.Dense(num_classes)
def call(self, inputs):
# Define forward propagation
# Use in (in `__init__`) Defined layer
x = self.dense_1(inputs)
return self.dense_2(x)
model = MyModel(num_classes=10)
# Instantiate an optimizer.
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3)
# Instantiate a loss function.
loss_fn = tf.keras.losses.CategoricalCrossentropy()
# Prepare the training dataset.
batch_size = 64
train_dataset = tf.data.Dataset.from_tensor_slices((data, labels))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
# epoch
#batch_size
#tape Find gradient Gradient update
# Training
epochs = 10
for epoch in range(epochs):
#print('Start of epoch %d' % (epoch,))
# Traversing the data set batch_size
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
# open GradientTape To record the operations that were run during the forward pass , This will enable automatic discrimination .
with tf.GradientTape() as tape:
# Run the forward propagation of the model . The operation of the model applied to its input will be recorded in GradientTape On .
logits = model(x_batch_train, training=True) # This minibatch The predicted value of
# Compute the minibatch The loss value of
loss_value = loss_fn(y_batch_train, logits)
# Use GradientTape Automatically obtain the gradient of the trainable variable relative to the loss .
grads = tape.gradient(loss_value, model.trainable_weights)
# Minimize the loss by updating the value of the variable , This performs a step of gradient descent .
optimizer.apply_gradients(zip(grads, model.trainable_weights))
# Every time 200 batches Print once .
print('Training loss %s epoch: %s' % (epoch, float(loss_value)))
Add evaluation function
import numpy as np
import tensorflow as tf
x_train = np.random.random((1000, 32))
y_train = np.random.random((1000, 10))
x_val = np.random.random((200, 32))
y_val = np.random.random((200, 10))
x_test = np.random.random((200, 32))
y_test = np.random.random((200, 10))
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# Define the layers you need
self.dense_1 = tf.keras.layers.Dense(32, activation='relu')
self.dense_2 = tf.keras.layers.Dense(num_classes)
def call(self, inputs):
# Define forward propagation
# Use in (in `__init__`) Defined layer
x = self.dense_1(inputs)
return self.dense_2(x)
# Optimizer
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3)
# Loss function
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
# Get ready metrics function
train_acc_metric = tf.keras.metrics.CategoricalAccuracy()
val_acc_metric = tf.keras.metrics.CategoricalAccuracy()
# Prepare the training data set
batch_size = 64
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
# Prepare the test data set
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model = MyModel(num_classes=10)
epochs = 10
for epoch in range(epochs):
print('Start of epoch %d' % (epoch,))
# Traversing the data set batch_size
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
# One batch
with tf.GradientTape() as tape:
logits = model(x_batch_train)
loss_value = loss_fn(y_batch_train, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))####
# Update the of the training set metrics
train_acc_metric(y_batch_train, logits)
# At every epoch Show at the end metrics.
train_acc = train_acc_metric.result()
# print('Training acc over epoch: %s' % (float(train_acc),))
# At every epoch Reset the training indicator at the end
train_acc_metric.reset_states()#!!!!!!!!!!!!!!!
# At every epoch Run a validation set at the end .
for x_batch_val, y_batch_val in val_dataset:
val_logits = model(x_batch_val)
# Update validation set merics
val_acc_metric(y_batch_val, val_logits)
val_acc = val_acc_metric.result()
# print('Validation acc: %s' % (float(val_acc),))
val_acc_metric.reset_states()
print('Training_losses: %s Training_acc: %s Validation_acc: %s' % (float(loss_value), float(train_acc), float(val_acc)))
边栏推荐
- Selenium chrome disable JS disable pictures
- svg野人动画代码
- 反射修改final
- 1 张量的简单使用
- Svg savage animation code
- (一)keras手写数字体识别并识别自己写的数字
- Beijing Fangshan District specialized special new small giant enterprise recognition conditions, with a subsidy of 500000 yuan
- Transformation of zero knowledge QAP problem
- Development, deployment and online process of NFT project (2)
- 【微信小程序】事件绑定,你搞懂了吗?
猜你喜欢

Summary of data interface API used in word search and translation applications

Stepn débutant et avancé

NFT 项目的开发、部署、上线的流程(1)

5000 word analysis: the way of container security attack and defense in actual combat scenarios

Evaluation - TOPSIS

Anaconda3安装tensorflow 2.0版本cpu和gpu安装,Win10系统

人人都当科学家之免Gas体验mint爱死机

9 Tensorboard的使用
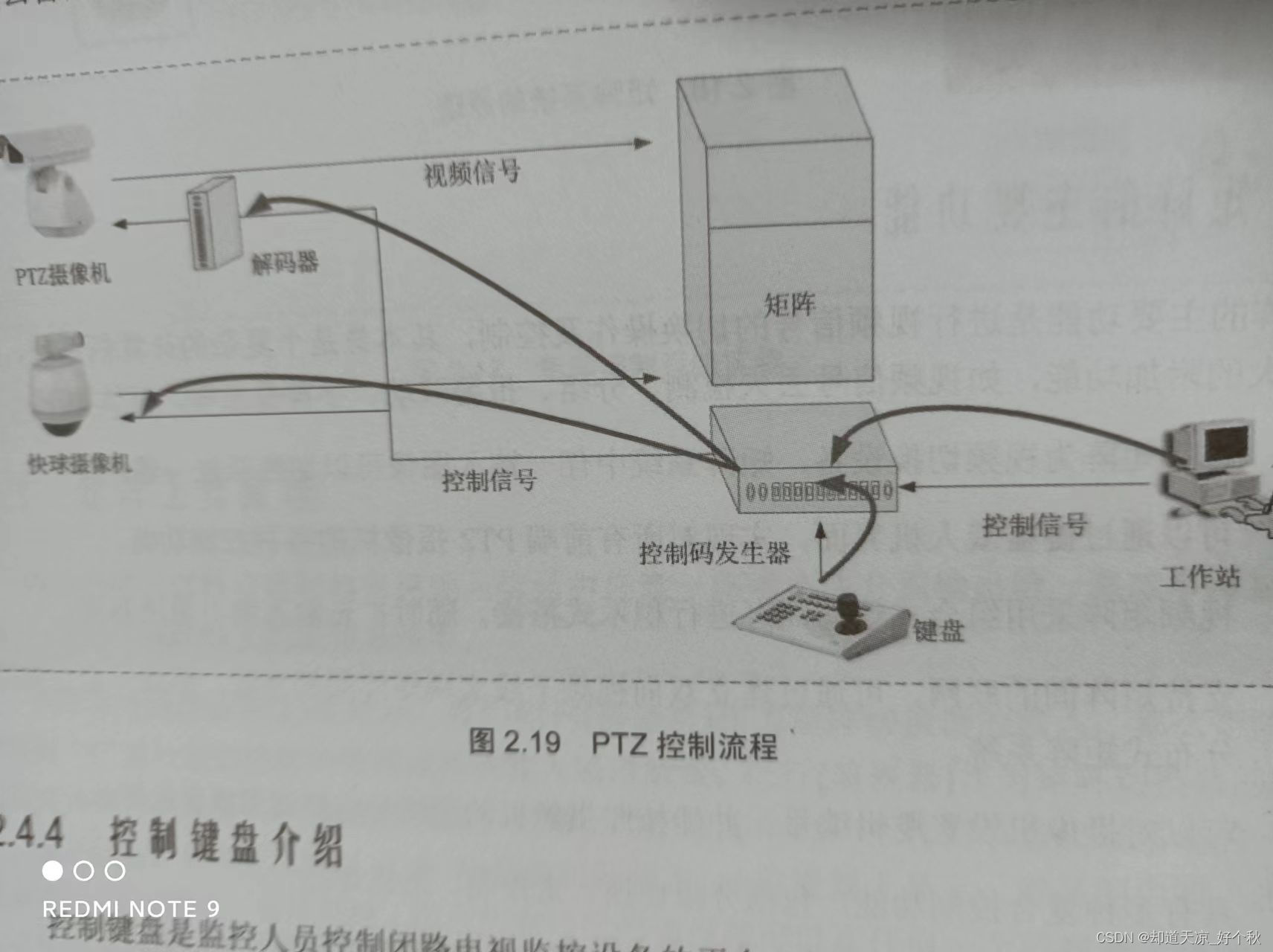
Audio and video learning (I) -- PTZ control principle

Unable to download Plug-in after idea local agent
随机推荐
selenium将元素保存为图片
Learning memory barrier
Development, deployment and online process of NFT project (2)
STEPN 新手入門及進階
Tweenmax+svg switch color animation scene
[problem solving] the loading / downloading time of the new version of webots texture and other resource files is too long
零知识 QAP 问题的转化
Transaction input data of Ethereum
9 Tensorboard的使用
Secure JSON protocol
Solana扩容机制分析(2):牺牲可用性换取高效率的极端尝试 | CatcherVC Research
[CEPH] MKDIR | mksnap process source code analysis | lock state switching example
【微信小程序】事件绑定,你搞懂了吗?
SVG大写字母A动画js特效
Nanopi duo2 connection WiFi
【leetcode】331. Verifying the preorder serialization of a binary tree
Utilisation d'abortcontroller
OpenSea上如何创建自己的NFT(Polygon)
[graduation season · advanced technology Er] what is a wechat applet, which will help you open the door of the applet
NFT合约基础知识讲解