当前位置:网站首页>Interpretation of EfficientNet: Composite scaling method of neural network (based on tf-Kersa reproduction code)
Interpretation of EfficientNet: Composite scaling method of neural network (based on tf-Kersa reproduction code)
2022-08-04 07:01:00 【hot-blooded chef】
论文:https://arxiv.org/pdf/1905.11946.pdf
代码:https://github.com/qubvel/efficientnet
1、介绍
EfficientNetThe paper attracted a lot of attention when it was published,The reason is because the result it shows kills the existing network in seconds,And in the case of a higher accuracy rate,There are few parameters,在ImageNeton the slaughter list.
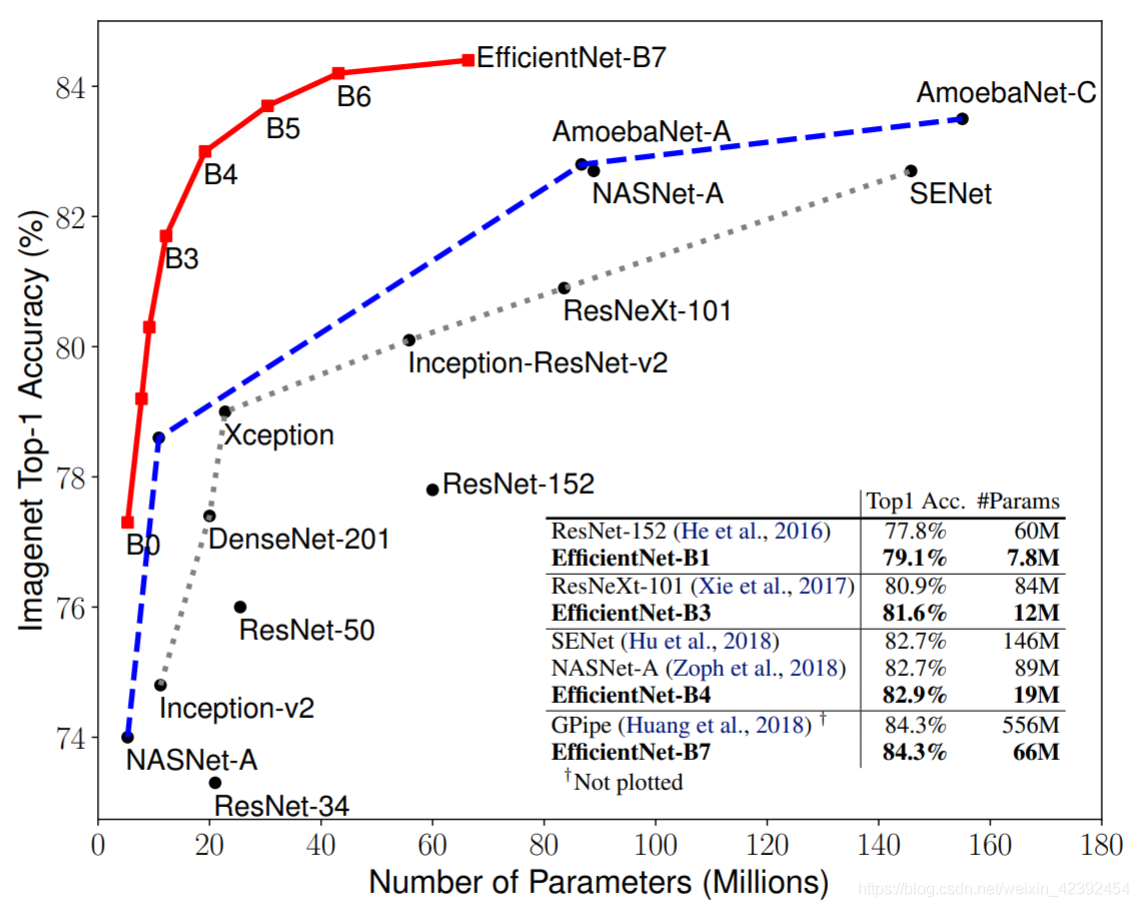
Seeing this breathtaking result,Many would argue that this paper should propose a completely new structure,To do it fast and well.其实并不是这样,作者独辟蹊径,From an angle that no one had noticed before:Quantify the relationship between the three dimensions,网络的宽度,深度和分辨率.
在之前的工作中,Usually just zoom in in three dimensions-深度,宽度,and one of the image dimensions.Although two or three dimensions can be arbitrarily increased,But arbitrary increases require tedious manual tuning and often result in sub-optimal accuracy and efficiency.
这篇文章中,The author rethinksCNNThe process of magnification.In particular, this core question is studied:Is there a principled way to growConvNetsCan achieve better accuracy and efficiency?
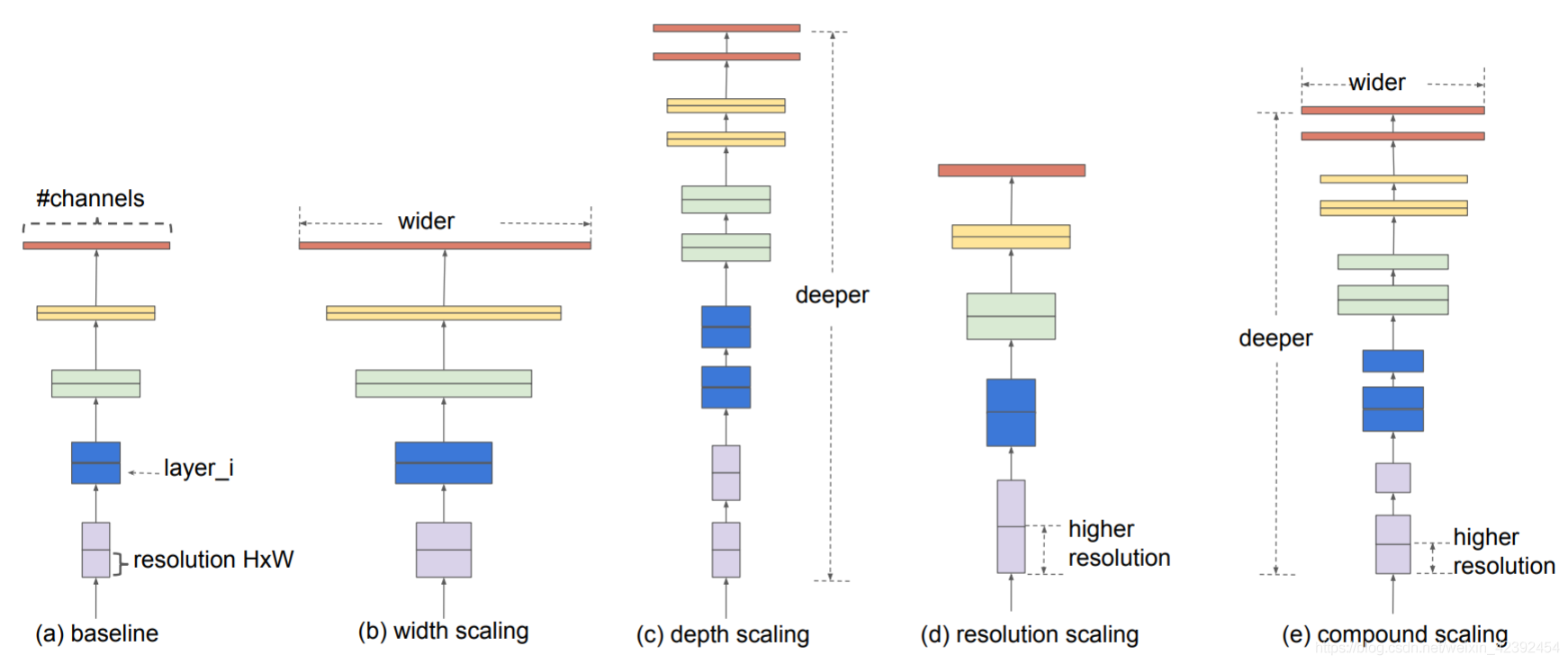
如上图所示,如果我们有一个baseline模型,例如,如果我们想要使用 2 N 2^N 2Ntimes more computing resources,那么我们可以通过 α N \alpha^N αNto increase the depth of the network,通过 β N \beta^N βN增加网络的宽度,通过 γ N \gamma^N γNto increase the resolution of the image.(b)-(d)are arbitrarily increased by one of the coefficients,(e)It is the composite scaling method proposed by the author.
2、问题公式化
定义:
一个ConvNet的第i层定义为: Y i = F i ( X i ) Y_i=F_i(X_i) Yi=Fi(Xi), Y i Y_i Yi是输出的tensor, X i X_i Xi是输入的tensor, F i F_i Fi是卷积层,输入tensor的shape为 < H i , W i , C i > <H_i, W_i,C_i> <Hi,Wi,Ci>,那么一个完整的ConvNet定义 N = F k ⨀ . . . ⨀ F 2 ⨀ F 1 ( X i ) = ⨀ j = 1... k F j ( X 1 ) N = F_k\bigodot...\bigodot F_2\bigodot F_1(X_i) = \bigodot_{j=1...k}F_j(X_1) N=Fk⨀...⨀F2⨀F1(Xi)=⨀j=1...kFj(X1).And a convolutional neural network is often divided into multiplestage,例如ResNet就被分为5个stage.
因此可以将ConvNet统一定义为:
N = ⨀ i = 1... s F i L i ( X < H i , W i , C i > ) N = \bigodot_{i=1...s}F^{L_i}_{i}(X<H_i,W_i,C_i>) N=i=1...s⨀FiLi(X<Hi,Wi,Ci>)
其中下标i(从1到s)表示的是stage的序号, F i L i F_{i}^{L_i} FiLi代表第i个stage,它由 F i F_i FiLayers are repeated L i L_i Li次构成.
与通常的ConvNet设计不同,通常的ConvNetDesign is mainly concerned with finding the best layer structure F i F_i Fi,But the author of this article did the opposite.Consistently scale the network width by a constant ratio、深度和分辨率,rather than scaling a single coefficient individually.So that the memory usage and the amount of parameters are less than the target threshold,achieve the highest accuracy.
Expressed as a formula:

其中 w , d , r w,d,r w,d,rare the width of the network, respectively,深度和分辨率的系数.其他参数同上.
3、EfficientNet
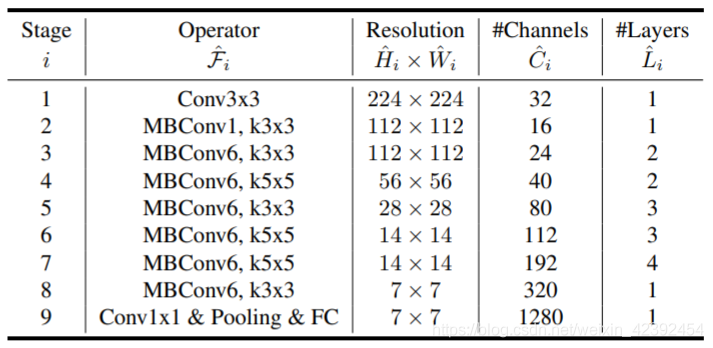
The author existsMobileNets和ResNetsThe above proves that the compound scaling method performs well,And the accuracy of the model after scaling is largely dependent on baseline网络.所以作者使用NAS(神经网络搜索)Search for a better onebaseline网络,也即EfficientNet-B0.
Efficient block
The overall design idea is very simple to use first1x1的卷积升维,Add an attention mechanism after the depthwise separable convolution operation(SENet),最后再利用1x1After convolutional dimension reduction,Merge with output.It is just a combination of the advantages of the previous networks.

EfficientNet
Eventually will these fewBlockRepeat the stacking multiple timesEfficientNet
4、实验结果
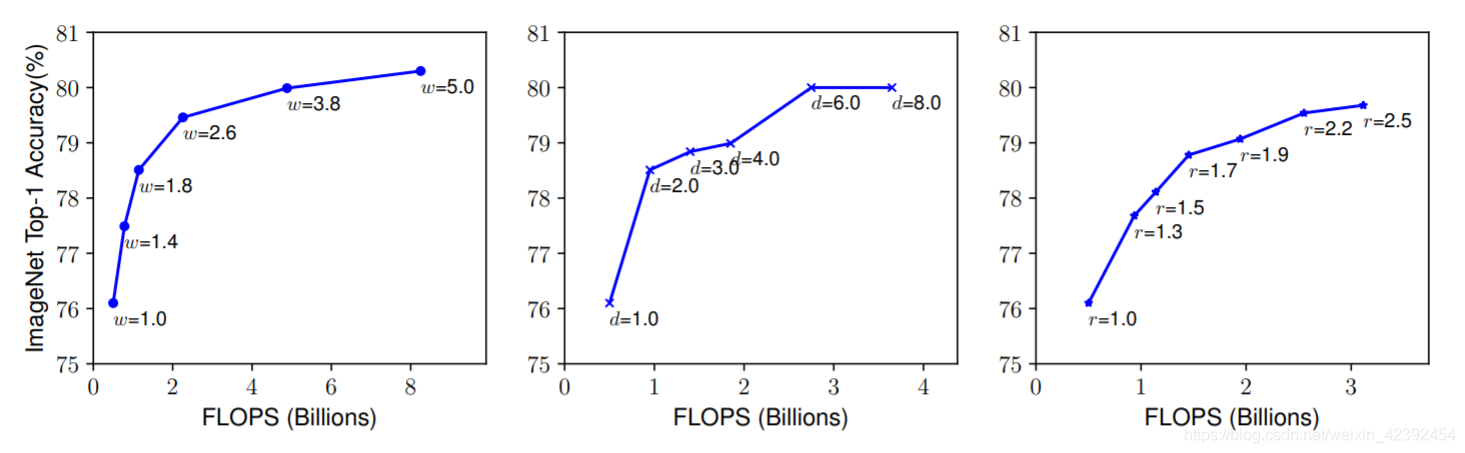
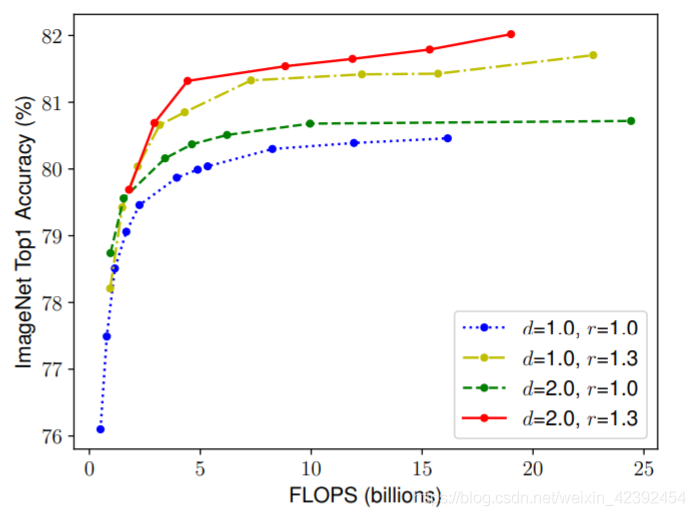
The authors first scale separately w , d , r w,d,r w,d,r的值,Often zooming in can get better accuracy,But the quasi went up to80%It will quickly saturate after that,This shows the limitations of dilating only a single dimension.
Then the author tried the method of compound scaling,直观来说,for larger resolution images,我们应该增加网络的深度,This larger receptive field helps capture similar features in larger images containing more pixels.相应的,when the resolution is higher,We should also increase the width of the network,Capture more fine-grained patterns in high-resolution images with more pixels.This means that we need to coordinate and balance scaling in different dimensions,instead of the traditional scaling of a single dimension.
为了验证这个想法,The authors compare the results of scaling widths at different network depths and resolutions,如下图所示.If just scaling the network width w w w,而不改变深度( d = 1.0 d=1.0 d=1.0)和分辨率( r = 1.0 r=1.0 r=1.0),Accuracy will quickly saturate.And in deeper( d = 2.0 d=2.0 d=2.0)and higher resolutions( r = 2.0 r=2.0 r=2.0),Scaling the width of the network achieves better accuracy with the same amount of computation.
5、结论
基于上述的实验结果,The paper presents a new one复合缩放方法,使用一个复合系数 ϕ \phi ϕto consistently scale the width of the network,Depth and resolution in a specified way
定义:
d e p t h : d = α ϕ w i d t h : w = β ϕ r e s o l u t i o n : r = γ ϕ depth: d=\alpha^\phi\\ width: w=\beta^\phi\\ resolution: r=\gamma^\phi\\ depth:d=αϕwidth:w=βϕresolution:r=γϕ
Suggested formula for scaling factor:
s . t . α ⋅ β 2 ⋅ γ 2 ≈ 2 α ≥ 1 , β ≥ 1 , γ ≥ 1 s.t. \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2\\ \alpha \geq 1, \beta \geq1, \gamma\geq1 s.t.α⋅β2⋅γ2≈2α≥1,β≥1,γ≥1
So for anything new ϕ \phi ϕThe total number of operations will increase approximately 2 ϕ 2^\phi 2ϕ
边栏推荐
猜你喜欢

随机推荐
解决腾讯云DescribeInstances api查询20条记录以上的问题
vs2017 redist 下载地址
20170729
数据库文档生成工具V1.0
为什么不使用VS管理QT项目
并发概念基础:线程安全与线程间通信
天鹰优化的半监督拉普拉斯深度核极限学习机用于分类
MAML原理讲解和代码实现
生成一个包含日期的随机编码
IP 核之 MMCM/PLL 实验
数据库sql的基础语句
如何在网页标题栏中加入图片!
Jackson 使用样例
数据库:整理四个实用的SQLServer脚本函数
基于Webrtc和Janus的多人视频会议系统开发7 - publish和subscribe声音设备冲突导致对方听不到声音
Memory limit should be smaller than already set memoryswap limit, update the memoryswap at the same
Multi-threaded sequential output
Visualization and Animation Technology (Computer Animation)
Flask request 返回网页中 checkbox 是否选中
狗都能看懂的变化检测网络Siam-NestedUNet讲解——解决工业检测的痛点