当前位置:网站首页>What is Flink? What can Flink do?
What is Flink? What can Flink do?
2022-06-25 12:09:00 【Ink mark vs. breeze】
summary
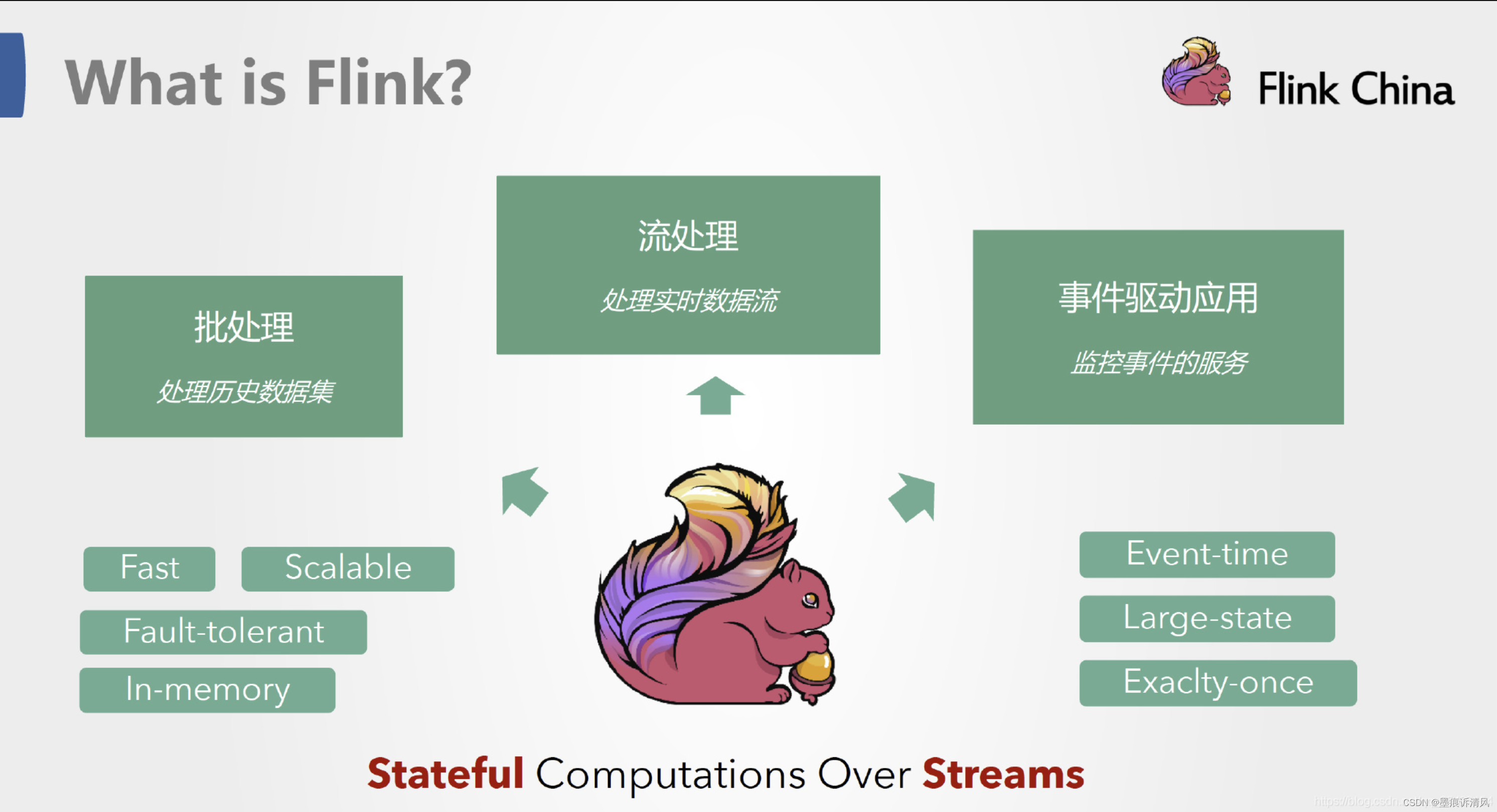
Apache Flink It's a frame and Distributed Processing engine , Used in Borderless and Boundary On the data stream A stateful The calculation of .Flink Can run in all common cluster environments , And can be calculated at memory speed and any scale .
Apache Flink Powerful , Support the development and running of many different kinds of applications . Its main features include : Batch flow integration 、 Sophisticated state management 、 Event time support and accurate state consistency guarantee etc .Flink Not only can it run in include YARN、 Mesos、Kubernetes In the framework of multiple resource management , It also supports independent deployment on bare metal cluster . With the high availability option enabled , It has no single point of failure . The fact proved that ,Flink It can be extended to thousands of cores , Its state can be achieved TB Level , And can still maintain high throughput 、 Low latency features . There are many demanding stream processing applications running around the world Flink above .
Next , Let's introduce it Flink Some important concepts in .
Batch and stream
The batch Is characterized by bounded 、 persistent 、 A lot of , Ideal for computing that requires access to a full set of records , It is generally used for offline statistics .
Stream processing Is characterized by boundlessness 、 real time , There is no need to perform operations on the entire dataset , Instead, it performs operations on each data item transmitted through the system , Generally used for real-time statistics .
stay Spark In my world view , It's all about batch Composed of , Offline data is a large batch , Real time data is composed of infinite small batches . And in the Flink In my world view , It's all about flow Composed of , Offline data is a bounded stream , Real time data is a stream without boundaries , This is called bounded flow and unbounded flow .
- By incident : There is the beginning of a defined flow , But the end of the flow is not defined . They produce data endlessly . The data of unbounded flow must be processed continuously , That is, the data needs to be processed immediately after being ingested . We can't wait until all the data arrives , Because the input is infinite , The input will not be completed at any time . Processing unbounded data usually requires ingesting events in a specific order , For example, the sequence of events , So that we can infer the integrity of the result .
- Bounded flow : There is the beginning of a defined flow , It also defines the end of the flow . A bounded flow can compute after taking all the data . All data in a bounded flow can be sorted , So there's no need for an orderly intake . Bounded flow processing is often referred to as batch processing .

Flink Good at dealing with unbounded and bounded data sets Precise time control and statefulness make Flink Runtime (runtime) Be able to run any application that handles unbounded flows . Bounded flows are handled internally by algorithms and data structures specially designed for fixed size datasets , Produces excellent performance .
Deploy it anywhere
Apache Flink It's a distributed system , It requires computing resources to execute the application .Flink Integrates all the common cluster resource managers , for example Hadoop YARN、 Apache Mesos and Kubernetes, But it can also run as a stand-alone cluster .
Flink Designed to work well in each of the above resource managers , This is done through the resource manager (resource-manager-specific) Implementation of the deployment pattern .Flink You can interact in a manner appropriate to the current explorer .
Deploy Flink Application time ,Flink The required resources are automatically identified according to the parallelism of the application configuration , And request these resources from the resource manager . In case of failure ,Flink Replace the failed container by requesting new resources . All communication to submit or control the application is through REST The call made , This can simplify Flink Integration with various environments .
Take advantage of memory performance
Stateful Flink The program is optimized for local state access . The state of the task is always kept in memory , If the state size exceeds the available memory , It will be saved in a disk data structure that can be accessed efficiently . Tasks are accessed locally by ( Usually in memory ) State to perform all calculations , This results in very low processing latency .Flink The local state is persisted and stored periodically and asynchronously to ensure the accurate state consistency in the fault scenario .

layered API
Flink According to the degree of abstraction , Three different ones are offered API. Each of these API There are different emphases on conciseness and expressiveness , And for different application scenarios .

- ProcessFunction: It can handle a single event in one or two input data streams or multiple events in a specific window . It provides fine-grained control of time and state . The developer can modify the state at will , You can also register a timer to trigger a callback function at some point in the future . therefore , You can use ProcessFunction Complex business logic based on single event is needed to implement many stateful event driven applications .
- DataStream API: Provides processing primitives for many common stream processing operations . These operations include windows 、 Record by record conversion operation , External database query when handling events, etc .DataStream API Support Java and Scala Language , Pre defined, for example map()、reduce()、aggregate() Such as function . You can implement predefined interfaces through extensions or use Java、Scala Of lambda Expressions implement custom functions .
- SQL & Table API:Flink Supporting two types of relationship API,Table API and SQL. these two items. API Both batch and stream processing are unified API, This means on the borderless real-time data stream and the bounded historical data stream , Relational type API The query will be executed with the same semantics , And produce the same result .Table API and SQL With the help of Apache Calcite To parse the query , Verification and optimization . They can be associated with DataStream and DataSet API Seamless integration , And support user-defined scalar functions , Aggregate functions and table valued functions .Flink Relation type of API Designed to simplify data analysis 、 Data pipeline and ETL Definition of application .
characteristic
Apache Flink It's a aggregate Many competitive third-generation stream processing engines , Its following characteristics make it stand out from other similar systems .
1. At the same time, it supports high throughput 、 Low latency 、 High performance .
Flink It is the only set of high throughput in the open source community 、 Low latency 、 A high-performance three in one distributed streaming processing framework . image Apache Spark It can only take into account the characteristics of high throughput and high performance , Mainly because of Spark Streaming Low delay guarantee cannot be achieved in streaming computing ; And the flow computing framework Apache Storm Only low latency and high performance features are supported , But it can't meet the requirement of high throughput .
2. Both event time and processing time semantics are supported .
In the field of flow computing , Window computing is very important , But at present, most frame window calculations use processing time , That is, the current time of the system host when the event is transferred to the computing framework for processing .Flink It can support window calculation based on event time semantics , That is, using the time when the event occurred , This event driven mechanism enables events to arrive even in disorder , The flow system can also calculate accurate results , Ensure the original timing of events .
3. Support stateful Computing , And provide accurate one-time state consistency guarantee .
The so-called state is to save the intermediate result data of the operator in the memory or file system in the process of stream computing , After the next event enters the operator, the current result can be calculated from the intermediate result obtained from the previous state , Therefore, it is not necessary to count the results based on all the original data every time , This way greatly improves the performance of the system , And reduce the resource consumption of data calculation process .
4. Fault tolerance mechanism based on lightweight distributed snapshot .
Flink It can run on thousands of nodes in a distributed way , Break up the flow of a large calculation task into a small calculation process , And then Task Distributed to parallel nodes for processing . During the execution of the task , It can automatically discover the data inconsistency caused by errors in the event processing process , under these circumstances , Based on distributed snapshot technology Checkpoints, Persist the state information during execution , Once the task terminates abnormally ,Flink From the Checkpoints Automatic recovery of tasks in , To ensure consistency in data processing .
5. High availability is guaranteed , Dynamic expansion , Realization 7 * 24 24 hours a day .
Support high availability configuration ( No single point of failure ), and Kubernetes、YARN、Apache Mesos Tight integration , Fast fault recovery , Dynamic expansion and contraction, etc . Based on the above characteristics , It can 7 X 24 Run streaming applications for hours , Almost no downtime . When dynamic update or quick recovery is required ,Flink adopt Savepoints Technology saves the snapshot of task execution on the storage media , When the task is restarted, you can directly engage in the first saved Savepoints Restore the original calculation state , Make the task continue to run as it was before the shutdown .
6. Support highly flexible window operation .
Flink Divide the window based on Time、Count、Session, as well as Data-driven And so on , Windows can be customized with flexible trigger conditions to support complex streaming modes , Users can define different window triggering mechanisms to meet different needs .
Application scenarios
In the actual production process , A lot of data is being produced , For example, financial transaction data 、 Internet order data 、GPS Location data 、 Sensor signal 、 Data generated by mobile terminals 、 Communication signal data, etc , As well as our familiar network traffic monitoring 、 Log data generated by the server , The biggest common ground of these data is that they are generated from different data sources in real time , Then it is transmitted to the downstream analysis system .
These data types mainly include the following scenarios ,Flink There is very good support for these scenarios .
1. Real time intelligent recommendation
utilize Flink Stream computing helps users build more real-time intelligent recommendation systems , Real time calculation of user behavior index , Update the model in real time , Real time prediction of user indicators , And push the predicted information to Web/App End , Help users get the information they want , On the other hand, it also helps enterprises increase sales , Create greater business value .
2. Complex event handling
For example, complex event processing in the industrial field , The data volume of these business types is very large , And it has high requirements for timeliness of data . We can use Flink Provided CEP( Complex event handling ) Extract event patterns , Simultaneous application Flink Of SQL Transform event data , Build real-time rule engine in streaming system .
3. Real time fraud detection
In the business of Finance , There are all kinds of frauds . Application Flink Streaming computing technology can complete the calculation of fraud judgment behavior indicators in milliseconds , Then, the rule judgment or model prediction of transaction flow can be carried out in real time , In this way, once it is detected that there is a suspicion of fraud in the transaction , Then it directly intercepts the transaction in real time , Avoid economic loss caused by untimely handling
4. Real time data warehouse and ETL
Combined with offline data warehouse , By taking advantage of many advantages and SQL Flexible processing power , Real time cleaning of convection data 、 Merger 、 Structured processing , Supplement and optimize the offline data warehouse . On the other hand, combine real-time data ETL processing capacity , Using stateful flow computing technology , As far as possible, the complexity of scheduling logic in the process of off-line data computation can be reduced , Efficient and rapid processing of statistical results needed by enterprises , Help enterprises better apply the results of real-time data analysis .
5. Stream data analysis
Real time calculation of various data indicators , And use the real-time results to adjust the relevant strategies of the online system in time , Launch in various categories 、 There are a lot of applications in the field of wireless intelligent push . Streaming computing technology makes data analysis scene real-time , Help enterprises to do real-time analysis Web Application or App Various indicators applied .
6. Real time report analysis
Real time report analysis is one of the report statistics schemes adopted by many companies in recent years , One of the most important applications is real-time large screen display . The real-time results obtained by streaming computing are directly pushed to the front application , Real time display of important indicator changes , The most typical case is Taobao's "double 11" real-time war report .
Flink VS Spark Streaming
Data model
Flink The basic data model is data flow , And the sequence of events .
Spark use RDD Model ,Spark Streaming Of DStream In fact, it is a small batch
data RDD Set .
Runtime schema
Flink Is the standard flow execution mode , An event can be directly sent to the next section after being processed by a node
Point for processing .
Spark It's batch calculation , take DAG Divide into different Stage, The next calculation can be completed after .
to update Fink Knowledge column
边栏推荐
- Solution to the timeout scenario of Flink streaming computing (official live broadcast)
- 19、wpf之事件转命令实现MVVM架构
- VFP uses Kodak controls to control the scanner to solve the problem that the volume of exported files is too large
- RecyclerView滚动到指定位置
- Encapsulation of practical methods introduced by webrtc native M96 basic base module (MD5, Base64, time, random number)
- 黑馬暢購商城---3.商品管理
- ThingsPanel 發布物聯網手機客戶端(多圖)
- Translation of meisai C topic in 2022 + sharing of ideas
- Cesium building loading (with height)
- Flink deeply understands the graph generation process (source code interpretation)
猜你喜欢
优品购电商3.0微服务商城项目实战小结

devsecops与devops的理解与建设

Use PHP script to view the opened extensions
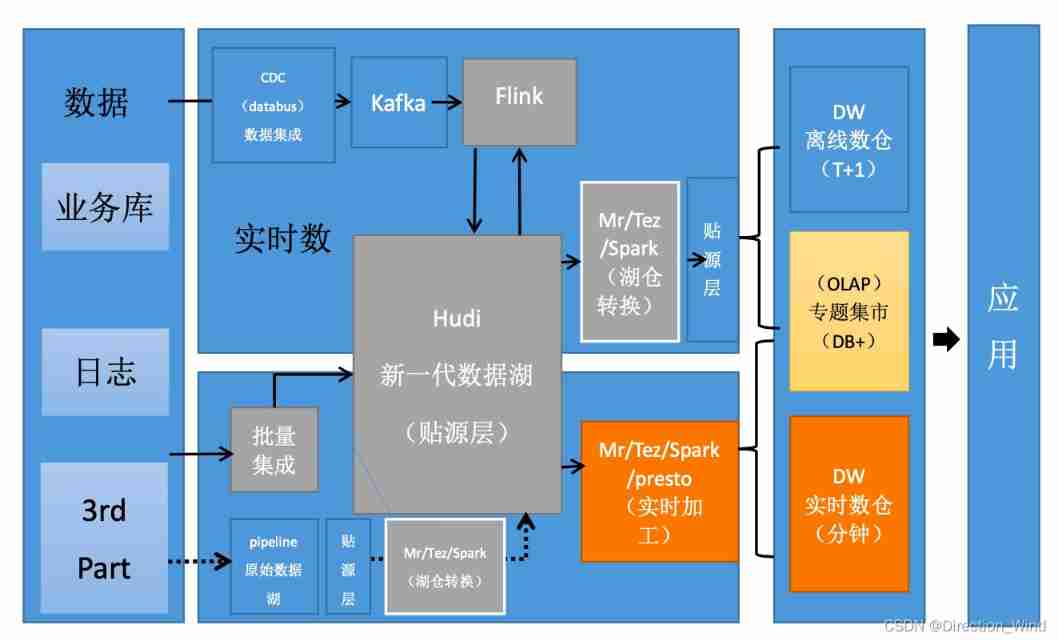
Data Lake survey
ThingsPanel 發布物聯網手機客戶端(多圖)

Time series analysis - how to use unit root test (ADF) correctly?

How terrible is it not to use error handling in VFP?

Translation of meisai C topic in 2022 + sharing of ideas

Dark horse shopping mall ---8 Microservice gateway and JWT token

Dark horse shopping mall ---6 Brand, specification statistics, condition filtering, paging sorting, highlighting
随机推荐
Explanation of ideas and sharing of pre-processing procedures for 2021 US game D (with pre-processing data code)
15、wpf之button样式小记
剑指 Offer II 091. 粉刷房子 : 状态机 DP 运用题
动态代理
The idea of mass distribution of GIS projects
Is the online stock trading account opening ID card information safe?
属性分解 GAN 复现 实现可控人物图像合成
A set of automated paperless office system (oa+ approval process) source code: with data dictionary
Why can't you Ping the website but you can access it?
实现领域驱动设计 - 使用ABP框架 - 系列文章汇总
网络 | traceroute,路由跟踪命令,用于确定 IP 数据包访问目标地址所经过的路径。
Dark horse shopping mall ---2 Distributed file storage fastdfs
Kotlin基础
20、wpf之MVVM命令绑定
If you also want to be we media, you might as well listen to Da Zhou's advice
Why should Apple change objc_ Type declaration for msgsend
Cesium editing faces
SQL server saves binary fields to disk file
SMS verification before deleting JSP
PyCaret 成功解决无法从‘sklearn.model_selection._search‘导入名称“_check_param_grid”