当前位置:网站首页>Flink_CDC搭建及简单使用
Flink_CDC搭建及简单使用
2022-07-30 20:14:00 【iijik55】
Flink_CDC搭建及简单使用
1.CDC简介:
CDC (Change Data Capture) ,在广义的概念上,只要能捕获数据变更的技术,都可以称为 CDC 。但通常我们说的CDC 技术主要面向数据库(包括常见的mysql,Oracle, MongoDB等)的变更,是一种用于捕获数据库中数据变更的技术。
目前市面上的CDC技术非常多,常见的主要包括Flink CDC,DataX,Canal,Sqoop,Kettle,Oracle Goldengate,Debezium等。DataX,Sqoop和kettle的CDC实现技术主要是基于查询的方式实现的,通过离线调度查询作业,实现批处理请求。这种作业方式无法保证数据的一致性,实时性也较差。Flink CDC,Canal,Debezium和Oracle Goldengate是基于日志的CDC技术。这种技术,利用流处理的方式,实时处理日志数据,保证了数据的一致性,为其他服务提供了实时数据。
2.Flink_CDC简介:
目前公司主要是通过canal监控mysql的binlog日志,然后将日志数据实时发送到kafka中,通过flink程序,将日志数据实时下发到其他服务中。这种方式,数据链路长,实时性效果较差,运维也比较复杂。
Flink_CDC技术的出现,解决了传统数据库实时同步的痛点。Flink_CDC通过伪装成msql的slave节点,实时读取master节点全量和增量数据,它能够捕获所有数据的变化,捕获完整的变更记录,无需像查询CDC那样发起全表的扫描过滤,高效且无需入侵代码,完全与业务解耦,运维及其简单。
3.Flink_CDC部署:
3.1 依赖版本
环境:Linux(Centos7)
Flink : 1.31.1
Flink_CDC: flink-sql-connector-mysql-cdc-2.1.0.jar
mysql版本:8.0.13
mysql驱动包:mysql-connector-java-8.0.13.jar
3.2环境搭建
3.2.1安装java环境(不再赘述);
3.2.2安装数据库(不在赘述);
3.2.3搭建Flink环境(单机模式);
1.获取flink版本。
cd /home
wget https://archive.apache.org/dist/flink/flink-1.9.0/flink-1.13.1-bin-scala_2.11.tgz
2.解压flink:
tar -zxvf flink-1.13.1-bin-scala_2.11.tgz
3.编辑flink配置文件,配置java环境
cd flink-1.13.1
vim conf/flink-conf.yaml
添加配置:env.java.home=/home/jdk/jdk1.8.0_291
4.上传flink_CDC驱动包和mysql驱动包:
cd flink-1.13.1/lib
上传:
flink-sql-connector-mysql-cdc-2.1.0.jar
mysql-connector-java-8.0.13.jar
5.启动flink集群:
/bin/start-cluster.sh
3.3创建mysql表:
CREATE TABLE `products` (
`id` int NOT NULL,
`name` varchar(45) DEFAULT NULL,
`description` varchar(45) DEFAULT NULL,
`weight` decimal(10,3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
3.4启动flink-sql-client
本次主要是通过flink的sql客户端来测试的。
./flink-1.13.1/bin/sql-client.sh
3.5创建Flink_CDC虚拟表:
CREATE TABLE `products_cdc` (
id INT NOT NULL,
name varchar(32),
description varchar(45),
weight DECIMAL(10,3)
) WITH (
'scan.incremental.snapshot.enabled' = 'false',
'connector' = 'mysql-cdc',
'hostname' = '0.0.0.0',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test_db',
'table-name' = 'products'
);
###如果未设置'scan.incremental.snapshot.enabled' = 'false',会报错:
Caused by: org.apache.flink.table.api.ValidationException: The primary key is necessary when enable 'Key: 'scan.incremental.snapshot.enabled' , default: true (fallback keys: [])' to 'true'
at com.alibaba.ververica.cdc.connectors.mysql.table.MySqlTableSourceFactory.validatePrimaryKeyIfEnableParallel(MySqlTableSourceFactory.java:186)
at com.alibaba.ververica.cdc.connectors.mysql.table.MySqlTableSourceFactory.createDynamicTableSource(MySqlTableSourceFactory.java:85)
at org.apache.flink.table.factories.FactoryUtil.createTableSource(FactoryUtil.java:134)
... 30 more
###报错原因:
MySQL CDC源表在Flink 1.13版本会进行语法检查,在MySQL CDC DDL WITH参数中,未设置主键(Primary Key)信息。因为Flink 1.13版本,新增支持按PK分片,进行多并发读取数据的功能。
###解决方案:
如果在Flink 1.13版本,您需要多并发读取MySQL数据,则在DDL中添加PK信息。
如果在Flink 1.13版本,您不需要多并发读取MySQL数据,则在DDL中添加scan.incremental.snapshot.enabled 参数,且把该参数值设置为false,无需设置PK信息。
3.6查询CDC表数据:
3.6.1 查看表数据
select * from products_cdc;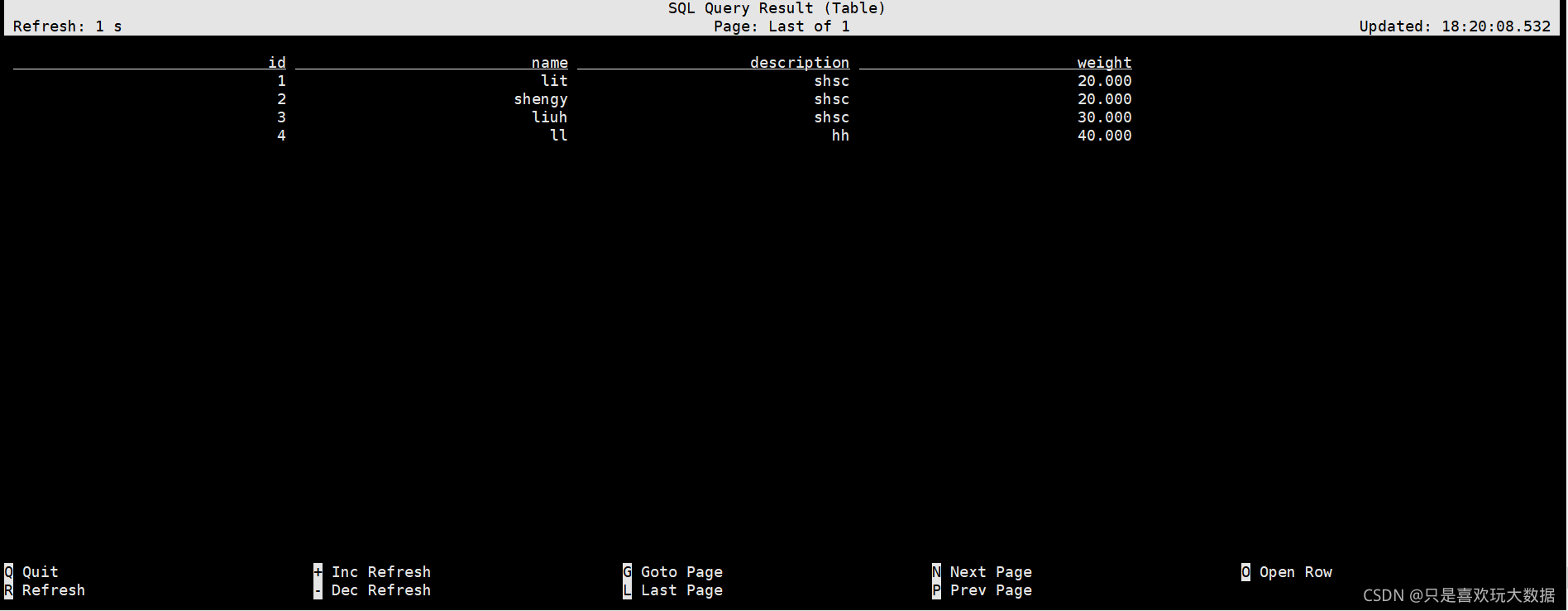
3.6.2 在数据库中新增一条数据:
insert into products(id,name,description,weight) values(5,‘gg’,‘haha’,60);
3.6.3观察products_cdc表数据变化;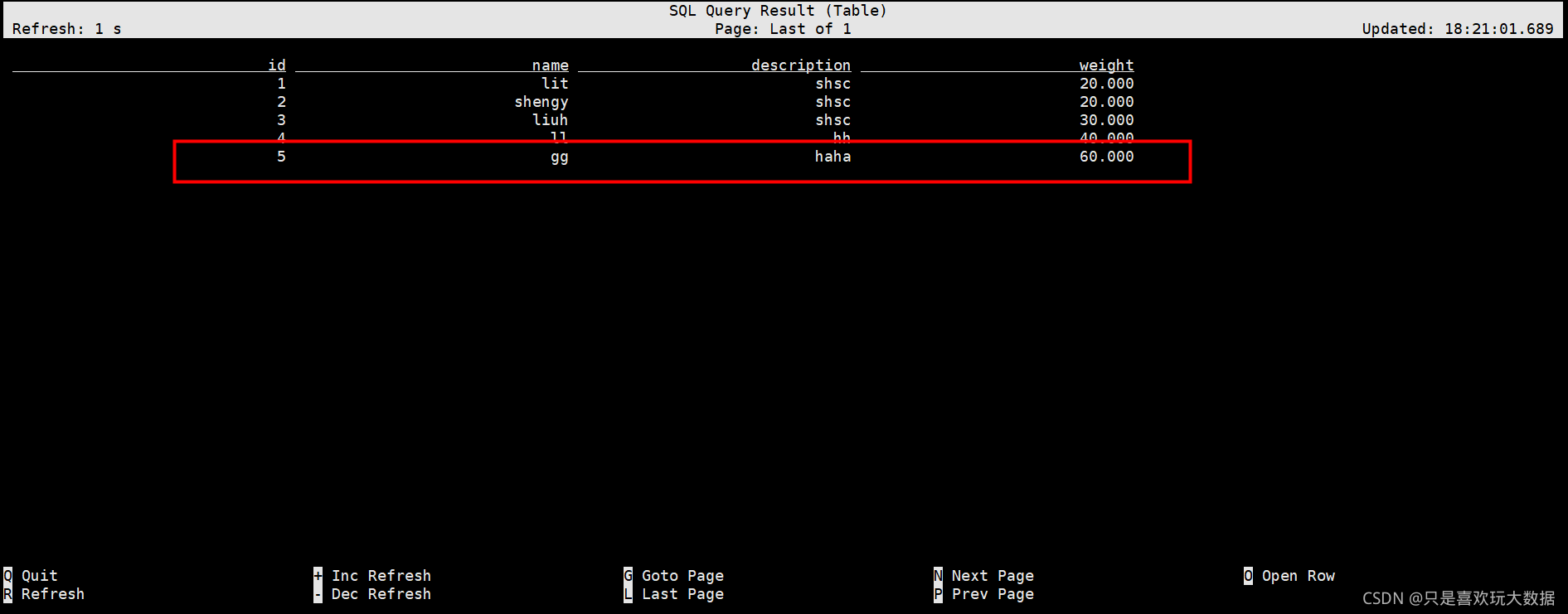
到此,通过flink-sql-client来增量获取mysql全量和增量数据变化的样例已结束。
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
边栏推荐
- .eslintrc.js for musicApp
- 推荐系统-模型:FNN模型(FM+MLP=FNN)
- YOLO V3详解
- 明解C语言第七章习题
- Running the evict task with compensationTime
- Recommendation System - Sorting Layer - Model (1): Embedding + MLP (Multilayer Perceptron) Model [Deep Crossing Model: Classic Embedding + MLP Model Structure]
- 【无标题】多集嵌套集合使不再有MultipleBagFetchException
- el-input can only input integers (including positive numbers, negative numbers, 0) or only integers (including positive numbers, negative numbers, 0) and decimals
- 基于人脸的常见表情识别(2)——数据获取与整理
- The JDBC programming of the MySQL database
猜你喜欢
idea plugins搜索不到插件

推荐系统:开源项目/工具【谷歌:TensorFlow Recommenders】【Facebook:TorchRec】【百度:Graph4Rec】【阿里:DeepRec和EasyRec】

Apple Silicon配置二进制环境(一)
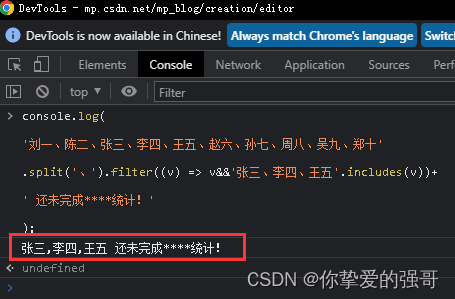
【PM专用】快速统计团队还有谁没有登记上报信息,快速筛选出属于自己项目组的成员,未完成XXX工作事项的名单
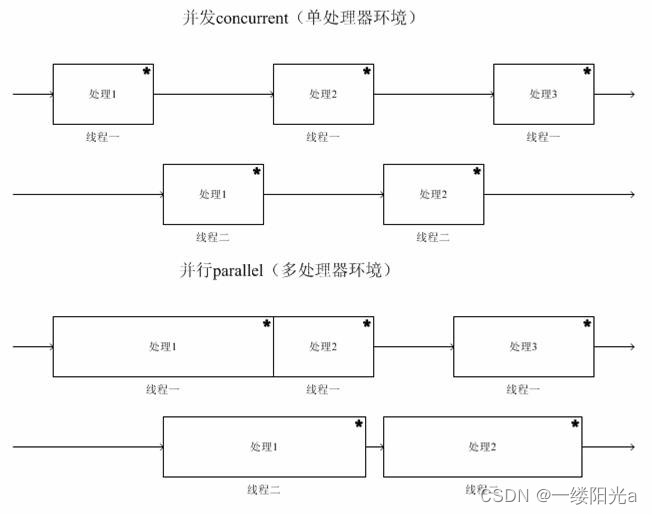
Difference Between Concurrency and Parallelism

化二次型为标准型

360杜跃进:太空安全风险加剧,需打造一体化防御体系
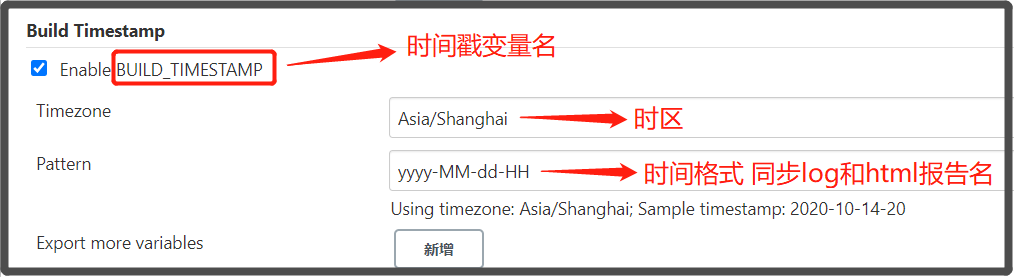
一文2500字手把手教你配置Jenkins自动化邮件通知
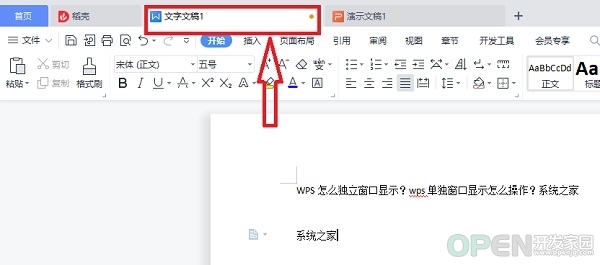
WPS怎么独立窗口显示?wps单独窗口显示怎么操作?
并发与并行的区别
随机推荐
excel数字如何转换成文本?excel表格数据转换成文本的方法
在jOOQ中获取数据的多种不同方式
MySQL大总结
MySQL_关于JSON数据的查询
HMS Core Discovery第16期回顾|与虎墩一起,玩转AI新“声”态
MySQL kills 10 questions, how many questions can you stick to?
【Codeforces思维题】20220728
MySql密码
ELK日志分析系统
Based on the face of the common expression recognition - model building, training and testing
Weak Banks to data conversion ability?Matt software help solve bank dilemma
推荐系统:AB测试(AB Test)
Redisson 的分布式锁找不到?
想要写出好的测试用例,先要学会测试设计
网络层协议------IP协议
MySQL复制表结构、表数据的方法
【请教】SQL语句按列1去重来计算列2之和?
PPT如何开启演讲者模式?PPT开启演讲者模式的方法
Scala类中的属性
FFmpeg —— 将mp4转为gif输出(附源码)