当前位置:网站首页>COVID-CT新冠肺炎检测(DenseNet网络)
COVID-CT新冠肺炎检测(DenseNet网络)
2022-08-04 11:31:00 【Blue Hole】
2020年新冠肺炎席卷全球,经过科学家的研究发现,新冠病毒经过呼吸道,进入我们的肺部。我们的肺部,绝大部分都是肺泡,而肺泡里面是空气。由于空气对X射线的衰减很小,即CT数很小,所以健康肺部在CT图中基本是黑色的。新冠病毒到达肺部之后,通过肺泡孔扩散,然后附着在肺泡上皮,其间会引起我们免疫系统的反应,大量免疫细胞会去和新冠病毒大战,这些会改变肺泡的物理性质(如肺泡肿胀、肺泡间隔液体的渗出,肺泡间隔增厚等),这样就会在CT图中露出痕迹。所以我们就是通过观察肺部CT中的痕迹,以及病毒的特点来判断是否有可能感染新冠病毒。本篇博客主要是学习记录,参考了新冠肺炎CT影像识别(二分类 | 逻辑回归)。
COVID-CT中把新冠肺炎CT图片识别,当做的一个二分类问题,即肺部CT中有新冠病毒和无病毒两种情况。CSDN的作者意疏改了代码结构、删了很多东西也引入了visdom来可视化训练过程。作为一个深度学习初学者,主要是体验一下过程。我参照作者给的逻辑,将代码写在notebook中,做了一下数据的分析,以及重新组织代码。
这次主要采用 DenseNet网络结构。
提示
由于我没有GPU,我是使用CPU训练的。大家如果有GPU,则只需要取消下按照下图更改即可:
- 定义训练函数

- 定义训练过程

- 定义测试过程

环境搭建
pip install --upgrade visdom
数据处理
1. 下载数据
本次实训,我们将采用来自加州大学圣地亚哥分校、Petuum 的研究者构建了一个开源的 COVID-CT 数据集,其中包含216例患者的349张COVID-19 CT图像和463张非COVID-19 CT图像。
下载地址:https://github.com/UCSD-AI4H/COVID-CT
- 我们主要关注
Data-splitImages-processed这两个文件夹。
2. 观察数据集
2.1 数据类
在Images-processed文件夹下,CT_COVID(阳性) CT_NonCOVID(阴性)
我们发现Images-processed文件夹下有一些损坏的数据集,如下图。

我们使用替换的方法将这些数据集给替换了
import os
import numpy as np
import pandas as pd
import seaborn as sns
from PIL import Image
from PIL import ImageEnhance
from skimage.io import imread
import matplotlib.pyplot as plt
import cv2
# 创建存储新的文件夹
new_file = './newfile/'
if not os.path.exists(new_file):
os.makedirs(new_file)
# 将损坏的数据集凡在damage_data文件夹
# 将损坏的数据名称用enumerate() 函数存储起来
lists = os.listdir('damage_data')
lists_a = enumerate(lists)
# 随机挑选一张新冠肺炎的照片做完样本
img=cv2.imread("./1.png")
# 生成照片
for i, j in lists_a:
copyimg=np.zeros(img.shape,np.uint8)
copyimg=img.copy()
grayimg=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv2.imwrite(new_file + j ,img,[int(cv2.IMWRITE_JPEG_QUALITY),5])
cv2.waitKey(0)
cv2.destroyAllWindows()
print('完成')
- 结束后将生成的照片拷贝到原来的文件夹
2.2 查看CT_COVID(阳性) 阳性数据集
dataset='./Images-processed/'
ct_h = os.path.join(dataset,"CT_COVID")
select_ct="CT_COVID"
rows,columns = 4,5
display_folder=os.path.join(ct_h,select_ct)
lists = os.listdir(display_folder)
# print(lists)
lists = enumerate(lists)
print(lists)
total_images=rows*columns
fig=plt.figure(1, figsize=(20, 10))
for i, j in lists:
img = plt.imread(os.path.join('./Images-processed/CT_COVID/CT_COVID/',j))
fig=plt.subplot(rows, columns, i+1)
fig.set_title(select_ct, pad = 11, size=20)
plt.imshow(img)
if i==total_images-1:
break
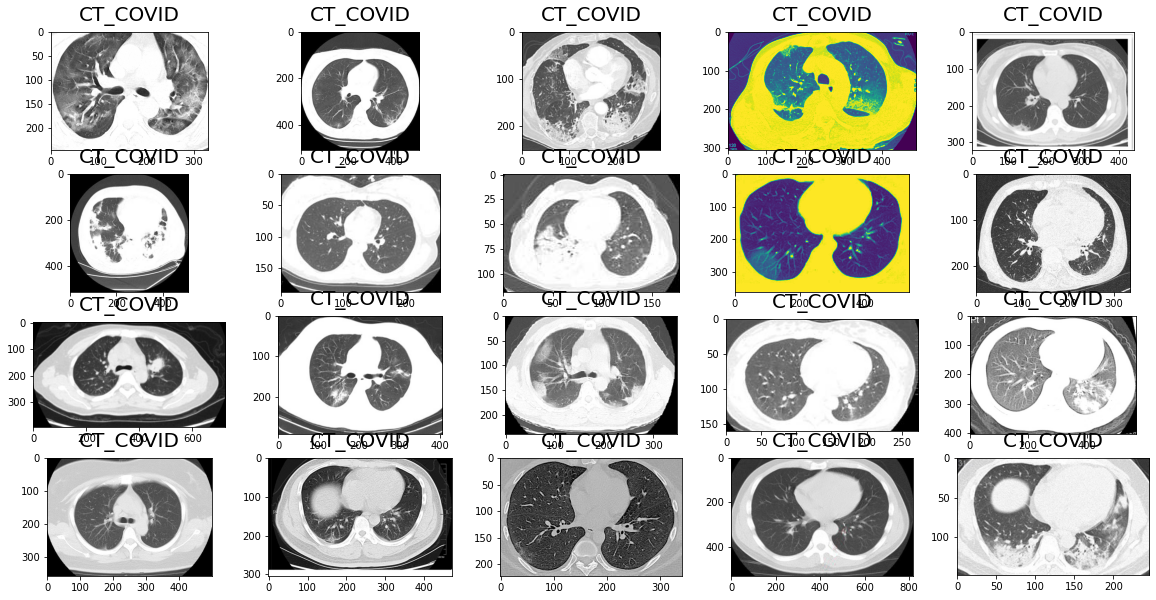
2.3 查看没有得新冠得数据集
dataset='./Images-processed/'
select_ct="CT_NonCOVID"
rows,columns = 4,5
lists = os.listdir('./Images-processed/CT_NonCOVID/')
lists = enumerate(lists)
total_images=rows*columns
fig=plt.figure(1, figsize=(20, 10))
for i, j in lists:
img = plt.imread(os.path.join('./Images-processed/CT_NonCOVID/',j))
fig=plt.subplot(rows, columns, i+1)
fig.set_title(select_ct, pad = 11, size=20)
plt.imshow(img)
if i==total_images-1:
break
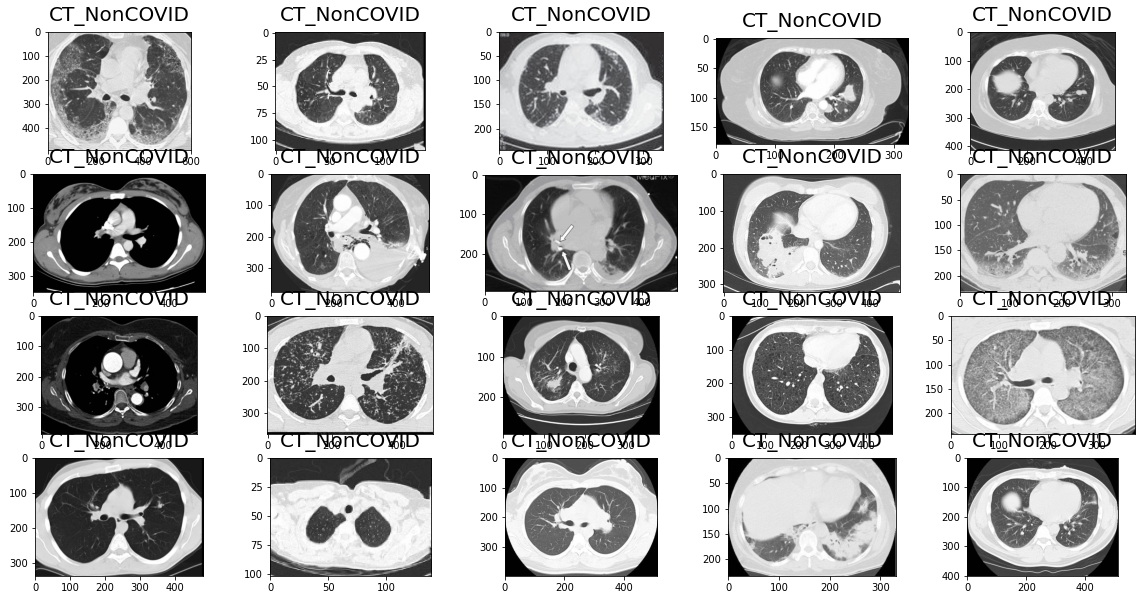
2.4 划分数据集
作者已经将数据集划分成了训练集,测试集和验证集。是通过路径分配来形成不同集的,并没有在物理上划分数据集。而是在读取过程中根据不同文档中的路径,来将数据信息给不同的数据集对象。
- 查看数据集划分结果
import pandas as pd
trainCT_COVID = len(open("./Data-split/COVID/trainCT_COVID.txt",'rU').readlines())
trainCT_NonCOVID = len(open("./Data-split/NonCOVID/trainCT_NonCOVID.txt",'rU').readlines())
traintotal = trainCT_COVID + trainCT_NonCOVID
valCT_COVID = len(open("./Data-split/COVID/valCT_COVID.txt",'rU').readlines())
valCT_NonCOVID = len(open("./Data-split/NonCOVID/valCT_NonCOVID.txt",'rU').readlines())
valtotal = valCT_COVID + valCT_NonCOVID
testCT_COVID = len(open("./Data-split/COVID/testCT_COVID.txt",'rU').readlines())
testCT_NonCOVID = len(open("./Data-split/NonCOVID/testCT_NonCOVID.txt",'rU').readlines())
testtotal = testCT_COVID + testCT_NonCOVID
data = [['train',trainCT_NonCOVID,trainCT_COVID,traintotal],['val',valCT_COVID,valCT_COVID,valtotal ],['test',testCT_COVID,testCT_COVID,testtotal]]
df = pd.DataFrame(data,columns=['Type','NonCOVID-19','COVID-19','total'])
print(df)
| Type | NonCOVID-19 | COVID-19 | total |
|---|---|---|---|
| train | 234 | 191 | 425 |
| val | 60 | 60 | 118 |
| test | 98 | 98 | 203 |
3. 构造训练数据目录
import os
import shutil
import time
datafile = './data/'
if not os.path.exists(datafile):
os.makedirs(datafile)
image1 = './Images-processed/CT_COVID/CT_COVID'
image2 = './Images-processed/CT_NonCOVID'
test_ct = './Data-split/COVID/testCT_COVID.txt'
train_ct = './Data-split/COVID/trainCT_COVID.txt'
val_ct = './Data-split/COVID/valCT_COVID.txt'
n_test_ct = './Data-split/NonCOVID/testCT_NonCOVID.txt'
n_train_ct = './Data-split/NonCOVID/trainCT_NonCOVID.txt'
n_val_ct = './Data-split/NonCOVID/valCT_NonCOVID.txt'
aim = './data'
print('----------------')
shutil.move(image1,aim)
shutil.move(image2,aim)
shutil.move(test_ct,aim)
shutil.move(train_ct,aim)
shutil.move(val_ct,aim)
shutil.move(n_test_ct,aim)
shutil.move(n_train_ct,aim)
shutil.move(n_val_ct,aim)
目录如下
.
├── CT_COVID
├── CT_NonCOVID
├── testCT_COVID.txt
├── testCT_NonCOVID.txt
├── trainCT_COVID.txt
├── trainCT_NonCOVID.txt
├── valCT_COVID.txt
└── valCT_NonCOVID.txt
模型训练
1. 导入相关依赖
import os
import torch
import warnings
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torchxrayvision as xrv
from torchvision import transforms
from torch.utils.data import DataLoader
from sklearn.metrics import roc_auc_score
import torch.nn.functional as F
from visdom import Visdom
import time
2. 定义训练函数
train()函数是训练过程的核心。在这个函数里,完成了一个epoch的数据的训练。过程是从train_loader中去取一个batch_size的图像和标签,前向传播,计算交叉熵loss,反向传播,完成一次迭代。过完全部数据,跳出函数。
device = torch.device("cpu") # 使用cpu训练,或者GPU
# device = torch.device("GPU") # 使用cpu训练,或者GPU
def train(optimizer, epoch, model, train_loader, modelname, criteria):
model.train() # 训练模式
bs = 32
train_loss = 0
train_correct = 0
for batch_index, batch_samples in enumerate(train_loader):
# move data to device
data, target = batch_samples['img'].to(device), batch_samples['label'].to(device)
# data形状,torch.Size([32, 3, 224, 224])
# data = data[:, 0, :, :] # 原作者只取了第一个通道的数据来训练,笔者改成了3个通道
# data = data[:, None, :, :]
# data形状,torch.Size([32, 1, 224, 224])
optimizer.zero_grad()
output = model(data)
loss = criteria(output, target.long())
train_loss += criteria(output, target.long()) # 后面求平均误差用的
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = output.argmax(dim=1, keepdim=True)
train_correct += pred.eq(target.long().view_as(pred)).sum().item() # 累加预测与标签吻合的次数,用于后面算准确率
# 显示一个epoch的进度,425张图片,批大小是32,一个epoch需要14次迭代
if batch_index % 4 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tTrain Loss: {:.6f}'.format(
epoch, batch_index, len(train_loader),
100.0 * batch_index / len(train_loader), loss.item() / bs))
# print(len(train_loader.dataset)) # 425
print('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
train_loss / len(train_loader.dataset), train_correct, len(train_loader.dataset),
100.0 * train_correct / len(train_loader.dataset)))
if os.path.exists('performance') == 0:
os.makedirs('performance')
f = open('performance/{}.txt'.format(modelname), 'a+')
f.write('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
train_loss / len(train_loader.dataset), train_correct, len(train_loader.dataset),
100.0 * train_correct / len(train_loader.dataset)))
f.write('\n')
f.close()
return train_loss / len(train_loader.dataset) # 返回一个epoch的平均误差,用于可视化损失
3.定义验证函数
val()函数是验证过程的核心。函数将验证集所有数据送入模型,并返回与模型评价有关的数据,如预测结果,和平均损失。
def val(model, val_loader, criteria):
'''
model:训练好的模型
val_loader: 验证集
criteria:
'''
model.eval()
val_loss = 0
# Don't update model
with torch.no_grad():
predlist = []
scorelist = []
targetlist = []
# Predict
for batch_index, batch_samples in enumerate(val_loader):
data, target = batch_samples['img'].to(device), batch_samples['label'].to(device)
# data = data[:, 0, :, :] # 原作者只取了第一个通道的数据,笔者改成了3个通道
# data = data[:, None, :, :]
# data形状,torch.Size([32, 1, 224, 224])
output = model(data)
val_loss += criteria(output, target.long())
score = F.softmax(output, dim=1)
pred = output.argmax(dim=1, keepdim=True)
targetcpu = target.long().cpu().numpy()
predlist = np.append(predlist, pred.cpu().numpy())
scorelist = np.append(scorelist, score.cpu().numpy()[:, 1])
targetlist = np.append(targetlist, targetcpu)
return targetlist, scorelist, predlist, val_loss / len(val_loader.dataset)
4. 数据读取
根据图像路径列表来读数据,COVID-CT作者给的列表文件只有图片名,没有相对路径。所以read_txt(txt_path)解析出来的是图片名列表,需要join一些目录才能使用。Image.open(img_path).convert(‘RGB’),根据相对路径读入图像。
class CovidCTDataset(Dataset):
def __init__(self, root_dir, txt_COVID, txt_NonCOVID, transform=None):
self.root_dir = root_dir
self.txt_path = [txt_COVID, txt_NonCOVID]
self.classes = ['CT_COVID', 'CT_NonCOVID']
self.num_cls = len(self.classes)
self.img_list = []
for c in range(self.num_cls):
cls_list = [[os.path.join(self.root_dir, self.classes[c], item), c] for item in read_txt(self.txt_path[c])]
self.img_list += cls_list
self.transform = transform
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_path = self.img_list[idx][0]
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
sample = {'img': image,
'label': int(self.img_list[idx][1])}
return sample
def read_txt(txt_path):
with open(txt_path) as f:
lines = f.readlines()
txt_data = [line.strip() for line in lines] # 主要是跳过'\n'
return txt_data
5. 数据预处理
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 依通道标准化
train_transformer = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop((224), scale=(0.5, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
val_transformer = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
6. 定义训练过程
if __name__ == '__main__':
batchsize = 32
total_epoch = 1500
votenum = 10
# ------------------------------- step 1/5 数据读取 ----------------------------
# 实例化CovidCTDataset
trainset = CovidCTDataset(root_dir='data',
txt_COVID='data/trainCT_COVID.txt',
txt_NonCOVID='data/trainCT_NonCOVID.txt',
transform=train_transformer)
valset = CovidCTDataset(root_dir='data',
txt_COVID='data/valCT_COVID.txt',
txt_NonCOVID='data/valCT_NonCOVID.txt',
transform=val_transformer)
print(trainset.__len__())
print(valset.__len__())
# 构建DataLoader
train_loader = DataLoader(trainset, batch_size=batchsize, drop_last=False, shuffle=True)
val_loader = DataLoader(valset, batch_size=batchsize, drop_last=False, shuffle=False)
# ------------------------------ step 2/5 模型 --------------------------------
model = xrv.models.DenseNet(num_classes=2, in_channels=3).cpu() #
# model = xrv.models.DenseNet(num_classes=2, in_channels=3).cuda()
DenseNet 模型,二分类
modelname = 'DenseNet_medical'
torch.cuda.empty_cache()
# ----------------------------- step 3/5 损失函数 ----------------------------
criteria = nn.CrossEntropyLoss() # 二分类用交叉熵损失
# ----------------------------- step 4/5 优化器 -----------------------------
optimizer = optim.Adam(model.parameters(), lr=0.0001) # Adam优化器
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10) # 动态调整学习率策略,初始学习率0.0001
# ---------------------------- step 5/5 训练 ------------------------------
# visiom可视化训练过程
viz = Visdom(server='http://localhost/', port=8097)
viz.line([[0., 0., 0., 0., 0.]], [0], win='train_performance', update='replace', opts=dict(title='train_performance', legend=['precision', 'recall', 'AUC', 'F1', 'acc']))
viz.line([[0., 0.]], [0], win='train_Loss', update='replace', opts=dict(title='train_Loss', legend=['train_loss', 'val_loss']))
warnings.filterwarnings('ignore')
# 模型评价
TP = 0
TN = 0
FN = 0
FP = 0
r_list = []
p_list = []
acc_list = []
AUC_list = []
vote_pred = np.zeros(valset.__len__())
vote_score = np.zeros(valset.__len__())
for epoch in range(1, total_epoch + 1):
train_loss = train(optimizer, epoch, model, train_loader, modelname, criteria) # 进行一个epoch训练的函数
targetlist, scorelist, predlist, val_loss = val(model, val_loader, criteria) # 用验证集验证
print('target', targetlist)
print('score', scorelist)
print('predict', predlist)
vote_pred = vote_pred + predlist
vote_score = vote_score + scorelist
if epoch % votenum == 0: # 每10个epoch,计算一次准确率和召回率等
# major vote
vote_pred[vote_pred <= (votenum / 2)] = 0
vote_pred[vote_pred > (votenum / 2)] = 1
vote_score = vote_score / votenum
print('vote_pred', vote_pred)
print('targetlist', targetlist)
TP = ((vote_pred == 1) & (targetlist == 1)).sum()
TN = ((vote_pred == 0) & (targetlist == 0)).sum()
FN = ((vote_pred == 0) & (targetlist == 1)).sum()
FP = ((vote_pred == 1) & (targetlist == 0)).sum()
print('TP=', TP, 'TN=', TN, 'FN=', FN, 'FP=', FP)
print('TP+FP', TP + FP)
p = TP / (TP + FP)
print('precision', p)
p = TP / (TP + FP)
r = TP / (TP + FN)
print('recall', r)
F1 = 2 * r * p / (r + p)
acc = (TP + TN) / (TP + TN + FP + FN)
print('F1', F1)
print('acc', acc)
AUC = roc_auc_score(targetlist, vote_score)
print('AUCp', roc_auc_score(targetlist, vote_pred))
print('AUC', AUC)
# 训练过程可视化
train_loss = train_loss.cpu().detach().numpy()
val_loss = val_loss.cpu().detach().numpy()
viz.line([[p, r, AUC, F1, acc]], [epoch], win='train_performance', update='append',
opts=dict(title='train_performance', legend=['precision', 'recall', 'AUC', 'F1', 'acc']))
viz.line([[train_loss], [val_loss]], [epoch], win='train_Loss', update='append',
opts=dict(title='train_Loss', legend=['train_loss', 'val_loss']))
print(
'\n The epoch is {}, average recall: {:.4f}, average precision: {:.4f},average F1: {:.4f}, '
'average accuracy: {:.4f}, average AUC: {:.4f}'.format(
epoch, r, p, F1, acc, AUC))
# 更新模型
if os.path.exists('backup') == 0:
os.makedirs('backup')
torch.save(model.state_dict(), "backup/{}.pt".format(modelname))
vote_pred = np.zeros(valset.__len__())
vote_score = np.zeros(valset.__len__())
f = open('performance/{}.txt'.format(modelname), 'a+')
f.write(
'\n The epoch is {}, average recall: {:.4f}, average precision: {:.4f},average F1: {:.4f}, '
'average accuracy: {:.4f}, average AUC: {:.4f}'.format(
epoch, r, p, F1, acc, AUC))
f.close()
if epoch % (votenum*10) == 0: # 每100个epoch,保存一次模型
torch.save(model.state_dict(), "backup/{}_epoch{}.pt".format(modelname, epoch))
7. 可视化查看训练过程
在终端输入
python -m visdom.server
访问:
http://localhost:8097
8.模型保存
每100个轮保存一次代码,最后挑选表现较好的
模型评估
1. 定义测试函数
def test(model, test_loader):
model.eval()
# Don't update model
with torch.no_grad():
predlist = []
scorelist = []
targetlist = []
# Predict
for batch_index, batch_samples in enumerate(test_loader):
data, target = batch_samples['img'].to(device), batch_samples['label'].to(device)
# data = data[:, 0, :, :] # 只取了第一个通道的数据来训练,笔者改成了灰度图像
# data = 0.299 * data[:, 0, :, :] + 0.587 * data[:, 1, :, :] + 0.114 * data[:, 2, :, :]
# data形状,torch.Size([32, 224, 224])
# data = data[:, None, :, :]
# data形状,torch.Size([32, 1, 224, 224])
# print(target)
output = model(data)
score = F.softmax(output, dim=1)
pred = output.argmax(dim=1, keepdim=True)
targetcpu = target.long().cpu().numpy()
predlist = np.append(predlist, pred.cpu().numpy())
scorelist = np.append(scorelist, score.cpu().numpy()[:, 1])
targetlist = np.append(targetlist, targetcpu)
return targetlist, scorelist, predlist
2. 定义测试过程
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 依通道标准化
test_transformer = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
if __name__ == '__main__':
batchsize = 32 # 原来用的10,这里改成32,根据个人GPU容量来定。
# ------------------------------- step 1/3 数据 ----------------------------
# 实例化CovidCTDataset
testset = CovidCTDataset(root_dir='data',
txt_COVID='data/testCT_COVID.txt',
txt_NonCOVID='data/testCT_NonCOVID.txt',
transform=test_transformer)
print(testset.__len__())
# 构建DataLoader
test_loader = DataLoader(testset, batch_size=batchsize, drop_last=False, shuffle=False)
# ------------------------------ step 2/3 模型 --------------------------------
model = xrv.models.DenseNet(num_classes=2, in_channels=3).cpu() #
# model = xrv.models.DenseNet(num_classes=2, in_channels=3).cuda()
DenseNet 模型,二分类
modelname = 'DenseNet_medical'
torch.cuda.empty_cache()
# ---------------------------- step 3/3 测试 ------------------------------
f = open(f'performance/test_model.csv', mode='w')
csv_writer = csv.writer(f)
flag = 1
for modelname in os.listdir('backup'):
model.load_state_dict(torch.load('backup/{}'.format(modelname)))
torch.cuda.empty_cache()
bs = 10
warnings.filterwarnings('ignore')
r_list = []
p_list = []
acc_list = []
AUC_list = []
TP = 0
TN = 0
FN = 0
FP = 0
vote_score = np.zeros(testset.__len__())
targetlist, scorelist, predlist = test(model, test_loader)
vote_score = vote_score + scorelist
TP = ((predlist == 1) & (targetlist == 1)).sum()
TN = ((predlist == 0) & (targetlist == 0)).sum()
FN = ((predlist == 0) & (targetlist == 1)).sum()
FP = ((predlist == 1) & (targetlist == 0)).sum()
p = TP / (TP + FP)
p = TP / (TP + FP)
r = TP / (TP + FN)
F1 = 2 * r * p / (r + p)
acc = (TP + TN) / (TP + TN + FP + FN)
AUC = roc_auc_score(targetlist, vote_score)
print(
'\n{}, recall: {:.4f}, precision: {:.4f},F1: {:.4f}, accuracy: {:.4f}, AUC: {:.4f}'.format(
modelname, r, p, F1, acc, AUC))
if flag:
header = ['modelname', 'recall', 'precision', 'F1', 'accuracy', 'AUC']
csv_writer.writerow(header)
flag = 0
row = [modelname, str(r), str(p), str(F1), str(acc), str(AUC)]
csv_writer.writerow(row)
f.close()
- precision:p = TP / (TP + FP),所有预测为1的结果中,正确的比例。精确率越高,负例被误判成正例的可能性越小,即查的准,代价就是可能会有越多的正例被误判成负例。
- recall:r = TP / (TP + FN),所有标签为1的样本中,预测正确的比例。召回率越高,就会有越少的正例被误判定成负例,即查的全,代价就是可能会有越多的负例被误判成正例。对于上述案例,肯定是recall越大越好,新冠肺炎阳性被判成阴性的代价是非常大的,而阴性判成阳性的代价相对较小,最多就是让医生多看几张片子。
- F1:F1 = 2 * r * p / (r + p)是P和R的调和平均数,综合考虑准与全。
- accuracy:acc = (TP + TN) / (TP + TN + FP + FN),预测正确的比例。
- AUC:ROC曲线下与坐标轴围成的面积,常用于评价二分类模型的好坏。
结果:
| modelname | recall | precision | F1 | accuracy | AUC |
|---|---|---|---|---|---|
| DenseNet_medical_epoch200.pt | 0.9143 | 0.6316 | 0.7471 | 0.6798 | 0.7342 |
| DenseNet_medical_epoch300.pt | 0.5429 | 0.7125 | 0.6162 | 0.6502 | 0.7532 |
| DenseNet_medical_epoch1000.pt | 0.7048 | 0.7255 | 0.7150 | 0.7094 | 0.7941 |
| DenseNet_medical_epoch500.pt | 0.8381 | 0.7213 | 0.7753 | 0.7488 | 0.7966 |
| DenseNet_medical.pt | 0.6857 | 0.7347 | 0.7094 | 0.7094 | 0.7975 |
| DenseNet_medical_epoch700.pt | 0.7619 | 0.6897 | 0.7240 | 0.6995 | 0.7763 |
| DenseNet_medical_epoch1200.pt | 0.8667 | 0.6947 | 0.7712 | 0.7340 | 0.8026 |
| DenseNet_medical_epoch1500.pt | 0.6857 | 0.7347 | 0.7094 | 0.7094 | 0.7975 |
| DenseNet_medical_epoch900.pt | 0.7810 | 0.6949 | 0.7354 | 0.7094 | 0.7977 |
| DenseNet_medical_epoch1400.pt | 0.6571 | 0.7841 | 0.7150 | 0.7291 | 0.8110 |
| DenseNet_medical_epoch1100.pt | 0.5714 | 0.8000 | 0.6667 | 0.7044 | 0.8099 |
| DenseNet_medical_epoch800.pt | 0.7143 | 0.7353 | 0.7246 | 0.7192 | 0.8185 |
| DenseNet_medical_epoch600.pt | 0.7429 | 0.7358 | 0.7393 | 0.7291 | 0.7960 |
| DenseNet_medical_epoch1300.pt | 0.7905 | 0.7477 | 0.7685 | 0.7537 | 0.8215 |
| DenseNet_medical_epoch100.pt | 0.9143 | 0.6234 | 0.7413 | 0.6700 | 0.7798 |
| DenseNet_medical_epoch400.pt | 0.8286 | 0.7500 | 0.7873 | 0.7685 | 0.7749 |
总结
主要是参照了原作者的实现方式,做了一些调整修改,是学习了解二分类问题的不错方式。
如有不对,欢迎大家指正!!!!
如有侵权联系删!
联系邮箱:[email protected]
边栏推荐
猜你喜欢
Rust 从入门到精通04-变量

请 AI 画家弄了个 logo,网友热议:画得非常好,下次别画了!
Leetcode - using sequence traversal features first completed 114. The binary tree to the list

Go编译原理系列8(变量捕获)

知道创宇EDR系统实力通过中国信通院端点检测与响应产品能力评测

Leetcode刷题——543. 二叉树的直径、617. 合并二叉树(递归解决)
HyperLynx仿真(一)LineSim简单介绍
【飞控开发高级教程7】疯壳·开源编队无人机-编队飞行
能力更强,医疗单据识别+医疗知识库校验
The use of DDR3 (Naive) in Xilinx VIVADO (3) simulation test
随机推荐
微信公众号之底部菜单
Leetcode刷题——构造二叉树(105. 从前序与中序遍历序列构造二叉树、106. 从中序与后序遍历序列构造二叉树)
手搓一个“七夕限定”,用3D Engine 5分钟实现烟花绽放效果
【RISC-V】Trap和Exception
手搓一个“七夕限定”,用3D Engine 5分钟实现烟花绽放效果
中介者模式(Mediator)
Rust 从入门到精通04-变量
深度学习------戴口罩和不戴口罩
MTBF是什么意思?交换机做MTBF有什么要求?MTTF、MTBF和MTTR的区别是什么?
*iframe*
字节技术官亲码算法面试进阶神技太香了
POJ2367Genealogical tree题解
200PLC转以太网与研华webaccess modbusTCP客户端在空调机上应用配置案例
Go编译原理系列8(变量捕获)
【LeetCode】98.验证二叉搜索树
[Flight Control Development Advanced Course 7] Crazy Shell Open Source Formation UAV - Formation Flight
到底什么是JS原型
力扣解法汇总1403-非递增顺序的最小子序列
Leetcode刷题——二叉搜索树相关题目(98. 验证二叉搜索树、235. 二叉搜索树的最近公共祖先、1038. 从二叉搜索树到更大和树、538. 把二叉搜索树转换为累加树)
中电金信技术实践|分布式事务简说