当前位置:网站首页>【数据分析】基于MATLAB实现SVDD决策边界可视化
【数据分析】基于MATLAB实现SVDD决策边界可视化
2022-08-03 02:08:00 【matlab_dingdang】
1 内容介绍
在现实世界中,万事万物都有着其特征,这样的特征或多或少、或重要或不重要。人们通过事物的特征可以确定其所属分类,但是当事物的特征都很多时,如果人们依靠传统的方法对事物进行分类就显得耗时耗力,并且分类的精确性不高。而分类作为一种预测模型,如果分类的精确性低或用时长,则这种预测将变得毫无价值。因此人们提出了各种分类模型来对事物进行预测,其中支持向量机和支持向量描述数据在对高维数据进行预测时有着一定的优势,并且根据不同的要求,对这两种算法的改进应用到了现实生活中的许多领域。 首先,本文研究了数据挖掘分类算法中的支持向量机的背景和理论,分析并总结了SVM各种改进方法的研究现状。
2 仿真代码
function x_range = grid_range(x, varargin)
%{
% DESCRIPTION
Compute the range of grid
x_range = grid_range(x)
x_range = grid_range(x, 'r', 0.5)
x_range = grid_range(x, 'n', 200)
x_range = grid_range(x, 'r', 0.5, 'n', 200)
INPUT
x Training inputs (N*1)
N: number of samples
r Radio of expansion (0<r<1)
n Number of grids
OUTPUT
x_range range of grid
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
% Default Parameters setting
r = 0.5; % radio of expansion (0<r<1)
n = 2*size(x, 1); % number of grids
% Parameters setting
if ~rem(nargin, 2)
error('Parameters to rvm_train should be pairs')
end
numParameters = (nargin-1)/2;
if numParameters ~= 0
for i =1:numParameters
Parameters = varargin{(i-1)*2+1};
value = varargin{(i-1)*2+2};
switch Parameters
%
case 'r'
r = value;
%
case 'n'
n = value;
end
end
end
%
xlim_1 = min(x);
xlim_2 = max(x);
% min
if xlim_1<0
xlim_1 = xlim_1*(1+r);
else
xlim_1 = xlim_1*(1-r);
end
% max
if xlim_2<0
xlim_2 = xlim_2*(1-r);
else
xlim_2 = xlim_2*(1+r);
end
% range of grid
x_range = linspace(xlim_1, xlim_2, n);
end
function [traindata, testdata, trainlabel, testlabel] = prepareData
%{
% DESCRIPTION
Prepare the data for SVDD_WOA
[traindata, testdata, trainlabel, testlabel] = prepareData
OUTPUT
traindata Training data
testdata Testing data
trainlabel Training label
trainlabel Training label
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
load .\data\banana.mat
traindata(:, 1) = banana(1:2:500, 1);
traindata(:, 2) = banana(1:2:500, 2);
testdata(:, 1) = banana(501:2:1000, 1);
testdata(:, 2) = banana(501:2:1000, 2);
trainlabel = ones(size(traindata, 1), 1);
testlabel = -ones(size(testdata, 1), 1);
end
function [rho, X1, X2] = decision_boundary(model, traindata)
%{
% DESCRIPTION
Computation of decision boundary
[rho, X1, X2] = decision_boundary(model, traindata)
INPUT
model SVDD model
N: number of samples
traindata Training data
OUTPUT
rho Bias term
X1, X2 Grid range
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
% Compute the range of grid
x1_range = grid_range(traindata(:, 1));
x2_range = grid_range(traindata(:, 2));
% grid
[X1, X2] = meshgrid(x1_range, x2_range);
X_Grid = [X1(:), X2(:)];
% the grid label is only for the input of the function 'libsvmpredict'
grid_label = ones(size(X_Grid, 1), 1);
% Predict the label of each grid point
[~, ~, rho_0] = libsvmpredict(grid_label, X_Grid, model);
rho = reshape(rho_0, size(X1, 1), size(X1, 2));
end
function [traindata, testdata, trainlabel, testlabel] = prepareData
%{
% DESCRIPTION
Prepare the data for SVDD_WOA
[traindata, testdata, trainlabel, testlabel] = prepareData
OUTPUT
traindata Training data
testdata Testing data
trainlabel Training label
trainlabel Training label
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
load .\data\banana.mat
traindata(:, 1) = banana(1:2:500, 1);
traindata(:, 2) = banana(1:2:500, 2);
testdata(:, 1) = banana(501:2:1000, 1);
testdata(:, 2) = banana(501:2:1000, 2);
trainlabel = ones(size(traindata, 1), 1);
testlabel = -ones(size(testdata, 1), 1);
end
1 内容介绍
在现实世界中,万事万物都有着其特征,这样的特征或多或少、或重要或不重要。人们通过事物的特征可以确定其所属分类,但是当事物的特征都很多时,如果人们依靠传统的方法对事物进行分类就显得耗时耗力,并且分类的精确性不高。而分类作为一种预测模型,如果分类的精确性低或用时长,则这种预测将变得毫无价值。因此人们提出了各种分类模型来对事物进行预测,其中支持向量机和支持向量描述数据在对高维数据进行预测时有着一定的优势,并且根据不同的要求,对这两种算法的改进应用到了现实生活中的许多领域。 首先,本文研究了数据挖掘分类算法中的支持向量机的背景和理论,分析并总结了SVM各种改进方法的研究现状。
2 仿真代码
function x_range = grid_range(x, varargin)
%{
% DESCRIPTION
Compute the range of grid
x_range = grid_range(x)
x_range = grid_range(x, 'r', 0.5)
x_range = grid_range(x, 'n', 200)
x_range = grid_range(x, 'r', 0.5, 'n', 200)
INPUT
x Training inputs (N*1)
N: number of samples
r Radio of expansion (0<r<1)
n Number of grids
OUTPUT
x_range range of grid
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
% Default Parameters setting
r = 0.5; % radio of expansion (0<r<1)
n = 2*size(x, 1); % number of grids
% Parameters setting
if ~rem(nargin, 2)
error('Parameters to rvm_train should be pairs')
end
numParameters = (nargin-1)/2;
if numParameters ~= 0
for i =1:numParameters
Parameters = varargin{(i-1)*2+1};
value = varargin{(i-1)*2+2};
switch Parameters
%
case 'r'
r = value;
%
case 'n'
n = value;
end
end
end
%
xlim_1 = min(x);
xlim_2 = max(x);
% min
if xlim_1<0
xlim_1 = xlim_1*(1+r);
else
xlim_1 = xlim_1*(1-r);
end
% max
if xlim_2<0
xlim_2 = xlim_2*(1-r);
else
xlim_2 = xlim_2*(1+r);
end
% range of grid
x_range = linspace(xlim_1, xlim_2, n);
end
function [traindata, testdata, trainlabel, testlabel] = prepareData
%{
% DESCRIPTION
Prepare the data for SVDD_WOA
[traindata, testdata, trainlabel, testlabel] = prepareData
OUTPUT
traindata Training data
testdata Testing data
trainlabel Training label
trainlabel Training label
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
load .\data\banana.mat
traindata(:, 1) = banana(1:2:500, 1);
traindata(:, 2) = banana(1:2:500, 2);
testdata(:, 1) = banana(501:2:1000, 1);
testdata(:, 2) = banana(501:2:1000, 2);
trainlabel = ones(size(traindata, 1), 1);
testlabel = -ones(size(testdata, 1), 1);
end
function [rho, X1, X2] = decision_boundary(model, traindata)
%{
% DESCRIPTION
Computation of decision boundary
[rho, X1, X2] = decision_boundary(model, traindata)
INPUT
model SVDD model
N: number of samples
traindata Training data
OUTPUT
rho Bias term
X1, X2 Grid range
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
% Compute the range of grid
x1_range = grid_range(traindata(:, 1));
x2_range = grid_range(traindata(:, 2));
% grid
[X1, X2] = meshgrid(x1_range, x2_range);
X_Grid = [X1(:), X2(:)];
% the grid label is only for the input of the function 'libsvmpredict'
grid_label = ones(size(X_Grid, 1), 1);
% Predict the label of each grid point
[~, ~, rho_0] = libsvmpredict(grid_label, X_Grid, model);
rho = reshape(rho_0, size(X1, 1), size(X1, 2));
end
function [traindata, testdata, trainlabel, testlabel] = prepareData
%{
% DESCRIPTION
Prepare the data for SVDD_WOA
[traindata, testdata, trainlabel, testlabel] = prepareData
OUTPUT
traindata Training data
testdata Testing data
trainlabel Training label
trainlabel Training label
Created on 18th October 2019, by Kepeng Qiu.
-------------------------------------------------------------%
%}
load .\data\banana.mat
traindata(:, 1) = banana(1:2:500, 1);
traindata(:, 2) = banana(1:2:500, 2);
testdata(:, 1) = banana(501:2:1000, 1);
testdata(:, 2) = banana(501:2:1000, 2);
trainlabel = ones(size(traindata, 1), 1);
testlabel = -ones(size(testdata, 1), 1);
end
3 运行结果

4 参考文献
[1]李传亮. 基于SVDD和参数辨识的模拟电路故障诊断方法研究[D]. 南京航空航天大学.
[2]肖托. 一种改进的支持向量数据描述算法[D]. 哈尔滨工程大学, 2013.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。
3 运行结果
4 参考文献
[1]李传亮. 基于SVDD和参数辨识的模拟电路故障诊断方法研究[D]. 南京航空航天大学.
[2]肖托. 一种改进的支持向量数据描述算法[D]. 哈尔滨工程大学, 2013.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。
边栏推荐
- leetcode:172. 阶乘后的零
- 思维+启发式合并
- 【云原生】阿里云ARMS业务实时监控
- MySQL-多表查询
- .NET in-depth analysis of the LINQ framework (four: IQueryable, IQueryProvider interface details)
- ES6 新特性:Class 的基本语法
- [Static type and dynamic type compile check and run check in Objective-C]
- numpy PIL tensor之间的相互转换
- MySQL-Explain详解
- 【云原生】灰度发布、蓝绿发布、滚动发布、灰度发布解释
猜你喜欢

qt opengl 使用不同的颜色绘制线框三角形
JVM internal structure and various modules operation mechanism
新库上线 | CnOpenDataA股上市公司董监高信息数据
国标GB28181协议EasyGBS平台项目现场通知消息过多导致系统卡顿该如何解决?
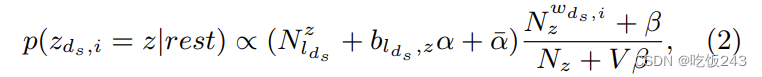
Topic Modeling of Short Texts: A Pseudo-Document View

The LVS load balancing cluster and the deployment of the LVS - NAT experiment
initramfs详解----设备文件系统
Summary of some interviews
lombok 下的@Builder和@EqualsAndHashCode(callSuper = true)注解
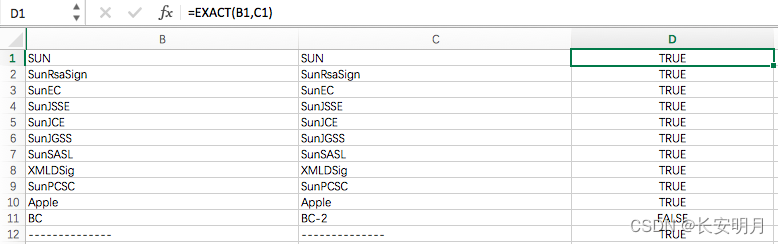
Excel 如何比较两列字符串是否相同?
随机推荐
monkey 压测
实现统一账号登录,sonarqube集成ldap
开发JSP应用的基础知识
Linux定时任务脚本执行时mysqldump备份异常的问题
MySQL-多表查询
能添加任意贴图超级复布局的初级智能文本提示器(超级版)
Topic Modeling of Short Texts: A Pseudo-Document View
The LVS load balancing cluster and the deployment of the LVS - NAT experiment
【云原生】灰度发布、蓝绿发布、滚动发布、灰度发布解释
怎么从零编写一个 v3 版本的 chrome 浏览器插件实现 CSDN 博客网站的暗黑和明亮主题切换?
一篇文章玩明白Stack-migration
pytorch 中 permute()函数的用法
ClickHouse数据类型
Kubernetes:(八)调度约束和故障排查
征集 |《新程序员》专访“Apache之父”Brian Behlendorf,你最想问什么?
常见钓鱼手法及防范
网易数帆陈谔:云原生“牵手”低代码,加速企业数字化转型
Excel 如何比较两列字符串是否相同?
容联云发送验证码
选中按钮上色