当前位置:网站首页>Spark broadcast variables and accumulators (cases attached)
Spark broadcast variables and accumulators (cases attached)
2022-06-23 02:14:00 【JKing_ one hundred and sixty-eight】
Broadcast variables :
If broadcast variable technology is used , be Driver The client will only send the shared data to each Executor One copy .Executor All in Task Reuse this object .
If you don't use broadcast variable technology , be Driver The client will distribute the shared data to each by default Task in , Causing great pressure on network distribution . Even cause you to carry on RDD When persistent to memory , Forced to save to disk due to insufficient memory , Added disk IO, Severely degrade performance .
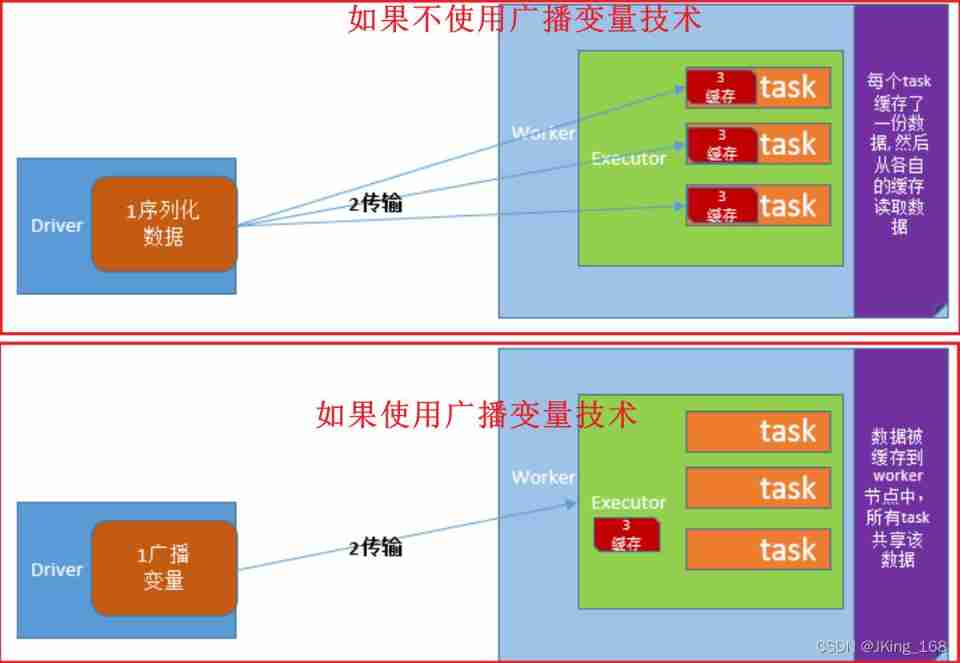
Broadcast variable usage (Python Realization ):
To ensure that the shared object is serializable . Because the data transmitted across nodes should be serializable .
stay Driver The client broadcasts the shared objects to each Executor:
#2- Define a list , Load special characters list_v=[",", ".", "!", "#", "$", "%"] #3- List from Driver End broadcast to each Executor in bc=sc.broadcast(list_v)- stay Executor In order to get :
list2=bc.value
accumulator :
Spark Provided Accumulator, It is mainly used for multiple nodes to share a variable .Accumulator Only the function of accumulation is provided , That is, multiple task The function of parallel operation on a variable . however task Only right Accumulator Carry out accumulation operation , Cannot read Accumulator Value , Only Driver The program can read Accumulator Value . Created Accumulator The value of the variable can be Spark Web UI See above , So you should try to name it when you create it .
Spark Built in three types of Accumulator, Namely LongAccumulator Cumulative integer type ,DoubleAccumulator Cumulative floating point ,CollectionAccumulator Accumulate set elements .
How to use the integer accumulator (Python Realization ) :
- stay Driver End define integer accumulator , Initial value of Fu .
acc=sc.accumulator(0) - stay Task Add up each time in 1
acc.add(1) # perhaps acc+=1
PySpark Integrated case of accumulator and broadcast variables :
- Case study : Filter non word characters , And count the non word characters

- Python Code implementation :
from pyspark import SparkConf, SparkContext, StorageLevel import os,jieba,time,re # Specify environment variables os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python' if __name__ == '__main__': conf = SparkConf().setAppName('text1').setMaster('local[*]') sc = SparkContext(conf=conf) # 2- Define a list , Load special characters list_v = [",", ".", "!", "#", "$", "%"] # 3- List from Driver End broadcast to each Executor in bc = sc.broadcast(list_v) # 4- Define accumulator , Follow up in distributed task in , Every time a special character is encountered , Just add up 1 acc = sc.accumulator(0) # 5- Load text content , formation RDD input_rdd=sc.textFile('file:///export/pyworkspace/sz27_spark/pyspark_core/data/accumulator_broadcast_data.txt') # 6- Filter blank line filtered_rdd = input_rdd.filter(lambda line:len(line.strip())>0) # 7- Write each sentence , Split into short strings by white space characters str_rdd = filtered_rdd.flatMap(lambda line:re.split('\\s+',line)) # 8- Right up there RDD, Filter , Every time a special character is encountered , accumulator acc Just add up 1, And eliminate special characters , Formed RDD Contains only words def filter_str(str): global acc # Get a list of special characters list2 = bc.value if str in list2: acc.add(1) return False else: return True word_rdd = str_rdd.filter(filter_str) # 9- Count the words , wordcount_rdd = word_rdd.map(lambda word:(word,1)).reduceByKey(lambda x,y:x+y) # 10- Print word count results print(' Word count results :',wordcount_rdd.collect()) # 11- Print the value of the accumulator , That is, the number of special characters print(' Special character accumulator results :',acc.value) sc.stop()
边栏推荐
- Game (sanziqi & minesweeping)
- "Initial C language" (Part 2)
- My good brother gave me a difficult problem: retry mechanism
- 9. class and object practice and initialization list
- Interviewer: what is the difference between SSH and SSM frameworks? How to choose??
- For Xiaobai who just learned to crawl, you can understand it after reading it
- Array part
- Common mistakes in C language (sizeof and strlen)
- Bc110 tic tac toe chess
- On function overloading from several examples
猜你喜欢
pd. read_ CSV and np Differences between loadtext

How to make word notes beautiful

Cmake configuration error, error configuration process, Preject files may be invalid

Mobile communication Overview - Architecture

Log a log4j2 vulnerability handling

Custom shapes for ugui skill learning

Detailed explanation of makefile usage

Interviewer: what is the difference between SSH and SSM frameworks? How to choose??

Quick sorting C language code + auxiliary diagram + Notes

An interesting example of relaxed memory models
随机推荐
Triangle judgment (right angle, equilateral, general)
Three ways to get class
Get the structure of the class through reflection, little chestnut
Problem thinking and analysis process
Quick sorting C language code + auxiliary diagram + Notes
Muduo simple usage
Operate attribute chestnut through reflection
Cmake configuration error, error configuration process, Preject files may be invalid
Docker installs mysql5.7 and mounts the configuration file
PHP Base64 image processing Encyclopedia
JS case: support canvas electronic signature function on PC and mobile
Mongodb aggregate query implements multi table associated query, type conversion, and returns specified parameters.
Bubble sort - double for implementation
You must know the type and method of urllib
Targeted and ready to go
Solution to the problem of easycvr switching MySQL database traffic statistics cannot be displayed
Analysis of web page status code
Bc117 xiaolele walks up the steps
Pywebio to quickly build web applications
Uint8 serializing and deserializing pits using stringstream