当前位置:网站首页>Deep learning - CV, CNN, RNN
Deep learning - CV, CNN, RNN
2022-07-26 06:31:00 【laluneX】
One 、 Computer vision
1. edge detection (edge detection)
stay majority When The edge of the image Sure Carry most of the information , also Edge extraction Sure remove quite a lot Interference information , Improve the efficiency of data processing . It contains Vertical edge detection (Vertical edge detection) and Horizontal edge detection (Vertical edge detection) wait
Vertical edge detection Yes, it will Input picture Through a kind of Convolution kernel Conduct operation Then I got a New pictures , In the picture Vertical edge display . Horizontal edge detection Through another Convolution kernel operation , Last The output picture shows the horizontal edge
Positive and negative sides , The actual difference is From light to dark And From dark to light The difference between
2. padding
His function yes :
- In order to solve After many convolutions after The image becomes very small The situation of
- In order to Save the edge information of the original picture
padding In three ways :full,same,valid
①full
full The pattern means , from filter and image Rigid intersection Start doing , The white part is filled with 0.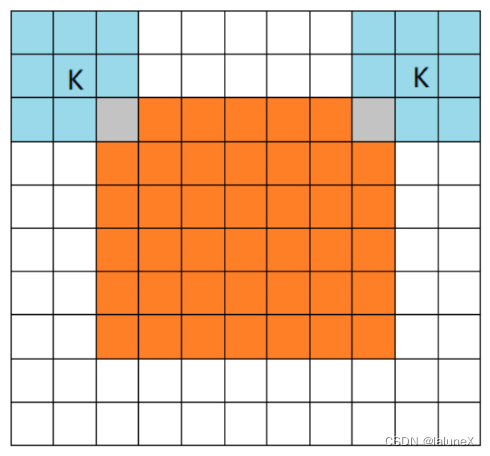
②same
there same After convolution Output feature map The size remains the same ( Relative to the input picture ), here filter Moving range ratio of full Smaller .
③valid
valid Refer to Don't do the original picture padding, Direct convolution , so filter The moving range of the is same Smaller .
3. Convolution step (Strided convolution)
Convolution step Refer to The distance of each filter move
4. CNN Layer type
Convolutional neural networks CNN Structure It generally includes these layers :
Input layer : be used for Data input
Convolution layer : Use Convolution kernel Conduct Feature extraction and feature mapping
Pooling layer : Take the next sample , Sparse processing of feature graph , Reduce the amount of data computation . It includes Max pooling and Average polling.Max pooling: take “ Pool vision ” In the matrix Maximum ;Average pooling: take “ Pool vision ” In the matrix Average
Fully connected layer : Usually in CNN Tail of Refit , Reduce the loss of feature information
Output layer : be used for Output results 
Of course, some other functional layers can be used in the middle :
Normalized layer (Batch Normalization): stay CNN Chinese vs Normalization of features
Cut the layers : For some ( picture ) Data processing Separate learning in different regions
Fusion layer : Yes The branch of independent feature learning Conduct The fusion
Two 、 Cyclic neural network -RNN(Recurrent Neural Networks)
1. Why RNN( Cyclic neural network )
General neural networks all Only one input can be processed separately , Previous input and The last input yes It doesn't matter at all . however , Some tasks Need to be able to Better processing of sequence information , namely The previous input is related to the following input .
2. RNN structure

This network is in t moment Received Input x t x_t xt after , Hidden layer The value of is s t s_t st, Output value yes o t o_t ot. The key point is , s t s_t st It's not just about x t x_t xt, It also depends on s t − 1 s_{t-1} st−1
3. RNN The type of structure
one-on-one 、 One to many 、 For one more 、 Many to many ( The output is equal to or unequal to the output )、 Attention structure 
4. The problem of gradient explosion
Gradient explosion is easier to deal with , Because when the gradient explodes , our The program will be received NaN error . We can Set up One Gradient threshold , When the gradient exceeds this threshold, you can To intercept directly .
5. The problem of gradient disappearance
- Reasonable initialization weight value , To avoid the area where the gradient disappears
- Use relu Instead of sigmoid and tanh As an activation function
- Use Long and short term memory network (LSTM) and Gated Recurrent Unit(GRU), This is the most popular way
① Long and short term memory network (Long Short Term Memory Network——LSTM)
LSTM use Two doors To control Unit status c The content of , One is Oblivion gate (forget gate), It determines Unit status at the last time c t − 1 c_{t-1} ct−1 How much remains to the present moment c t c_{t} ct; The other is Update door (update gate), It determines Current moment network c ~ t \tilde{c}_{t} c~t How much of the input is saved to the unit state c t c_{t} ct.LSTM use Output gate (output gate) To control Unit status c t c_{t} ct How much output to LSTM The current output value of a t a_{t} at.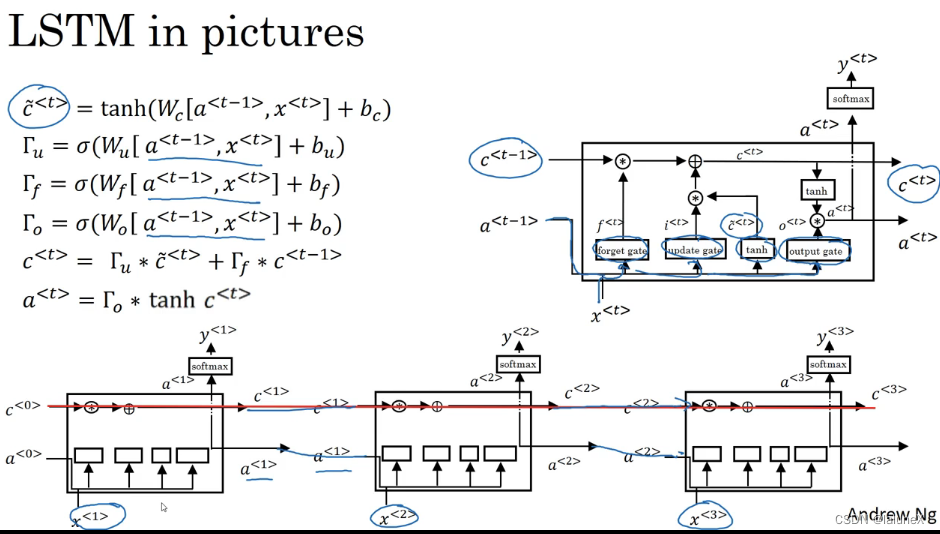
② Door control cycle unit (GRU)
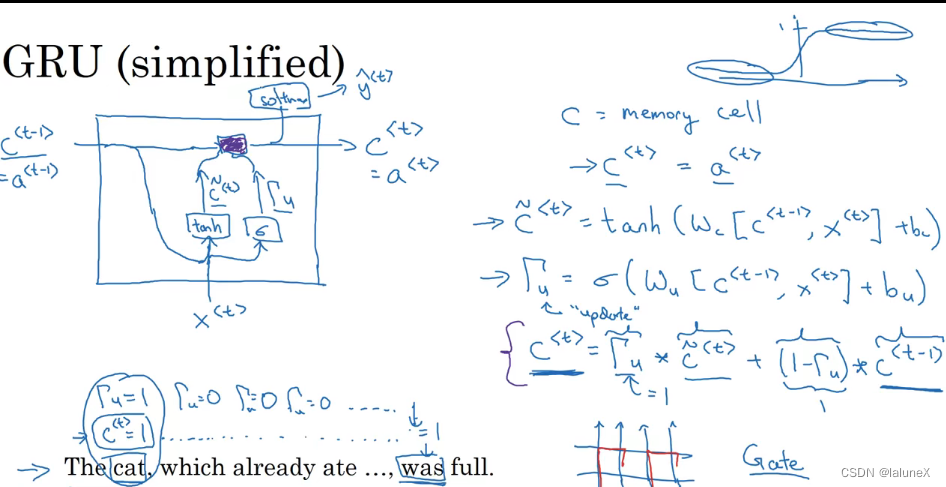
GRU (Gated Recurrent Unit) yes LSTM A variant of , Maybe the most successful one . It makes a lot of simplification , At the same time, it keeps the same relationship with LSTM Same effect .
GRU There are two Two doors , namely A reset door (reset gate) And an update door (update gate). Intuitively speaking , Reset door To determine the How to combine the new input information with the previous memory , Update door Defined The amount of previous memory saved to the current time step .
The following figure z Update doors for ,r To reset the door , r t r_t rt representative h t − 1 h_{t-1} ht−1 And h ~ t \tilde{h}_{t} h~t The correlation between 

The following figure is a simplified GRU( A door ):
3、 ... and 、 Two way recurrent neural network -BRNN(Bidirectional Recurrent Neural Networks)
because Standard recurrent neural network (RNN) Process sequence in time sequence , They tend to Ignored Future contextual information . A very obvious terms of settlement It's for the network Add future contextual information . Theoretically ,M It can be very large to capture all available information in the future , But in fact, I found that if M Too big , The prediction results will get worse .
Two way recurrent neural network (BRNN) The basic idea of is to make For each training sequence Forward and backward formation Two recurrent neural networks (RNN), And these two are connected An output layer . This structure is provided to Output layer At each point in the input sequence complete Past and future The context of .
Four 、 Deep circulation neural network (Deep RNN)
Deep circulation neural network In order to Enhance the expression ability of model And the network is set Multiple circulation layers 
This article is only for personal learning and recording , Tort made delete
边栏推荐
- 【Day_02 0419】排序子序列
- IP day 10 notes - BGP
- Age is a hard threshold! 42 years old, Tencent level 13, master of 985, looking for a job for three months, no company actually accepted!
- JS date details, string to date
- 将金额数字转换为大写
- 【C语言】文件操作
- 【故障诊断】基于贝叶斯优化支持向量机的轴承故障诊断附matlab代码
- C language introduction practice (7): switch case calculation of days in the year (normal year / leap year calculation)
- 【Day_04 0421】进制转换
- 【BM2 链表内指定区间反转】
猜你喜欢
![[C language] file operation](/img/19/5bfcbc0dc63d68f10155e16d99581c.png)
[C language] file operation

Basis of multimodal semantic segmentation
![[pytorch] fine tuning technology](/img/d3/6d0f60fffd815f520f4b3880bd0ac7.png)
[pytorch] fine tuning technology

Leetcode:940. How many subsequences have different literal values

Distributed | practice: smoothly migrate business from MYCAT to dble

【保姆级】包体积优化教程

Embedded sharing collection 14

C语言进阶——可存档通讯录(文件)

【图像去噪】基于双立方插值和稀疏表示实现图像去噪matlab源码

Embedded sharing collection 15
随机推荐
[pytorch] fine tuning technology
Convert amount figures to uppercase
【保姆级】包体积优化教程
移动web
Leetcode:741. picking cherries
多目标检测
MySQL multi table query introduction classic case
力扣——3. 无重复字符的最长子串
Embedded sharing collection 14
[day_060423] convert string to integer
分布式 | 实战:将业务从 MyCAT 平滑迁移到 dble
Leetcode:336. palindrome pair
Input the records of 5 students (each record includes student number and grade), form a record array, and then output them in order of grade from high to low The sorting method adopts selective sortin
【Day02_0419】C语言选择题
【Day_05 0422】统计回文
[Hangzhou][15k-20k] medical diagnosis company recruits golang development engineers without overtime! No overtime! No overtime!
Convolutional neural network (III) - target detection
@ConstructorProperties注解理解以及其对应使用方式
【Day04_0421】C语言选择题
[untitled]