当前位置:网站首页>Spark BUG实践(包含的BUG:ClassCastException;ConnectException;NoClassDefFoundError;RuntimeExceptio等。。。。)
Spark BUG实践(包含的BUG:ClassCastException;ConnectException;NoClassDefFoundError;RuntimeExceptio等。。。。)
2022-06-27 19:57:00 【wr456wr】
环境
scala版本:2.11.8
jdk版本:1.8
spark版本:2.1.0
hadoop版本:2.7.1
ubuntu版本:18.04
window版本:win10
scala代码在windows端编程,ubuntu在虚拟机安装,scala,jdk,spark,hadoop都安装在ubuntu端
问题一
问题描述:在使用wget下载scala时,出现 Unable to establish SSL connection
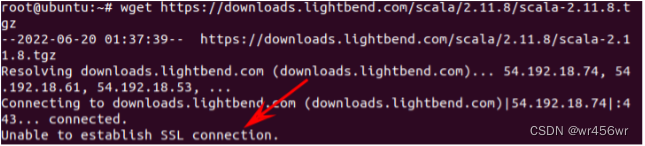
解决:
加上跳过验证证书的参数--no-check-certificate
问题二
问题描述:在使用scala程序测试wordCount程序时出现错误:
(scala程序在主机,spark安装在虚拟机)
22/06/20 22:35:38 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://192.168.78.128:7077...
22/06/20 22:35:41 WARN StandaloneAppClient$ClientEndpoint: Failed to connect to master 192.168.78.128:7077
org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:226)
...
Caused by: io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: no further information: /192.168.78.128:7077
Caused by: java.net.ConnectException: Connection refused: no further information

解决:
对spark下的conf目录内的spark-env.sh进行配置如下

配置后在spark目录下启动master和worker
bin/start-all.sh
之后再次运行wordCount程序,出现如下错误
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/06/20 22:44:09 INFO SparkContext: Running Spark version 2.4.8
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration$DeprecationDelta
at org.apache.hadoop.mapreduce.util.ConfigUtil.addDeprecatedKeys(ConfigUtil.java:54)
at org.apache.hadoop.mapreduce.util.ConfigUtil.loadResources(ConfigUtil.java:42)
at org.apache.hadoop.mapred.JobConf.<clinit>(JobConf.java:123)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-935LgtJu-1655814306434)(开发流程.assets/1655736581056.png)]](/img/05/ced290f170c5a54cf5f6e8b3085318.png)
在pom文件内引入hadooop依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
刷新依赖后运行程序,出现:
22/06/20 22:50:31 INFO spark.SparkContext: Running Spark version 2.4.8
22/06/20 22:50:31 INFO spark.SparkContext: Submitted application: wordCount
22/06/20 22:50:31 INFO spark.SecurityManager: Changing view acls to: Administrator
22/06/20 22:50:31 INFO spark.SecurityManager: Changing modify acls to: Administrator
22/06/20 22:50:31 INFO spark.SecurityManager: Changing view acls groups to:
22/06/20 22:50:31 INFO spark.SecurityManager: Changing modify acls groups to:
22/06/20 22:50:31 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Administrator); groups with view permissions: Set(); users with modify permissions: Set(Administrator); groups with modify permissions: Set()
Exception in thread "main" java.lang.NoSuchMethodError: io.netty.buffer.PooledByteBufAllocator.metric()Lio/netty/buffer/PooledByteBufAllocatorMetric;
at org.apache.spark.network.util.NettyMemoryMetrics.registerMetrics(NettyMemoryMetrics.java:80)
at org.apache.spark.network.util.NettyMemoryMetrics.<init>(NettyMemoryMetrics.java:76)

更新spark-core依赖版本,原本是2.1.0,现在更新为2.3.0,spark-core的pom依赖如下
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>2.3.0</version>
</dependency>
刷新依赖后再次运行又出现连接问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5aCGosbR-1655814306436)(开发流程.assets/1655737140250.png)]](/img/62/19cc73fb261628bd758bd1cc02ac9e.png)
修改pom依赖为
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mesos_2.11</artifactId>
<version>2.1.0</version>
</dependency>
刷新后再次报错:java.lang.RuntimeException: java.lang.NoSuchFieldException: DEFAULT_TINY_CACHE_SIZE
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a2eBPfzi-1655814306436)(开发流程.assets/1655779696035.png)]](/img/ea/521961d605216fe83d5422faffc33f.png)
添加io.netty依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.0.52.Final</version>
</dependency>
运行后再次出现连接问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b9NjY23a-1655814306437)(开发流程.assets/1655780018354.png)]](/img/63/09ae16b7418166366aa161ee9177ee.png)
查看虚拟机的spark的master启动情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TAi3JuIs-1655814306437)(开发流程.assets/1655780121179.png)]](/img/5f/6b896bd68648184d028f9cc85eb78d.png)
确实都启动成功,排除未启动成功原因
修改spark的conf下的spark-env .sh文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VY3mBPyk-1655814306437)(开发流程.assets/1655780670484.png)]](/img/ee/66bbe637481253ae3a9ecd0df678e9.png)
重新启动spark
sbin/start-all.sh
启动程序后成功连接到虚拟机的spark的master
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LnC2GfcA-1655814306438)(开发流程.assets/1655780808544.png)]](/img/dd/2ccd07fea591e7b0950517d92d97ab.png)
问题三
问题描述:
运行scala的wordCount出现:com.fasterxml.jackson.databind.JsonMappingException: Incompatible Jackson version: 2.13.0
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BFx03mtx-1655814306438)(开发流程.assets/1655781028153.png)]](/img/46/b28492219cd898cf3cc30b2e7b227e.png)
这是由于Jackson这个工具库的版本不一致导致的。解决方案:首先在Kafka的依赖项中,排除对于Jackon的依赖,从而阻止Maven自动导入高版本的库,随后手动添加较低版本Jackon库的依赖项,重新import即可。
添加依赖:
<dependency>
<groupId> org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>1.1.1</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.6.6</version>
</dependency>
导入后重新运行程序,再次出现问题:
NoClassDefFoundError: com/fasterxml/jackson/core/util/JacksonFeature
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SLr4iDc6-1655814306438)(开发流程.assets/1655781408043.png)]](/img/44/bac3f27b5292f815a7d430dfbbd675.png)
原因是jackson依赖不全,导入jackson依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.6.7</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.6.7</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.6.7</version>
</dependency>
再次运行出现:Exception in thread “main” java.net.ConnectException: Call From WIN-P2FQSL3EP74/192.168.78.1 to 192.168.78.128:9000 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)

推测这应该是hadoop连接拒绝,而不是spark的master连接问题
修改hadoop的etc下的core-site.xml文件

之后重新启动hadoop运行程序,出现新的问题:
WARN scheduler.TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, 0.0.0.0, executor 0): java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2301)
at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1431)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2411)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2329)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2187)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1667)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2405)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2329)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2187)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1667)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:503)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:461)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:99)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:282)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N6EssLDt-1655814306440)(开发流程.assets/1655786575000.png)]](/img/17/4845ada83ca6314a4380e990c95499.png)
从问题截图应该可以看到连接应该是没有问题的,以及开始了预定的wordCount工作,这次可能是代码层面的问题。
wordCount完整scala代码:
import org.apache.spark.{
SparkConf, SparkContext}
object WordCount {
def main(arg: Array[String]): Unit = {
val ip = "192.168.78.128";
val inputFile = "hdfs://" + ip + ":9000/hadoop/README.txt";
val conf = new SparkConf().setMaster("spark://" + ip + ":7077").setAppName("wordCount");
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
需要设置jar包,将项目进行打包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1fgMuGMF-1655814306440)(开发流程.assets/1655812962723.png)]](/img/10/7a769ec1c6a72cc1ccb9090a8d5163.png)
然后打包后的项目在target路径下,找到对应jar包位置,复制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nnVVC8Xn-1655814306440)(开发流程.assets/1655813012337.png)]](/img/34/6dc70b2b48b184ebcaa6f745cd341e.png)
复制路径添加到配置setJar方法内,完整Scala WordCount代码
import org.apache.spark.{
SparkConf, SparkContext}
object WordCount {
def main(arg: Array[String]): Unit = {
//打包后的jar包地址
val jar = Array[String]("D:\\IDEA_CODE_F\\com\\BigData\\Proj\\target\\Proj-1.0-SNAPSHOT.jar")
//spark虚拟机地址
val ip = "192.168.78.129";
val inputFile = "hdfs://" + ip + ":9000/hadoop/README.txt";
val conf = new SparkConf()
.setMaster("spark://" + ip + ":7077") //master节点地址
.setAppName("wordCount") //spark程序名
.setSparkHome("/root/spark") //spark安装地址(应该可以不用)
.setIfMissing("spark.driver.host", "192.168.1.112")
.setJars(jar) //设置打包后的jar包
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1)).reduceByKey((a, b) => a + b)
val str1 = textFile.first()
println("str: " + str1)
val l = wordCount.count()
println(l)
println("------------------")
val tuples = wordCount.collect()
tuples.foreach(println)
sc.stop()
}
}
运行的大致结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i1D32Pdr-1655814306441)(开发流程.assets/1655814085565.png)]](/img/b2/c56726e066147097086358d8bec899.png)
md,csdn什么时候可以直接导入markdown完整文件啊,每次本机写完导入图片都无法直接导入,还要一个一个截图粘贴上去
边栏推荐
- Stunned! The original drawing function of markdown is so powerful!
- 改善深层神经网络:超参数调试、正则化以及优化(三)- 超参数调试、Batch正则化和程序框架
- 渗透学习-靶场篇-pikachu靶场详细攻略(持续更新中-目前只更新sql注入部分)
- 游戏手机平台简单介绍
- 【微服务】(十六)—— 分布式事务Seata
- 渗透学习-靶场篇-dvwa靶场详细攻略(持续更新中-目前只更新sql注入部分)
- "I make the world cooler" 2022 Huaqing vision R & D product launch was a complete success
- The "business and Application Security Development Forum" held by the ICT Institute was re recognized for the security capability of Tianyi cloud
- Passerelle de service pour les microservices
- 7 jours d'apprentissage de la programmation simultanée go 7 jours de programmation simultanée go Language Atomic Atomic Atomic actual Operation contains ABA Problems
猜你喜欢

渗透学习-靶场篇-pikachu靶场详细攻略(持续更新中-目前只更新sql注入部分)

解决本地连接不上虚拟机的问题

雪糕还是雪“高”?

對話喬心昱:用戶是魏牌的產品經理,零焦慮定義豪華
扁平数组和JSON树的转换

7 jours d'apprentissage de la programmation simultanée go 7 jours de programmation simultanée go Language Atomic Atomic Atomic actual Operation contains ABA Problems

The "business and Application Security Development Forum" held by the ICT Institute was re recognized for the security capability of Tianyi cloud
微服务之服务网关
Solve the problem that the virtual machine cannot be connected locally

Educational Codeforces Round 108 (Rated for Div. 2)

随机推荐
7 jours d'apprentissage de la programmation simultanée go 7 jours de programmation simultanée go Language Atomic Atomic Atomic actual Operation contains ABA Problems
爬虫笔记(1)- urllib
结构化机器学习项目(二)- 机器学习策略(2)
Character interception triplets of data warehouse: substrb, substr, substring
Windwos 8.1系统安装vmware tool插件报错的解决方法
The karsonzhang/fastadmin addons provided by the system reports an error
Basics of operators
[suggested collection] ABAP essays-excel-4-batch import recommended
Codeforces Round #717 (Div. 2)
One to many association in MySQL to obtain the latest data in multiple tables
Conversation Qiao Xinyu: l'utilisateur est le gestionnaire de produits Wei Brand, zéro anxiété définit le luxe
关于davwa的SQL注入时报错:Illegal mix of collations for operation ‘UNION‘原因剖析与验证
《7天学会Go并发编程》第六天 go语言Sync.cond的应用和实现 go实现多线程联合执行
Login credentials (cookie+session and token token)
Solution to the error of VMware tool plug-in installed in Windows 8.1 system
改善深层神经网络:超参数调试、正则化以及优化(三)- 超参数调试、Batch正则化和程序框架
MySQL数据库 实验报告(一)
Memoirs of actual combat: breaking the border from webshell
Beijing University of Posts and Telecommunications - multi-agent deep reinforcement learning for cost and delay sensitive virtual network function placement and routing
ABAP essay-excel-3-batch import (breaking through 9999 lines of standard functions)