当前位置:网站首页>Introduction to spark learning - 1
Introduction to spark learning - 1
2022-08-03 16:04:00 【@Autowire】
1 配置
export SCALA_HOME=/Users/zhaoshuai11/work/scala-2.12.14
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home
## 指定spark老大Master的IP和提交任务的通信端口
export SPARK_MASTER_IP=localhost
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI=8080
export SPARK_WORKER_CORES=1
export SPARK_MEMORY=1g
export HADOOP_CONF_DIR=/Users/zhaoshuai11/work/hadoop-2.7.3
export YARN_CONF_DIR=/Users/zhaoshuai11/work/hadoop-2.7.3/etc/hadoop
export PATH=$SPARK_HOME/bin:$PATH
1 配置Yarn历史服务器并关闭资源检查
* /Users/zhaoshuai11/work/hadoop-2.7.3/etc/hadoop vim mapred-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
</configuration>
* /Users/zhaoshuai11/work/hadoop-2.7.3/etc/hadoop vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 配置yarn的历史服务器-->
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/logs</value>
</property>
<!--配置yarn主节点的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
</configuration>
2 配置Sparkinstance server and Yarn的整合
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/conf vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address localhost:18080
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/conf vim spark-env.sh
export SPARK_HISTORY_OPTS=" -Dspark.history.fs.logDirectory=hdfs://localhost:8020/sparklog -Dspark.history.fs.cleaner.enabled=true"
手动创建 sparklog
hadoop fs -mkdir /sparklog
修改日志级别
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/conf cp log4j.properties.template log4j.properties
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/conf vim log4j.properties
log4j.rootCategory=WARN, console
3 配置依赖的jar包
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/jars hadoop fs -mkdir -p /spark/jars/
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/conf vim spark-defaults.conf
spark.yarn.jars hdfs://localhost:8020/spark/jars/*
* /Users/zhaoshuai11/work/hadoop-2.7.3/sbin mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /Users/zhaoshuai11/work/hadoop-2.7.3/logs/mapred-zhaoshuai11-historyserver-localhost.out
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/sbin ./start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/logs/spark-zhaoshuai11-org.apache.spark.deploy.history.HistoryServer-1-localhost.out
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/sbin
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/sbin jps
38419 Jps
37731 NodeManager
38227 JobHistoryServer
37524 SecondaryNameNode
37334 NameNode
38311 HistoryServer
37639 ResourceManager
37421 DataNode
http://localhost:19888/jobhistory
http://localhost:18080/
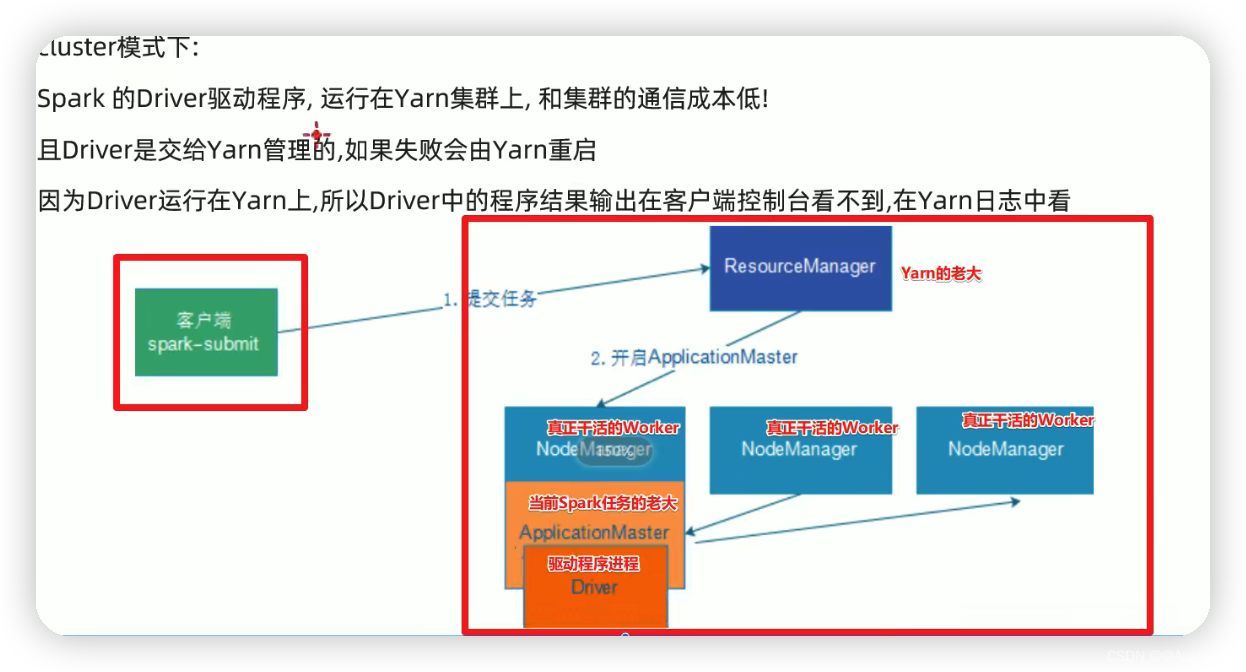
2 There are two modes of operation-client&cluster
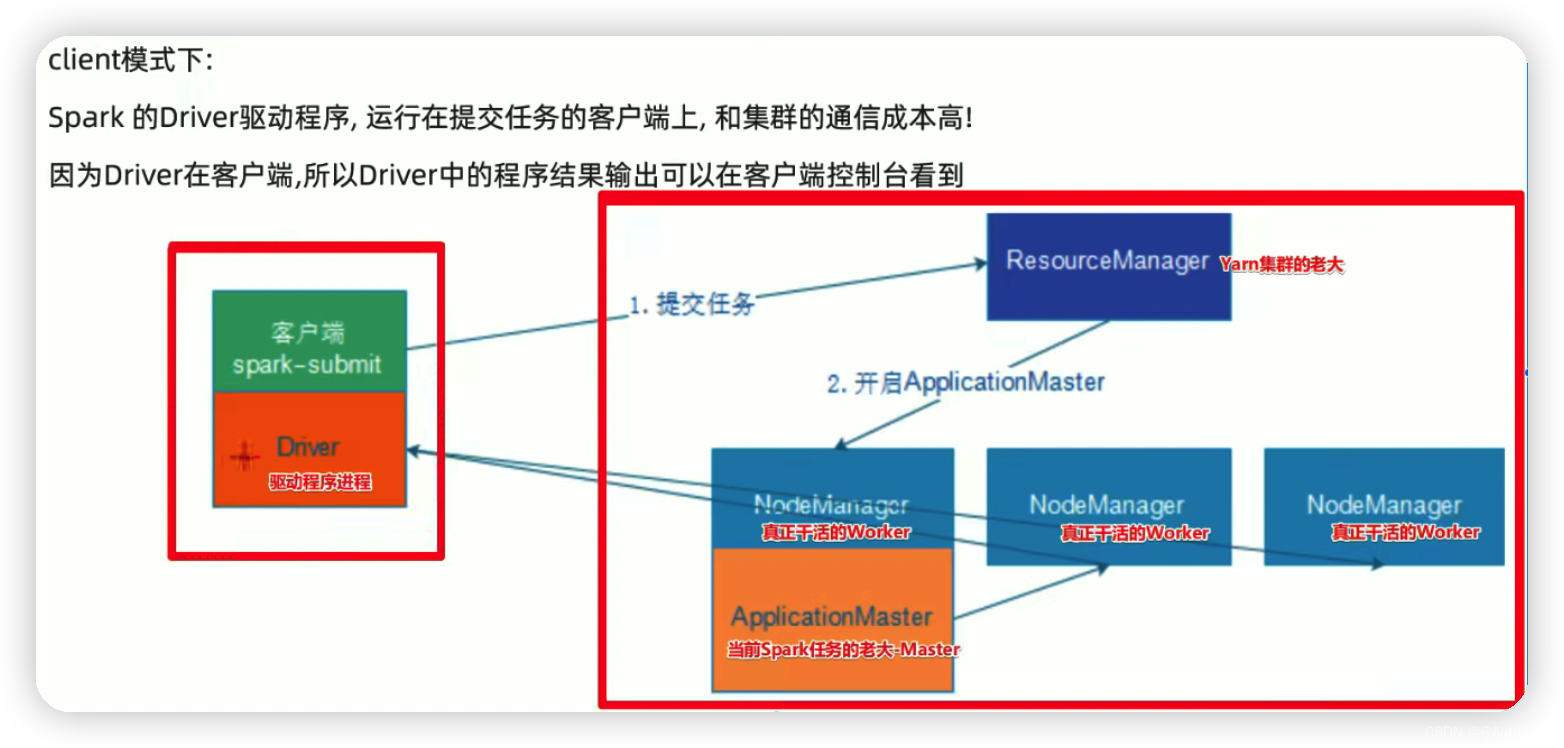
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/bin spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --executor-memory 512M --num-executors 2 /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.1.jar 100
22/07/31 08:38:47 WARN Utils: Your hostname, localhost resolves to a loopback address: 127.0.0.1; using 192.168.199.241 instead (on interface en0)
22/07/31 08:38:47 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
22/07/31 08:38:48 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Pi is roughly 3.1413315141331513
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/bin
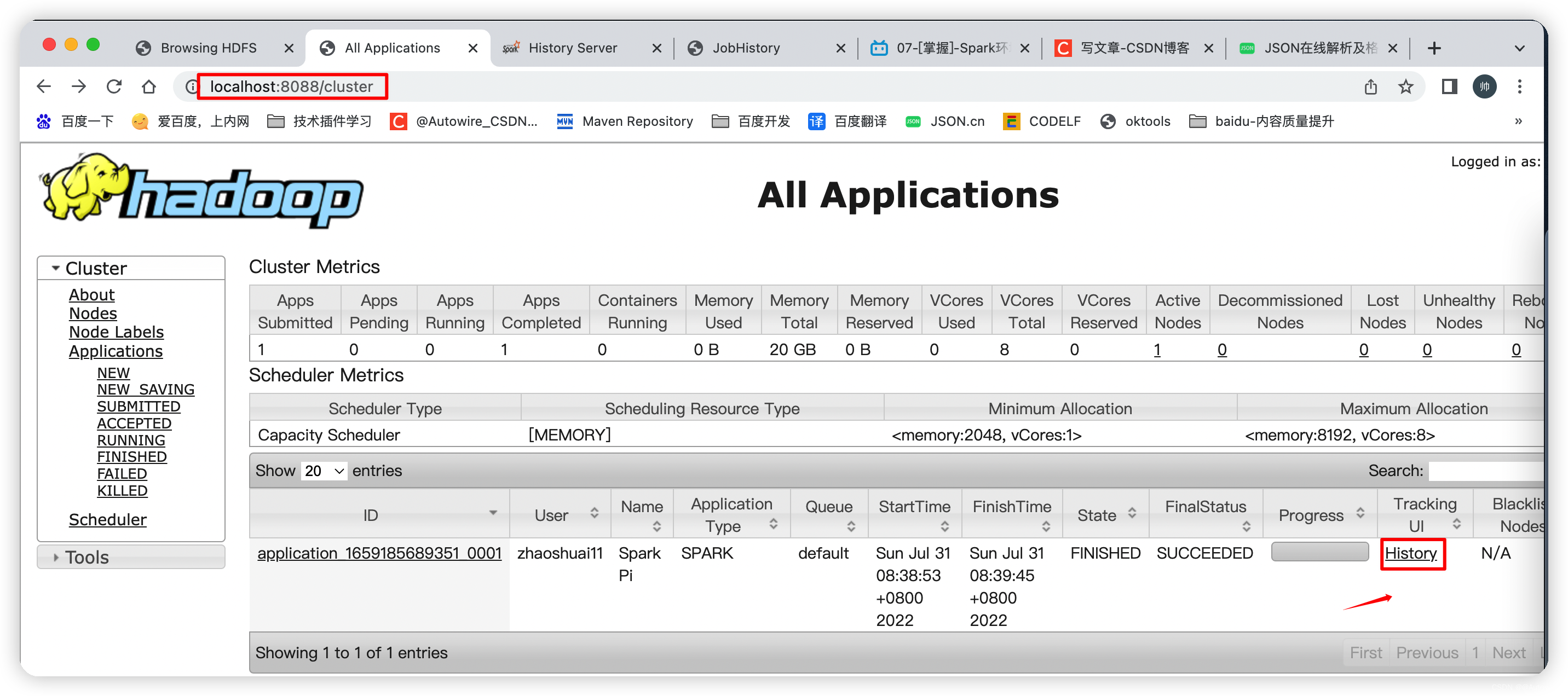
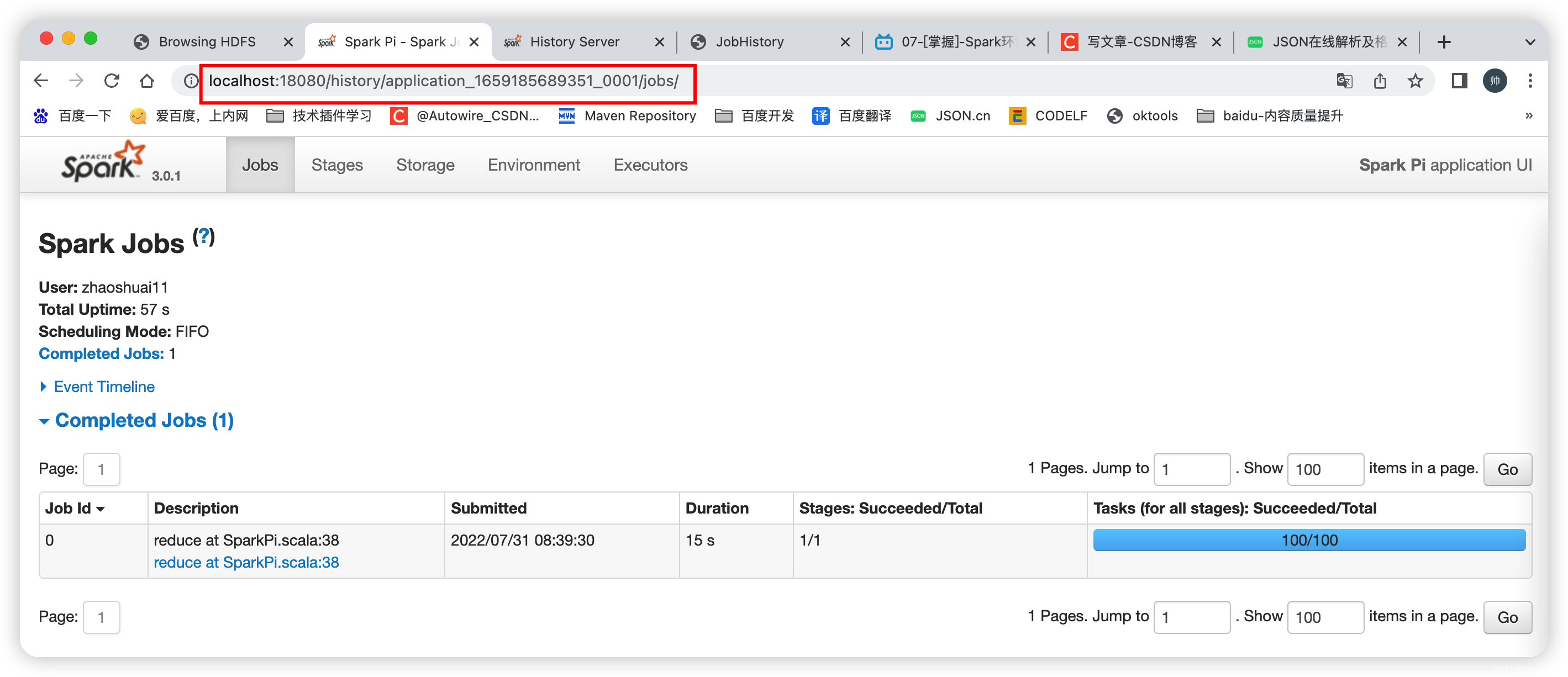
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/bin spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory 512M --num-executors 2 /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.1.jar 100
22/07/31 08:43:46 WARN Utils: Your hostname, localhost resolves to a loopback address: 127.0.0.1; using 192.168.199.241 instead (on interface en0)
22/07/31 08:43:46 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
22/07/31 08:43:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/bin
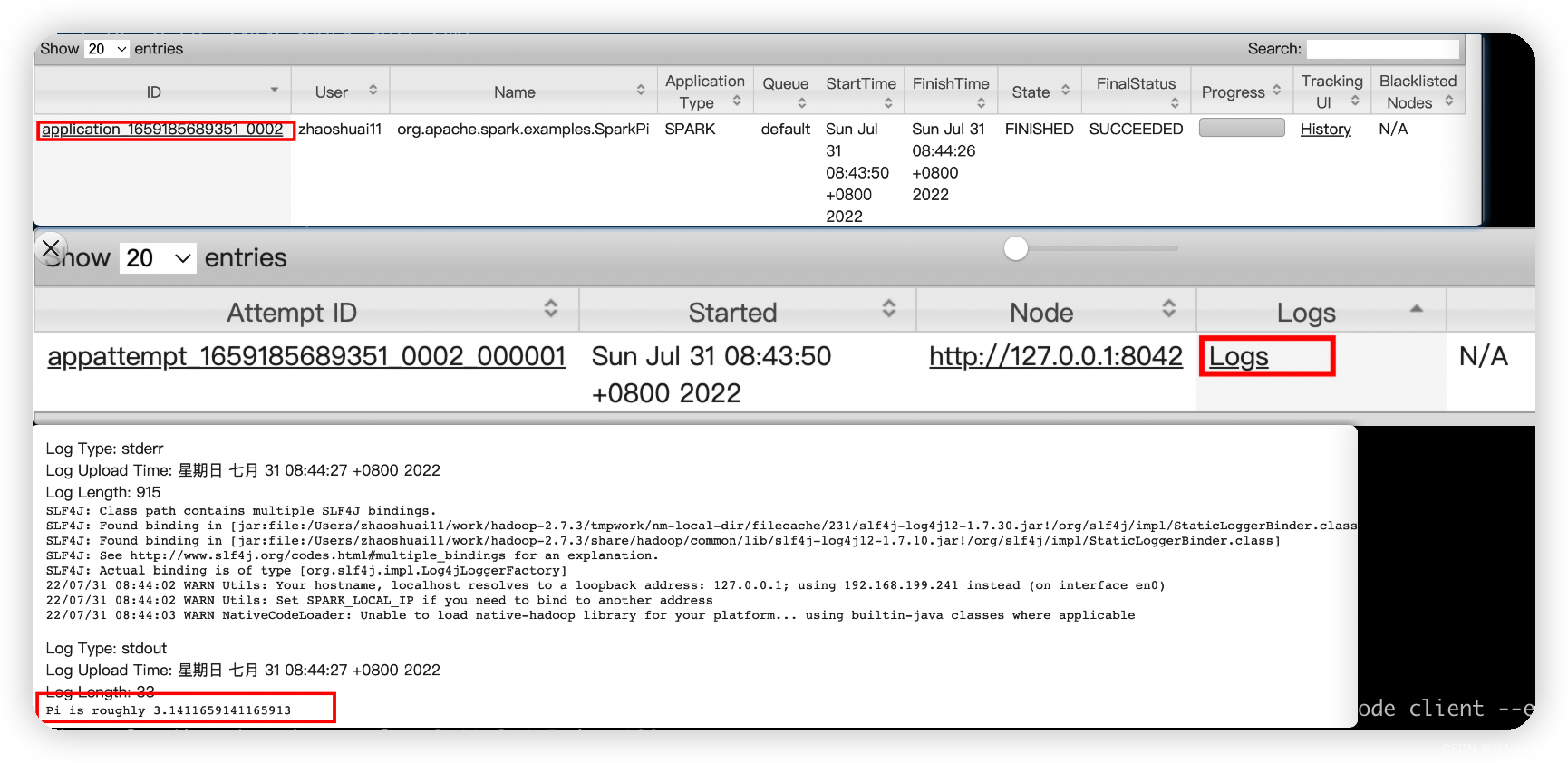
3 spark-shell && spark-submit
spark-shell: spark应用交互式窗口,启动后可以直接编写spark代码,即时运行,一般在学习测试时使用
spark-submit: 用来将spark任务/程序的jar包提交到spark集群(一般都是提交到Yarn集群)
–master 【参数如下】:
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/bin ./spark-shell --help
Usage: ./bin/spark-shell [options]
Scala REPL options:
-I <file> preload <file>, enforcing line-by-line interpretation
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf, -c PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
Spark standalone, Mesos or K8s with cluster deploy mode only:
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone, Mesos and Kubernetes only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone, YARN and Kubernetes only:
--executor-cores NUM Number of cores used by each executor. (Default: 1 in
YARN and K8S modes, or all available cores on the worker
in standalone mode).
Spark on YARN and Kubernetes only:
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--principal PRINCIPAL Principal to be used to login to KDC.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above.
Spark on YARN only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
* /Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/bin ./spark-submit --help
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf, -c PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
Spark standalone, Mesos or K8s with cluster deploy mode only:
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone, Mesos and Kubernetes only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone, YARN and Kubernetes only:
--executor-cores NUM Number of cores used by each executor. (Default: 1 in
YARN and K8S modes, or all available cores on the worker
in standalone mode).
Spark on YARN and Kubernetes only:
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--principal PRINCIPAL Principal to be used to login to KDC.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above.
Spark on YARN only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
4 spark Program development case
http://localhost:50070/explorer.html#/
http://localhost:8088/cluster/
http://localhost:18080/
http://localhost:19888/jobhistory
spark-submit \
--class com.baidu.sparkcodetest.wordCount \
--master yarn \
--deploy-mode cluster \
--executor-memory 512M \
--num-executors 2 \
/Users/zhaoshuai11/work/spark-3.0.1-bin-hadoop2.7/myJars/wordcount.jar \
hdfs://localhost:8020/itcast/hello.txt \
hdfs://localhost:8020/itcast/wordcount/output_1
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.baidu.cpd</groupId>
<artifactId>stu-scala</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scala-lang/scala-library -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.14</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive-thriftserver -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<extensions>
<extension>
<groupId>kr.motd.maven</groupId>
<artifactId>os-maven-plugin</artifactId><!--Introduce the operating systemosSet properties for plugins,否则${os.detected.classifier} The OS version will not be found -->
<version>1.5.0.Final</version>
</extension>
</extensions>
<plugins>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!--<arg>-make:transitive</arg>-->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
<configuration>
<scalaVersion>2.12.14</scalaVersion>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<!-- If you have classpath issue like NoDefClassError,... -->
<!-- useManifestOnlyJar>false</useManifestOnlyJar -->
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
<encoding>UTF8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<!-- package with project dependencies -->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
package com.baidu.sparkcodetest
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object wordCount {
def main(args: Array[String]): Unit = {
if (args.length < 2) {
println("请指定input & output")
System.exit(1) // 非0 - 非正常退出
}
// 1 准备sc-SparkContext上下文执行环境
val sc = new SparkContext(new SparkConf().setAppName("wordCount"))
// 2 source 读取数据
val lines: RDD[String] = sc.textFile(args(0))
// 3 业务处理
val words = lines.flatMap(_.split(" "))
val wordAndOnes: RDD[(String, Int)] = words.map((_, 1))
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_ + _)
// 4 输出文件
System.setProperty("HADOOP_USER_NAME", "root")
result.repartition(1).saveAsTextFile(args(1))
sc.stop()
}
}
5 RDD
RDD:弹性分布式数据集,是Spark中最基本的数据抽象.用来表示分布式集合,支持分布式操作!
在内部,每个RDD具有五个主要特性:
1 分区列表
2 The function used to compute each shard
3 对其他RDD的依赖关系列表
4 可选地,用于键值RDD的分区器(例如,说RDD是哈希分区的)
5 可选地,Compute a list of preferred locations for each shard(例如HDFS文件的块位置)
package com.baidu.sparkcodetest.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * 演示RDD的创建 */
object RDDDemo_Create {
def main(args: Array[String]): Unit = {
// 1创建环境
val sc = new SparkContext(new SparkConf().setAppName("RDDDemo_Create").setMaster("local[*]"))
sc.setLogLevel("WARN")
// 2加载数据 创建RDD
// RDD[行数据]
val rdd1: RDD[Int] = sc.parallelize(1 to 10) // 8
val rdd2: RDD[Int] = sc.parallelize(1 to 10, 3) // 3
val rdd3: RDD[Int] = sc.makeRDD(1 to 10) // 8
val rdd4: RDD[Int] = sc.makeRDD(1 to 10, 4) // 4
val rdd5: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt") // 2 -- 小文件 Distributed least in the cluster2个
val rdd6: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt", 3) // 4
val rdd7: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/file") // 2 One small file one partition
val rdd8: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/file", 3) // 4
// RDD[文件名,行数据] Read small files-wholeTextFiles
val rdd9: RDD[(String, String)] =
sc.wholeTextFiles("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/file") // 2
val rdd10: RDD[(String, String)] =
sc.wholeTextFiles("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/file", 3) // 2
// 3业务操作
// 4输出
// 5关闭资源
}
}
6 RDD 操作分类
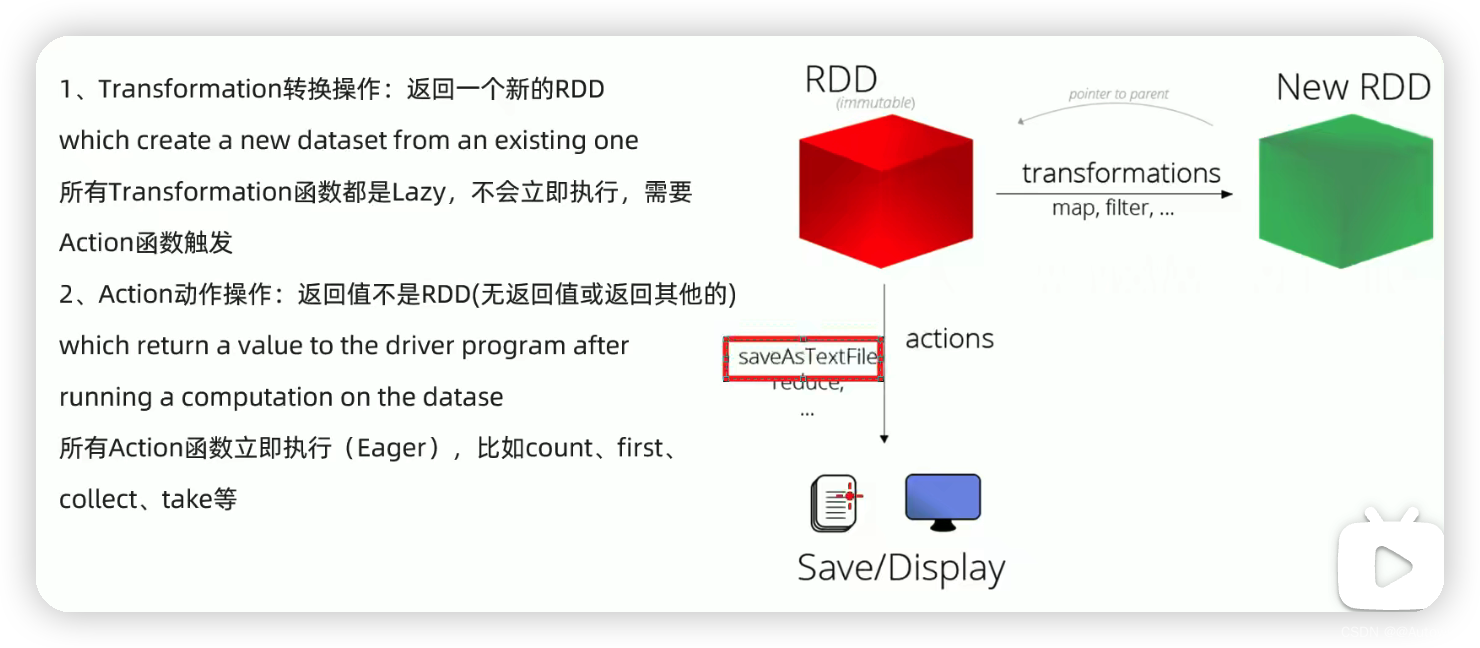
1 基本算子、API操作
map flatMap filter foreach saveAsTextFile
package com.baidu.sparkcodetest.rdd
import org.apache.commons.lang3.StringUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_Transform_action {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("RDDDemo_Create").setMaster("local[*]"))
sc.setLogLevel("WARN")
val lines =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
val result: RDD[(String, Int)] = lines.filter(StringUtils.isNotBlank(_))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
result.foreach(println)
result.saveAsTextFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/output")
}
}
(worldhello,4)
("",3)
(hello,48)
(world,9)
2 分区操作***partitions
package com.baidu.sparkcodetest.rdd
import org.apache.commons.lang3.StringUtils
import org.apache.spark.{
SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object RDDDemo_Transform_action_partition {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("RDDDemo_Transform_action_partition").setMaster("local[*]"))
sc.setLogLevel("WARN")
val lines =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
println(lines.getNumPartitions)
val result: RDD[(String, Int)] = lines.filter(StringUtils.isNotBlank(_))
.flatMap(_.split(" "))
// .map((_,1)) Operate on each piece of data in the partition
.mapPartitions(iter => {
// Operate on each partition
// 开启连接 -- 有几个分区就执行几次
iter.map((_, 1)) // Acts on each piece of data in the partition
// 关闭连接
}).reduceByKey(_ + _)
result.foreachPartition(iter => {
iter.foreach(println)
})
}
}
/**
* 2
* (worldhello,4)
* ("",3)
* (hello,48)
* (world,9)
*/
3 重分区操作
package com.baidu.sparkcodetest.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_Transform_action_repartion_coalesce {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("RDDDemo_Transform_action_partition").setMaster("local[*]"))
sc.setLogLevel("WARN")
// 增加减少分区 Note that the original does not change
val rdd1: RDD[Int] = sc.parallelize(1 to 10) // 8
val rdd2: RDD[Int] = rdd1.repartition(10) // 10
val rdd3: RDD[Int] = rdd1.repartition(11) // 11
// 默认减少分区 Note that the original does not change
val rdd4: RDD[Int] = rdd1.coalesce(5) // 5
val rdd5: RDD[Int] = rdd1.coalesce(4) // 5
// 等同于 repartition
val rdd6: RDD[Int] = rdd1.coalesce(9, shuffle = true)
}
}
4 聚合算子
package com.baidu.sparkcodetest.rdd
import org.apache.spark.{
SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object RDDDemo_agg_noKey {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("RDDDemo_Transform_action_partition").setMaster("local[*]"))
sc.setLogLevel("WARN")
val rdd1: RDD[Int] = sc.parallelize(1 to 10)
// rdd1 各元素的和
println(rdd1.sum()) // 55
println(rdd1.reduce(_ + _))
println(rdd1.fold(0)(_ + _))
println(rdd1.aggregate(0)(_ + _, _ + _))
}
}
package com.baidu.sparkcodetest.rdd
import org.apache.commons.lang3.StringUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_agg_key {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("RDDDemo_Transform_action_partition").setMaster("local[*]"))
sc.setLogLevel("WARN")
val lines: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
val wordAndOne: RDD[(String, Int)] = lines.filter(StringUtils.isNotBlank(_))
.flatMap(_.split(" "))
.map((_, 1))
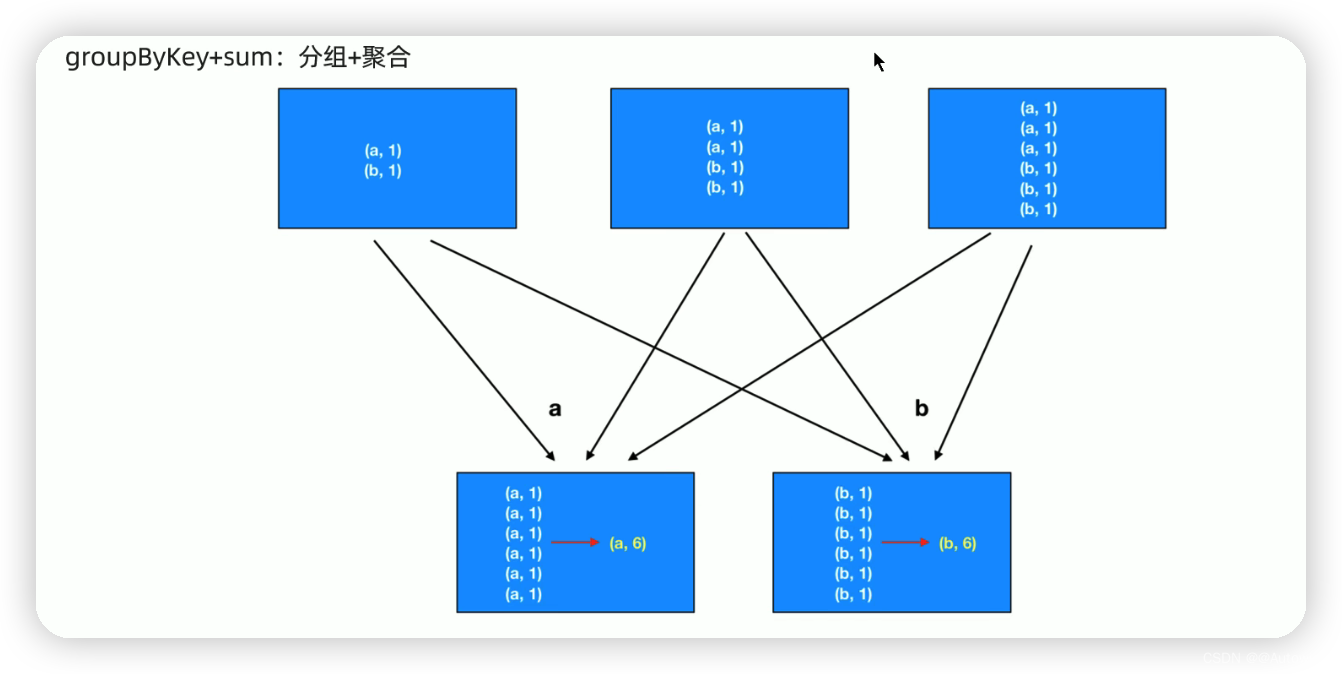
// 分组+聚合 groupByKey & groupBy
val grouped: RDD[(String, Iterable[Int])] = wordAndOne.groupByKey()
// val grouped: RDD[(String, Iterable[(String, Int)])] = wordAndOne.groupBy(_._1)
val result: RDD[(String, Int)] = grouped.mapValues(_.sum)
result.foreach(println)
/** * (worldhello,4) * ("",3) * (hello,48) * (world,9) */
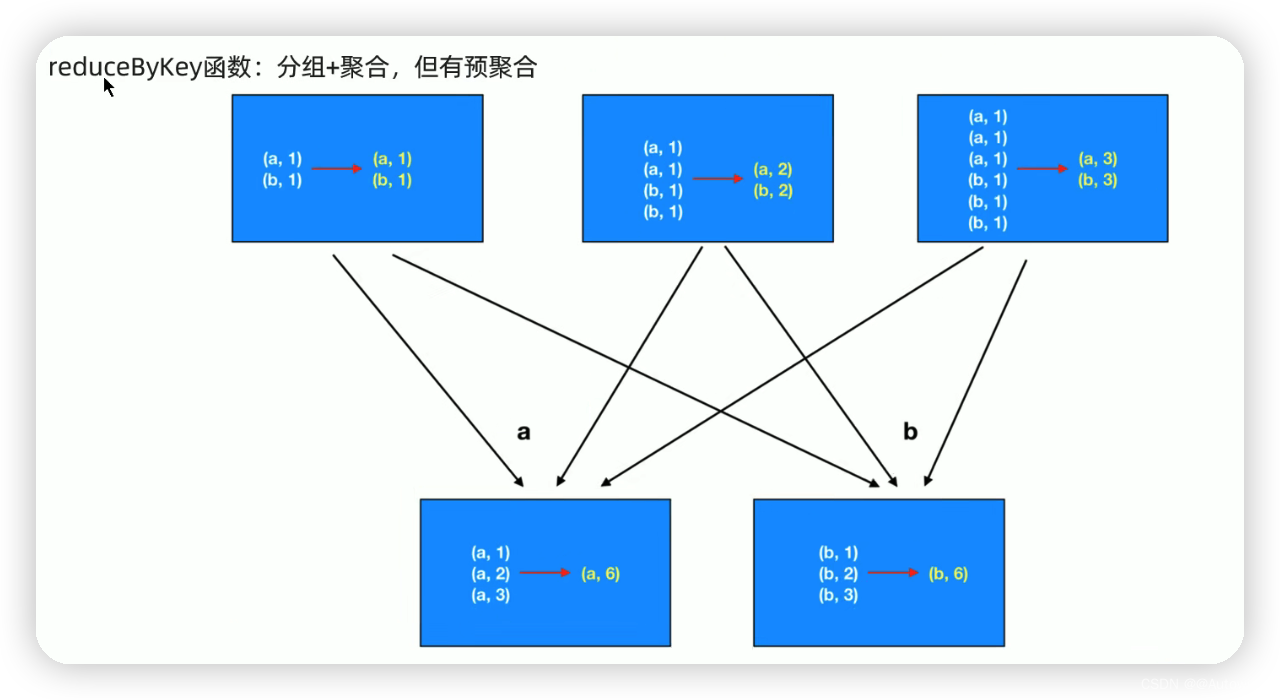
// 分组+聚合 reduceByKey
val result2: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result2.foreach(println)
// 分组+聚合 foldByKey
val result3: RDD[(String, Int)] = wordAndOne.foldByKey(0)(_ + _)
result3.foreach(println)
// 分组+聚合 aggregateByKey
val result4: RDD[(String, Int)] = wordAndOne.aggregateByKey(0)(_ + _, _ + _)
result4.foreach(println)
}
}
5 reduceByKey && groupByKey
7 RDD 的关联 JOIN
package com.baidu.sparkcodetest.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_join {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("RDDDemo_join").setMaster("local[*]"))
sc.setLogLevel("WARN")
// 员工集合 RDD[部门编号, 员工姓名]
val emptyRDD: RDD[(Int, String)] = sc.parallelize(
Seq(
(1001, "zhangsan"), (1002, "Lisi"), (1003, "wangwu"), (1004, "zhaoliu")
)
)
// department collection[部门编号, 部门名称]
val deptRDD: RDD[(Int, String)] = sc.parallelize(
Seq(
(1001, "销售部"), (1002, "技术部"), (1004, "客服部")
)
)
// Find the department name corresponding to the employee
val result1: RDD[(Int, (String, String))] = emptyRDD.join(deptRDD)
result1.foreach(println)
/** * (1004,(zhaoliu,客服部)) * (1002,(Lisi,技术部)) * (1001,(zhangsan,销售部)) */
println("******************")
val result2: RDD[(Int, (String, Option[String]))] = emptyRDD.leftOuterJoin(deptRDD)
result2.foreach(println)
/** * (1003,(wangwu,None)) * (1001,(zhangsan,Some(销售部))) * (1004,(zhaoliu,Some(客服部))) * (1002,(Lisi,Some(技术部))) */
println("******************")
val result3: RDD[(Int, (Option[String], String))] = emptyRDD.rightOuterJoin(deptRDD)
result3.foreach(println)
/** * (1002,(Some(Lisi),技术部)) * (1001,(Some(zhangsan),销售部)) * (1004,(Some(zhaoliu),客服部)) */
}
}
8 排序 sortByKey && sortBy && top
package com.baidu.sparkcodetest.rdd
import com.baidu.utils.LoggerTrait
import org.apache.commons.lang3.StringUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_sort extends LoggerTrait {
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_sort").setMaster("local[*]")
val sc = new SparkContext(conf)
// 2 source 读取数据
val lines: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
val result: RDD[(String, Int)] = lines.filter(StringUtils.isNotBlank(_))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
val top3: Array[(String, Int)] = result.sortBy(_._2, ascending = false).take(3) // The number of singles is in descending order,去除top3
top3.foreach(println)
/** * (hello,4) * (me,3) * (you,2) */
println("********")
// take The resulting array can only be used when it is small
val top3_1: Array[(Int, String)] = result.map(_.swap).sortByKey(ascending = false).take(3)
top3_1.foreach(println)
println("*******")
/** * (4,hello) * (3,me) * (2,you) */
// The resulting array can only be used when it is small
val top3_2: Array[(String, Int)] = result.top(3)(Ordering.by(_._2)) // topN
top3_2.foreach(println)
/** * (hello,4) * (me,3) * (you,2) */
}
}
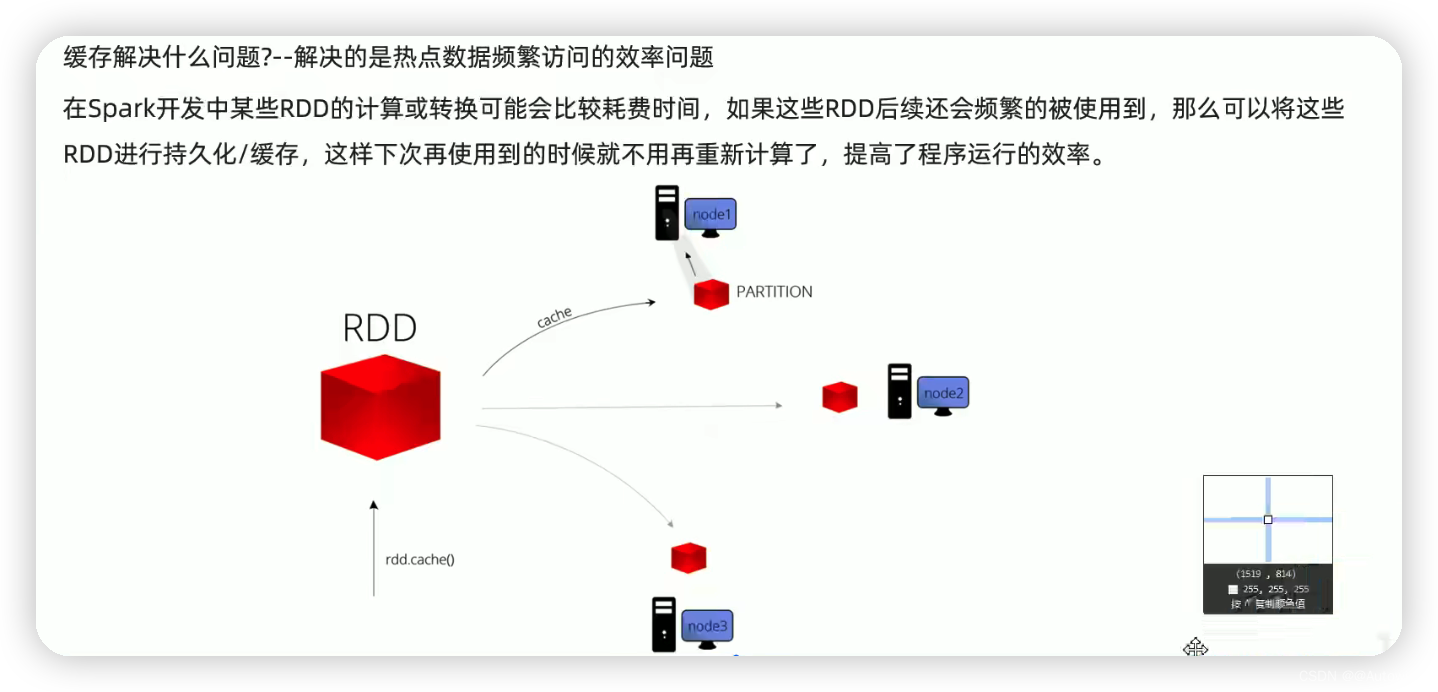
9 RDD 的持久化-缓存

package com.baidu.sparkcodetest.rdd
import org.apache.commons.lang3.StringUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_cache {
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_sort").setMaster("local[*]")
val sc = new SparkContext(conf)
// 2 source 读取数据
val lines: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
val result: RDD[(String, Int)] = lines.filter(StringUtils.isNotBlank(_))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
// result will be used frequently in the future 且该RDD的计算过程比较复杂,So in order to improve subsequent visits to thatRDD的效率,放到缓存中
result.cache()
// result.persist()
// result.persist(StorageLevel.MEMORY_AND_DISK)
/** * def cache(): this.type = persist() * def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) * */
val top3: Array[(String, Int)] = result.sortBy(_._2, ascending = false).take(3) // The number of singles is in descending order,去除top3
top3.foreach(println)
/** * (hello,4) * (me,3) * (you,2) */
println("********")
// take The resulting array can only be used when it is small
val top3_1: Array[(Int, String)] = result.map(_.swap).sortByKey(ascending = false).take(3)
top3_1.foreach(println)
println("*******")
/** * (4,hello) * (3,me) * (2,you) */
// The resulting array can only be used when it is small
val top3_2: Array[(String, Int)] = result.top(3)(Ordering.by(_._2)) // topN
top3_2.foreach(println)
/** * (hello,4) * (me,3) * (you,2) */
result.unpersist()
}
}
缓存级别:
10 Checkpoint


package com.baidu.sparkcodetest.rdd
import com.baidu.utils.LoggerTrait
import org.apache.commons.lang3.StringUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_checkpoint extends LoggerTrait{
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_checkpoint").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setCheckpointDir("hdfs://localhost:8020/output/ckp/result_checkpoint/") // actually writtenhdfs的目录
// 2 source 读取数据
val lines: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
val result: RDD[(String, Int)] = lines.filter(StringUtils.isNotBlank(_))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
result.foreach(println)
result.checkpoint() //设置检查点
println(result.count())
println(result.isCheckpointed) //Determines whether to set checkpoints
println(result.getCheckpointFile) //Get the file directory where the checkpoint is located
/** * * 缓存持久化 并不能 保证RDDAbsolute security of data,所以应该使用checkpoint把数据放到HDFS */
result.unpersist()
}
}
11 共享变量

package com.baidu.sparkcodetest.rdd
import com.baidu.utils.LoggerTrait
import org.apache.commons.lang3.StringUtils
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{
SparkConf, SparkContext}
import java.lang
object RDDDemo_share_variables extends LoggerTrait {
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_share_variables").setMaster("local[*]")
val sc = new SparkContext(conf)
// 2 source 读取数据
val lines: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
// 3 统计词频 Filter non-word symbols
/** * 累加器Accumulators * 累加器支持在所有不同节点之间进行累加计算(比如计数或者求和); */
val myCounter: LongAccumulator = sc.longAccumulator("myCounter")
// Defines a set of special characters
val ruleList: List[String] = List(",", ".", "@", "!", "*", "%", "$", "#")
// The so-called broadcast variables will be set broadcast to all nodes
val broadcast: Broadcast[List[String]] = sc.broadcast(ruleList)
val result: RDD[(String, Int)] = lines.filter(StringUtils.isNoneBlank(_))
.flatMap(_.split("\\s+"))
.filter(ch => {
// 获取广播数据
val list: List[String] = broadcast.value
if (list.contains(ch)) {
myCounter.add(1)
false
} else {
true
}
}).map((_, 1))
.reduceByKey(_ + _)
result.foreach(println)
println("***************")
val chResult: lang.Long = myCounter.value
println(chResult)
/** * (hello,4) * (you,2) * (me,3) * (her,1) * ************** * 4 */
}
}
package com.baidu.sparkcodetest.rdd
import com.baidu.utils.LoggerTrait
import org.apache.commons.lang3.StringUtils
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{
SparkConf, SparkContext}
import java.lang
object RDDDemo_share_variables extends LoggerTrait {
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_share_variables").setMaster("local[*]")
val sc = new SparkContext(conf)
// 2 source 读取数据
val lines: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
// 3 统计词频 Filter non-word symbols
/** * 累加器Accumulators * 累加器支持在所有不同节点之间进行累加计算(比如计数或者求和); */
val myCounter: LongAccumulator = sc.longAccumulator("myCounter")
// Defines a set of special characters
val ruleList: List[String] = List(",", ".", "@", "!", "*", "%", "$", "#")
// The so-called broadcast variables will be set broadcast to all nodes
val broadcast: Broadcast[List[String]] = sc.broadcast(ruleList)
val result: RDD[(String, Int)] = lines.filter(StringUtils.isNoneBlank(_))
.flatMap(_.split("\\s+"))
.filter(ch => {
// 获取广播数据
// val list: List[String] = broadcast.value
if (ruleList.contains(ch)) {
// if (list.contains(ch)) {
myCounter.add(1)
false
} else {
true
}
}).map((_, 1))
.reduceByKey(_ + _)
result.foreach(println)
println("***************")
val chResult: lang.Long = myCounter.value
println(chResult)
/** * (hello,4) * (you,2) * (me,3) * (her,1) * ************** * 4 */
}
}
区别: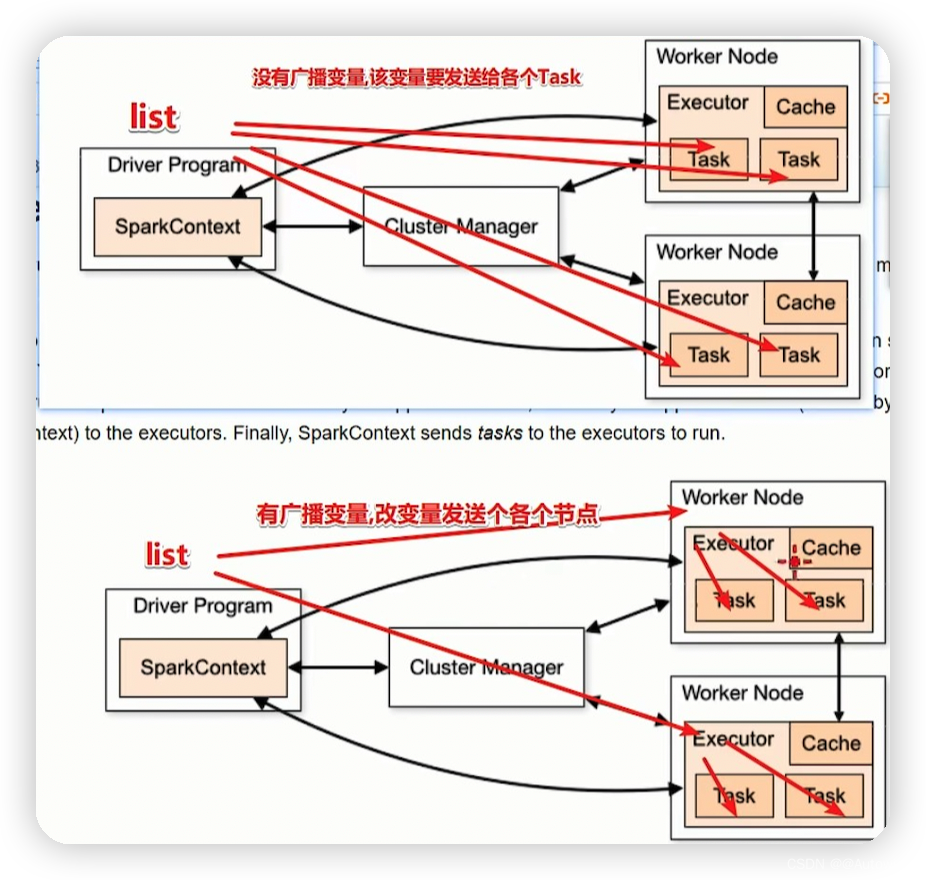
There are no broadcast variables,This variable is sent to eachTask
There are broadcast variables,This variable is sent to each node
12 多种数据源
1 Seq文件
package com.baidu.sparkcodetest.rdd
import com.baidu.utils.LoggerTrait
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object RDDDemo_datasource extends LoggerTrait {
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_datasource").setMaster("local[*]")
val sc = new SparkContext(conf)
// 2 source 读取数据
val lines: RDD[String] =
sc.textFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/helloworld.txt")
// 业务处理
val words = lines.flatMap(_.split(" "))
val wordAndOnes: RDD[(String, Int)] = words.map((_, 1))
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_ + _)
// 输出
result.foreach(println)
// 1 为文件
result.repartition(1)
.saveAsTextFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/output/result1")
// 2
result.repartition(1)
.saveAsObjectFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/output/result2")
// 3
result.repartition(1)
.saveAsSequenceFile("/Users/zhaoshuai11/Desktop/baidu/ebiz/stu-scala/src/main/resources/output/result3")
sc.stop()
}
}
13 JDBC
package com.baidu.sparkcodetest.rdd
import com.baidu.utils.LoggerTrait
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
import java.sql.{
Connection, DriverManager, PreparedStatement}
object RDDDemo_jdbc extends LoggerTrait {
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_jdbc").setMaster("local[*]")
val sc = new SparkContext(conf)
val data: RDD[(String, Int)] = sc.makeRDD(List(
("jack", 18), ("zhaoshuai11", 25), ("xiaoming", 11)
))
/** * CREATE TABLE `test-spark-datasource` ( * `id` int(11) NOT NULL, * `name` varchar(255) NOT NULL, * `age` int(11) NOT NULL * ) ENGINE=InnoDB DEFAULT CHARSET=latin1; */
data.foreachPartition(d => {
// 开启连接
val connection: Connection =
DriverManager.getConnection("jdbc:mysql://localhost:3306/test",
"root", "root")
val sql:String =
"INSERT INTO `test`.`test-spark-datasource` (`id`, `name`, `age`) VALUES (NULL, ?, ?);"
val ps: PreparedStatement = connection.prepareStatement(sql)
d.foreach(t => {
val name = t._1
val age = t._2
ps.setString(1, name)
ps.setInt(2, age)
ps.addBatch()
// ps.executeUpdate()
})
ps.executeBatch()
// 关闭连接
if (null != connection) {
connection.close()
}
if (null != ps) {
ps.close()
}
})
}
}
package com.baidu.sparkcodetest.rdd
import com.baidu.utils.LoggerTrait
import org.apache.spark.rdd.{
JdbcRDD, RDD}
import org.apache.spark.{
SparkConf, SparkContext}
import java.sql.{
Connection, DriverManager, PreparedStatement, ResultSet}
object RDDDemo_jdbc extends LoggerTrait {
def main(args: Array[String]): Unit = {
// 1 准备sc-SparkContext上下文执行环境
val conf = new SparkConf().setAppName("RDDDemo_jdbc").setMaster("local[*]")
val sc = new SparkContext(conf)
val data: RDD[(String, Int)] = sc.makeRDD(List(
("jack", 18), ("zhaoshuai11", 25), ("xiaoming", 11)
))
/** * CREATE TABLE `test-spark-datasource` ( * `id` int(11) NOT NULL, * `name` varchar(255) NOT NULL, * `age` int(11) NOT NULL * ) ENGINE=InnoDB DEFAULT CHARSET=latin1; */
data.foreachPartition(d => {
// 开启连接
val connection: Connection =
DriverManager.getConnection("jdbc:mysql://localhost:3306/test",
"root", "root")
val sql: String =
"INSERT INTO `test`.`test-spark-datasource` (`id`, `name`, `age`) VALUES (NULL, ?, ?);"
val ps: PreparedStatement = connection.prepareStatement(sql)
d.foreach(t => {
val name = t._1
val age = t._2
ps.setString(1, name)
ps.setInt(2, age)
ps.addBatch()
// ps.executeUpdate()
})
ps.executeBatch()
// 关闭连接
if (null != connection) {
connection.close()
}
if (null != ps) {
ps.close()
}
})
// 读取mysql
/** * sc: SparkContext, * getConnection: () => Connection, * sql: String, * lowerBound: Long, // sqlThe lower bound in the statement * upperBound: Long, // sqlThe upper bound in the statement * numPartitions: Int, // 分区 * mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _ // The result set processing function */
val getConnection = () => DriverManager.getConnection("jdbc:mysql://localhost:3306/test",
"root", "root")
val sql =
""" |select id, name, age from `test-spark-datasource` where id >= ? and id <= ? |""".stripMargin
val mapRow = (r: ResultSet) => {
val id = r.getInt("id")
val name = r.getString("name")
val age = r.getInt("age")
(id, name, age)
}
val studentRDD: JdbcRDD[(Int, String, Int)] = new JdbcRDD[(Int, String, Int)](
sc,
getConnection,
sql,
1,
2,
1,
mapRow)
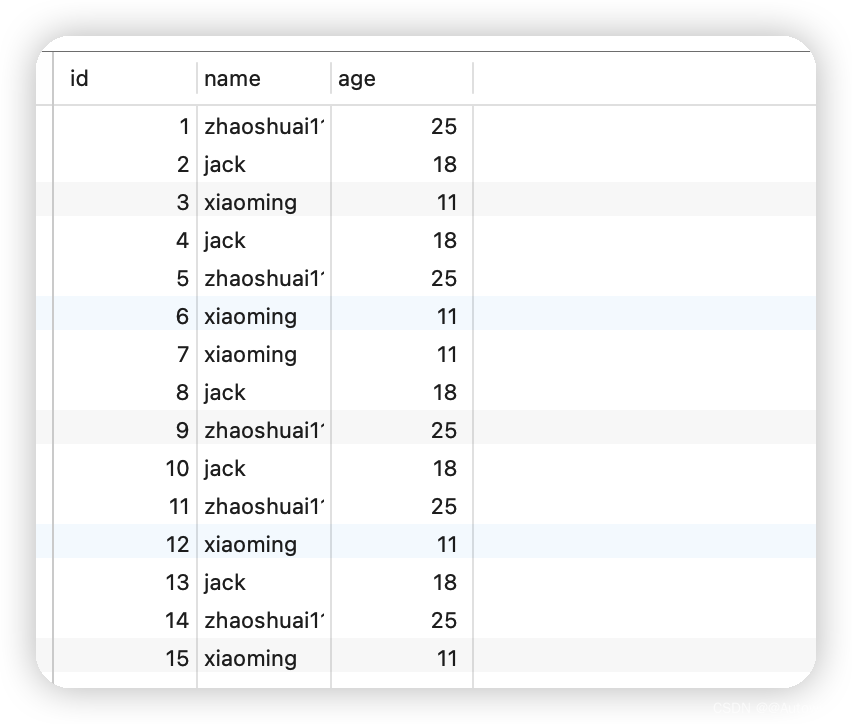
studentRDD.foreach(println)
/** * (1,zhaoshuai11,25) * (2,jack,18) */
}
}
边栏推荐
- How to prevent hacking Windows server security Settings
- 【QT】Qt 给已经开发好的程序快速封装成动态库
- Small Tools(4) 整合Seata1.5.2分布式事务
- 用户侧有什么办法可以自检hologres单表占用内存具体是元数据、计算、缓存的使用情况?
- 如何分析周活跃率?
- 【Unity入门计划】基本概念(6)-精灵渲染器 Sprite Renderer
- 身为售后工程师的我还是觉得软件测试香,转行成功定薪11.5K,特来分享下经验。
- 开源一夏 | 阿里云物联网平台之极速体验
- js中的基础知识点 —— 事件
- ECCV 2022 | 基于关系查询的时序动作检测方法
猜你喜欢
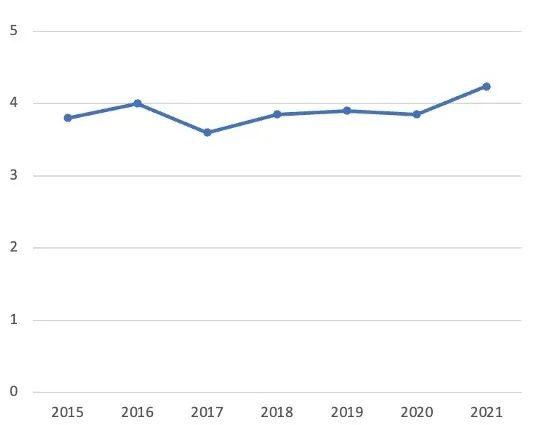
2021年数据泄露成本报告解读

Not to be ignored!Features and advantages of outdoor LED display
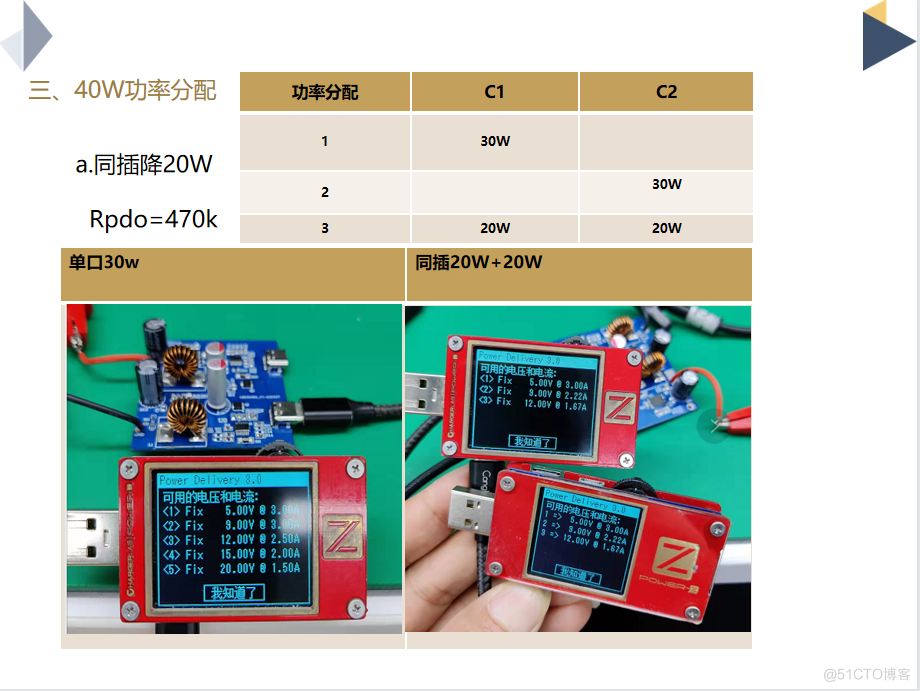
DC-DC 2C(40W/30W) JD6606SX2退功率应用

一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
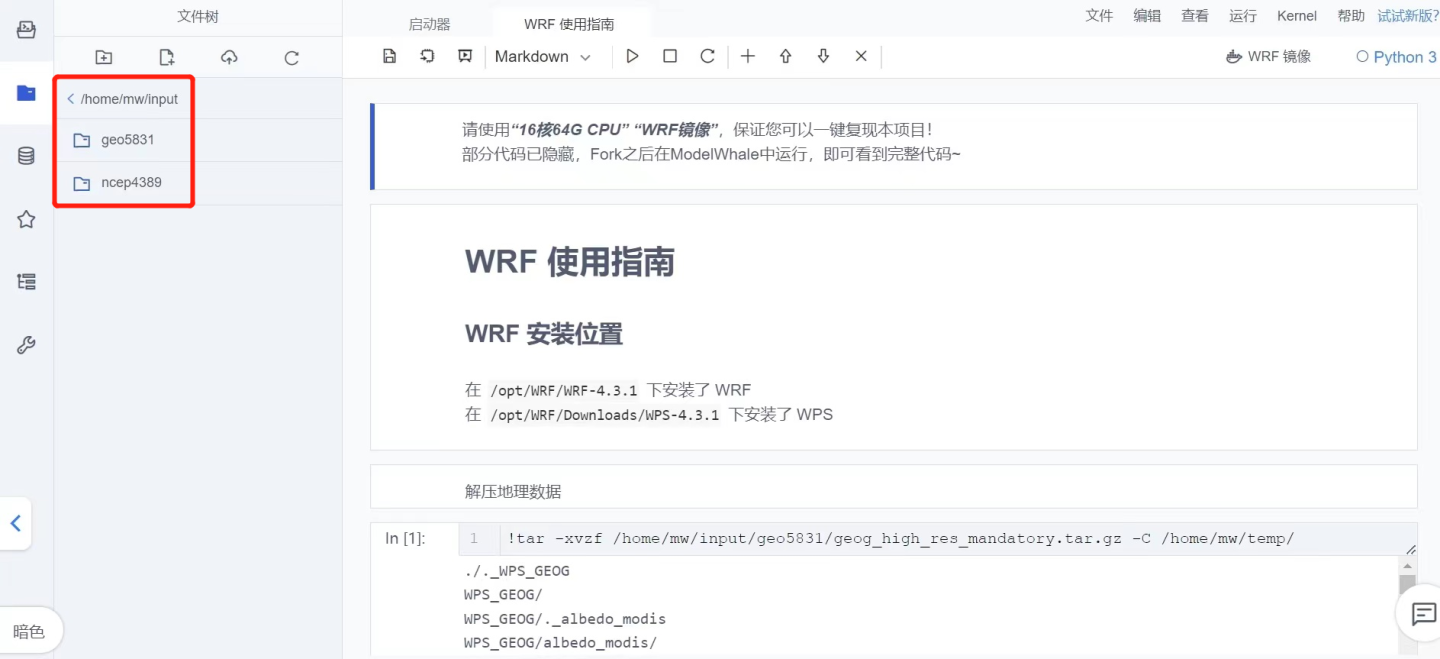
ModelWhale 云端运行 WRF 中尺度数值气象模式,随时随地即开即用的一体化工作流

Yii2安装遇到Loading composer repositories with package information
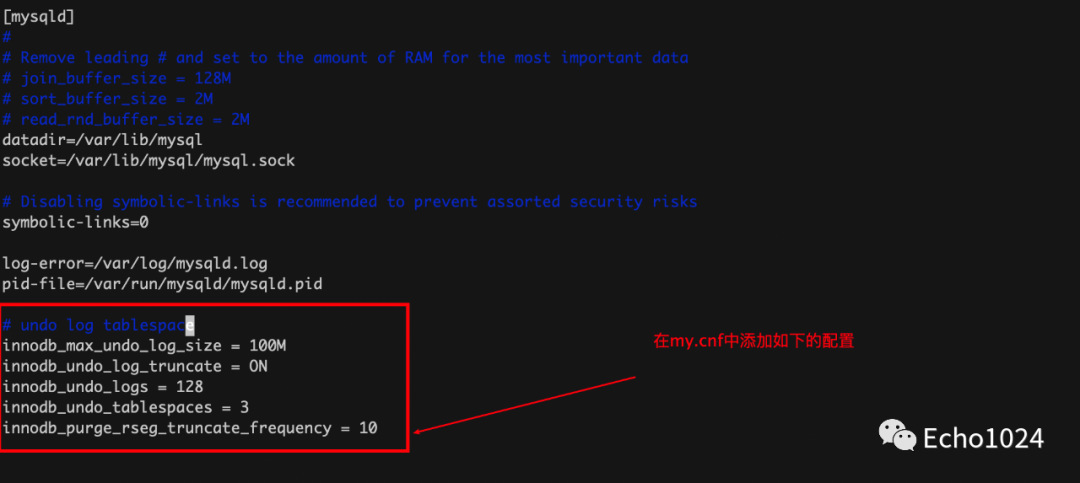
简介undo log、truncate、以及undo log如何帮你回滚事物?
如何启动 NFT 集合
![[微信小程序开发者工具] × #initialize](/img/38/ea90525f53de3933a808f0d75028b0.png)
[微信小程序开发者工具] × #initialize

JD6606SP5_JD6606SSP_JD6606SASP_JD6621W7百盛新纪元授权代理商
随机推荐
opencv 读取和写入路径有汉字的处理方法
聊聊这个SaaS领域爆火的话题
基于DMS的数仓智能运维服务,知多少?
在 360 度绩效评估中应该问的 20 个问题
常见分布式理论(CAP、BASE)和一致性协议(Gosssip、Raft)
6000 字+,帮你搞懂互联网架构演变历程!
出海季,互联网出海锦囊之本地化
leetcode: 899. Ordered Queue [Thinking Question]
16 【过渡 动画】
深度学习——安装CUDA以及CUDNN实现tensorflow的GPU运行
【码蹄集新手村600题】将一个函数定义宏
Ark server opening tutorial win
js中的基础知识点 —— 事件
window.open不显示favicon.icon
Js array method is summarized
生态剧变,电子签名SaaS模式迎来新突破,网络效应加速到来
【数据库数据恢复】SqlServer数据库无法读取的数据恢复案例
LyScript 验证PE程序开启的保护
神经网络,凉了?
With a single operation, I improved the SQL execution efficiency by 10,000,000 times!