当前位置:网站首页>【目标检测】Focal Loss for Dense Object Detection
【目标检测】Focal Loss for Dense Object Detection
2022-08-03 16:30:00 【呆呆的猫】
论文:Focal Loss for Dense Object Detection
代码:https://github.com/facebookresearch/Detectron
出处:原始论文出自 ICCV2017

贡献:
- 发现了单阶段和双阶段目标检测器的效果差距所在,即正负样本不平衡
- 提出了 Focal loss 来解决样本不平衡的问题
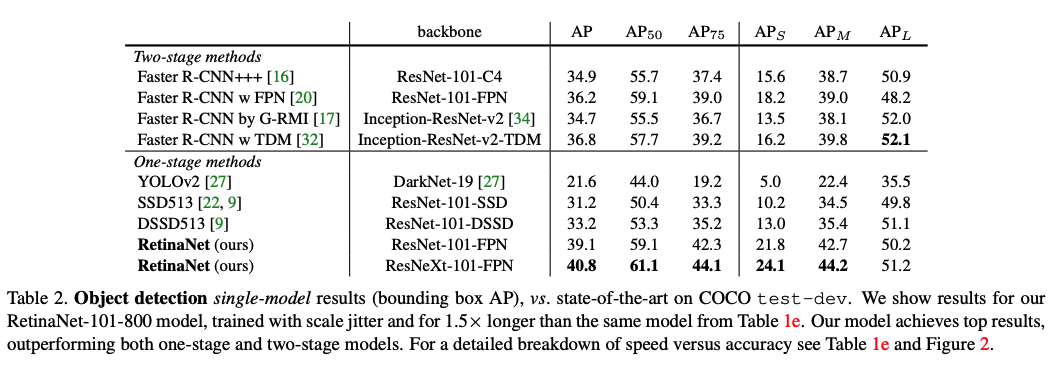
- 在 COCO test 上使用 ResNet-101-FPN 达到了 39.1 AP,5fps,是第一个超越双阶段检测器的单阶段检测器
一、背景
在当时的情况下,两阶段检测器处于统治地位,两阶段检测器是由两部分构成,第一阶段是 RPN 网络,进行候选框的生成,第二阶段输出检测结果。
作者提出了一个问题:单阶段目标检测器能否达到类似的效果?
YOLO、SSD 等方法是属于单阶段目标检测的方法,虽然很快,但效果不尽如意
本文作者就想寻找一个单阶段目标检测器,能够又快又好的解决目标检测任务
作者提出单阶段目标检测器和两阶段目标检测器效果差异的最重要原因:正负样本不平衡
- 两阶段检测器:使用 RPN 网络来生成候选框,大约保留 1-2k,该网络能区分正负样本,保留下更多的正样本,过滤掉大量的背景样本,来保持前景和背景的样本均衡(如 1:3)
- 单阶段检测器:在特征图上均匀的部署很多 anchor,大约 100k 左右,大量的都是负样本
二、方法
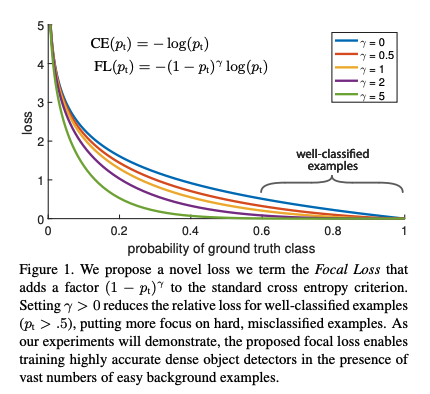
为了解决上述正负样本不平衡问题,作者提出了一个新的 loss 函数——focal loss,来处理样本不平衡问题,曲线如图 1 所示。
2.1 Focal loss
在one-stage检测算法中,目标检测器通常会产生10k数量级的框,但只有极少数是正样本,会导致正负样本数量不平衡以及难易样本数量不平衡的情况,为了解决则以问题提出了focal loss。
Focal Loss是为one-stage的检测器的分类分支服务的,它支持 0 或者 1 这样的离散类别label。
目的是解决样本数量不平衡的情况:
- 正样本loss增加,负样本loss减小
- 难样本loss增加,简单样本loss减小
一般分类时候通常使用交叉熵损失:
C r o s s E n t r o p y ( p , y ) = { − l o g ( p ) , y = 1 − l o g ( 1 − p ) , y = 0 CrossEntropy(p,y)= \begin{cases} -log(p), & y=1 \\ -log(1-p), & y=0 \end{cases} CrossEntropy(p,y)={ −log(p),−log(1−p),y=1y=0
为了解决正负样本数量不平衡的问题,我们经常在二元交叉熵损失前面加一个参数 α \alpha α。负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定 α \alpha α的值来控制正负样本对总的loss的共享权重。 α \alpha α取比较小的值来降低负样本(多的那类样本)的权重。即:
C r o s s E n t r o p y ( p , y ) = { − α l o g ( p ) , y = 1 − ( 1 − α ) l o g ( 1 − p ) , y = 0 CrossEntropy(p,y)= \begin{cases} -\alpha log(p), & y=1 \\ -(1-\alpha) log(1-p), & y=0 \end{cases} CrossEntropy(p,y)={ −αlog(p),−(1−α)log(1−p),y=1y=0
虽然平衡了正负样本的数量,但实际上,目标检测中大量的候选目标都是易分样本。这些样本的损失很低,但是由于数量极不平衡,易分样本的数量相对来讲太多,最终主导了总的损失。
因此,这篇论文认为易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本 。一个简单的想法就是只要我们将高置信度样本的损失降低一些, 也即是下面的公式:
F o c a l l o s s = { − ( 1 − p ) γ l o g ( p ) , y = 1 − p γ l o g ( 1 − p ) , y = 0 Focalloss = \begin{cases} -(1-p)^ \gamma log(p), & y=1 \\ -p^\gamma log(1-p), & y=0 \end{cases} Focalloss={ −(1−p)γlog(p),−pγlog(1−p),y=1y=0
当 γ = 0 \gamma=0 γ=0 时,即为交叉熵损失函数,当其增加时,调整因子的影响也在增加,实验发现为2时效果最优。
假设取 γ = 2 \gamma=2 γ=2,如果某个目标置信得分p=0.9,即该样本学的非常好,那么这个样本的权重为 ( 1 − 0.9 ) 2 = 0.001 (1-0.9)^2=0.001 (1−0.9)2=0.001,损失贡献降低了1000倍。
为了同时平衡正负样本问题,Focal loss还结合了加权的交叉熵loss,所以两者结合后得到了最终的Focal loss:
F o c a l l o s s = { − α ( 1 − p ) γ l o g ( p ) , y = 1 − ( 1 − α ) p γ l o g ( 1 − p ) , y = 0 Focal loss = \begin{cases} -\alpha (1-p)^\gamma log(p), & y=1 \\ -(1-\alpha) p^\gamma log(1-p), & y=0 \end{cases} Focalloss={ −α(1−p)γlog(p),−(1−α)pγlog(1−p),y=1y=0
取 α = 0.25 \alpha=0.25 α=0.25 在文中,即正样本要比负样本占比小,这是因为负样本易分。
单单考虑alpha的话,alpha=0.75时是最优的。但是将gamma考虑进来后,因为已经降低了简单负样本的权重,gamma越大,越小的alpha结果越好。最后取的是alpha=0.25,gamma=2.0
2.2 RetinaNet 网络结构
RetinaNet 是一个由 backbone + subnetworks 构成的统一的网络结构,如图 3 所示,backbone 后面跟了一个 neck 网络 FPN,然后后面跟了两个并行子网络,分别用于分类和回归。
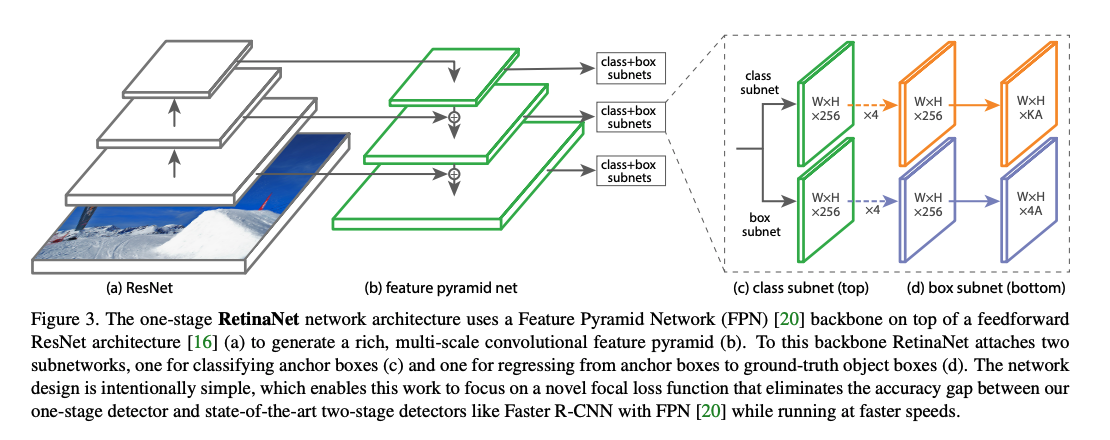
1、FPN 网络
如图 3 b,作者在 ResNet 结构的后面增加了 FPN 结构,每个 level 用于检测不同尺度的目标。
2、Anchors
从 P3 到 P7,anchor 的大小也从 3 2 2 32^2 322 到 51 2 2 512^2 5122,在每个 level 使用三种纵横比 1 : 2 , 1 : 1 , 2 : 1 {1:2, 1:1, 2:1} 1:2,1:1,2:1,大小为 2 0 , 2 1 3 , 2 2 3 {2^0, 2^{\frac{1}{3}}, 2^{\frac{2}{3}}} 20,231,232,每个 level 共 9 种 anchor,可以覆盖像素范围是 23~813。
每个 anchor 分配一个长度为 K 的 one-hot 编码特征存储类别信息,一个 4D 向量存储回归特征。
anchor 是如何寻找自己对应的真值框呢?
如果某个 anchor 和某个真值框的 IoU>0.5,则将其分配给对应的真值框进行学习,IoU 为 [0, 0.4] 的 anchor 被分配给背景,其他 anchor 被定义为 ignore。
3、分类子网络
分类子网络在每个空间位置分别预测这 A 个 anchor 对应的 K 个类别。
在 FPN 的每一层上,都接一个分类子网络,且是参数共享的小型 FCN 网络,输入 C 通道特征,使用 4 个 3x3 conv 提取特征,1 个 3x3 conv ,通过 sigmoid 后,输出 KA 个二值结果,如图 3c。
4、回归子网络
对于每个位置上的 A 个 anchor,输出 4 个偏移。
三、效果
边栏推荐
- 最强分布式锁工具:Redisson
- Excuse me this hologres dimension table is cached?How to Finished
- MySQL窗口函数 PARTITION BY()函数介绍
- 如何使用MATLAB绘制极坐标堆叠柱状图
- 生产环境如何删除表呢?只能在SQL脚本里执行 drop table 吗
- leetcode SVM
- 《社会企业开展应聘文职人员培训规范》团体标准在新华书店上架
- 【带你了解SDN和网络虚拟化】
- Detailed explanation of ReentrantReadWriteLock
- To participate in sweepstakes, incoming new programmers magazine welfare!
猜你喜欢

黄致绮 荣获第六季完美童模全球总决赛 全国总冠军

Yuan xiaolin: Volvo focus on travel security, and put it perfectly
从零开始搭建MySQL主从复制架构
Understand the recommendation system in one article: Outline 02: The link of the recommendation system, from recalling rough sorting, to fine sorting, to rearranging, and finally showing the recommend
SQL中对 datetime 类型操作
高效的组织信息共享知识库是一种宝贵的资源
To add digital wings to education, NetEase Yunxin released the overall solution of "Internet + Education"
TiKV & TiFlash accelerate complex business queries丨TiFlash application practice
使用uniapp 封装一个request 请求

leetcode-693.交替位二进制数
随机推荐
Big guys.Use flink-cdc-sqlserver version 2.2.0 to read sqlserver2008R
黄致绮 荣获第六季完美童模全球总决赛 全国总冠军
TiKV & TiFlash accelerate complex business queries丨TiFlash application practice
超分重建数据集
leetcode:189. 轮转数组
虹科分享 | 如何测试与验证复杂的FPGA设计(3)——硬件测试
Kubernetes 笔记 / 目录
中小微企业如何简单便捷、低成本实现数字化?360视觉云有妙招
leetcode:202. 快乐数
B站回应HR称核心用户是Loser;微博回应宕机原因;Go 1.19 正式发布|极客头条
DataGrip数据仓库工具
Hannah荣获第六季完美童模全球总决赛全球人气总冠军
How to analyze the weekly activity rate?
甲方不让用开源【监控软件】?大不了我自己写一个
设置海思芯片MMZ内存、OS内存详解
纯纯粹粹纯纯粹粹
【There is no tracking information for the current branch. Please specify which branch you want to 】
C专家编程 第3章 分析C语言的声明 3.7 typedef struct foo{... foo;}的含义
【翻译】关于扩容一个百万级别用户系统的六个课程
Looking at the ecological potential of Hongmeng OS from the evolution of MatePad Pro