当前位置:网站首页>Efk Upgrade to clickhouse log Storage Reality
Efk Upgrade to clickhouse log Storage Reality
2022-06-26 06:10:00 【Impl Sunny.】
0、Contexte
Vipshop Logging Systemdragonfly 1.0Est basé surEFKConstruire,À2014Jusqu'à présent7Année,Prise en charge de la collecte physique des journaux de machine,Collecte des journaux de conteneurs,Collecte complète de journaux de classification spéciaux, etc.,Facilite grandement le stockage et l'interrogation des journaux de l'ensemble de l'entreprise.
Au fur et à mesure que l'entreprise se développe,Les scénarios d'application de journaux rencontrent progressivement des goulets d'étranglement,Principalement en raison du nombre croissant d'applications et de journaux imprimés,Le développement nécessite l'impression de journaux supplémentaires,Localiser les problèmes commerciaux,Effectuer une analyse des données opérationnelles;Autres problèmes d'attaque externe et exigences en matière de vérification,Plus de données de log liées à la sécurité sont nécessaires pour la Déclaration et peuvent fournir plus de six mois de stockage,Enquêter sur les causes et les zones touchées en cas d'attaque potentielle et d'attaque.ELKLes défauts de l'architecture,ESTaille de la grappe260Machines,Matériel et entretien nécessaires jusqu'à 10 millions de dollars,Si les scénarios d'affaires ci - dessus sont satisfaits par l'expansion de la capacité,ESLes grappes seront trop grandes et instables.,Créer un Cluster autonome,Des coûts plus élevés sont également nécessaires,Les deux peuvent entraîner une augmentation des coûts et de la charge de travail d'entretien..
Un.、Évolution du système de journalisation
1.1 Format de journal standard

Spécification format standard du Journal,Il est utile d'identifier correctement les éléments clés du Journal,Pour répondre à la requête,Exigences en matière de calcul des alarmes et des agrégats.à partir du Journal de format ci - dessus,AdoptionfilebeatLe résultat de la conversion est le suivant::
Horodatage,Niveau du Journal,Nom du fil,Nom de la classe,eventName, Et les champs personnalisés seront recueillis par le journal Agent Après analyse et autres métadonnées telles que les noms de domaine , Nom du conteneur ou de l'hôte avec JSONPrésentation.
Les champs personnalisés sont imprimés par le développeur dans le journal en fonction des besoins de l'entreprise , Principales fonctions de soutien :
① Divers scénarios d'analyse agrégée sont pris en charge lors de la requête
② Alarme de fonction agrégée basée sur un champ personnalisé
1.2 ES Problèmes de stockage
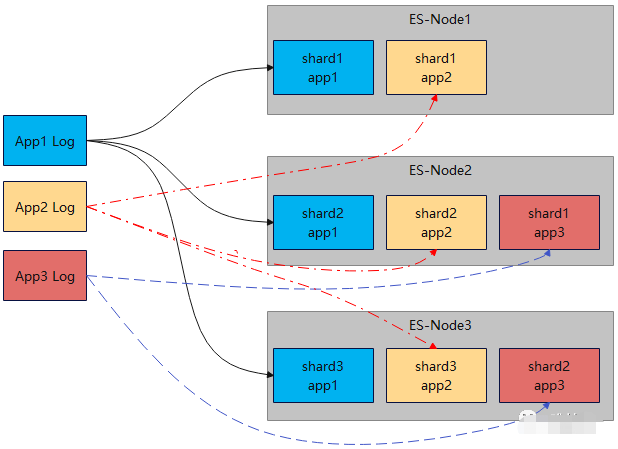
EFKLes journaux sont stockés danselasticsearch, Les journaux de chaque domaine ont une granularité de jour de ESCréer un index, La taille de l'index est calculée à partir de la taille des données des jours précédents , La taille de chaque tranche d'index ne doit pas dépasser 30G, Plus la quantité de log est grande, plus le domaine est fragmenté . Si la quantité de journaux écrits dans un domaine est trop grande ou trop longue ,Sera occupéES Un grand nombre de noeuds CPU Pour l'analyse et segmentFusionner, Cela affecte l'écriture normale d'autres journaux de domaine , Provoque une baisse globale du débit d'écriture . .Il est souvent difficile de trouver quel domaine a un log fragmenté trop grand , .Il faut souvent beaucoup de temps pour faire face à ce genre de problème brûlant .
ESLa version utilise5.5, La suppression automatique des index et la migration à chaud et à froid ne sont pas encore prises en charge , Plusieurs scripts sont programmés quotidiennement , Terminer la suppression de l'index ,Fermer l'index, Déplacer l'index froid , Tâche de créer un nouvel index , Le déplacement de l'index et la création d'un nouvel index sont des opérations très longues . Tout le cycle de vie est exécuté quotidiennement , Si une étape échoue soudainement un jour , Ou le temps d'exécution est trop long , Cela peut entraîner un allongement du cycle de vie complet ou même l'incapacité de terminer , L'écriture de nouvelles données le lendemain sera sérieusement affectée , Impossible d'écrire .
En plusES L'Index inversé de doit segmenter le journal , Le fichier index qui en résulte est plus grand , Prend beaucoup d'espace disque .
MaisESIl a aussi ses avantages, Les caractéristiques basées sur l'Index inversé font que ESLors de la requête,1 Un seul noyau est nécessaire pour compléter la requête , Parce que les requêtes sont généralement plus rapides ,QPSPlus élevé.
C'est à grande échelle ( Ou en masse ) Dans le scénario de stockage des journaux ES Principaux avantages et inconvénients du stockage :

1.3 Système de journalisation2.0Programme
2019 On a essayé un autre HDFSSolutions de stockage, Mettez les données de chaque domaine par nom de domaine +toYYDDMMHH(timestamp)+host Cache comme clé dans le client , Quand la taille ou l'expiration est arrivée ,Soumis àHDFS Générer un fichier séparé , Le chemin de stockage contient le domaine , Informations sur l'hôte et le temps , La recherche peut être filtrée à partir de ces étiquettes , Ce stockage est un peu similaire loki,Ses inconvénients sont évidents, L'avantage est que le débit et le taux de compression sont très élevés , Peut résoudre nos problèmes de débit et de compressibilité insuffisants .
Si les améliorations se poursuivent sur la base de ce scénario , Si vous ajoutez une étiquette , Simple index de sauts ,Fonction de requête, Requêtes simultanées Multi - noeuds , Stockage Multi - Champs , La charge de travail et la difficulté du développement sont énormes . Nous avons comparé plusieurs solutions de stockage utilisées à l'avant - garde de l'industrie ,Finalement choisiclickhouse, Son système d'écriture par lots et de stockage en colonne répond entièrement à nos exigences (Basé surHDFSStockage), Des index de clés primaires et des index de sauts sont également disponibles avec un très petit espace disque ,Comparé àESIndex texte complet de,Les avantages sont évidents.
Presque26G Les journaux d'application sont utilisés séparément pour clickhouseDelz4,zstdEtESDelz4Comparaison des algorithmes de compression

Dans l'environnement de production réelzstd Le rapport de compression des journaux est plus élevé pour , Ceci est lié à la similitude du Journal d'application ,Jusqu'à15.8.

Clickhouse Le taux de compression est si élevé , Mais pas d'index , Quelle est sa vitesse de requête ? Bien qu'il n'y ait pas d'index , Mais son vecteur exécute et SIMD Avec plusieurs noyaux CPU, Les inconvénients de l'absence d'index plein texte peuvent être grandement atténués . Après de nombreuses comparaisons d'essais , Sa vitesse de requête est dans la plupart des scénarios et ESC'est pareil, Dans certains scénarios, c'est encore plus ESPlus vite..
Le graphique ci - dessous montre les données réelles de fonctionnement de milliers d'applications dans un environnement de production réel ,Requête24 Journal de bord et 24 Comparaison du temps consacré à l'enregistrement des plages de temps supérieures à l'heure

Grâce à l'analyse des scénarios d'application du Journal , Nous avons trouvé des billions de niveaux de journaux , Le nombre réel de journaux qui peuvent être interrogés est très, très faible ,Cela signifieES Index de segmentation de tous les journaux , La plupart sont inefficaces , Plus il y a de journaux , Ce participant consomme plus de ressources .ComparaisonclickhouseDeMergeTree Le moteur est beaucoup plus spécialisé , La principale consommation de ressources est la compression et le stockage du tri des journaux .
En plusClickhouseDeMPP L'architecture rend le cluster très stable , Peu de travail O & M . Voici une comparaison complète d'une image ESEtClickhouseAvantages et inconvénients, Expliquez pourquoi nous avons choisi de clickhouse En tant que base de données de stockage de journaux de prochaine génération .

2.、Détails techniques
EFK L'architecture s'est développée au fil des ans et le système a beaucoup mûri ,ES Les paramètres par défaut et l'Index inversé vous permettent de ne pas avoir besoin de ES Facile à utiliser avec trop de connaissances ,Open Sourcekibana Offre également une riche interface de requête et des panneaux graphiques , Pour un scénario avec peu de log ,EFK L'architecture reste le premier choix .
ClickhouseCes dernières années.OLAP Les bases de données les plus populaires dans le domaine , Sa maturité et son écologie se développent encore rapidement , Il n'y a pas beaucoup de solutions open source pour stocker les journaux , Pour bien l'utiliser, il faut non seulement avoir raison ClickhouseAvoir une compréhension approfondie, Il reste encore beaucoup à faire .

2.1 Journal de bord -vfilebeat
Au débutdragonflyUtiliserlogstash Pour la collecte de journaux ,Mais...logstash La configuration est complexe et ne supporte pas la distribution de profils , Pas pratique pour la collecte de journaux dans un environnement conteneur , Un autre a utilisé GO Outils de collecte pour le développement linguistique vfilebeat Meilleure performance et extensibilité , Sur cette base, nous avons personnalisé et développé notre propre composant de collecte de journaux vfilebeat.
vfilebeatFonctionne sur l'hôte hôte, Au démarrage, vous pouvez spécifier le domaine auquel appartient le journal hôte collecté par paramètre ,Si ce n'est pas spécifié, Lors de la lecture de l'installation CMDB Nom de domaine et nom d'hôte du profil , Chaque journal collecté par l'hôte hôte hôte est étiqueté avec un nom de domaine et un nom d'hôte .
Dans l'environnement du conteneurvfilebeat La création et la destruction de conteneurs sont également surveillées , Lorsque le conteneur est créé , Lire le conteneur POD Informations sur le nom de domaine et le nom d'hôte ,Et deETCD Paramètres de configuration tels que le chemin de collecte des journaux vers le domaine , Par nom de domaine et POD Chemin de collecte des fichiers journaux pour le répertoire auquel appartient le conteneur de génération de noms , Et générer un nouveau profil localement ,vfilebeatRecharger le profil, Vous pouvez faire défiler la collection .
Aujourd'hui, la plupart des applications de notre environnement utilisent vfilebeatAcquisition, Quelques scènes réservées logstashAcquisition.vfilebeat Joindre les journaux recueillis à des étiquettes telles que l'environnement de l'application et du système , Sérialisation des formats de données configurés ,Rapport àkafkaCluster, Le journal d'application est JSON,Accesslog Pour les lignes de texte .
2.2 Résolution des journaux-flink writer
Acquiskafka Le journal de bord sera flink writer La tâche est consommée avant d'être écrite à clickhouseCluster.

writerDekafka Les données sur la consommation sont d'abord converties en données structurées ,vfilebeat Certaines données plus anciennes peuvent être déclarées lors de la Déclaration , Trop de données , Ça ne veut pas dire grand - chose , Et il en résulte plus de petits part,Consommationclickhosue cpuRessources, Cette étape élimine ces dates d'expiration de plus de trois jours , Les données qui ne peuvent pas être résolues ou les journaux qui manquent de champs obligatoires sont également perdus . Les données filtrées par analyse sont ensuite converties en étapes ,Convertir enclickhouse Champs et types de tableaux pour .
Opération de conversion de schemaEtmetadata Le tableau lit les méta - informations stockées dans le journal de domaine ,schemaDéfiniclickhouse Noms des tables locales et mondiales ,Pendant la session, Et la cartographie par défaut des champs log et table .metadata Définit l'utilisation spécifique du Journal de domaine schemaInformation, Durée du stockage des journaux , Valeur du champ de partition de domaine , Champ personnalisé champ de table auquel le champ personnalisé est mappé , Grâce à ces informations de configuration au niveau du domaine , Nous pouvons spécifier les tables stockées dans le domaine , Durée de stockage , Super Big log Domain Independent partition Storage , Réduire la fusion des journaux CPUConsommation.
Les champs personnalisés sont stockés par tableau par défaut , Certains champs impriment plus de champs de journaux personnalisés , Avec une grande quantité de journaux ,Plus lent, Le stockage physique des champs de cartographie personnalisés est configuré , Peut fournir une vitesse de requête et un taux de compression plus rapides que le tableau .
clickhouseTableauschemaInformation

Domaine personnaliser les métadonnées de stockage

Données converties , Avec stockage à CK Toutes les informations requises pour le tableau , Stocker temporairement dans une file d'attente locale , Les files d'attente locales peuvent avoir des journaux mixtes de plusieurs domaines et tables , Après avoir atteint la longueur ou le temps spécifié , Soumis à nouveau dans une file d'attente globale au niveau du processus .
Parce quewriter Le processus est multithreadé consomme plusieurs kafkaPartition, La file d'attente globale regroupe les données de plusieurs Threads d'une même table , Faire en sorte qu'un seul lot soumis soit plus grand , Global thread Short buffer , Quand le nombre d'écritures est atteint , Après la taille ou le délai , Les données seront écrites comme une seule fois ,Soumis àsubmit workerThread.submit workerResponsable de l'écriture des données,Haute disponibilité,Équilibrage de la charge, Logique de tolérance aux pannes et de retry .
submit Dès réception des données de lot soumises , Recherche aléatoire d'un clickhosueFractionnement, Commit write to Split Node .clickhouse La configuration du cluster est double , Quand un noeud de réplique échoue , Écrivez une tentative de basculer sur un autre noeud , Si les deux échouent , Alors retirez temporairement les tranches , Recherchons un fragment sain pour écrire .
Écrire des données àClickhouseNous utilisonsclickhouse-jdbc, Consommation de mémoire et CPUTous plus grands.,C'est exact.jdbc Après analyse du code source ,Nous avons découvertjdbcLors de l'écriture des données, Convertissez d'abord toutes les données en un ListObjet,C'estlist Objet équivalent à byte[] Format de copie , Pour réduire cette occupation , Nous optimisons les étapes de conversion des données , Chaque donnée de journal est convertie directement en jdbcPeut être utilisé directementListDonnées,Voilà.jdbc Dans la construction SQLQuand, Les données obtenues sont en fait ListUne citation de, Cette optimisation réduit la consommation de mémoire d'environ un tiers .
En plus, oui.writer Lors de l'analyse du diagramme de flamme ,Nous avons découvertjdbcEn générantSQLHeure, Chaque caractère des données soumises sera jugé , Reconnaître des caractères spéciaux tels que '\', '\n', '\b' Attendez de vous échapper , Cette opération d'évasion utilise mapFonctions, Quand les données sont volumineuses , Ça a coûté environ 17%DeCPU, On a optimisé ça ,UtiliserswtichAprès, Réduction significative de la mémoire ,Économisez.13%DeCPUConsommation.
clickhouse Le concept de Cluster faible de garantit que lorsqu'un seul noeud tombe , L'ensemble de la grappe est à peine touché ,submit La haute disponibilité garantit que lorsque le noeud est anormal , Les données peuvent encore être écrites normalement au noeud santé , .Cela rend l'écriture du Journal entier très stable , Il n'y a pratiquement pas de latence due aux temps d'arrêt des noeuds .
À propos de log ingestion ClickhouseDe la façon dont, Le graphite est une source ouverte d'un autre type d'ingestion ,CréationKafkaEngine Tableau consommation directe clickhouse, Importer les données dans la vue matérialisée , Importation finale dans la table locale via la vue matérialisée . L'avantage de cette approche est d'économiser writerComposants de,Rapport àkafka Les données peuvent être stockées directement dans clickhouse, Mais il y a beaucoup de défauts :
Chaquetopic Vous devez créer un KafkaEngine, Si vous devez changer de table ,Ajoutertopic,Tout change.DDL, Et ne supporte pas un topic Différents champs sont stockés dans différentes tables
Analyse supplémentaire kafka Les données et les vues matérialisées consomment des noeuds CPURessources,Etclickhouse Les fusions et les requêtes sont très dépendantes cpuFonctionnement de la ressource, Ça va empirer clickhouseCharge,Ce qui limiteclickhosue Déglutition globale , Affecte la performance de la requête , Besoin d'agrandir plus de noeuds pour atténuer ce problème ,clickhouse Un seul serveur pour ,SSD Et un grand stockage de disques , Le coût de l'expansion est donc élevé .
La résolution write Component est sélectionnée indépendamment , Peut résoudre beaucoup des problèmes mentionnés ci - dessus , Il offre également une grande flexibilité pour de nombreuses extensions ultérieures ,Beaucoup d'avantages,Ne les énumérez plus..
2.3 Stockage-Clickhouse
2.3.1 Écrire à haut débit
Soumis àClickhouse Les données sont stockées sous forme de tableaux bidimensionnels , Table bidimensionnelle nous utilisons ClickhouseLe plus souvent utiliséMergeTreeMoteur,À propos deMergeTree Pour une description plus détaillée, voir cet article en ligne 《MergeTreeStructure de stockage pour》.
https://developer.aliyun.com/article/761931spm=a2c6h.12873639.0.0.2ab34011q7pMZK
Schéma de stockage logique des données sur disque

MergeTreeAdopter une approche similaireLSM-TreeStockage de la structure des données, Données par lot soumises , Appuyez sur la touche partition de la table ,Enregistrer séparément dans unpartDans la table des matières,Unpart Après avoir trié les données de ligne dans la clé de tri , Ensuite, Compressez et stockez - les dans différents fichiers par colonne ,Clickhouse Les tâches d'arrière - plan se poursuivront sur chacune de ces petites partFusionner,Générer un plus grandpart.
MergeTreeBien que non.ESIndex inversé de, Mais il y a des touches de partition plus légères , Index des clés primaires et des sauts .
Les touches de partition permettent de filtrer rapidement beaucoup de part, Par exemple, lors d'une recherche dans le temps , Ne touche que la plage de temps part.
L'index de la clé primaire diffère de la clé primaire de la base de données relationnelle , Est un index léger utilisé pour trouver rapidement des blocs de données triés .
L'index Hop indexe la valeur du champ en fonction du type d'index ,Par exempleminmax L'index indique les valeurs maximales et minimales des champs ,set Une valeur unique du champ est stockée pour l'indexation ,tokenbf_v1 Les champs sont divisés ,CréationbloomfilterIndex, Lors de l'interrogation, vous pouvez calculer si le journal se trouve dans le bloc de données correspondant en fonction des mots clés .
Unpart Les données sont triées par la clé de tri , Ensuite, découpez - les en petits morceaux par taille (index_granularity), Par défaut, les blocs ont 8192D'accord, En même temps, l'index de la clé primaire indexe les limites de chaque bloc , L'index Hop génère un fichier index basé sur les champs de l'index , En général, les fichiers d'index générés par les trois sont très petits , Cache les requêtes accélérées en mémoire .
Compris.MergeTreePrincipe de réalisation,On peut trouver,ImpactClickhouse Un élément clé de l'écriture est partNombre de, Chaque écriture produit un part,partPlus, Plus la tâche de fusion de fond sera occupée . En plus de ce facteur ,part La production et la fusion de CPUEt le disqueIO.
Alors résumez, Trois facteurs influencent l'écriture :
①partNombre - Moins.
②CPUNombre de noyaux - Beaucoup.
③DisqueIO - Élevé
Pour améliorer le débit d'écriture , Il faut commencer par ces trois facteurs ,RéductionpartNombre,AméliorationCPUNombre de noyaux,Augmenter le disqueIO

Classer les méthodes du diagramme en fonction des moyens de mise en oeuvre
- Matériel:CPU Plus il y a de noyaux, mieux c'est , Notre environnement de production 40+,DisqueSSDC'est standard.,Parce queSSD Prix élevé petite capacité ,AdoptionSSD+HDD Mode de séparation à chaud et à froid
- Structure du tableau: Utilisation de domaines longs et volumineux bloomfilterRequête d'accélération de l'index, D'autres champs utilisent l'index Hop normal , Nous testons l'observation pour économiser près de la moitié de CPU.
- Écrire des données:WriterDonnées soumises, Soumettre par lots selon la clé de partition , Ou certains champs de partition peuvent être , C'est - à - dire que la base de la clé de partition pour une seule soumission est aussi petite que possible , Idéalement 1, Cette méthode permet de réduire considérablement les partNombre. Sélection de la clé de partition , La clé de partition autonome peut être sélectionnée en fonction du nombre de journaux d'application , Stockage de grands champs de log , Les grandes applications de journalisation atteignent généralement le seuil de nombre d'entrées soumises , Peut faire fusionner part Tout est grand part,Efficacité élevée; Ou mélanger les touches de partition , Mélange de petites applications en une seule partition .
2.3.2 Requête haute vitesse
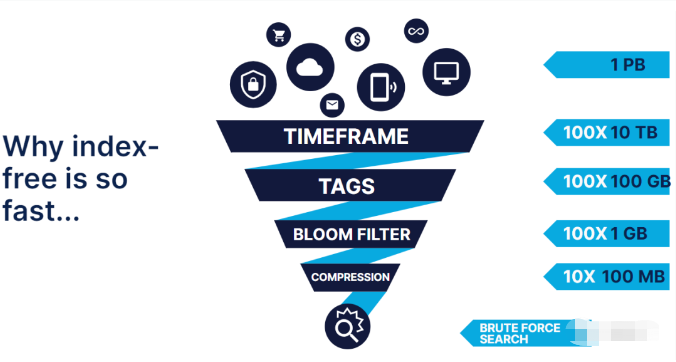
1PBStockage de données pour, Sans index plein texte , La violence directe récupère un mot clé ,Ça doit être un délai., Si le temps passe avant ,Étiquettes etbloomfilter Après filtrage , Encore une recherche violente , La quantité de données à récupérer sera beaucoup plus petite .
MergeTree Le moteur est un stockage en colonne ,Le taux de compression est élevé, Un taux de compression élevé offre de nombreux avantages , La quantité de données lues à partir du disque est faible , Le cache de page nécessite moins de mémoire , Plus de fichiers peuvent être mis en cache dans la mémoire cache ,ClickhouseOui etHumio La même direction d'exécution quantitative et SIMD,Au moment de la requête, Les blocs de données compressés dans ces mémoires seront CPUExécution par lotsSIMDDirectives, Parce que le bloc est assez petit , Habituellement avant compression 1M, De cette façon, le vecteur de fonction exécute et SIMD Les données calculées sont suffisantes pour placer toutes les données dans cpuDans le cache, Non seulement réduit le nombre d'appels de fonctions ,Etcpu cacheDemissLe taux a considérablement diminué. Il n'y a pas d'exécution vectorielle et SIMD Plusieurs fois plus haut .

2.4 Appliquer le Journal des dimensions TTL
Au début, nous avions prévu d'utiliser TTLPour gérer les journaux, Mettre des journaux de différentes durées de stockage dans différentes tables , Mais il en résulte beaucoup de tables et de vues matérialisées ,Pas facile à gérer, Un programme d'amélioration a ensuite été utilisé ,Oui.TTL Dans le champ partition de table , Développer une tâche simple et chronométrée , Numériser tous les jours pour supprimer tout ce qui dépasse TTLDatepart, Cela permet de supporter une table différente TTL Log Store for ,Très flexible, L'application peut facilement voir et ajuster la durée de stockage à travers l'interface .
2.5 Schéma de stockage de champ personnalisé
Les noms de champs personnalisés dans le journal de format standard sont produits par l'entreprise , La base est incertaine , Notre premier scénario était de créer des centaines de chaînes , Champs étendus pour les entiers et les points flottants , Configurer cette carte personnalisée par le développeur lui - même , Il a ensuite été constaté que le programme présentait de graves lacunes :
① Le développement exige que chaque champ du journal soit configuré manuellement pour être cartographié , Au fur et à mesure que le journal change , De plus en plus de ces champs , Avec l'expansion de la quantité, il sera difficile de maintenir ,
②Clickhouse Vous devez créer un grand nombre de colonnes pour enregistrer ces champs , Parce que toutes les applications sont stockées ensemble ,Pour la plupart des applications, Trop de colonnes ne sont pas seulement gaspillées , Et réduit la vitesse de stockage , Prend beaucoup de systèmes de fichiers INODESection
Plus tard, il s'est inspiré de Uber Scénario de stockage des journaux , Champs pour chaque type de données , Créer deux tableaux chacun , Un nom de champ enregistré , Une autre valeur de champ enregistrée , Les noms et les valeurs correspondent un par un dans l'ordre ,Lors de la requête,Utiliserclickhouse Fonction de recherche de tableau pour récupérer les champs , Cette utilisation prend en charge tous les ClickhouseCalcul de la fonction.
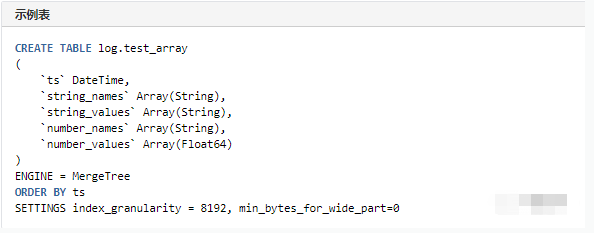
[type]_namesEt[type]_values Stocke séparément le nom et la valeur du champ de type de données correspondant
Insérer:

Multicouches imbriquéesjson Les champs seront nivelés pour le stockage ,Par exemple{"json": {"name": "tom"}}Convertir en json_name="tom"Champ
Le stockage des tableaux n'est plus pris en charge , La valeur du champ Array sera convertie en stockage de chaînes ,Par exemple:{"json": [{"name": "tom", "age": 18}]},Convertir enjson="[{\"name\": \"tom\", \"age\": 18}]"
Requête:

Les champs personnalisés cartographiés d'origine sont toujours conservés 10- Oui.,Si ce n'est pas assez,Peut être ajouté à tout moment, Vous pouvez prendre en charge des champs personnalisés fixes pour certains champs , Ou un type particulier de journal , Par exemple, le journal de vérification ,Journal du système, etc., Ces champs permettent à l'utilisateur d'utiliser le nom original au moment de la requête ,Accès àClickhouse Est remplacé par le nom du champ de tableau
Un autre scénario pour les champs personnalisés est stocké dans mapIntérieur, Deux champs peuvent être sauvegardés , Les requêtes sont aussi plus simples , Mais après nos tests , La performance de la requête n'est pas aussi bonne que le tableau :
① Rapport de compression du stockage des tableaux MapUn peu mieux.
② Rapport de vitesse de requête du tableau MapAllez1.7Plus de deux fois
③Map La syntaxe de requête est plus simple que le tableau , Dans le cas où la syntaxe de requête du tableau est simplifiée à l'avant , Cet avantage est négligeable
Trois、 Système de recherche de journaux frontaux
La première édition du système log est basée sur kibanaDéveloppé par,Version plus ancienne.2.0 Système nous abandonnons directement l'ancienne version , J'ai mis au point un système d'interrogation . La nouvelle requête analyse automatiquement les déclarations de requête saisies par l'utilisateur , Ajouter le nom de domaine de l'application et la plage de temps pour la requête ci - dessus, etc ,Réduire la difficulté de fonctionnement de l'utilisateur, Prise en charge de l'isolement multilocataires .
La recherche de champs personnalisés est très fastidieuse , Nous avons également fait une opération simplifiée :
string_values[indexOf(string_names, 'name')] Réduit à:str.name
number_values[indexOf(number_names, 'height')] Réduit à:num.height
Clickhouse Exécuter une déclaration à la fois , Histogramme et TOP L'exemple de journal est deux déclarations , Double la plage de temps de la requête , Voir la méthode d'optimisation du Ctrip , Pour plus de détails , Selon les résultats de l'histogramme , Réduire le délai à TOP L'intervalle de temps dans lequel se trouve l'enregistrement .
3.1 Enrichir l'utilisation de la requête
Clickhouse Riche syntaxe de requête , La fonction d'analyse des requêtes de notre nouveau système de journalisation est très puissante , Extraire les mots clés des journaux de masse ,Très facile., Voici deux exemples d'utilisation de la requête :
① Du texte et JSON Extraction à partir de données de journaux mixtes JSONChamp

② Calculer les quantiles à partir du Journal

Quatre、Utiliser correctement la posture
1、 Ne pas imprimer le journal trop longtemps ,Pas plus de10K
2、 Les critères de requête sont marqués avec un index Hop , Ou d'autres champs qui ne sont pas des détails de journal , Plus le nombre de journaux de rappel est faible ,Plus la requête est rapide
Cinq、Résumé
Le cas décrit le stockage du système de journalisation à partir de EFK Mise à niveau du programme en fonction de Clickhouse Solutions de stockage et d'analyse , Le plan est très clair et détaillé , .Peut être utilisé comme référence pour les méthodes de mise à jour des journaux de masse .
Clickhouse Est une arme pointue pour traiter des scènes à grande échelle à forte intensité de données , Idéal pour le stockage massif de journaux et l'analyse de requêtes , Construit un faible coût ,Pas de point unique,Hyperphagie, Système de journalisation de la prochaine génération pour les requêtes à grande vitesse .
Références:
1.Wechat public Number( Seule la technologie )-《 Le VIP sera basé sur Clickhouse Pratiques de stockage des journaux 》
边栏推荐
- 423- binary tree (110. balanced binary tree, 257. all paths of binary tree, 100. same tree, 404. sum of left leaves)
- numpy. frombuffer()
- 421-二叉树(226. 翻转二叉树、101. 对称二叉树、104.二叉树的最大深度、222.完全二叉树的节点个数)
- 06. talk about the difference and coding between -is and = = again
- 【Spark】Spark SQL 字段血缘如何实现
- 302. minimum rectangular BFS with all black pixels
- kolla-ansible部署openstack yoga版本
- ByteDance starts the employee's sudden wealth plan and buys back options with a large amount of money. Some people can earn up to 175%
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 卷妹带你学jdbc---2天冲刺Day2
猜你喜欢

Class and object learning

消息队列-功能、性能、运维对比

ByteDance starts the employee's sudden wealth plan and buys back options with a large amount of money. Some people can earn up to 175%

423-二叉树(110. 平衡二叉树、257. 二叉树的所有路径、100. 相同的树、404. 左叶子之和)
架构设计方法

解决在win10下cmder无法使用find命令

技术能力的思考和总结

Library management system

Adapter mode
![Selective search for object recognition paper notes [image object segmentation]](/img/cf/d3b08d41083f37c164b26a96b989c9.png)
Selective search for object recognition paper notes [image object segmentation]
随机推荐
Level signal and differential signal
Solve the problem that Cmdr cannot use find command under win10
numpy. tile()
Test depends on abstraction and does not depend on concrete
Tortoise and rabbit race example
Tencent WXG internship experience (has offered), I hope it will help you!
Deeply uncover Ali (ant financial) technical interview process with preliminary preparation and learning direction
423- binary tree (110. balanced binary tree, 257. all paths of binary tree, 100. same tree, 404. sum of left leaves)
Logstash - logstash sends an alarm email to email
Data visualization practice: Experimental Report
numpy.frombuffer()
The difference between overload method and override method
Logstash——Logstash将数据推送至Redis
Implement the runnable interface
Easy to understand from the IDE, and then talk about the applet IDE
Matching environment of ES6
MySQL-09
通俗易懂的从IDE说起,再谈谈小程序IDE
COW读写复制机制在Linux,Redis ,文件系统中的应用
小程序第三方微信授权登录的实现