当前位置:网站首页>Mpai data science platform SVM support vector machine classification \ explanation of regression parameter adjustment
Mpai data science platform SVM support vector machine classification \ explanation of regression parameter adjustment
2022-06-25 12:05:00 【Halosec_ Wei】
C: Penalty factor , The penalty coefficient used to control the loss function , Be similar to LR The regularization coefficient in .C The bigger it is , It's equivalent to punishing relaxation variables , I want the relaxation variable to be close to 0, That is, the punishment for misclassification is increased , It tends to be the case that the training set is totally divided into pairs , In this way, the accuracy of training set test is very high , But the generalization ability is weak , It is easy to cause over fitting . C Small value , The penalty for misclassification is reduced , Enhanced fault tolerance , The generalization ability is strong , But it may also be under fitted .
Value :【0,1】
Kernel function : The kernel function type used in the algorithm , Kernel function is a method used to transform nonlinear problems into linear problems .
RBF nucleus : Gaussian kernel function is to find some points in the attribute space , These points may or may not be sample points , Think of these points as base, With these base Extend the center of the circle outward , The expansion radius is the bandwidth , Data can be divided . let me put it another way , Find some supercircles in the attribute space , Use these hypercircles to determine the positive and negative classes .
Linear kernel and polynomial kernel : The function of these two kernels is to find some points in the attribute space first , Think of these points as base, The function of kernel function is to find the sample point that satisfies some relationship with the distance and angle of the point . When the angle between the sample point and the point is almost vertical , The Euclidean length of two samples must be very long to ensure that the linear kernel function is greater than 0; And when the sample point and base When the directions of the points are the same , The length doesn't have to be very long ; And when the direction is opposite , The value of the kernel function is negative , Be judged as anti class . namely , It divides a shuttle shape in space , Divide the positive and negative classes according to the shuttle shape .
Sigmoid nucleus : Again, define some base, Kernel function is to pass a linear kernel function through a tanh Function to process , Limit the range of values to -1 To 1 On .
All in all , They are all defining the distance , Greater than this distance , Positive , Less than this distance , Negative judgment . As for which kernel function to choose , It should be determined according to the specific sample distribution .
Value :RBF, Linear, Poly, Sigmoid
Coefficient of kernel function : Parameter is rbf,poly and sigmoid Kernel coefficient of ; The default is 'auto', Then the reciprocal of the characteristic digits will be used , namely 1 / n_features.( That is, the bandwidth of the kernel function , The radius of a hypercircle ).gamma The bigger it is ,σ The smaller it is , Make the Gaussian distribution tall and thin , So the model can only act near the support vector , May lead to over fitting ; conversely ,gamma The smaller it is ,σ The bigger it is , Gaussian distribution will be too smooth , The classification effect on the training set is not good , May cause under fitting ,
'auto' 1 / n_features.
scale,1 / (n_features * X.var())
Value :'auto'、scale、(0,1]
Shrinking : Heuristic or not . If you can predict which variables correspond to support vectors , Then it is enough to train on these samples , Other samples may be disregarded , This does not affect the training results , But it reduces the scale of the problem and helps to solve it quickly . further , If you can predict which variables are on the boundary ( namely a=C), Then these variables can remain fixed , Optimize only other variables , So that the scale of the problem is smaller , Training time is greatly reduced . This is it. Shrinking technology . Shrinking Technology is based on the fact that : The support vector only accounts for a small part of the training sample , And the Lagrange multipliers of most support vectors are equal to C.
Value : yes 、 no
Residual convergence condition : The default is 0.0001, Namely tolerance 1000 There is an error in the classification , And LR In the same ; When the error term reaches the specified value, the training will be stopped .
Value :【0,+ infinite 】
Maximum number of iterations : There are no restrictions by default . This is a hard limit , It takes precedence over Residual convergence condition Parameters , Whether the training standard and accuracy meet the requirements or not , Stop training .
Value :【1,+ infinite 】
Multi classification fusion strategy
SVM This is a binary classification algorithm , Because of its strong performance of neural network , Therefore, it is also widely used in the field of multi classification , this ovo and ovr They are two different strategies that need to be selected for multi classification .
ovo:one versus one, one-on-one . It's a one-to-one classifier , Right now K There are three categories that need to be built K * (K - 1) / 2 A classifier
ovr:one versus rest, A couple of other , Right now K All you need to do is build K A classifier
Value :ovo,ovr
边栏推荐
- Cesium draw point line surface
- 动态代理
- Develop two modes of BS mode verification code with VFP to make your website more secure
- Continue to cut the picture after the ArcGIS Server is disconnected
- Network related encapsulation introduced by webrtc native M96 basic base module
- Sentinel integrated Nacos data source
- R语言dplyr包filter函数过滤dataframe数据中指定数据列的内容不是(不等于指定向量中的其中一个)指定列表中的数据行
- 为什么ping不通网站 但是却可以访问该网站?
- VFP function to summarize all numeric columns of grid to cursor
- R语言使用glm函数构建泊松对数线性回归模型处理三维列联表数据构建饱和模型、epiDisplay包的poisgof函数对拟合的泊松回归模型进行拟合优度检验(检验模型效果)
猜你喜欢

架构师为你揭秘在阿里、腾讯、美团工作的区别

Why distributed IDS? What are the distributed ID generation schemes?

VFP uses Kodak controls to control the scanner to solve the problem that the volume of exported files is too large
The service layer reports an error. The XXX method invalid bound statement (not found) cannot be found

使用php脚本查看已开启的扩展

Windows11 MySQL service is missing

SDN系统方法 | 9. 接入网

Redis雪崩、穿透和击穿是什么?
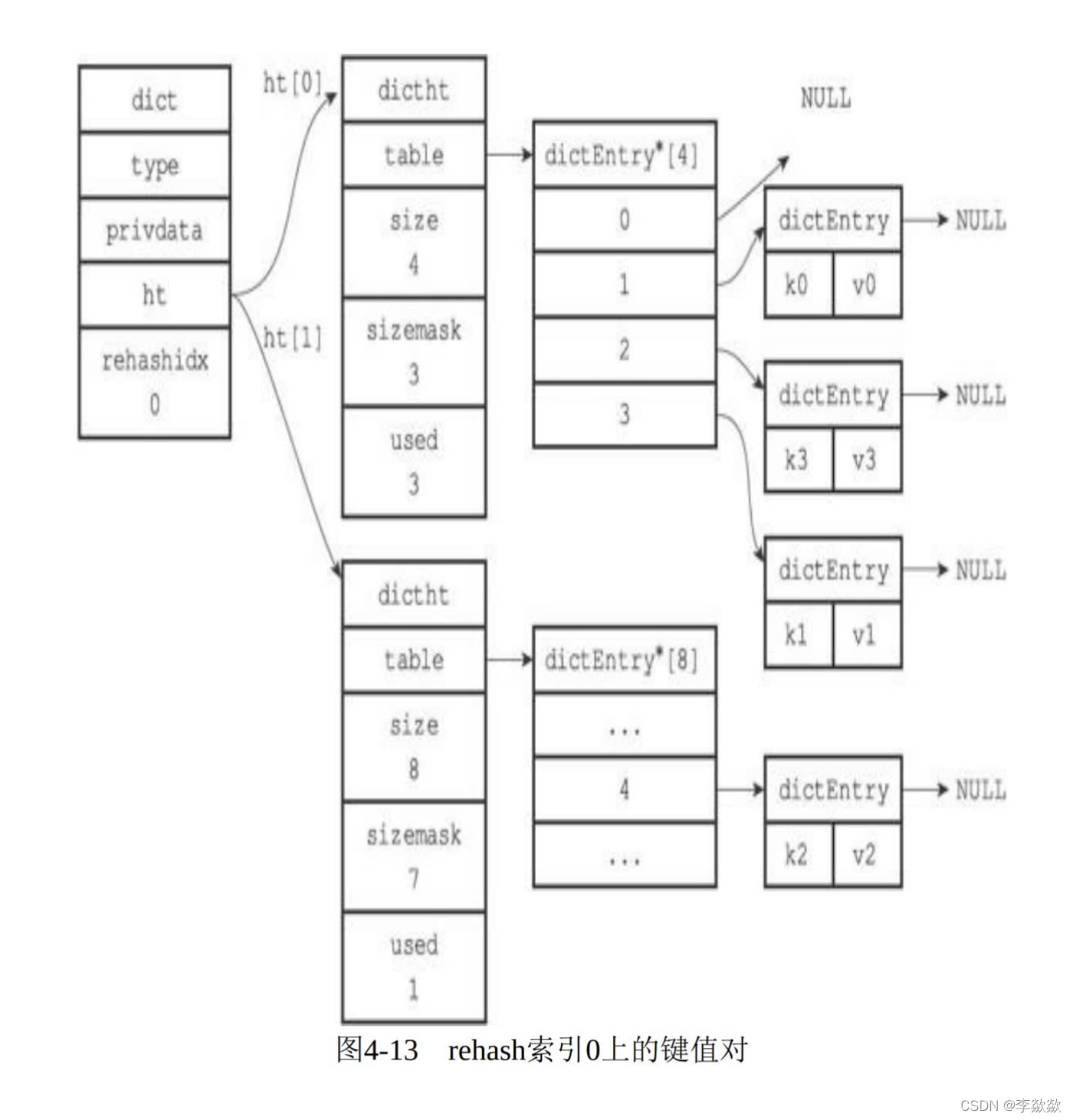
redis的dict的扩容机制(rehash)

Multiple clicks of the button result in results
随机推荐
图片打标签之获取图片在ImageView中的坐标
ArcGIS services query filter by time field
Cesium building loading (with height)
Is industrial securities a state-owned enterprise? Is it safe to open an account in industrial securities?
ThingsPanel 發布物聯網手機客戶端(多圖)
Effective reading of literature
动态代理
R语言使用glm函数构建泊松对数线性回归模型处理三维列联表数据构建饱和模型、epiDisplay包的poisgof函数对拟合的泊松回归模型进行拟合优度检验(检验模型效果)
Record the process of submitting code to openharmony once
黑马畅购商城---1.项目介绍-环境搭建
Problems encountered using easyexcel
Actual combat summary of Youpin e-commerce 3.0 micro Service Mall project
Recommend a virtual machine software available for M1 computer
Black Horse Chang Shopping Mall - - - 3. Gestion des produits de base
Caused by: org. xml. sax. SAXParseException; lineNumber: 1; columnNumber: 10; Processing matching '[xx][mm][ll]' is not allowed
Why can't the form be closed? The magic of revealing VFP object references
Flink deeply understands the graph generation process (source code interpretation)
交易期货沪镍产品网上怎么开户
R语言使用nnet包的multinom函数构建无序多分类logistic回归模型、使用summary函数获取模型汇总统计信息
Openfeign uses