当前位置:网站首页>Data Lake (11): Iceberg table data organization and query
Data Lake (11): Iceberg table data organization and query
2022-07-02 15:56:00 【Hua Weiyun】
Iceberg Table data organization and query
One 、 download avro-tools jar package
Because you need to check later avro The contents of the document , We can go through avro-tool.jar Check it out. avro The data content . It can be downloaded from the following website avro-tools Corresponding jar package , Download and upload to node5 Node :
https://mvnrepository.com/artifact/org.apache.avro/avro-tools
see avro The following commands can be directly executed for file information , Can be avro Convert the data in to the corresponding json data .
[[email protected] ~]# java -jar /software/avro-tools-1.8.1.jar tojson snap-*-wqer.avroTwo 、 stay Hive Created in Iceberg Table and insert data
stay Hive Created in Iceberg Format table , And insert the following data :
# stay Hive Created in iceberg Format table create table test_iceberg_tbl1(id int ,name string,age int) partitioned by (dt string) stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';# Insert the following data insert into test_iceberg_tbl1 values (1,"zs",21,"20211212");insert into test_iceberg_tbl1 values (2,"ls",22,"20211212");insert into test_iceberg_tbl1 values (3,"ww",23,"20211213");insert into test_iceberg_tbl1 values (4,"ml",24,"20211213");insert into test_iceberg_tbl1 values (5,"tq",25,"20211213");3、 ... and 、 see Iceberg Underlying data storage
The following figure for Iceberg surface “test_iceberg_tbl1” stay HDFS Data organization chart stored in :

From the above figure, we can see that there are 5 individual Snapshot snapshot , above 5 individual Snapshot In fact, it corresponds to 5 individual Manifest list List of checklists .
1、 Query the latest snapshot data
In order to understand Iceberg How to query the latest data , You can refer to the following figure to understand the underlying implementation in detail .

Inquire about Iceberg Table data , First get the latest metadata Information , Get it here first “00000-*ec504.metadata.json” Metadata information , Parsing the current metadata file can get a snapshot of the current table id:“949358624197301886” And all the snapshot information of this table , That is to say json In information snapshots The value of the array . According to the snapshot of the current table id Value to get the corresponding snapshot Corresponding avro file information :“snap-*-32800.avro”, We can find the path corresponding to the current snapshot , See what it contains Manifest The manifest file has 5 individual :"*32800-m0.avro"、"*2abba-m0.avro"、"*d33de-m0.avro"、"*748bf-m0.avro"、"*b946e-m0.avro", Read the Iceberg The latest data of the format table is to read the corresponding data described in these files parquet Data file is enough .
We can see “snap-*-32800.avro” The snapshot file contains not only manifest Path information , also “added_data_files_count”、“existing_data_files_count”、“deleted_data_files_count” Three attributes ,Iceberg according to deleted_data_files_count Greater than 0 To determine the corresponding manifest Is there any deleted data in the manifest file , If one manifest The value in the manifest file is greater than 0 Represents data deletion , You don't need to read this when reading data manifest The data file corresponding to the manifest file .
according to Manifest list The corresponding manifest Inventory file , Each document describes the corresponding parquet Location information of file storage , You can see in the corresponding avro In file “status” attribute , The attribute is 1 For the corresponding parquet The file is a new file , Read required , by 2 representative parquet File deleted .
2、 Query the data of a snapshot
Apache Iceberg Supports querying snapshots at any time in history , When querying, you need to specify snapshot-id Attribute is enough , This can only be done through Spark/Flink To query and implement , For example, in Spark Query a snapshot data in as follows :
spark.read.option("snapshot-id",6155408340798912701L).format("iceberg").load("path")The principle of querying a snapshot data is shown in the following figure ( To query the snapshot id by “6155408340798912701” As an example ):

As can be seen from the figure above , In fact, the difference between reading historical snapshot data and reading the latest data is found snapshot-id It's just different , The principle is the same .
3、 View the data of a snapshot based on the timestamp
Apache iceberg It also supports the adoption of as-of-timestamp Parameter execution timestamp to read the data of a snapshot , Also through Spark/Flink To read ,Spark Read the code as follows :
spark.read.option("as-of-timestamp"," Time stamp ").format("iceberg").load("path")In fact, the principle and method of finding the corresponding data file through timestamp snapshot-id The principle of finding data files is the same , stay *.metadata.json In file , Except for “current-snapshot-id”、“snapshots” In addition to attributes, there are “snapshot-log” attribute , The corresponding values of this attribute are as follows :

We can see one of them timestamp-ms Properties and snapshot-id attribute , And according to timestamp-ms ascend . stay Iceberg Internal implementation , It will be as-of-timestamp Designated time and snapshot-log Of each element in the array timestamp-ms Compare , Find the last satisfaction timestamp-ms <= as-of-timestamp Corresponding snapshot-id, The principle of same , adopt snapshot-id Then find the data file to read .
边栏推荐
- Pyinstaller's method of packaging pictures attached to exe
- 《大学“电路分析基础”课程实验合集.实验七》丨正弦稳态电路的研究
- 爱可可AI前沿推介(7.2)
- 手机app通达信添加自定义公式(分时T+0)为例子讲解
- Use ffmpeg command line to push UDP and RTP streams (H264 and TS), and ffplay receives
- 中科大脑知识图谱平台建设及业务实践
- SQL modification statement
- floyed「建议收藏」
- 纪念成为首个 DAYU200 三方 demo 贡献者
- 如何實現十億級離線 CSV 導入 Nebula Graph
猜你喜欢

处理gzip: stdin: not in gzip formattar: Child returned status 1tar: Error is not recoverable: exitin
![[experience cloud] how to get the metadata of experience cloud in vscode](/img/45/012c2265402ba1b44f4497f468bc61.png)
[experience cloud] how to get the metadata of experience cloud in vscode
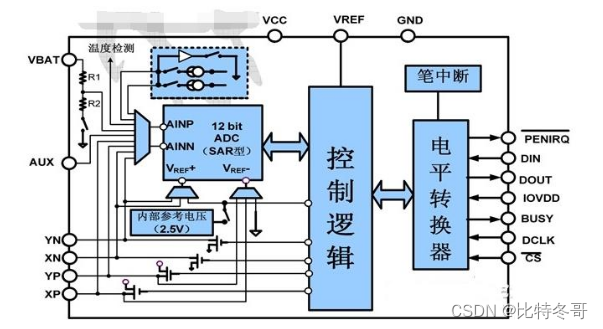
Xpt2046 four wire resistive touch screen
Processing gzip: stdin: not in gzip format: child returned status 1tar: error is not recoverable: exitin

idea 公共方法抽取快捷键

Boot transaction usage
win10系统升级一段时间后,内存占用过高

华为云服务器安装mysqlb for mysqld.service failed because the control process exited with error code.See “sys
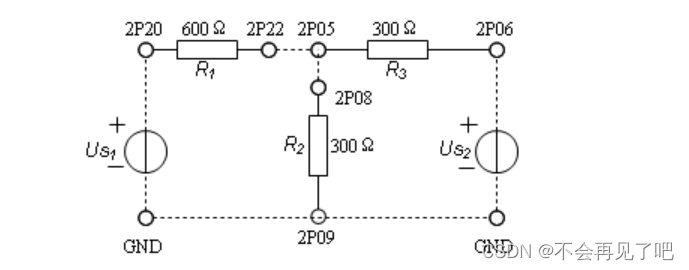
《大学“电路分析基础”课程实验合集.实验四》丨线性电路特性的研究

Crawl the information of national colleges and universities in 1 minute and make it into a large screen for visualization!
随机推荐
6096. Success logarithm of spells and potions
Strings and arrays
[idea] recommend an idea translation plug-in: translation "suggestions collection"
floyed「建议收藏」
Aiko ai Frontier promotion (7.2)
6092. Replace elements in the array
[development environment] install Visual Studio Ultimate 2013 development environment (download software | install software | run software)
/bin/ld: 找不到 -lpam
图数据库|Nebula Graph v3.1.0 性能报告
Postgressql stream replication active / standby switchover primary database no read / write downtime scenario
/bin/ld: 找不到 -lxml2
奥比中光 astra: Could not open “2bc5/[email protected]/6“: Failed to set USB interface
ssh/scp 使不提示 All activities are monitored and reported.
【5G NR】RRC连接释放
Two traversal sequences are known to construct binary trees
Fiddler实现手机抓包——入门
Floyed "suggestions collection"
Experiment collection of University "Fundamentals of circuit analysis". Experiment 7 - Research on sinusoidal steady-state circuit
/Bin/ld: cannot find -lxml2
数据湖(十一):Iceberg表数据组织与查询