当前位置:网站首页>CUDA中的Warp Shuffle
CUDA中的Warp Shuffle
2022-07-02 06:12:00 【扫地的小何尚】
CUDA中的Warp Shuffle
Warp Shuffle Functions
__shfl_sync、__shfl_up_sync、__shfl_down_sync 和 __shfl_xor_sync 在 warp 内的线程之间交换变量。
由计算能力 3.x 或更高版本的设备支持。
弃用通知:__shfl、__shfl_up、__shfl_down 和 __shfl_xor 在 CUDA 9.0 中已针对所有设备弃用。
删除通知:当面向具有 7.x 或更高计算能力的设备时,__shfl、__shfl_up、__shfl_down 和 __shfl_xor 不再可用,而应使用它们的同步变体。
作者添加:这里可能大家对接下来会提到的threadIndex, warpIdx, laneIndex会比较混淆.那么我用下图来说明.

1. Synopsis
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize);
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);
T 可以是 int、unsigned int、long、unsigned long、long long、unsigned long long、float 或 double。 包含 cuda_fp16.h 头文件后,T 也可以是 __half 或 __half2。 同样,包含 cuda_bf16.h 头文件后,T 也可以是 __nv_bfloat16 或 __nv_bfloat162。
2. Description
__shfl_sync() 内在函数允许在 warp 内的线程之间交换变量,而无需使用共享内存。 交换同时发生在 warp 中的所有活动线程(并以mask命名),根据类型移动每个线程 4 或 8 个字节的数据。
warp 中的线程称为通道(lanes),并且可能具有介于 0 和 warpSize-1(包括)之间的索引。 支持四种源通道(source-lane)寻址模式:
__shfl_sync()
从索引通道直接复制
__shfl_up_sync()
从相对于调用者 ID 较低的通道复制
__shfl_down_sync()
从相对于调用者具有更高 ID 的通道复制
__shfl_xor_sync()
基于自身通道 ID 的按位异或从通道复制
线程只能从积极参与 __shfl_sync() 命令的另一个线程读取数据。 如果目标线程处于非活动状态,则检索到的值未定义。
所有 __shfl_sync() 内在函数都采用一个可选的宽度参数,该参数会改变内在函数的行为。 width 的值必须是 2 的幂; 如果 width 不是 2 的幂,或者是大于 warpSize 的数字,则结果未定义。
__shfl_sync() 返回由 srcLane 给定 ID 的线程持有的 var 的值。 如果 width 小于 warpSize,则 warp 的每个子部分都表现为一个单独的实体,其起始逻辑通道 ID 为 0。如果 srcLane 超出范围 [0:width-1],则返回的值对应于通过 srcLane srcLane modulo width所持有的 var 的值 (即在同一部分内)。
作者添加:这里原本中说的有点绕,我还是用图来说明比较好.注意下面四个图均由作者制作,如果有问题,仅仅是作者水平问题-_-!.

__shfl_up_sync() 通过从调用者的通道 ID 中减去 delta 来计算源通道 ID。 返回由生成的通道 ID 保存的 var 的值:实际上, var 通过 delta 通道向上移动。 如果宽度小于 warpSize,则warp的每个子部分都表现为一个单独的实体,起始逻辑通道 ID 为 0。源通道索引不会环绕宽度值,因此实际上较低的 delta 通道将保持不变。
__shfl_down_sync() 通过将 delta 加调用者的通道 ID 来计算源通道 ID。 返回由生成的通道 ID 保存的 var 的值:这具有将 var 向下移动 delta 通道的效果。 如果 width 小于 warpSize,则 warp 的每个子部分都表现为一个单独的实体,起始逻辑通道 ID 为 0。至于 __shfl_up_sync(),源通道的 ID 号不会环绕宽度值,因此 upper delta lanes将保持不变。
__shfl_xor_sync() 通过对调用者的通道 ID 与 laneMask 执行按位异或来计算源通道 ID:返回结果通道 ID 所持有的 var 的值。 如果宽度小于warpSize,那么每组宽度连续的线程都能够访问早期线程组中的元素,但是如果它们尝试访问后面线程组中的元素,则将返回他们自己的var值。 这种模式实现了一种蝶式寻址模式,例如用于树规约和广播。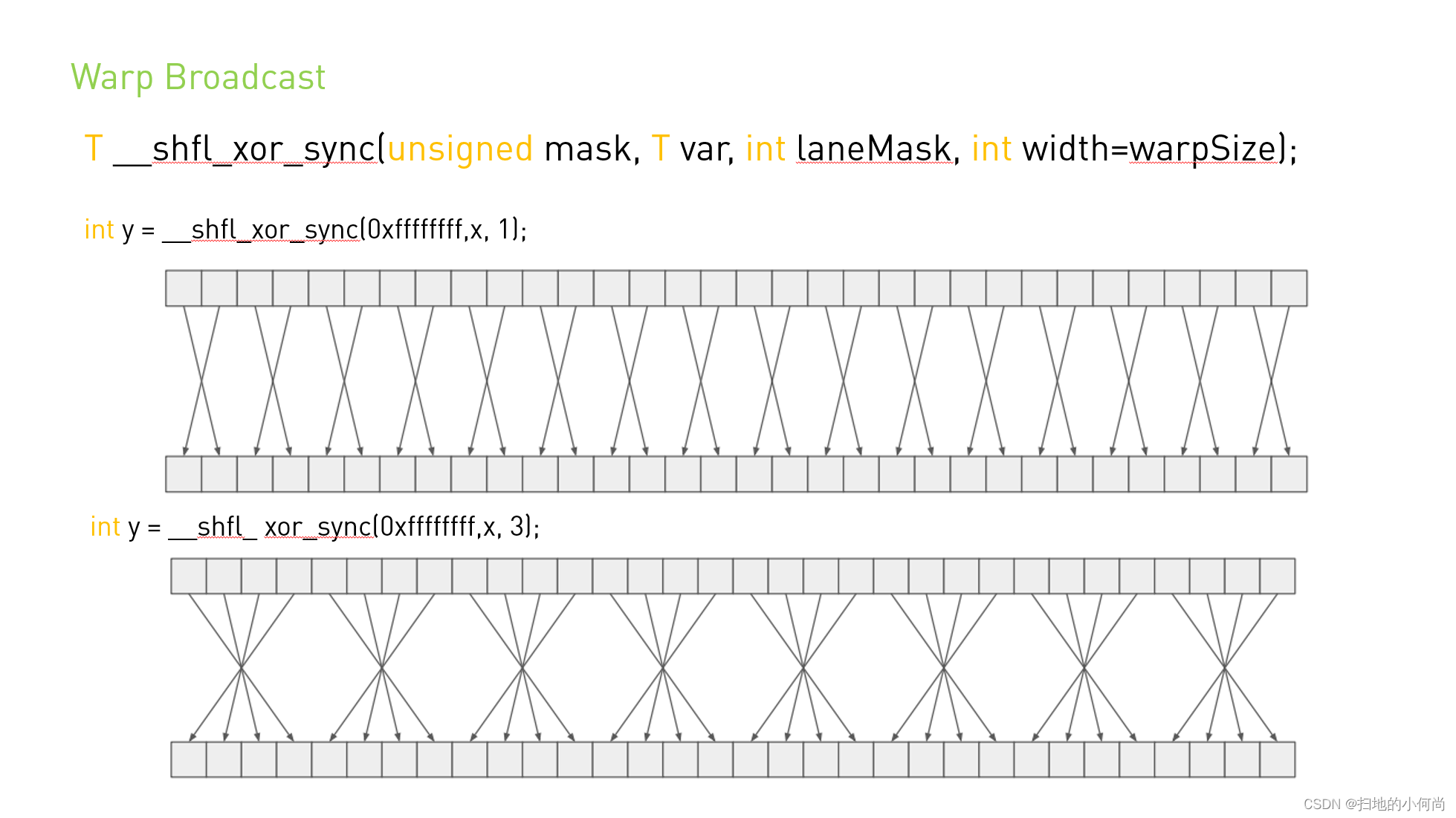
新的 *_sync shfl 内部函数采用一个掩码,指示参与调用的线程。 必须为每个参与线程设置一个表示线程通道 ID 的位,以确保它们在硬件执行内部函数之前正确收敛。 掩码中命名的所有非退出线程必须使用相同的掩码执行相同的内在函数,否则结果未定义。
3. Notes
线程只能从积极参与 __shfl_sync() 命令的另一个线程读取数据。 如果目标线程处于非活动状态,则检索到的值未定义。
宽度必须是 2 的幂(即 2、4、8、16 或 32)。 未指定其他值的结果。
4. Examples
4.1. Broadcast of a single value across a warp
#include <stdio.h>
__global__ void bcast(int arg) {
int laneId = threadIdx.x & 0x1f;
int value;
if (laneId == 0) // Note unused variable for
value = arg; // all threads except lane 0
value = __shfl_sync(0xffffffff, value, 0); // Synchronize all threads in warp, and get "value" from lane 0
if (value != arg)
printf("Thread %d failed.\n", threadIdx.x);
}
int main() {
bcast<<< 1, 32 >>>(1234);
cudaDeviceSynchronize();
return 0;
}
4.2. Inclusive plus-scan across sub-partitions of 8 threads
#include <stdio.h>
__global__ void scan4() {
int laneId = threadIdx.x & 0x1f;
// Seed sample starting value (inverse of lane ID)
int value = 31 - laneId;
// Loop to accumulate scan within my partition.
// Scan requires log2(n) == 3 steps for 8 threads
// It works by an accumulated sum up the warp
// by 1, 2, 4, 8 etc. steps.
for (int i=1; i<=4; i*=2) {
// We do the __shfl_sync unconditionally so that we
// can read even from threads which won't do a
// sum, and then conditionally assign the result.
int n = __shfl_up_sync(0xffffffff, value, i, 8);
if ((laneId & 7) >= i)
value += n;
}
printf("Thread %d final value = %d\n", threadIdx.x, value);
}
int main() {
scan4<<< 1, 32 >>>();
cudaDeviceSynchronize();
return 0;
}
4.3. Reduction across a warp
#include <stdio.h>
__global__ void warpReduce() {
int laneId = threadIdx.x & 0x1f;
// Seed starting value as inverse lane ID
int value = 31 - laneId;
// Use XOR mode to perform butterfly reduction
for (int i=16; i>=1; i/=2)
value += __shfl_xor_sync(0xffffffff, value, i, 32);
// "value" now contains the sum across all threads
printf("Thread %d final value = %d\n", threadIdx.x, value);
}
int main() {
warpReduce<<< 1, 32 >>>();
cudaDeviceSynchronize();
return 0;
}
边栏推荐
- 官方零基础入门 Jetpack Compose 的中文课程来啦!
- BGP routing optimization rules and notification principles
- Frequently asked questions about jetpack compose and material you
- Eco express micro engine system has supported one click deployment to cloud hosting
- Contest3147 - game 38 of 2021 Freshmen's personal training match_ 1: Maximum palindromes
- Common means of modeling: combination
- Sudo right raising
- Bgp Routing preference Rules and notice Principles
- Zhuanzhuanben - LAN construction - Notes
- Introduce uview into uni app
猜你喜欢

经典文献阅读之--Deformable DETR
State machine in BGP

Jetpack Compose 与 Material You 常见问题解答
浏览器原理思维导图

Little bear sect manual query and ADC in-depth study

栈(线性结构)
LeetCode 90. Subset II
Google Go to sea entrepreneurship accelerator registration countdown 3 days, entrepreneurs pass through the guide in advance collection!

递归(迷宫问题、8皇后问题)
Deep learning classification network -- alexnet
随机推荐
Shenji Bailian 3.52-prim
Picture clipping plug-in cropper js
Spark overview
Unity shader learning notes (3) URP rendering pipeline shaded PBR shader template (ASE optimized version)
Use of Arduino wire Library
步骤详解 | 助您轻松提交 Google Play 数据安全表单
CNN visualization technology -- detailed explanation of cam & grad cam and concise implementation of pytorch
日志(常用的日志框架)
Detailed explanation of BGP message
找到页面当前元素z-index最高的数值
LeetCode 283. 移动零
亚马逊aws数据湖工作之坑1
Error creating bean with name 'instanceoperatorclientimpl' defined in URL when Nacos starts
借力 Google Cloud 基础设施和着陆区,构建企业级云原生卓越运营能力
Ruijie ebgp configuration case
492. Construction rectangle
经典文献阅读之--SuMa++
sudo提权
WLAN相关知识点总结
Servlet web XML configuration details (3.0)