当前位置:网站首页>Deep learning classification network -- vggnet
Deep learning classification network -- vggnet
2022-07-02 06:01:00 【occasionally.】
Deep learning classification network Summary
1. AlexNet
2. VGGNet
List of articles
Preface
VGGNet yes 2014 year ILSVRC The second place , The first name is GoogLeNet. Put forward VGG Our motivation is mainly to study the influence of network depth on its accuracy , The main idea is to use only 3×3 Convolution builds a deep network . It turns out that , When the depth of the network reaches 16~19 Can achieve better performance .
One 、 Network structure
A total of 6 It's a network structure , This design has a certain purpose :
- contrast A and A-LRN Performance on the test set LRN Whether it works ;
- contrast A and B To determine whether adding a convolution layer in the shallow layer of the network is effective ;
- contrast B and C To determine the increase in the depth of the network 1×1 Whether the convolution layer is effective ;
- contrast C and D To make sure 1×1 Convolution kernel 3×3 Convolution is better or worse ;
- contrast D and E To determine the increase in the depth of the network 3×3 Whether convolution is effective ;

Two 、 The main points of
1. Abandoning LRN
The Internet A-LRN Of top1 and top5 The error rate is higher than that of the network A, So in the following B、C、D、E None of them are used LRN layer .
2. Small size convolution
- Use stacked 3×3 Convolution instead of 5×5 or 7×7 Convolution , There are two advantages :
① Add more nonlinearity on the basis of keeping the receptive field unchanged , At the same time, the network is also deeper . Suppose you use 3 individual 3×3 Convolution instead of a 7×7 Convolution , After each convolution, there is a ReLU, It is equivalent to adding two additional ReLU;
② Reduce the number of parameters . Assume that the input and output channels are C, Then use 7×7 The parameter of convolution is 7 ∗ 7 ∗ C ∗ C = 49 C 2 7*7*C*C=49C^2 7∗7∗C∗C=49C2, Use 3 individual 3×3 The parameter of convolution is 3 ∗ 3 ∗ C ∗ C ∗ 3 = 27 C 2 3*3*C*C*3=27C^2 3∗3∗C∗C∗3=27C2, Reduced the appointment 45%. - Use 1×1 Convolution increases nonlinearity without affecting receptive fields .(1×1 Convolution in Network In Network Used in architecture )
3. Weight initialization
- Random initialization A Online weights and bias, Yes A Network training .
- In training deeper BCDE When the network , Use A Network parameters to initialize their pre 4 A convolution and post 3 All connection layers , The middle layer is initialized randomly , Do not change the learning rate of the pre initialization layer .
- Random initialization : w ∼ N ( 0 , 0.01 ) w\sim N(0,0.01) w∼N(0,0.01), b i a s = 0 bias=0 bias=0
notes : Mentioned in the text Xavier(glorot) Initialization can initialize weights without pre training .
4. Multiscale training
Make S Is the minimum side length of the training image after rescaling , Crop in rescaled image 224*224 As input to the network , therefore S≥224. There are two ways to set S:
- Fix S, Corresponding to single scale training : Use S=256 and S=384 Two scales , First use S=256 Training network , To speed up S=384 Network training , Use S=256 Parameter initialization of S=384 Network weight , And use a smaller learning rate 0.001.
- from [256,512] Random sampling in range S, Corresponding to multi-scale training : For speed reasons , adopt fine-tune Single scale with the same configuration (S=384) Pre train all layers of the model to train the multiscale model .
Why multi-scale training ?
- The same kind of objects can have different scales in different images , Therefore, it is beneficial for network learning to consider multi-scale in training ;
- It can be seen as a kind of data enhancement , To train a single model that can recognize objects of various scales
5. Multiscale & Multi crop test
Multi scale testing ( This method is called ‘dense’) Divided into the following steps :
- Rescale the training image to the scale Q( That is, the minimum side length ), also Q It doesn't need to be equal to S, Because the article puts forward Converting a fully connected layer to a convoluted layer , So it can adapt to different sizes of input ;
- Q There are two choices : For single scale training ,Q={S-32, S, S+32}; For multiscale training ,Q={256, 384, 512} ;
- Zoom to scale Q The image is directly input into the full convolution network , The feature map obtained at each scale is averaged in the spatial dimension , Get the category score vector , Then average the category score vectors of all scales to obtain the final result .
About “ Converting a fully connected layer to a convoluted layer ”: Because the input during training is 224×224, Output characteristic diagram after maximum pooling size Fixed for 7×7×512, The input channel of the first full connection layer is 7×7×512=25088, The output channel is 4096, Then the conversion to convolution is 4096 individual 7×7×512 Convolution kernel . Empathy , The second and third fully connected layers are converted to include 4096 A dimension for 1×1×4096 The convolution layer of the convolution kernel .
Multi crop test (multi-crop): For each scale , Cut from 50 picture 224*224 Image , The three scales are 150 Images , Average the category score vector of all images as the final result .
3、 ... and 、 experimental result & Conclusion
1. Single scale testing

- Using local response normalization (A-LRN The Internet ) It cannot improve the model without any normalization layer A, Therefore, there is no deeper architecture (B-E) Use in LRN;
- A~E Decreasing error rate , It shows that increasing the network depth within a certain range can improve the classification accuracy ;
- Although the additional nonlinearity (1×1 Convolution ) It can really improve the accuracy (C Than B Better ), But by using 3×3 Convolution to capture spatial context is also important (D Than C good );
- Multi scale training is better than single scale training , It is confirmed that the training set enhanced by scale jitter is indeed helpful to capture multi-scale image statistical data .
2. Multiscale & Multi crop test
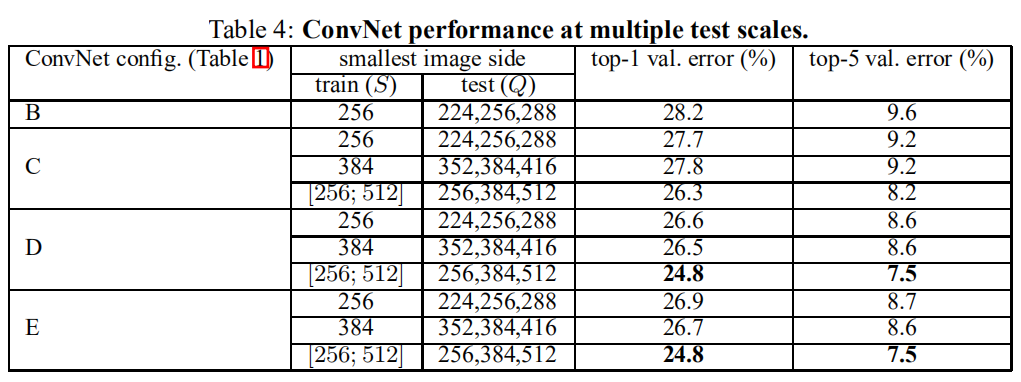

- Both multi-scale and multi tailoring tests can reduce the error rate , The combination of the two can further reduce the error rate .
Reference material
边栏推荐
- Shenji Bailian 3.52-prim
- Yyds dry inventory what is test driven development
- 使用HBuilderX的一些常用功能
- php读文件(读取json文件,转换为数组)
- The Hong Kong Stock Exchange learned from US stocks and pushed spac: the follow-up of many PE companies could not hide the embarrassment of the world's worst stock market
- 运动健身的一些心得经验
- Use some common functions of hbuilderx
- Redis key value database [primary]
- Happy Lantern Festival | Qiming cloud invites you to guess lantern riddles
- Matplotlib double Y axis + adjust legend position
猜你喜欢
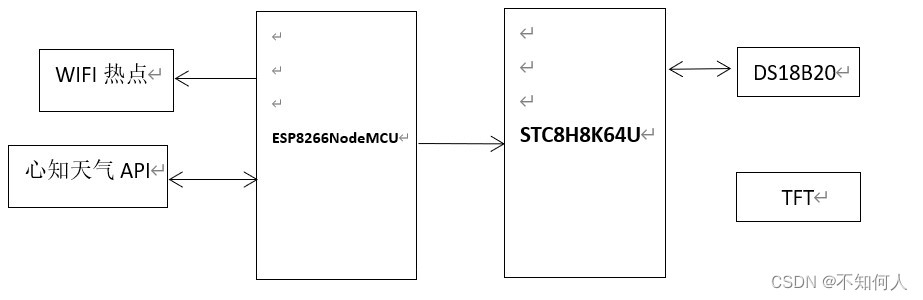
Linkage between esp8266 and stc8h8k single chip microcomputer - Weather Clock
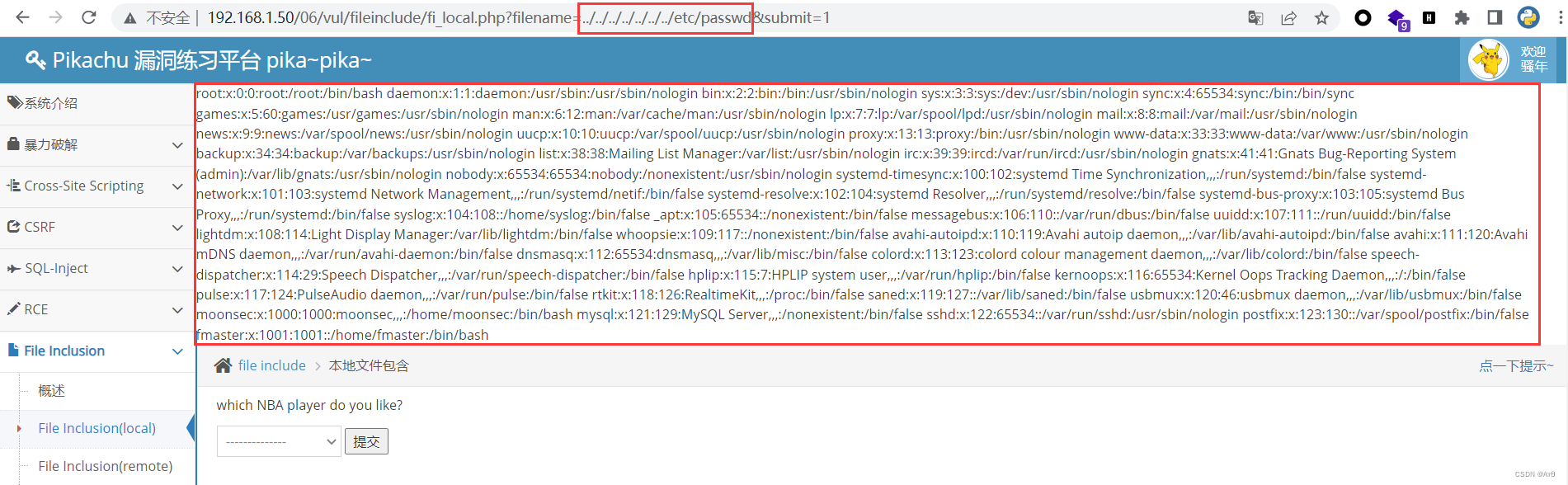
File contains vulnerability (I)
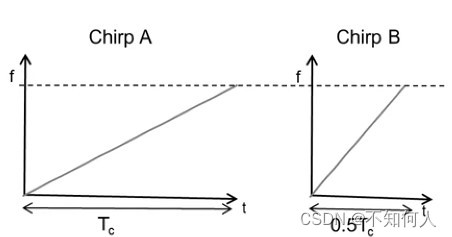
TI毫米波雷达学习(一)

Lantern Festival gift - plant vs zombie game (realized by Matlab)
![[whether PHP has soap extensions installed] a common problem for PHP to implement soap proxy: how to handle class' SoapClient 'not found in PHP](/img/25/73f11ab2711ed2cc9f20bc7f9116b6.png)
[whether PHP has soap extensions installed] a common problem for PHP to implement soap proxy: how to handle class' SoapClient 'not found in PHP

PHP development and testing WebService (soap) -win
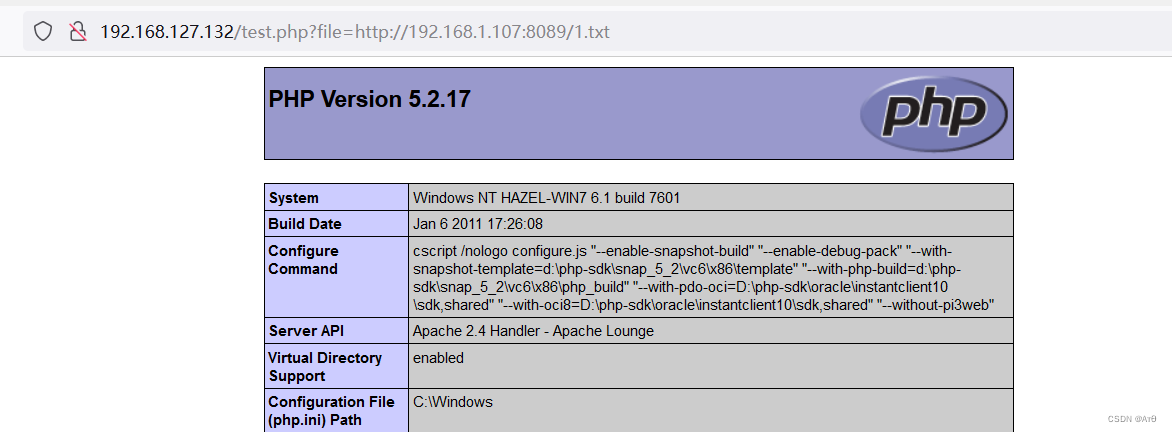
File contains vulnerabilities (II)
在uni-app中引入uView

"Simple" infinite magic cube

死磕大屏UI,FineReport开发日记
随机推荐
OLED12864 液晶屏
ROS2----LifecycleNode生命周期节点总结
神机百炼3.52-Prim
How vite is compatible with lower version browsers
数据挖掘方向研究生常用网站
Go 学习笔记整合
ESP8266与STC8H8K单片机联动——天气时钟
Gcnet: non - local Networks meet Squeeze excitation Networks and Beyond
Some descriptions of Mipi protocol of LCD
How to write good code - Defensive Programming Guide
外部中断无法进入,删代码再还原就好......记录这个想不到的bug
Lantern Festival gift - plant vs zombie game (realized by Matlab)
Unity Shader 学习笔记(3)URP渲染管线带阴影PBR-Shader模板(ASE优化版本)
Redis key value database [advanced]
【C语言】筛选法求素数
数据回放伴侣Rviz+plotjuggler
Mock simulate the background return data with mockjs
从设计交付到开发,轻松畅快高效率!
Keepalived installation, use and quick start
Lambda 表达式 和 方法引用