当前位置:网站首页>DeLighT:深度和轻量化的Transformer
DeLighT:深度和轻量化的Transformer
2022-08-04 08:08:00 【思艺妄为】
DELIGHT: DEEP AND LIGHT-WEIGHT TRANSFORMER
论文:https://arxiv.org/abs/2008.00623
代码:https://github.com/sacmehta/delight
1.简介
本文提出了一个更深更轻量的Transformer-DeLighT,DeLighT更有效地在每个Transformer Block中分配参数:
(1)使用DeLighT转换进行深度和轻量级的转换;
(2)使用Block-wise Scaling进行跨Block,允许在输入附近有较浅和较窄的DeLighT Block,以及在输出附近有较宽和较深的DeLighT Block。
总的来说,DeLighT网络的深度是标准Transformer的2.5到4倍,但参数和操作更少。在机器翻译和语言建模任务上的实验表明,DeLighT在提高了基准Transformer性能的基础上,平均减少了2到3倍的参数量。
2.干啥了都
2.1模型缩放
模型缩放是提高顺序模型性能的标准方法。 模型的大小在宽度比例上增加,而在深度比例上堆叠更多的块。 在这两种情况(及其组合)中,网络每个块中的参数都相同,这可能出现次优解决方案。 为了进一步改善序列模型的性能,[1]引入了块比例缩放,允许设计可变大小的块并在网络中有效分配参数。
论文的研究结果表明:
靠近输入的较浅和较窄的DeLighT块,靠近输出的较深和较宽的DeLighT块可提供最佳性能。
与仅使用模型缩放相比,基于块缩放的模型可以实现更好的性能。
卷积神经网络(CNN)还可以学习靠近输入的浅层和窄层表示,以及靠近输出的深层和宽泛表示。 与在每个卷积层中执行固定数量的操作的CNN不同,建议的块缩放在每个层和块中使用可变数量的操作。
2.2改进序列模型
重要工作:
(1)使用更好的标记级别表示(例如使用BPE),自适应输入和输出以及定义以提高准确性
(2)使用压缩 ,修剪和蒸馏以提高效率
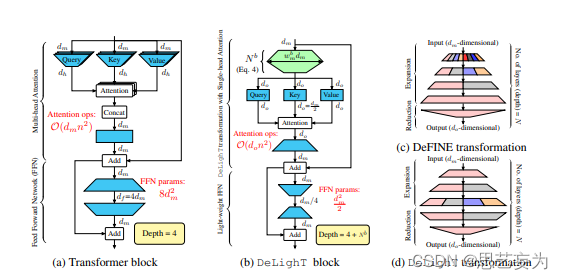
本文工作最接近的是定义转换,它也使用“展开-缩小”策略学习表示。DeFINE转换(图1c)和DeLighT转换(图1d)之间的关键区别是,DeLighT转换更有效地在扩展层和简化层中分配参数。
3.Delight Transformer
标准的Transformer块如图(a)所示:
包括使用查询,键,值对序列令牌之间的关系进行建模,以及使用前馈网络(FFN)来学习更广泛的表示形式。
通过将3个投影应用于输入以获得Query,Key和Value,可以获得多头注意。 每个投影均由h个线性层(或头部)组成,并且尺寸输入映射到一维空间,即头部尺寸。
FFN由以下两个线性层操作完成:
第1步:尺寸扩展
第2步:尺寸缩减
Transformer Block的深度是4,一般情况下,基于Transformer的网络设计均是按顺序堆叠Transformer Block,以增加网络容量和深度。
3.1DeLighT
DeLighT变换首先将维输入向量映射到高维空间,然后使用N层组变换将其简化为维输出向量(降阶),如图1b所示。
在expansion-reduction阶段,DeLighT变换使用组线性变换(GLT),因为它们通过从输入的特定部分导出输出来学习局部表示,这比线性变换更有效。为了学习全局表征,DeLighT变换使用特征变换在组线性变换的不同组之间共享信息,类似于卷积网络中的通道变换。
增加Transformer的表达能力和容量的标准方法是增加输入维度dm。但是,线性增加也会增加标准Transformer块(序列长度在其中)的多头注意力的复杂性。相比之下,为了增加DeLighT块的表达能力和容量,本文使用扩展和收缩阶段来增加中间DeLighT过渡的深度和宽度。这使DeLighT可以使用较小的尺寸和较少的操作来计算注意力。
DeLighT变换由5个配置参数控制:
(1)GLT层数N(2)宽度乘数wm(3)输入维数dm(4)输出维度d0(5)GLT中最大的组数
在expansion阶段:DeLighT transformation将dm维输入投影到高维空间, = wm*dm,线形层为N/2层。
= wm*dm,线形层为N/2层。
在reduction阶段:DeLighT变换使用剩余的N-N/2 GLT层将维向量投影到d0维空间。
3.2 DeLighT Block
图(b)显示了如何将DeLighT Transformation集成到Transformer块中以提高其效率, 先将dm维度的输入首先被反馈到DeLighT变换以产生do维的输出,其中do<dm。这些d0维度的输出然后被反馈到单个head attention中,随后是一个轻量的FFN来建模它们之间的关系。
DeLighT层和单头注意:假设有一个n个输入token序列,每个token的维数为dm。这些n个dm维的输入首先被反馈到DeLighT变换以产生n,do维的输出,其中do<dm。然后使用三个线性层同时投影这些n个do维输出以产生do维查询Q、键K和值v。然后使用缩放的点积注意力来建模这n个token之间的上下文关系。为了能够使用残差连接,该注意力操作的do维输出被线性投影到dm维空间中。
假设,学习更广泛表征的DeLighT能力允许用单头注意力取代多头注意力。标准transformer中计算注意力的计算代价和DeLighT块分别为O(dmn2)和O(don2),其中do<dm。因此,DeLighT块将计算注意力的成本降低了dm/do的因子。在实验中,使用do=dm/2,因此与transformer架构相比,所需的乘法-加法运算减少了2倍。
轻量级FFN:与transformer中的FFN类似,此块也由两个线性层组成。由于DeLighT块已经使用DeLighT变换合并了更广泛的表示,因此它允许在Transformer中反转FFN层的功能。第一层将输入的维数从dm降至dm/r,而第二层将维数从dm/r扩展至dm,其中r为降因子。轻量级FFN将FFN中的参数和操作数量减少了一个rdf/dm因子。在标准transformer中,FFN的维度扩大了4倍。使用r=4。因此,轻量级FFN将FFN中的参数数量减少了16倍。
DeLighT块栈包括:
1)、1个有N个GLTs的DeLighT转换,
2)、3个平行的用于键、查询和值的线性层,
3)、一个投影层,
4)、轻量级FFN的2个线性层。
因此,DeLighT块的深度是N+4。与标准transformer(深度为4)相比,DeLighT块更深。
3.3 分块缩放Block-Wise Scaling
改进序列模型性能的标准方法包括增加模型尺寸(宽度缩放),堆叠更多的块(深度缩放),或两者兼用。然而,这种尺度变换在小数据集上并不十分有效。为了创建深度和宽度的网络,将模型缩放到块级别。
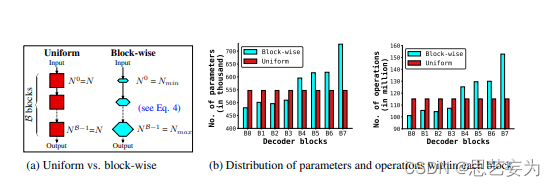
缩放DeLighT块:DeLighT块使用DeLighT变换学习深度和宽度表示,其深度和宽度分别由两个配置参数控制:GLT层数N和宽度乘数wm(图a)。这些配置参数允许独立于输入dm和输出do维度增加DeLighT块内的可学习参数的数量。标准transformer块不可能进行这种校准,因为它们的表现力和容量是输入的函数(输入维度=头数×头维度)。在这里,引入了分块缩放,它创建了一个具有不同大小的DeLighT块的网络,在输入端附近分配较浅和较窄的DeLighT块,在输出端附近分配较深和较宽的DeLighT块。
为此,引入两个网络范围的配置参数:DeLighT变换中的最小Nmin和最大Nmax GLT数。对于第b个DeLighT块,计算在使用线性缩放的DeLighT变换中GLT的个数Nb和宽度乘数wmb。通过这种缩放,每个DeLighT块具有不同的深度和宽度。
网络深度:transformer块深度固定为4。因此,之前的工作已经将基于transformer的网络的深度与transformer块的数量相关联。本论文提出了一个不同的视角来学习更深的表征,其中每个块的大小是可变的。为了计算网络深度,使用跨不同领域的标准定义,包括计算机视觉和理论机器学习。这些工作将网络深度度量为连续的可学习层(例如,卷积层、线性层或组线性层)的数量。与此类似,具有B块的DeLighT网络和transformer网络的深度分别为∑b=0B−1(Nb+4)和4B。
4.实验
更好更good更给力哈哈哈
边栏推荐
- (三)DDD上下文映射图——老师,我俩可是纯洁的男女关系!
- [NOI Simulation Competition] Paper Tiger Game (Game Theory SG Function, Long Chain Division)
- New Questions in Module B of Secondary Vocational Network Security Competition
- IntelliJ新建一个类或者包的快捷键是什么?
- 解决:Hbuilder工具点击发行打包,一直报尚未完成社区身份验证,请点击链接xxxxx,项目xxx发布H5失败的错误。
- 分布式计算实验3 基于PRC的书籍信息管理系统
- 【JS 逆向百例】某网站加速乐 Cookie 混淆逆向详解
- GIS数据与CAD数据间带属性字段互相转换还原工具,解决ArcGIS等软件进行GIS数据转CAD数据无法保留属性字段问题
- 25.时间序列预测实战
- Distributed Computing Experiment 3 PRC-based Book Information Management System
猜你喜欢




随机推荐
Mysql insert on duplicate key 死锁问题定位与解决
金仓数据库KingbaseES客户端编程接口指南-JDBC(9. JDBC 读写分离)
Detailed explanation of TCP protocol
使用requests post请求爬取申万一级行业指数行情
并查集介绍和基于并查集解决问题——LeetCode 952 按公因数计算最大组件大小
大佬们,mysql里text类型的字段,FlinkCDC需要特殊处理吗 就像处理bigint uns
金仓数据库KingbaseES客户端编程接口指南-JDBC(10. JDBC 读写分离最佳实践)
占位,稍后补上
C语言strchr()函数以及strstr()函数的实现
关于常用状态码4XX提示错误
inject() can only be used inside setup() or functional components.
Distributed Computing Experiment 2 Thread Pool
IDEA引入类报错:“The file size (2.59 MB) exceeds the configured limit (2.56MB)
<jsp:useBean>动作的使用
虚拟机没有USB网卡选项怎么解决
Thread类的基本使用。
在安装GBase 8c数据库的时候,报错显示“Host ips belong to different cluster”。这是为什么呢?有什么解决办法?
Typora_Markdown_图片标题(题注)
设计信息录入界面,完成人员基本信息的录入工作,
leetcode 22.8.1 二进制加法