当前位置:网站首页>2020CCFBDCI训练赛之室内用户时序数据分类baseline
2020CCFBDCI训练赛之室内用户时序数据分类baseline
2020-11-10 11:27:00 【osc_2koojuzp】
室内用户时序数据分类
赛题介绍
赛题名:室内用户运动时序数据分类
赛道:训练赛道
背景:随着数据量的不断积累,海量时序信息的处理需求日益凸显。作为时间序列数据分析中的重要任务之一,时间序列分类应用广泛且多样。时间序列分类旨在赋予序列某个离散标记。传统特征提取算法使用时间序列中的统计信息作为分类的依据。近年来,基于深度学习的时序分类取得了较大进展。基于端到端的特征提取方式,深度学习可以避免繁琐的人工特征设计。如何对时间序列中进行有效的分类,从繁芜丛杂的数据集中将具有某种特定形态的序列归属到同一个集合,对于学术研究及工业应用具有重要意义。
任务:基于上述实际需求以及深度学习的进展,本次训练赛旨在构建通用的时间序列分类算法。通过本赛题建立准确的时间序列分类模型,希望大家探索更为鲁棒的时序特征表述方法。
比赛链接:https://www.datafountain.cn/competitions/484
数据简介
数据整理自网上公开数据集UCI(已脱敏),数据集涵盖2类不同时间序列,该类数据集广泛应用于时序分类的业务场景。
| 文件类别 | 文件名 | 文件内容 |
|---|---|---|
| 训练集 | train.csv | 训练数据集标签文件,标签CLASS |
| 测试集 | test.csv | 测试数据集标签文件,无标签 |
| 字段说明 | 字段说明.xlsx | 训练集/测试集XXX个字段的具体说明 |
| 提交样例 | Ssample_submission.csv | 仅有两个字段ID\CLASS |
数据分析
本题是一个二分类的问题,通过对训练集数据的观察,发现数据量很小(210个)且拥有大量的特征(240个),并且对于训练数据的标签值,0和1的分布十分均匀(约各一半)。基于此,使用直接神经网络模型会导致需要训练的参数过多从而获得不理想的结果。而使用树模型,需要调整一些超参数来适应该数据,也比较繁琐。综合以上分析,本文考虑使用最简单的支持向量机来进行分类,结果表明也获得了比较好的结果。
Baseline程序
import pandas as pd
import numpy as np
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.svm import SVR
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
#分离数据集
X_train_c = train.drop(['ID','CLASS'], axis=1).values
y_train_c = train['CLASS'].values
X_test_c = test.drop(['ID'], axis=1).values
nfold = 5
kf = KFold(n_splits=nfold, shuffle=True, random_state=2020)
prediction1 = np.zeros((len(X_test_c), ))
i = 0
for train_index, valid_index in kf.split(X_train_c, y_train_c):
print("\nFold {}".format(i + 1))
X_train, label_train = X_train_c[train_index],y_train_c[train_index]
X_valid, label_valid = X_train_c[valid_index],y_train_c[valid_index]
clf=SVR(kernel='rbf',C=1,gamma='scale')
clf.fit(X_train,label_train)
x1 = clf.predict(X_valid)
y1 = clf.predict(X_test_c)
prediction1 += ((y1)) / nfold
i += 1
result1 = np.round(prediction1)
id_ = range(210,314)
df = pd.DataFrame({
'ID':id_,'CLASS':result1})
df.to_csv("baseline.csv", index=False)
提交结果
提交baseline,得分是0.83653846154。
由于对数据做了五折,因此提交结果分数会有一点波动。
版权声明
本文为[osc_2koojuzp]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4301555/blog/4710875
边栏推荐
猜你喜欢
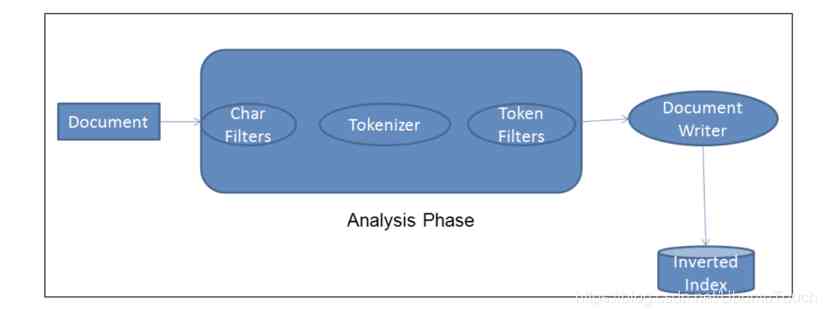
ElasticSearch 集群基本概念及常用操作汇总(建议收藏)

getIServiceManager() 源码分析
Unity style transfer for person re identification
世界上最伟大的10个公式,其中一个人尽皆知

LeetCode:数组(一)
Notes on Python cookbook 3rd (2.3): matching strings with shell wildcards
中央重点布局:未来 5 年,科技自立自强为先,这些行业被点名
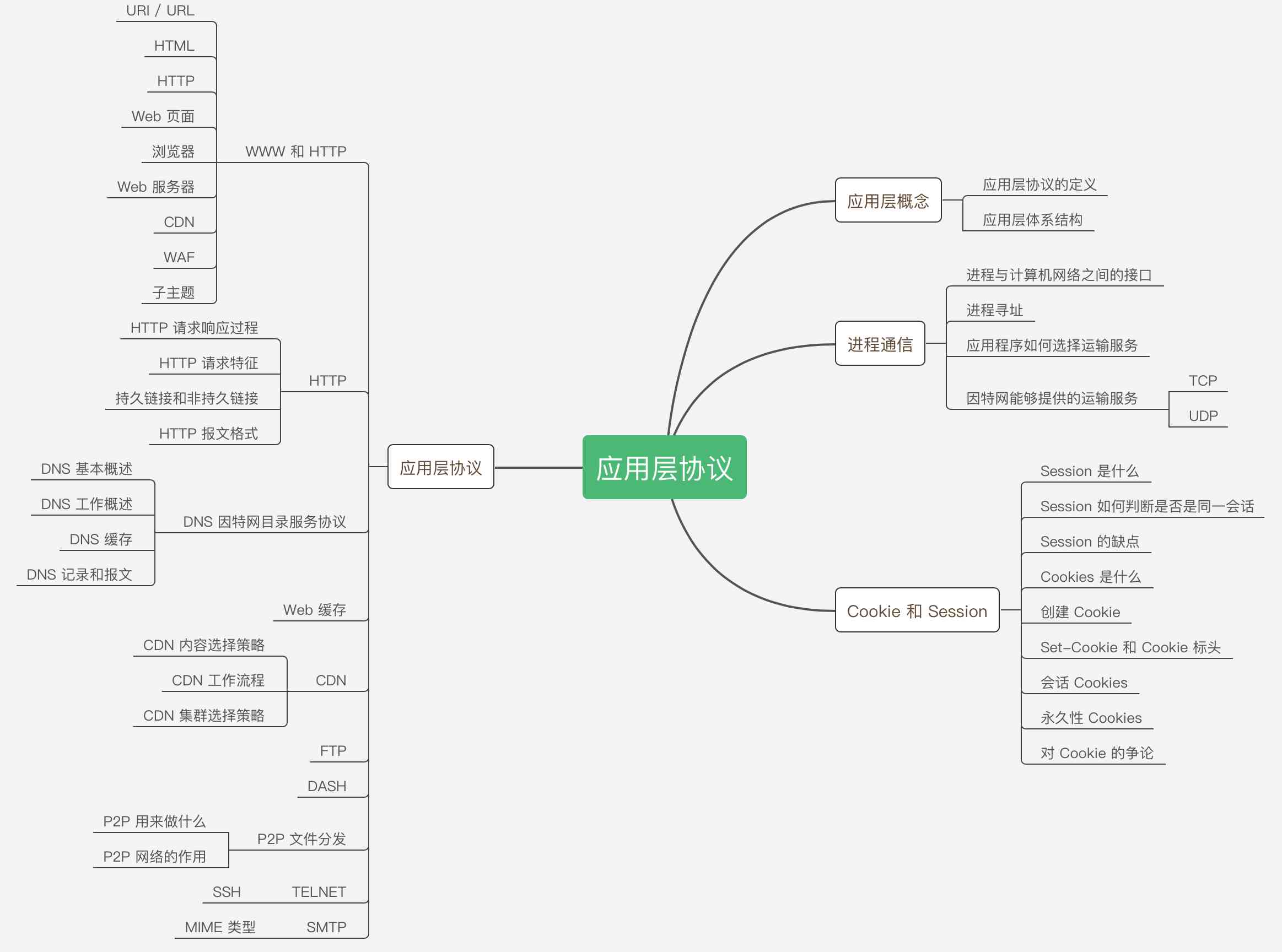
One accidentally drew 24 diagrams to analyze the network application layer protocol!
The high pass snapdragon 875 has won the title of Android processor, but the external 5g baseband has become its disadvantage
The unscrupulous merchants increase the price of mate40, and Xiaomi is expected to capture more market in the high-end mobile phone market
随机推荐
Leetcode 1-sum of two numbers
How can computer major students avoid becoming low-level code farmers?
世界上最伟大的10个公式,其中一个人尽皆知
GNU assembly language uses inline assembly to extend ASM
jsliang 求职系列 - 09 - 手写浅拷贝和深拷贝
【高级测试工程师】新鲜出炉的三套价值18K的自动化测试面试(网易、字节跳动、美团)
He doubled the fluency of the long list of idle fish app
TCP性能分析与调优策略
Centos7 Rsync + crontab scheduled backup
8、参数校验
ASP.NET Core framework revealed
《Python Cookbook 3rd》笔记(2.4):字符串匹配和搜索
CCR coin robot: novel coronavirus pneumonia has accelerated the interest of regulators in CBDC.
idea提交SVN忽略文件设置
Centos7 rsync+crontab 定时备份
Android网络性能监控方案
A professional tour -- a quick tour of GitHub hot spots Vol.45
gnu汇编语言使用内联汇编 扩展asm
MultiBank Group宣布创纪录的财务业绩,2020年前三季度毛利达到9,400万美元
一个 Task 不够,又来一个 ValueTask ,真的学懵了!