当前位置:网站首页>Unity style transfer for person re identification
Unity style transfer for person re identification
2020-11-10 11:22:00 【osc_dc6pbw3x】
Pedestrian recognition of reading notes Unity Style Transfer for Person Re-Identification
paper: https://arxiv.org/pdf/2003.02068.pdf
Abstract
Style change has always been ReID One of the main challenges of , The goal is to match the same pedestrian under different cameras . Existing research attempts to solve this problem by using camera invariant description subspace learning . When the images taken by different cameras are quite different , It will produce more image artifacts .
To solve this question , The author proposes a unified style UnityStyle Adaptive methods . This method can smooth the style differences between the same camera and different cameras . say concretely , First create UnityGAN To learn the style changes between cameras , Give each camera a uniform image with stable style , namely UnityStyle Images . Use UnityStyle Images to eliminate style differences between different images , send query and gallery A better match between .
The main problem
Because of the environment 、 The influence of light and other factors , The style of images taken by each camera is often different for the same person . Even the same camera , Because of the time , Take photos of different styles . therefore , The style of the image changes , Has a considerable impact on the final result .
The solution is to obtain stable feature representation between different cameras . The previous approach :
1、 The traditional methods are KISSME、DNS etc. .
2、IDE、PCB Solve by deep representation learning .
3、 Use GANs Learn the style differences between different cameras , Enhance the data by style shifting , To get CamStyle.
CamStyle Deficiency
This paper deals with the former method CamStyle Point out the shortcomings :
1、 stay CycleGAN There will be image artifacts in the generated transfer samples , Especially for the molding part , Generated a lot of wrong images .
2、 The generated image enhancement will bring noise to the system , We need to smooth regularize with labels Label Smooth Regularization(LSR) Need to adjust network performance .
3、 The generated enhancement image can only be used as the data enhancement method of the extended training set , The effect is not obvious .
4、 The number of models to be trained is C2¬C(C It's the number of cameras ), This means that with the increase of cameras , There will be more and more models to train , This doesn't apply to situations where computing power is low .
UnityGAN
For the above problems , This paper constructs a kind of UnityStyle Adaptive methods , Used to smooth style differences within the same camera and between different cameras . Author use UnityGAN To overcome CycleGAN The problem of easy deformation . utilize UnityGAN Learn from every camera style data , Get something that fits all camera styles UnityStyle Images , It makes the generated enhanced image more efficient . Last , Combine real images with UnityStyle Image as a new data enhancement training set .
UnityStyle The adaptive method has the following advantages :
1、 As a data enhancement scheme , The generated enhancement sample can be processed as the original image . therefore UnityStyle Images no longer need LSR.
2、 By adapting to different camera modes , It is also robust to the style changes in the same camera .
3、 No additional information is needed , And all the enhancements come from ReID Mission .
4、 Just training C individual UnityGAN Model , You don't need too much computing resources .
Contribution of thesis
in summary , The contribution of this paper can be summarized as :
1、 Put forward UnityStyle Method , For stable production form 、 Enhanced images of style changes , And it's equivalent to a real image , No need LSR.
2、UnityStyle There's no need to train a lot of models . It takes only a small amount of computing resources to train C A model .
Model
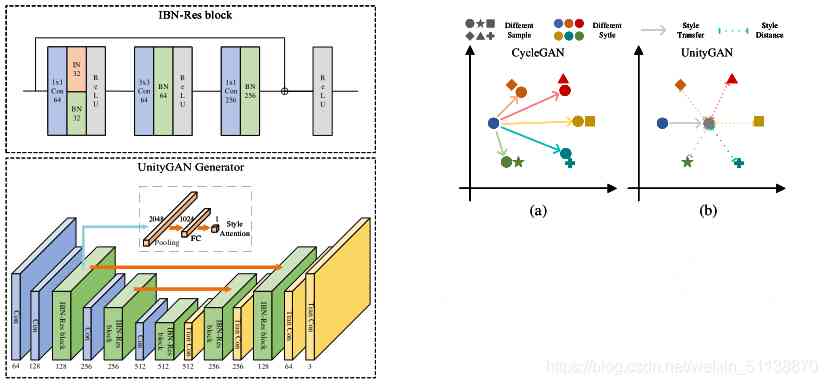
UnityGAN
UnityGAN Set up DiscoGAN and CycleGAN The advantages of , And improve it . among DiscoGAN Use standard architecture , Its narrow bottleneck layer bottleneck layer May prevent the output image from retaining visual details in the input image .CycleGAN The introduction of residual fast residual blocks To increase DiscoGAN The capacity of . However, using residual blocks at a single scale level does not preserve information at multiple scale levels .
UnityGAN Combining two networks , Introduce residual block and jump link in multi-scale layer , Multi scale information can be retained at the same time , Make changes more accurate and accurate . Through multi-scale transmission ,UnityGAN You can produce images that are structurally stable , Avoid producing images with structural errors , And CycleGAN The difference is ,UnityGAN Trying to produce a picture that blends all the styles , You don't have to learn how to transform each style .
Besides , Create a IBN-Res block , It can guarantee the structure information and enhance the robustness of style changes . stay UnityGAN Add... To the model IBN-Res block , Adapt the model to style changes , Make sure the model generates the same style of pseudo images .
Given the image field X and Y, set up G:X->Y,F:Y->X.DX and DY respectively G and F Discriminator of . In order to change the style while retaining the image feature information , The loss of identity mapping is added to the formula identity mapping loss. The loss of identity mapping can be expressed as :
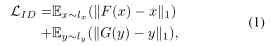
therefore ,UnityGAN The loss function of is composed of four loss normalization terms : standard GANs Loss 、 Feature matching loss 、 Loss of identity mapping and loss of loop reconstruction .
The total objective function is :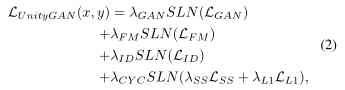
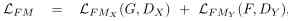
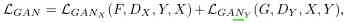
among ,SLN It's scheduling loss normalization scheduled loss normalization,
λGAN+λFM+ λID+ λCYC= 1, λSS+ λL1= 1, All the coefficients are >0.
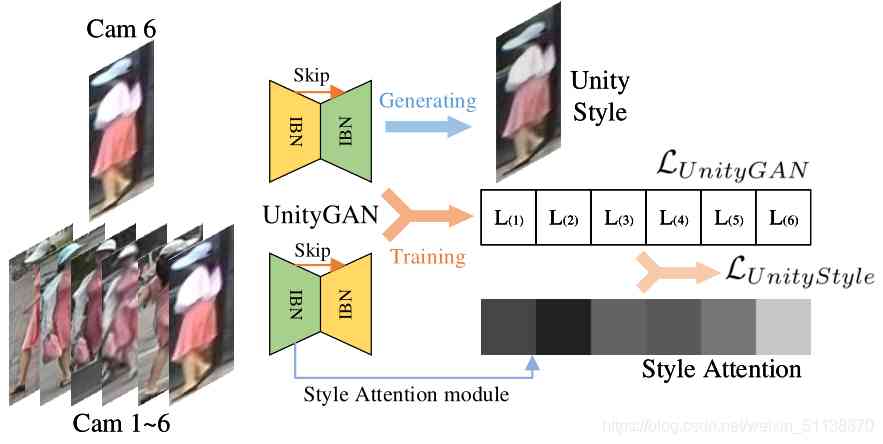
In the process of training , Use each camera and all cameras in the training set as a group to train one UnityGAN Model .UnityGAN Can produce stable structural images , Reduce the number of training models . however UnityGAN The images produced are not stable in style , To solve this problem , Put forward UnityStyle loss function , In order to ensure that UnityGAN Generate The image style is stable .
UnityStyle
UnityStyle The image is made by UnityGAN Generated , It can smooth the style differences within the same camera and between different cameras . utilize UnityStyle Image model training and prediction , Improve the performance of the model .
In order to ensure UnityGAN Can generate UnityStyle Images , The author in UnityGAN Add... To the generator Style Attention modular . Through this module , The underlying image features are obtained Style The attention characteristic of "Hua" . Define the input image x Of Style Attention by 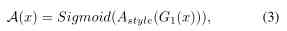
among Astyle yes Style Attention modular ,G1 yes UnityGAN The first of the generators IBN-Res Block output .
Final UnityStyle loss Function is :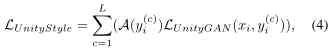
among ,c It's the camera number ,C It's the number of cameras .A(yi) It's No i There are... Cameras style attention.
Here it is loss Under the constraint of function , The model produces a stable image , The style of the image is in the middle of all camera styles .
Deep Re-ID Model
In this paper, we use IDE Examples of ways to embed them .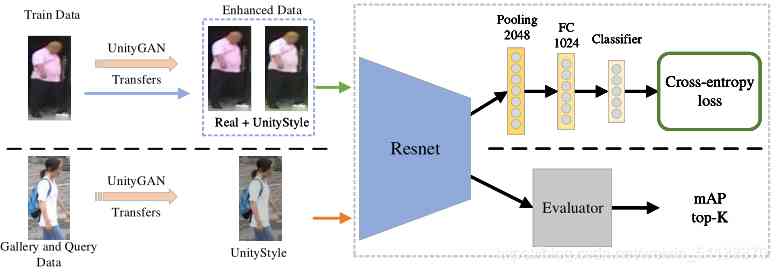
The input image size is specified as 256x128, In the process of training , It is necessary to ensure that the output of the final classification layer is consistent with the number of tags in the training set . As shown in the figure above , Replace the last classification layer with two fully connected layers . During the test , Using models 2048 Dimension feature output for evaluation .Evaluator Use the output characteristics to calculate the average accuracy (mAP) and top-K( The correct result is in K individual top Percentage of search results )
Pipeline
Training
Before training , Use the trained UnityGAN Transfers To generate UnityStyle Images . Combine real images with UnityStyle Images as enhanced training sets , In training , The image in the enhanced data volume is used as input , The size is specified as 256x128, Random sampling N A real image and N vice UnityStyle Images . According to the above definition , Get the loss function :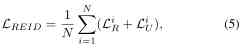
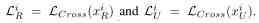
among ,xR It's a real image sample ,xU yes UnityStyle Image samples .LCross It's the cross entropy loss function .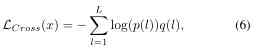
among L It's the number of tags ,p(l) yes x The tag of is predicted to be l Probability ,q(l) = {1 if l = y|0 if l 6=y} It's a real distribution , According to the previous description 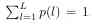
stay q(l) in ,y Is the real label corresponding to the current image .
For real labels y Of x, According to the formula (6) You can get 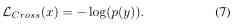
Further, according to the formula (7) And the formula (5), You can get 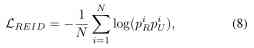
here ,piR It's No i The probability that real images will be correctly predicted ,piU It's No i individual UnityStyle The probability that the image will be correctly predicted .
Testing
For testing , It is divided into query data set and graph database data set , The introduction of UnitStyle Probability , To ensure that the images of both datasets pass before starting the test UnityStyle The corresponding transmission is generated UnityStyle Images . Use generated UnityStyle Images are tested as new input ,UnityStyle Reduces the differences between the element styles in the test set , Can further improve query performance .
summary
In my opinion, this paper is more appropriate as a data enhancement method . What you're doing seems to be enhancing data .
The core idea is through GANs Generate images to minimize style differences between cameras and within camera images .
The method is by building UnityGAN To gather images of the same pedestrian in all cameras to generate images that match different styles of all cameras , Where image generation is UnityStyle constraint , And then generate UnityStyle Images and real images are used as enhanced data sets to train the model . Use... In the prediction phase UnityGAN To generate pseudo images in accordance with the model style for prediction . It is equivalent to data preprocessing in training and testing .
版权声明
本文为[osc_dc6pbw3x]所创,转载请带上原文链接,感谢
边栏推荐
- [论文阅读笔记] Large-Scale Heterogeneous Feature Embedding
- LeetCode:数组(一)
- Looking for a small immutable dictionary with better performance
- 2020-11-07
- ASP.NET Core framework revealed
- [paper reading notes] a multilayered informational random walk for attributed social network embedding
- C + + STL container
- Notes on Python cookbook 3rd (2.4): string matching and searching
- Call the open source video streaming media platform dawinffc
- GNU assembly basic mathematical equations multiplication
猜你喜欢

高通骁龙875夺安卓处理器桂冠,但外挂5G基带成为它的弊病
LeetCode 5561. 获取生成数组中的最大值

One task is not enough, but another valuetask. I'm really confused!
One of the 10 Greatest formulas in the world is well known
[operation tutorial] introduction and opening steps of easygbs subscription function of national standard gb28181 protocol security video platform
【技术教程】C#控制台调用FFMPEG推MP4视频文件至流媒体开源服务平台EasyDarwin过程
《Python Cookbook 3rd》笔记(2.3):用Shell通配符匹配字符串

Why should small and medium sized enterprises use CRM system
微服务授权应该怎么做?
带劲!饿了么软件测试python自动化岗位核心面试题出炉,你全程下来会几个?
随机推荐
[C.NET] 11: the most basic thread knowledge
What should be paid attention to when designing API to get data through post
高通骁龙875夺安卓处理器桂冠,但外挂5G基带成为它的弊病
[operation tutorial] introduction and opening steps of easygbs subscription function of national standard gb28181 protocol security video platform
ASP.NET Core framework revealed [blog Summary - continuous update]
js 基础算法题(一)
Why use it cautiously Arrays.asList , sublist of ArrayList?
Looking for a small immutable dictionary with better performance
刷题到底有什么用?你这么刷题还真没用
MFC界面开发帮助文档——BCG如何在工具栏上放置控件
[论文阅读笔记] Community-oriented attributed network embedding
腾讯云TBase在分布式HTAP领域的探索与实践
First acquaintance of file
Understanding recursion with examples
Sign in with apple
奸商加价销售mate40,小米可望在高端手机市场夺取更多市场
中小企业为什么要用CRM系统
ASP.NET Core框架揭秘[博文汇总
getIServiceManager() 源码分析
Notes on Python cookbook 3rd (2.4): string matching and searching