当前位置:网站首页>BEVDetNet: Bird's Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Drivi
BEVDetNet: Bird's Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Drivi
2022-07-29 23:57:00 【byzy】
BEVDetNet: Bird's Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Driving 论文笔记
原文链接:https://arxiv.org/pdf/2104.10780.pdf
I 引言
Current research focuses on detection accuracy,And ignore the delay、Storage space and computational complexity requirements.
Traditional detection methods voxelize point clouds,使用3D卷积处理.Later improvements such asPointPillars虽使用2DConvolution increases speed,However, preprocessing operations are still introduced.3DUse of anchor boxes、And the time and space requirements for non-maximum suppression operations are high.
The performance of our method is only comparablePointPillars低2%,但速度是其5倍.A segmentation network is proposed,The center point of the output object(作为关键点)、The bounding box parameter regression value,And the heading angle interval classification result.The network is mixedResNet和膨胀卷积,And the optimal network structure is determined by ablation study.
III 方法
A.BEV表达
手工编码,每个BEVThe grid is characterized by the maximum height of the points it contains、占用值(a little bit1,否则为0)and intensity encoding.
B.网络结构
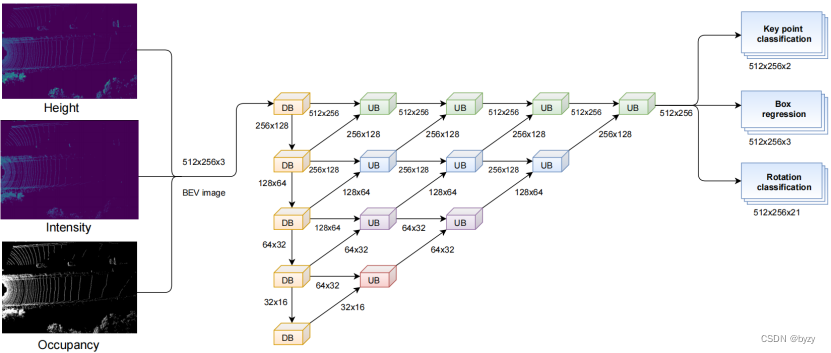
The network contains a segmentation network for feature extraction as well3个预测头.
分割网络Use deep aggregation(DLA)风格的网络(称为混合DLA结构)to provide feature maps at different spatial resolutions and at different levels.其中,编码器由5feature extraction and downsampling blocks(DB)组成;The decoder contains the same number of feature aggregation and upsampling blocks(UB).
下采样块:
如下图所示,DB是修改的ResNet,有两个输出,One is the same as the input spatial resolution,And the other is half of the input,通过均值池化实现下采样,Because mean pooling is more suitable for preserving overall contextual features than max pooling.

The expressive power of the initial convolutional layer is severely reduced due to the unoccupied pixels,本文使用SqueezesegV2defined in the networkContext aggregation module(CAM),And replace the max pooling with large kernels均值池化,Reduce the chance of encountering unoccupied windows.仅在前3个DB中使用CAM,因为后面的DB有更大的感受野,Unoccupied pixels have less impact.
Using larger receptive field kernels can extract better context-aware features,Thereby facilitating keypoint detection.使用膨胀卷积The receptive field can be increased without increasing the amount of parameters,And it is very effective for feature extraction of small and crowded objects.
上采样块:
如下图所示.UBUse transposed convolution and regular convolution+ReLU+BN结构,Collect low-level and high-level features from different levels,Fusion is performed by concatenation or addition.

3个预测头are used for keypoint classification respectively(Centers and Categories)、Bounding box size regression and rotation prediction for each keypoint group(as an interval classification task).
本文将关键点Defined as the center of the object on the ground plane.KITTIonly provides annotations for object centers on the image,This article first converts it to a point cloud,然后投影到BEV下.
Due to the large amount of computation in the segmentation network,需要进行改进.The method in this paper only classifies the object keypoint pixels,And other segmentation categories such as roads and vegetation can be added.
C.损失函数
The total loss is the keypoint classification、Weighted sum of bounding box size regression and rotation classification loss.
关键点分类:Use weighted cross-entropy loss to deal with class imbalance.即

其中 是类别
是类别 的出现频率,
的出现频率, is the true class of pixels,
is the true class of pixels, is the predicted category(概率).
is the predicted category(概率).
The article here is not clear,It feels like it should be(类别数+1)个类别,Represents categories of keypoints and categories that are not keypoints.
Bounding box size regression:回归目标为对数值.使用下列SmoothL1损失:

其中 is the difference between the predicted value and the true value.
is the difference between the predicted value and the true value.
The object center position is directly given by the keypoint,Its resolution is affectedBEVImage resolution limit,Can be refined using additional center offset regression headers.
Rotation interval classification:Considering the classification task is more suitable for segmentation network,Therefore, this paper uses interval classification.Use the same weighted cross-entropy loss as the keypoint classification loss.to reduce the number of intervals,Orientation is ignored,while limiting the orientation angle to 0到180°之间(如45°和-135°均视为45°).Then the task is to classify each set of key points and their receptive fields into orientation intervals(An additional interval is added for the background points).
D.后处理
Under the assumption that the bounding boxes do not overlap,The remaining keypoints in adjacent regions are removed using distance threshold based non-maximum suppression.Finally set the keypoint pixel coordinates 投影回3D空间
投影回3D空间 :
:

其中 为BEV分辨率.
为BEV分辨率. Coordinates can be obtained from keypoint pixel values(Because the pixel value contains height information,见III.A).
Coordinates can be obtained from keypoint pixel values(Because the pixel value contains height information,见III.A).
IV.实验
A.实验设置
Use data augmentation such as horizontal flip、Rotate a small angle globally,And sampling-based object augmentation.
B.Metrics and performance comparisons
本文使用基于 的AP指标,Performance is only comparablePointPillars低2%但速度快很多.如使用
的AP指标,Performance is only comparablePointPillars低2%但速度快很多.如使用 的AP指标,The worse will be more,It may be that the complexity required for precise positioning is higher.
的AP指标,The worse will be more,It may be that the complexity required for precise positioning is higher.
C.消融研究
(1)Different segmentation network structures are compared,This article was confirmed to be mixedDLAThe advantages of structure in performance and speed.
(2)The weighted cross-entropy loss sum for classification tasks is comparedfocal损失,and return tasksL1损失和SmoothL1损失.Find the sum of weighted cross-entropy lossesSmoothL1The combination of losses is the best.
(3)Comparisons were made with quantized models with reduced accuracy.量化精度越低,速度越快,But the accuracy has decreased.Accuracy degradation can be reduced by quantization-aware training.
D.失效情况
(1)Caused when the points of the object are sparseBEVWhen there are few pixels in the image,会出现漏检.Using data augmentation to increase the corresponding amount of data for training results in more false detections.Perhaps preprocessing with deep completion methods can solve this problem.
(2)容易产生Incorrect estimation of object center.Because of the simplicity of the model,The object center is selected from a set of keypoints,Sometimes adjacent pixels are selected.This error is projected back3Dspace will increase.增加BEVResolution can alleviate this problem,But it will introduce more inference time.
边栏推荐
猜你喜欢

Codeforces Round #805 (Div. 3)总结

Apache Doris 1.1 特性揭秘:Flink 实时写入如何兼顾高吞吐和低延时

Mysql8.0新特性之详细版本

Why does LabVIEW freeze when saving a VI

WLAN笔记
论文精读——YOLOv3: An Incremental Improvement

MySQL 用 BETWEEN AND 日期查询包含范围边界

rk-boot framework combat (1)

「大厂必备」系列之Redis主从、持久化、哨兵

go语言(函数、闭包、defer、panic/recover,递归,结构体,json序列化与反序列化)
随机推荐
关于 byte 的范围
Design for failure 12 common design ideas
【openlayers】Map【1】
Elephant Swap:借助ePLATO提供加密市场的套利空间
MySQL 用 BETWEEN AND 日期查询包含范围边界
全国双非院校考研信息汇总整理 Part.2
vim相关介绍(二)
Adaptive feature fusion pyramid network for multi-classes agriculturalpest detection
月薪15k的阿里测试岗,面试原来这么简单
UE4 制作十字准心+后坐力
Docker install MySQL8.0
JVM初探- 内存分配、GC原理与垃圾收集器
Mysql8.0新特性之详细版本
Prometheus 的功能特性
环形链表(LeetCode 141、142)
NumPy(二)
管理区解耦架构见过吗?能帮客户解决大难题的
综合练习——三子棋小游戏
UE4 makes crosshair + recoil
C陷阱与缺陷 第4章 链接 4.5 检查外部类型