当前位置:网站首页>[transform] [practice] use pytoch's torch nn. Multiheadattention to realize self attention
[transform] [practice] use pytoch's torch nn. Multiheadattention to realize self attention
2022-07-03 15:01:00 【Hali_ Botebie】
Self-Attention Structure diagram
This paper focuses on Pytorch Chinese vs self-attention The concrete practice of , The specific principle will not be explained in detail ,self-attention Please refer to the following figure for the specific structure of .
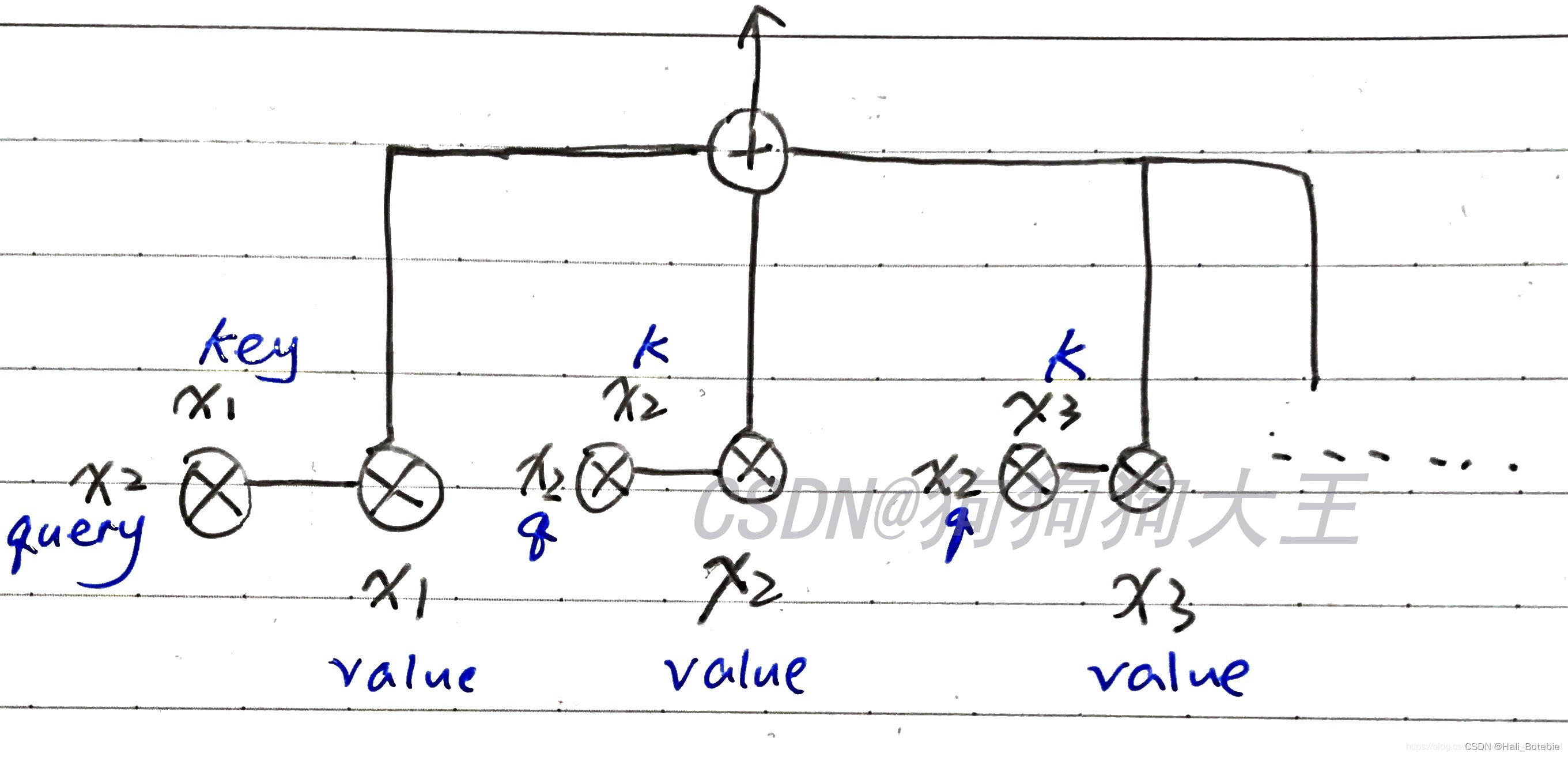
( The second item of output is shown in the figure attention output The situation of ,k And q by key、query Abbreviation )
This article will use Pytorch Of torch.nn.MultiheadAttention To achieve self-attention.
So-called multihead-attention It's right KQV Parallel computing in parallel . The original attention It 's a direct calculation “ Word vector length ( dimension ) Vector ”, and Multi First of all “ Word vector length ( dimension ) Vector ” adopt linear layer , Quantile h individual head Calculation attention, And then put these attention When connected together , One more pass linear Layer output . It can be seen that ,linear The input and output dimensions of the layer are “ Word vector length ( dimension )”.

As you can see from the picture V K Q Is a fixed single value , and Linear Layer has a 3 individual ,Scaled Dot-Product Attention Yes 3 individual , namely 3 Multiple heads ; Last cancat together , then Linear The layer conversion becomes the same output value as the single header ; Similar to integration ; The difference between multiple heads and single heads is to copy multiple single heads , But the weight coefficient is definitely different ; It is analogous to a neural network model and multiple neural network models , But because the initialization is different , It will lead to different weights , Then the results are integrated ;( Preliminary understanding )
The long function shows :multihead-attention The function input is the original Q,K,V Turned into Q W , K W , V W Q^W,K^W,V^W QW,KW,VW; namely 3 individual W Are different ; take Q,K,V From the original 512 The dimension becomes 64 dimension ( Because of the adoption of 8 Multiple heads ); Then they are spliced together to become 512 dimension , Through linear transformation ; Get the final long attention value ;
I finally think : The essence of bulls is multiple independent attention Calculation , As an integration , Prevent over fitting ; from attention is all your need The input sequence in the paper is exactly the same ; same Q,K,V, Through linear transformation , Each attention mechanism function is responsible for only one subspace in the final output sequence , namely 1/8, And independent of each other ;
Bull in micro Attention It can be expressed as :

KQV

forward In input query、key、value
First , The first three inputs are the most important part query、key、value. From the figure 1 You know , We self-attention These three things are actually the same , They're all in the shape of :(L,N,E) .
L: Input sequence The length of ( For example, the length of a sentence )
N: Batch size ( For example, the number of sentences in a batch )
E: Word vector length
forward Output
The output content is very few, only two :
attn_output
That is, through self-attention after , Output from each word position attention. Its shape is (L,N,E), Yes and input query They have the same shape . Because after all, it's just for value Took a weight.attn_output_weights
namely attention weights, The shape is (N,L,L), Because every word and any other word will produce a weight, So every sentence weight The number is L*L
Instantiate a nn.MultiheadAttention
Here to MultiheadAttention Instantiate and pass in some parameters , What we get after instantiation can be passed into it input 了 .
The code when instantiating :
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
among ,embed_dim Is the original word vector length of each word ;num_heads It is our MultiheadAttention Of head The number of .
( About embedding What is it? ? You can read another article Blog ,nn.Embedding Have a weight (.weight), The shape is (num_words, embedding_dim).Embedding Input shape N×W,N yes batch size,W It's the length of the sequence , The output shape is N×W×embedding_dim. For example, there is only one sample , The length of a sentence is 10 Word , Every word uses 256 Dimension vector representation , The corresponding weight is a 10×256 Matrix , The output shape is 1 × 10 × 256, be embed_dim The length of the original word vector of each word is 256 )
pytorch Of MultiheadAttention What should be used is Narrow self-attention Mechanism , namely , hold embedding Divided into num_heads Share , Make each one separately attention.
( for example ,embed_dim yes 256,num_heads yes 8, Will be divided into 8 Share , The dimension of each share is 32)
in other words :
- word 1 The first of 、 word 2 The first of 、 word 3 The first of … Will be regarded as a sequence, Do our chart once 1 Shown self-attention.
- then , word 1 The second of 、 word 2 The second of 、 word 3 The second of … I will also do it once
- Until the word 1 Of the num_heads Share 、 word 2 Of the num_heads Share 、 word 3 Of the num_heads Share … Also done self-attention
We will get one from every one (L,N,E/num_heads) Shape output , We put all these concat together , You'll get one (L,N,E) Tensor .
( for example . Every one self attention Get one 10 × 1 × 32,concat Get back 10×1×256 Tensor )
Now , Let's take a matrix , Change the dimension of this tensor back to (L,N,E) Can be output .
Conduct forward operation
Let's instantiate what we just instantiated multihead_attn Carry on forward operation ( The input input obtain output):
attn_output, attn_output_weights = multihead_attn(query, key, value)
About mask
mask It can be understood as a mask 、 Mask , The function is to help us “ Occlusion ” Lose what we don't need , That is, let the blocked things not affect our attention The process .
stay forward When , There are two mask Parameters can be set :
key_padding_mask
every last batch The length of each sentence of is generally impossible to be exactly the same , So we will use padding Fill up some vacancies . And this one here key_padding_mask It's for “ Occlusion ” these padding Of .
This mask It's binary (binary) Of , in other words , It is a matrix and we key It's the same size , The value in it is 1 or 0, Let's get key There is padding The location of , And then put mask The number in the corresponding position in the is set to 1, such attention It will key The corresponding part becomes "-inf". ( Why become -inf We'll talk about it later )attn_mask
This mask It is often used to cover “ right key ” Of :
Suppose you want to use this model to predict the next word at a time , In every position of ours attention How does the output come from ? Do you want to see the whole sequence , Then calculate one for each word attention weight? That means , You are predicting 5 A word , You'll actually see the whole sequence , In this case, you already know the number before you predict 5 What is a word , This is cheating .
We don't want the model to cheat , Because when this model is actually used to predict , We don't have the information of the whole sequence . So what to do ? Then let the first 5 A word of attention weight=0 Well , That is to say : I don't want to see this word , Don't give it my attention at all .
How to make this weight=0:
Let's imagine , What we currently have attention scores What does it look like ?( notes :attention_score yes attention_weight The initial appearance of , after softmax And then it becomes attention_weight.
attention_score and weight The shape of is the same , After all, there's only one softmax The difference between )
We mentioned earlier ,attention weights The shape of is L*L, Because every word has one between two weight.
As shown in the figure below , The part I circled with a blue pen , Namely “ I want to predict x 2 x_2 x2” when , Whole sequence Of attention score situation . Where I crossed out with a fork , It's our hope that =0 The location of , Because we want x 2 、 x 3 、 x 4 x_2、x_3、x_4 x2、x3、x4 A weight of 0, namely : forecast x 2 x_2 x2 When , Our attention can only be focused on x 1 x_1 x1 On .
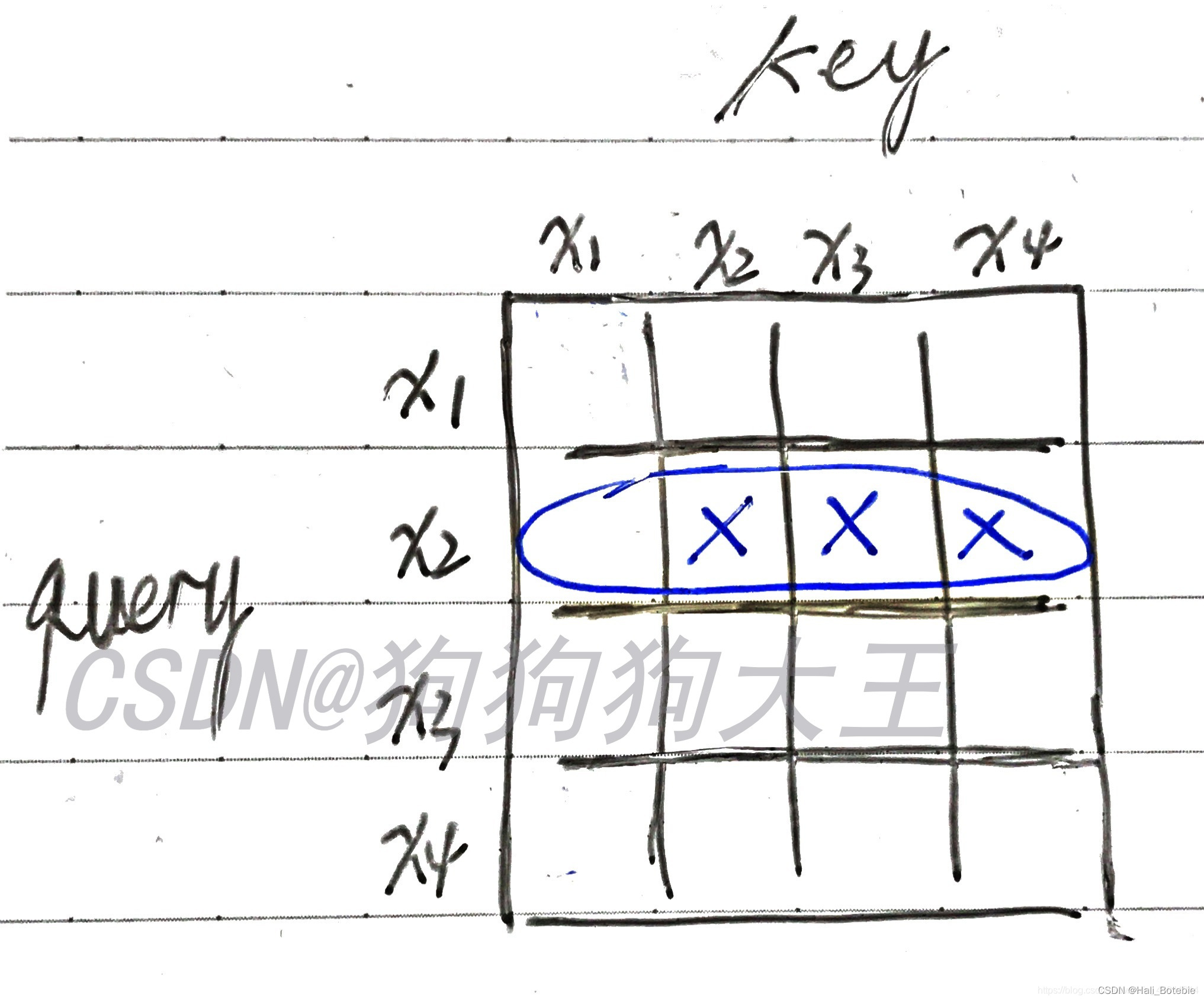
For other lines , You can analogy , It is found that we need a triangle area attention weight=0, At this time, our attn_mask At this time, I came out , Put this mask Make it into a triangle .
About mask A digression of :
Some friends are curious about why they see pictures in some places mask There is no diagonal , I think it's because sequence Different or training tasks / In a different way , But essentially mask The principle is the same . I'll find another picture to help you understand , For example, if you add s(start) and e(end) Is similar to this :( White is mask The missing part )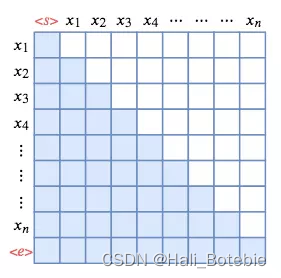
mask Value (additive mask)
Now let's talk about mask Value . and key_padding_mask Different , our attn_mask No binary Of , It is a “additive mask”.
What is? additive mask Well ? It's us mask The value set on , Will be Add to Our original attention score On . We want to make the triangle region weight=0, Our triangle mask What value should be set ? The answer is -inf,( This -inf stay key_padding_mask Also appeared in the explanation of , Here's why we use -inf). We mentioned above ,attention score It's going through a softmax It becomes attention_weights.
We all know softmax The formula of can be expressed as 
When we attention score Is set to -inf ( It can be seen as z j = − inf z_j=-\inf zj=−inf, So through softmax And then our attention weight Will approach 0 了 , That's why the two of us here mask All need to be used. -inf.
Reference resources
Baidu library 【pytorch series 】nn.MultiheadAttention Detailed explanation
边栏推荐
- 创业团队如何落地敏捷测试,提升质量效能?丨声网开发者创业讲堂 Vol.03
- Dllexport et dllimport
- C language to realize mine sweeping
- Besides lying flat, what else can a 27 year old do in life?
- Zzuli:1055 rabbit reproduction
- Byte practice plane longitude 2
- Simulation of LS -al command in C language
- [ue4] material and shader permutation
- 链表有环,快慢指针走3步可以吗
- [wechat applet] wxss template style
猜你喜欢
零拷贝底层剖析
High quality workplace human beings must use software to recommend, and you certainly don't know the last one
Dllexport et dllimport
Bucket sorting in C language
![[ue4] material and shader permutation](/img/8f/7743ac378490fcd7b9ecc5b4c2ef2a.jpg)
[ue4] material and shader permutation
![[engine development] in depth GPU and rendering optimization (basic)](/img/71/abf09941eb06cd91784df50891fe29.jpg)
[engine development] in depth GPU and rendering optimization (basic)
![[graphics] efficient target deformation animation based on OpenGL es 3.0](/img/53/852ac569c930bc419846ac209c8d47.jpg)
[graphics] efficient target deformation animation based on OpenGL es 3.0

el-switch 赋值后状态不变化

4-20-4-23 concurrent server, TCP state transition;

To improve efficiency or increase costs, how should developers understand pair programming?
随机推荐
Yolov5进阶之八 高低版本格式转换问题
第04章_逻辑架构
QT - draw something else
My QT learning path -- how qdatetimeedit is empty
Troubleshooting method of CPU surge
C language DUP function
4-20-4-23 concurrent server, TCP state transition;
C language to implement a password manager (under update)
[graphics] hair simulation in tressfx
Yolov5进阶之七目标追踪最新环境搭建(二)
Center and drag linked global and Chinese markets 2022-2028: Research Report on technology, participants, trends, market size and share
Zzuli:1044 failure rate
Solve the problem that PR cannot be installed on win10 system. Pr2021 version -premiere Pro 2021 official Chinese version installation tutorial
Zzuli:1055 rabbit reproduction
Pytorch深度学习和目标检测实战笔记
Déformation de la chaîne bm83 de niuke (conversion de cas, inversion de chaîne, remplacement de chaîne)
There are links in the linked list. Can you walk three steps faster or slower
dllexport和dllimport
Zzuli:1059 highest score
牛客 BM83 字符串变形(大小写转换,字符串反转,字符串替换)