当前位置:网站首页>2022 T2i text generated image Chinese Journal Paper quick view-1 (ecagan: text generated image method based on channel attention mechanism +cae-gan: text generated image technology based on transforme
2022 T2i text generated image Chinese Journal Paper quick view-1 (ecagan: text generated image method based on channel attention mechanism +cae-gan: text generated image technology based on transforme
2022-07-27 04:56:00 【Medium coke with ice】
2022 year T2I Text generated images Quick view of Chinese Journal Papers -1
One 、ECAGAN: Text image generation method based on channel attention mechanism
Source of the article : Computer engineering 2022 year 4 month
Citation format : Zhang Yunfan , Yi Yaohua , Tang Ziwei , Wang Xinyu . Text image generation method based on channel attention mechanism [J]. Computer engineering ,2022,48(04):206-212+222.DOI:10.19678/j.issn.1000-3428.0062998.
1.1、 Major innovations
In the task of generating images for text The details of the generated image are missing And There is a structural error in the image generated in the low resolution stage ( If a bird has two heads , Lack of claws ) The problem of , Generate confrontation network based on dynamic attention mechanism (DMGAN), Introduce content aware upsampling module and channel attention convolution module , A new method of text image generation is proposed ECAGAN.
The main innovations are :
- Adopt content aware up sampling method , The reconstructed convolution kernel is obtained by calculating the input characteristic graph , The convolution operation is carried out by using the reconstructed convolution kernel and the characteristic graph , Ensure semantic alignment ;
- Use the channel attention mechanism to learn the importance of each feature channel of the feature map , Highlight important feature channels , Suppress invalid information , Enrich the details of the generated image ;
- Combined with condition enhancement and perceptual loss function auxiliary training , Enhance the robustness of the training process .
1.2、 Main framework

The main structure is still similar StackGAN++ Three layer stacking , The network structure can be divided into Low resolution image generation stage and image refining stage , Generator generation in low resolution image generation stage 64×64 Pixel low resolution image , Generator generation in image refining stage 128×128 Pixels and 256×256 Pixel image .
1.2.1、 Low resolution image generation stage
Text encoder stage and StackGAN、AttnGAN、DMGAN And so on , Generate sentence features and word features through text encoder , The sentence features are stitched together after random noise FC Input to Content aware upsampling module (CAUPBlock) in , The first stage image is formed after up sampling the input feature map .
Content aware upsampling module It consists of an adaptive convolution kernel prediction module and a content aware feature reorganization module :
Adaptive convolution In the nuclear prediction module , The feature map passes through the content encoder ,Reshape And normalized to a size of S H × S W × k u p 2 SH × SW × k^2_{up} SH×SW×kup2 Recombined convolution kernel of . Content aware feature reorganization module Simply put, it is to dot product each region of the feature map with the corresponding predicted convolution kernel .
Structure diagram is as follows , Characteristics of figure R After input, in the adaptive convolution kernel prediction module ψ in
For output characteristic graph R′ Every area of l′ Predict the convolution kernel γ l γ_l γl, Then the original feature map is in the content aware feature reorganization module ξ Neutralize the predicted convolution kernel and dot multiply to get the result γ l ′ = ψ ( Z ( R l , k e n c o d e r ) ) R l ′ ′ = ξ ( Z ( R l , k u p ) , γ l ′ ) \begin{array}{l} \gamma_{l^{\prime}}=\psi\left(Z\left(R_{l}, k_{\mathrm{encoder}}\right)\right) \\ R_{l^{\prime}}^{\prime}=\xi\left(Z\left(R_{l}, k_{\mathrm{up}}\right), \gamma_{l^{\prime}}\right) \end{array} γl′=ψ(Z(Rl,kencoder))Rl′′=ξ(Z(Rl,kup),γl′), among Z ( R l , k u p ) Z(R_l,k_{up}) Z(Rl,kup) Represents the midpoint of the feature map l The surrounding k u p × k u p k_{up}×k_{up} kup×kup Sub areas of .
After up sampling, the characteristic graph is input into the generator , After convolution operation with channel attention mechanism, the image is generated .
The attention convolution module weights the feature map through channel attention , Make the generated image more detailed , The realization of channel attention will not be repeated , See the original text for details .
1.2.2、 Image refining stage

Image refining stage and AttnGAN Very similar , The dynamic attention layer is used to calculate the correlation between each word in the word vector and the image sub region , Then calculate the attention weight of the image sub region according to the Correlation , Finally, the update of the feature map is controlled according to the attention weight of the feature map , Get a new feature map and then upsampling , Zoom in on the image .( Three methods that can effectively fuse text and image information second )
1.3、 Loss function
The generator loss function is in the form of :
L G = ∑ ( L G i + λ 1 L p e r ( I i ′ , I i ) ) + λ 2 L C A + λ 3 L D A M S M L_{G}=\sum\left(L_{G_{i}}+\lambda_{1} L_{\mathrm{per}}\left(I_{i}^{\prime}, I_{i}\right)\right)+\lambda_{2} L_{\mathrm{CA}}+\lambda_{3} L_{\mathrm{DAMSM}} LG=∑(LGi+λ1Lper(Ii′,Ii))+λ2LCA+λ3LDAMSM
L G i L_{Gi} LGi Represents the loss function of generators at all levels ; L p e r L_{per} Lper Represents the perceived loss function ; L C A L_{CA} LCA Represents the conditional enhancement loss function ; L D A M S M L_{DAMSM} LDAMSM Express DAMSM Module loss function .
L G i = − 1 2 E x ∼ p ϵ [ log a D i ( x i ^ ) ] ⏟ unconditional loss − 1 2 E x ∼ p σ , [ log a D i ( x ^ i , s ) ] ⏟ conditional loss L_{G_{i}}=\underbrace{-\frac{1}{2} E_{x \sim p_{\epsilon}}\left[\log _{a} D_{i}\left(\widehat{x_{i}}\right)\right]}_{\text {unconditional loss }} \underbrace{-\frac{1}{2} E_{x \sim p_{\sigma},}\left[\log _{a} D_{i}\left(\widehat{x}_{i}, s\right)\right]}_{\text {conditional loss }} LGi=unconditional loss −21Ex∼pϵ[logaDi(xi)]conditional loss −21Ex∼pσ,[logaDi(xi,s)]
L D i = − 1 2 E x ∼ p datu log a D i ( x i ) − 1 2 E x ∼ p σ i log a ( 1 − D i ( x i ^ ) ) ⏟ unconditional loss − 1 2 E x ∼ p datu log a D i ( x i , s ) − 1 2 E x ∼ p σ i log a ( 1 − D i ( x ^ i , s ) ) ⏟ conditional loss \begin{array}{l} L_{D_{i}}= \\ \underbrace{-\frac{1}{2} E_{x \sim p_{\text {datu }}} \log _{a} D_{i}\left(x_{i}\right)-\frac{1}{2} E_{x \sim p_{\sigma_{i}}} \log _{a}\left(1-D_{i}\left(\widehat{x_{i}}\right)\right)}_{\text {unconditional loss }} \\ \underbrace{-\frac{1}{2} E_{x \sim p_{\text {datu }}} \log _{a} D_{i}\left(x_{i}, s\right)-\frac{1}{2} E_{x \sim p_{\sigma_{i}}} \log _{a}\left(1-D_{i}\left(\widehat{x}_{i}, s\right)\right)}_{\text {conditional loss }} \end{array} LDi=unconditional loss −21Ex∼pdatu logaDi(xi)−21Ex∼pσiloga(1−Di(xi))conditional loss −21Ex∼pdatu logaDi(xi,s)−21Ex∼pσiloga(1−Di(xi,s))
L C A = D K L ( N ( μ ( s ) , Σ ( s ) ) ∥ N ( 0 , I ) ) \begin{array}{l} L_{\mathrm{CA}}=D_{\mathrm{KL}}(\mathcal{N}(\boldsymbol{\mu}(\boldsymbol{s}), \boldsymbol{\Sigma}(\boldsymbol{s})) \| \mathcal{N}(0, I))\end{array} LCA=DKL(N(μ(s),Σ(s))∥N(0,I))
L p e r ( I ′ , I ) = 1 C i H i W i ∥ ϕ i ( I ′ ) − ϕ i ( I ) ∥ 2 2 \begin{array}{l}L_{\mathrm{per}}\left(I^{\prime}, I\right)=\frac{1}{C_{i} H_{i} W_{i}}\left\|\phi_{i}\left(I^{\prime}\right)-\phi_{i}(I)\right\|_{2}^{2} \end{array} Lper(I′,I)=CiHiWi1∥ϕi(I′)−ϕi(I)∥22
1.4、 experiment



Two 、CAE-GAN: be based on Transformer Cross attention text generation image technology
Source of the article : Computer science 2022 year 2 month
Citation format : Tan Xinyue , He Xiaohai , Wang Zhengyong , Luo Xiaodong , Sparkling waves . be based on Transformer Cross attention text generation image technology [J]. Computer science ,2022,49(02):107-115.
2.1、 Major innovations
at present , The mainstream method is to complete the encoding of the input text description by pre training the text encoder , but Current methods encode text descriptions , The mapping relationship with the corresponding image is not considered , Ignoring the semantic gap between language space and image space , As a result, the matching degree between the generated image and the text semantics in the initial stage is still low , And the image quality is also affected .
Innovation points :
Through the cross attention encoder , Translate and align text information with visual information , To capture the cross modal mapping relationship between text and image information , So as to improve the fidelity of the generated image and the matching degree with the input text description .
2.2、 Main framework
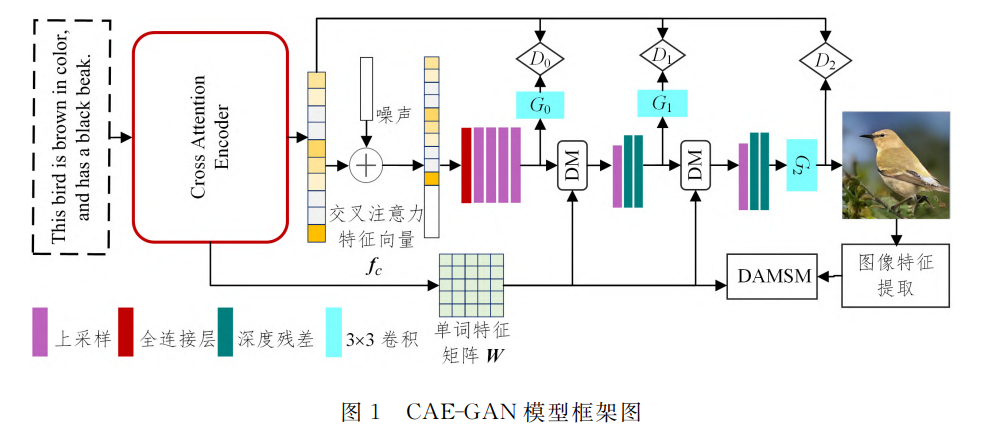
Pictured above , The text first passes through the cross attention encoder , Generate cross attention eigenvectors f c f_c fc And word feature matrix W, The cross attention feature vector is fully connected after adding noise 、 Initial image features are formed in the upper sampling stage , Then word characteristic matrix W Input to dynamic memory module and fuse with primary image features , Get the new image features after fusion , The process is as follows :
f c , W = C E ( s , F R ) F 0 = G 0 ( f c + z ) F 1 = G 1 ( D M ( F 0 , W ) ) F 2 = G 2 ( D M ( F 1 , W ) ) \begin{array}{l} \boldsymbol{f}_{c}, \boldsymbol{W}=C_{E}\left(\boldsymbol{s}, \boldsymbol{F}_{R}\right) \\ \boldsymbol{F}_{0}=G_{0}\left(\boldsymbol{f}_{c}+\boldsymbol{z}\right) \\ \boldsymbol{F}_{1}=G_{1}\left(D M\left(\boldsymbol{F}_{0}, \boldsymbol{W}\right)\right) \\ \boldsymbol{F}_{2}=G_{2}\left(D M\left(\boldsymbol{F}_{1}, \boldsymbol{W}\right)\right) \end{array} fc,W=CE(s,FR)F0=G0(fc+z)F1=G1(DM(F0,W))F2=G2(DM(F1,W))
2.2.1、 Cross attention coder
Cross attention coder is used for joint cross coding and alignment of language information and visual information . As shown in the figure below :
It mainly includes text feature extraction 、 Image feature extraction 、 Cross attention coding and self attention coding :
Text feature extraction , Use two-way LSTM Encode the original text into a global sentence feature vector W And a word eigenvector s;
Image feature extraction , Use InceptionV3 The Internet Extraction of image features f c f_c fc;
Cross attention code , It is mainly used to construct the internal relationship between language features and image features , Realize joint coding . Word eigenvector s And image features f c f_c fc They are mapped into q s , k s , v s , q v , k v , v v q_s,k_s,v_s,q_v,k_v,v_v qs,ks,vs,qv,kv,vv, namely q s , k s , v s = L i n e a r ( s ) , q v , k v , v v = ( f v ) q_s,k_s,v_s=Linear(s),q_v,k_v,v_v=(f_v) qs,ks,vs=Linear(s),qv,kv,vv=(fv), Then calculate the cross attention score score, Then get the attention code l c l_c lc
score = λ c q v k s T score = Softm ( score ) s c = dropout ( score ′ ) l = s c ⋅ v s , l c = N o r m a l i z a t i o n ( A 1 l + B 1 ) \begin{array}{l} \text { score }=\lambda_{c} \boldsymbol{q}_{v} \boldsymbol{k}_{s}^{\mathrm{T}} \\ \text { score }=\operatorname{Softm}(\text { score }) \\ \boldsymbol{s}_{c}=\operatorname{dropout}\left(\text { score }{ }^{\prime}\right) \\ \boldsymbol{l}=\boldsymbol{s}_{c} \cdot \boldsymbol{v}_{s} ,l_c=Normalization(A_1l+B_1)\end{array} score =λcqvksT score =Softm( score )sc=dropout( score ′)l=sc⋅vs,lc=Normalization(A1l+B1)Self attention encoding , The main use is still Self attention mechanism babbling , I won't repeat
q l , k l , v l = Linear ( l c ) s s = Dropout ( softm ( λ s q l k l T ) ) l c s = s s ⋅ v l f c = Normalization ( A 2 l c s + B 2 ) \begin{array}{l} \boldsymbol{q}_{l}, \boldsymbol{k}_{l}, \boldsymbol{v}_{l}=\text { Linear }\left(\boldsymbol{l}_{c}\right) \\ \boldsymbol{s}_{s}=\operatorname{Dropout}\left(\operatorname{softm}\left(\lambda_{s} \boldsymbol{q}_{l} \boldsymbol{k}_{l}^{\mathrm{T}}\right)\right) \\ \boldsymbol{l}_{c s}=\boldsymbol{s}_{s} \cdot \boldsymbol{v}_{l} \\ \boldsymbol{f}_{c}=\operatorname{Normalization}\left(A_{2} \boldsymbol{l}_{c s}+B_{2}\right) \end{array} ql,kl,vl= Linear (lc)ss=Dropout(softm(λsqlklT))lcs=ss⋅vlfc=Normalization(A2lcs+B2)
2.2.2、 Dynamic enclosure

Dynamic enclosure and DM-GAN The internal dynamic memory mechanism is similar .
2.3、 Loss function
The global loss function L Divided into three parts , The total loss function is as follows :
L = ∑ i L G i + τ 1 L C A + τ 2 L D A M S M L=\sum_{i} L_{G^{i}}+\tau_{1} L_{C A}+\tau_{2} L_{D A M S M} L=∑iLGi+τ1LCA+τ2LDAMSM
among L G i L_{G^i} LGi Is the generator loss , L C A L_{CA} LCA Is the conditional loss function , L D A M S M L_{DAMSM} LDAMSM It is the loss of deep attention multimodal similarity ( And AttnGAN be similar )
L G i = − 1 2 [ E x ∼ p G i log D i ( x ) + E x ∼ p G i log D i ( x , s ) ] L C A = D K L ( N ( μ ( s ) ) ∥ N ( 0 , I ) ) \begin{aligned} L_{G^{i}} &=-\frac{1}{2}\left[E_{x \sim p G^{i}} \log D_{i}(x)+E_{x \sim p G^{i}} \log D_{i}(x, s)\right] \\ L_{C A} &=D_{K L}(N(\mu(s)) \| N(0, I)) \end{aligned} LGiLCA=−21[Ex∼pGilogDi(x)+Ex∼pGilogDi(x,s)]=DKL(N(μ(s))∥N(0,I))
The loss function of the discriminator consists of conditional loss and unconditional loss :
L D i = − 1 2 [ L D + L C D ] L D = E x ∼ P data log D i ( x ) + E x ∼ p G i log ( 1 − D i ( x ) ) L C D = E x ∼ P data log D i ( x , s ) + E x ∼ p G i log ( 1 − D i ( x , s ) ) \begin{array}{l} L_{D^{i}}=-\frac{1}{2}\left[L_{D}+L_{C D}\right] \\ L_{D}=E_{x \sim P \text { data }} \log D_{i}(x)+E_{x \sim p G^{i}} \log \left(1-D_{i}(x)\right) \\ L_{C D}=E_{x \sim P \text { data }} \log D_{i}(x, s)+E_{x \sim p G^{i}} \log \left(1-D_{i}(x, s)\right) \end{array} LDi=−21[LD+LCD]LD=Ex∼P data logDi(x)+Ex∼pGilog(1−Di(x))LCD=Ex∼P data logDi(x,s)+Ex∼pGilog(1−Di(x,s))
2.4、 experiment



Last
Personal profile : Graduate students in the field of artificial intelligence , At present, I mainly focus on text generation and image generation (text to image) Direction
Personal home page : Medium coke with more ice
Time limited free subscribe : Text generated images T2I special column
Stand by me : give the thumbs-up + Collection ️+ Leaving a message.
in addition , We have established wechat T2I Learning exchange group , If you are T2I Fans or researchers in this field can send me a private message to join .
If this article helps you a lot , I hope you can give me a coke ! Add more ice !
边栏推荐
- Understand kingbasees V9 in one picture
- [construction of independent stations] this website is the first choice for cross-border e-commerce companies to open online stores at sea!
- 5.component动态组件的展示
- Yolov4网络详解
- Cache read / write policies: cacheside, read/writethrough and writeback policies
- Interview must ask | what stages does a thread go through from creation to extinction?
- js小技巧
- 有趣的C语言
- Comprehensive experiment of static routing
- .htaccess learning
猜你喜欢
![[C language] dynamic memory management](/img/20/3970cd2112204774a37b5a1d3bdce0.png)
[C language] dynamic memory management

使用Photoshop出现提示“脚本错误-50出现一般Photoshop错误“

ps样式如何导入?Photoshop样式导入教程

Comprehensive experiment of static routing
2019 top tennis cup upload
TCP three handshakes and four disconnects

Huawei's entry into the commercial market: due to the trend, there are many challenges
HCIA dynamic routing rip basic experiment

干货 | 独立站运营怎么提高在线聊天客户服务?

Maximum value, minimum value, bubble sort in the array
随机推荐
The usage syntax and scene of selector, as well as the usage of background picture size, text box shadow and excessive effect
How can I index the Oracle database field date?
.htaccess learning
Interview must ask | what stages does a thread go through from creation to extinction?
grid布局
How does novice Xiaobai learn to be we media?
The digital China Construction Summit ended with a list of massive pictures on site!
自定义视口高度,多余的部分使用滚动
[day02] Introduction to data type conversion, operators and methods
使用Photoshop出现提示“脚本错误-50出现一般Photoshop错误“
勤于奋聊聊现在还有哪些副业可以做
JS第二天(变量、变量的使用、命名规则、语法扩展)
如何将Photoshop图层复制到其他文档
【C语言】自定义类型详解(结构体+枚举+联合)
Two way republication experiment
Technology sharing | gtid that needs to be configured carefully_ mode
Title: there is an array that has been sorted in ascending order. Now enter a number and ask to insert it into the array according to the original rule.
Safety fourth after class exercise
博云容器云、DevOps 平台斩获可信云“技术最佳实践奖”
使用Unity做一个艺术字系统