当前位置:网站首页>11.1.1 overview of Flink_ Flink overview
11.1.1 overview of Flink_ Flink overview
2022-06-26 00:26:00 【Loves_ dccBigData】
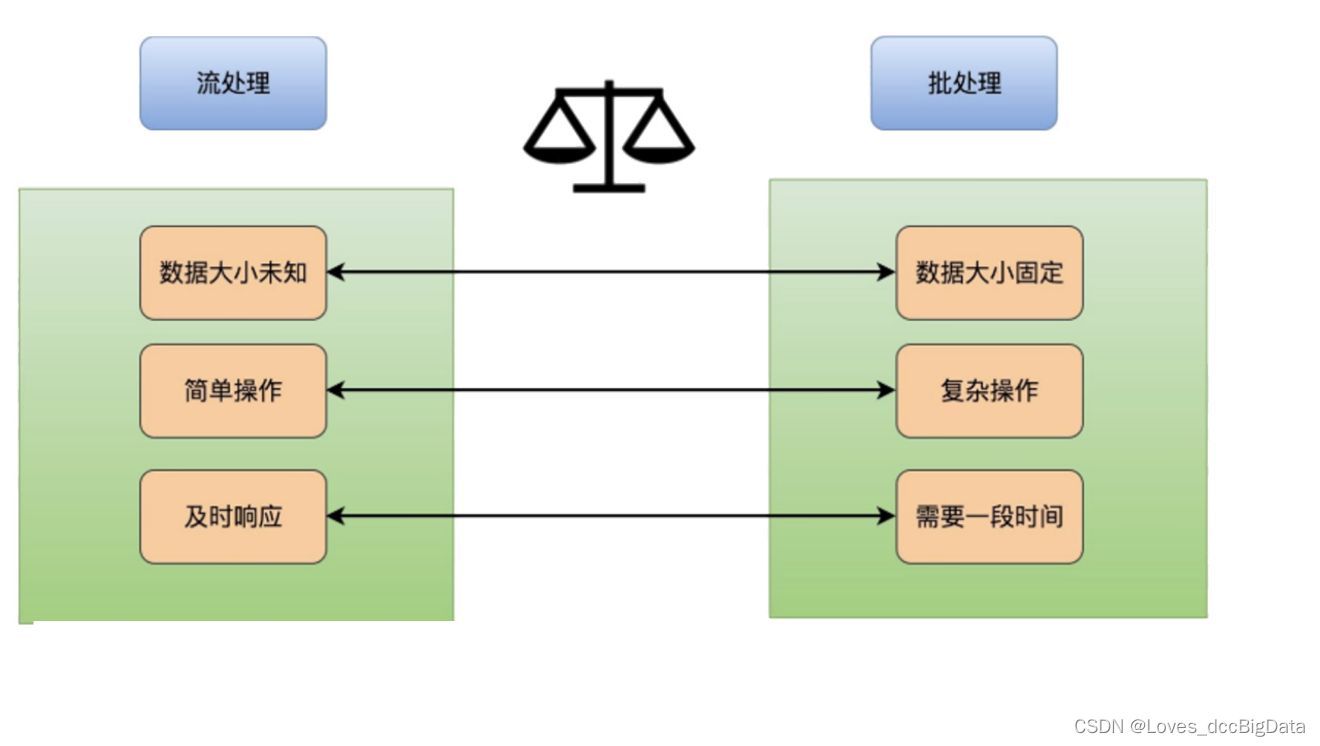
1、 Stream processing and batch processing
2、 Bounded flow and unbounded flow
Bounded flow : The amount of data is limited ,eg:mysql etc.
By incident : Data has no boundaries , commonly kafka Li data
3、flink summary , characteristic
(1)flink Is a distributed data processing engine
(2) Support high throughput 、 Low latency 、 High performance streaming
(3) Support windows with event time (Window)
(4) operation
Supports stateful computing Exactly-once semantics
(5) Support highly flexible windows (Window) operation , Support based on time、count、session, as well as data-driven Window operation
(6) Support continuous flow model with back pressure function
(7) Support based on lightweight distributed snapshot (Snapshot) Implemented fault tolerance
(8) A runtime supports Batch on Streaming Deal with and Streaming Handle
(9)Flink stay JVM Internal implementation of their own memory management , Avoid the appearance of oom
(10) Support iterative calculation
(11) Support automatic program optimization : Avoid specific situations Shuffle、 Expensive operations like sorting , Intermediate results need to be cached
4、 Deployment environment
(1) Local mode local
(2)cluster Cluster pattern (standalone,yarn)
(3) Cloud model cloud
5、flink Continuous flow execution process ( important )
KeyBy: Will be the same key To the same Task in
— The default is hash Partition
—flink and spark Both are coarse-grained resource scheduling
— Called upstream and downstream , Don't cry map,reduce
—flink It is a scheduling
— It is generally a stateful operator

spark Of shuffle The process :
wait for map Execute after the end reduce End
flink Of shuffle The process :
flink All in task Start together , Wait for the data to come
The upstream task Downstream task Conditions for sending data :
(1) The data reaches 32k(buffle Cache size , Prevent frequent data sending IO Consume )
(2) Time to achieve 200 millisecond
6、 Dispatch
spark Task scheduling :
(1) structure DAG Directed acyclic graph
(2) segmentation stage
(3) Put in order stage Send to taskschedule
(4)taskschedule take task Send to executor In the implementation of
fink Task scheduling
(1) structure DataFlow
(2) Split into multiple task
(3) Will all task Deployment launch
(4) Wait for the data to come , Processing data
7、 Run Guide Package
logger For printing logs , You also need to put the log file in resources Only in the middle can
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.11.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.12</scala.version>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
</dependencies>
边栏推荐
- 【TSP问题】基于Hopfield神经网络求解旅行商问题附Matlab代码
- ORA-01153 :激活了不兼容的介质恢复
- yolov5 提速多GPU训练显存低的问题
- JS to input the start time and end time, output the number of seasons, and print the corresponding month and year
- Maintenance and key points of SMT Mounter
- About Simple Data Visualization
- 学习识别对话式问答中的后续问题
- Cloud rendering and Intel jointly create the "core" era of cloud rendering
- Ora-01153: incompatible media recovery activated
- Oracle RAC cluster failed to start
猜你喜欢

86.(cesium篇)cesium叠加面接收阴影效果(gltf模型)

Machine vision: illuminating "intelligence" and creating a new "vision" world

About Simple Data Visualization

Cloud rendering and Intel jointly create the "core" era of cloud rendering

什么是微服务

Regular expression introduction and some syntax

EBS R12.2.0升级到R12.2.6

深圳台电:联合国的“沟通”之道

每日刷题记录 (四)
性能领跑云原生数据库市场!英特尔携腾讯共建云上技术生态
随机推荐
2021-04-28
JS to input the start time and end time, output the number of seasons, and print the corresponding month and year
SPI锡膏检查机的作用及原理
tensorrt pb转uff问题
Linux下搭建集群环境(2)-----------linux下安装Mysql
【图像检测】基于高斯过程和Radon变换实现血管跟踪和直径估计附matlab代码
解决线程并发安全问题
机器视觉:照亮“智”造新“视”界
Introduction to anchor free decision
原型和原型链的理解
Frequently asked questions about redis
Network connection verification
Multi-Instance Redo Apply
[advanced ROS] Lecture 1 Introduction to common APIs
Regular expression introduction and some syntax
EasyConnect连接后显示未分配虚拟地址
CaMKIIa和GCaMP6f是一樣的嘛?
Display unassigned virtual address after easyconnect connection
Xiaohongshu microservice framework and governance and other cloud native business architecture evolution cases
SMT行业AOI,X-RAY,ICT分别是什么?作用是?