当前位置:网站首页>ECCV 2022 Huake & ETH propose OSFormer, the first one-stage Transformer framework for camouflaging instance segmentation!The code is open source!...
ECCV 2022 Huake & ETH propose OSFormer, the first one-stage Transformer framework for camouflaging instance segmentation!The code is open source!...
2022-07-31 21:28:00 【I love computer vision】
关注公众号,发现CV技术之美
本篇分享 ECCV 2022 论文『OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers』,华科ÐPropose the first one-stage for camouflage instance segmentationTransformer的框架OSFormer!代码已开源!
详细信息如下:

论文地址:https://arxiv.org/abs/2207.02255[1]
代码地址:https://github.com/PJLallen/OSFormer[2]
01
摘要
在本文中,作者提出了OSFormer,This is the first for camouflage instance segmentation(CIS)的一阶段Transformer框架.OSFormerBased on two key designs.
首先,By introducing position-guided queries and hybrid convolutional feed-forward networks,作者设计了一个位置感知Transformer(LST)to get location labels and instance-aware parameters.
其次,The author developed aFusion from coarse to fine(CFF),to merge fromLST编码器和CNNDifferent contextual information for the backbone.Coupling these two components makesOSFormerAble to efficiently mix local features and long-term context dependencies,to predict fake instances.
compared to a two-stage framework,本文的OSFormerachieved without requiring a large amount of training data41%的AP,and achieves good convergence efficiency.
02
Motivation
Camouflage is a powerful and widespread tool,Detection or identification from biology can be avoided.在自然界中,Camouflage objects have evolved a set of concealment strategies to deceive the perception and cognitive mechanisms of prey or predators,For example background matching、Hidden from shadow、Erase shadows、Destructive coloring, etc.与一般的目标检测相比,These defensive behaviors enable camouflaged object detection(COD)becomes a very challenging task.CODGoal is to distinguish between camouflage object and background with high internal similarity.
由于COD10K、CAMO、CAMO++和NC4Kestablishment of large-scale standard benchmarks,CODperformance has been significantly improved.然而,CODDetach only camouflage objects from the scene at the object level,while ignoring further instance-level identifiers.最近,Researchers propose a new camouflage instance segmentation(CIS)基准和CFL框架.Capturing camouflaged instances can provide more clues in real scenarios(such as semantic categories、对象数量),因此CIS更具挑战性.
Compared to generic instance segmentation,CISneed to be executed in more complex scenarios,have high feature similarity,and yields class agnosticmask.此外,Various instances may show different camouflage strategies in the scene,and combining them may form mutual camouflage.These derived overall camouflages makeCIS任务更加艰巨.When humans gaze at a deeply camouflaged scene,The vision system instinctively scans the entire scene for a range of local ranges,to find valuable clues.Inspired by this visual mechanism,The authors propose a new location-awareCIS方法,The method carefully captures all locations from a global perspective(即局部上下文)的关键信息,and directly generate the masquerading instance mask(That is, a one-stage model).
由于transformerThe rise of vision,Long-term dependencies can be captured using self-attention and cross-attention,and build global content-aware interactions.尽管transformerThe model shows strong performance on some dense prediction tasks,But it needs to contain large-scale training data and longer training period.然而,as a new downstream task,Currently only limited instance-level training data is available.
为此,The authors propose a location-awareness-basedTransformer(LST),for faster convergence and higher performance with fewer training samples.To dynamically generate location-guided queries for each input image,作者将LSTThe multi-scale global features output by the encoder are gridded into a set of feature blocks with different local information.与vanilla DETRCompared with zero initializes the object in the query,The proposed location-guided query can focus on location-specific features,and interact with global features via cross-attention,to obtain instance-aware embeddings.
This design effectively speeds up the convergence,Significantly improves detection of fake instances.To enhance local awareness and neighbortoken之间的相关性,The author introduces the convolution operation into the standard feedforward network,Call it a Hybrid Convolutional Feedforward Network(BC-FFN).因此,本文基于LSTThe model can seamlessly integrate local and global contextual information,and effectively provide location-sensitive features to segment camouflaged instances.
此外,The author devised a fusion from coarse to fine(CFF)to integrate fromResNet和LSTSequentially generated multi-scale low-level and high-level features,to generate shared mask features.Since the edges of camouflaged instances are difficult to capture,作者在CFFReverse edge attention is embedded in the module(REA)模块,to improve sensitivity to edge features.
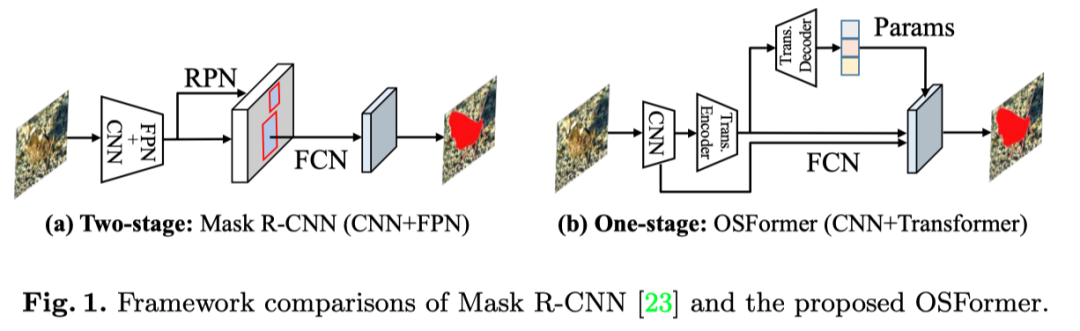
最后,The author introduces dynamic camouflage instance normalization(DCIN),Generate masks by combining high-resolution mask features and instance-aware embeddings.Based on the above two new designs,即LST和CFF,The authors provide a new one-stage framework for camouflage instance segmentationOSFormer(如上图).OSFormer是第一个为CISMission Exploration is based ontransformerframe work.
本文的贡献如下:
提出了OSFormer,This is the first based on the camouflage instance segmentation task.Transformerone-stage framework.这是一个灵活的框架,可以端到端的方式进行训练.
location-awareTransformer(LST)to dynamically capture instance clues at different locations.本文的LSTContains an encoder with a hybrid convolutional feedforward network,Used to extract multi-scale global features,And a decoder with location guide the query,For instance the embedded perception.所提出的LSTStructure can quickly converge to limited training data.
proposed a new coarse-to-fine fusion(CFF)方法,By the fusion of the trunk andLSTBlock multi-scale low-level and high-level features to obtain high-resolution masks.在该模块中,Reverse edge attention is embedded(REA),to highlight edge information of camouflaged instances.
广泛的实验表明,OSFormer在具有挑战性的CIS任务中表现良好,在很大程度上优于11popular instance segmentation method,例如,在COD10K测试集上实现了8.5% 的AP改进.
03
方法

本文提出的OSFormerIncludes four basic components:(1)for extracting object feature representationsCNN主干,(2)Generating instance-aware embeddings using global features and location-guided queries位置感知Transformer(LST).(3) Coarse to fine fusion(CFF)for integrating multi-scale low- and high-level features and producing high-resolution mask features,以及(4)Used to predict the ultimate example of maskDynamic Masquerade Instance Normalization(DCIN).The image above shows the entire architecture.
3.1 CNN Backbone
给定输入图像,Walk use fromCNNBackbone Multiscale Features(即ResNet-50).为了降低计算成本,The author directly maps the last three features()flatten and concatenate into one256A sequence of channels asLST编码器的输入.对于特征,Input it as high-resolution low-level features toCFF模块中,to capture more disguised instance clues.
3.2 Location-Sensing Transformer
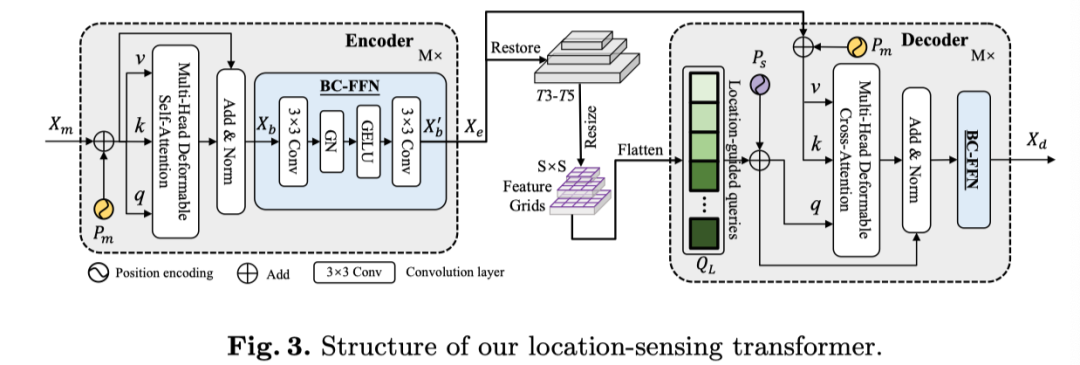
虽然transformerGlobal information can be better extracted by self-attention layers,But it requires large-scale training samples and high computational cost.由于CIS的数据有限,The goal of this article is to design an efficient architecture,Can converge faster and achieve competitive performance.在上图中,The authors demonstrate the location-awareness of this paperTransformer(LST).
LST Encoder
with onlytransformerThe encoder inputs a single-scale low-resolution featureDETR不同,本文的LSTThe encoder receives multi-scale features for rich information.Deformable Self-Attention Layer,In order to better capture local information and enhance adjacenttoken之间的相关性,The author introduces the convolution operation into the feedforward network,Hybrid Convolutional Feedforward Network(BC-FFN).
首先,restore the feature vector to the spatial dimension according to the shape of.然后,The execution core size is 3×3convolutional layers to learn inductive biases.最后,The authors added a group normalization(GN)和一个GELUactivation to form a feedforward network.在3×3卷积层之后,The author will feature flattening for sequence.与混合FFN相比,本文的BC-FFN不包含MLPOperations and residual connections.
With previous work at the beginning of each stage design of convolutiontokenEmbedded and inTransformerDifferent depthwise separable convolution operations are used in the block,作者在BC-FFNOnly two convolutional layers are introduced in.具体来说,给定输入特征,BC-FFNThe process can be formulated as:
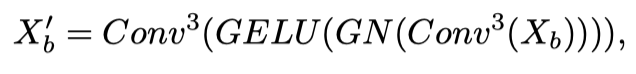
其中,是3×3卷积运算.总的来说,LSTThe encoder layer is described as follows:
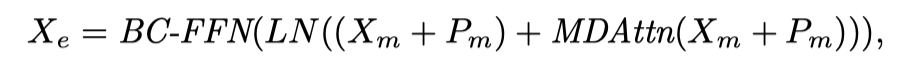
where expressed as the position code.And respectively bull deformable layer since the attention and normalized.
Location-Guided Queries
Object query is intransformerArchitecture plays a key role,transformerThe architecture is used as the initial input to the decoder,And through the decoder output layer embedded.然而,vanilla DETROne of the reasons for slow convergence is that object queries are zero-initialized.为此,The author put forward the position to guide the query,该查询具有LSTAdvantages of multi-scale feature maps for encoders.
值得注意的是,DETREach query in is focused on a specific field.受SOLO的启发,The authors first adjust the recovered feature maps to the shape of,.然后,Divide the resized feature into a feature grid,并将其展平,to generate location guided queries.
在这种情况下,The proposed location-guided query can leverage learnable local features at different locations to optimize initialization,and efficiently aggregate features in camouflaged regions.compared to zero initialization or random initialization,This query strategy improvestransformerEfficiency of query updates in the decoder,and speed up the training convergence.
LST Decoder
LSTdecoder for andLSTEncoder-generated global features and location-guided query interactions are critical to generate instance-aware embeddings.Spatial location encoding is also added to this paper's location-guided queries and encodersmemory中.然后,It is fused by deformable cross-attention layers.
与一般transformer解码器不同,The authors use cross-attention directly instead of self-attention,Because the proposed query already contains learnable global features.与LST编码器类似,BC-FFNAlso used after deformable attention manipulation.Guided query for a given location,本文的LSTThe decoder can be expressed as:

where represents the feature grid-based position encoding.Represented as a multi-head deformable cross-attention operation.is the output embedding of the instance-aware representation.最后,recovery to send to the followingDCIN模块,用于预测掩码.
3.3 Coarse-to-Fine Fusion

as a bottom-upTransformer的模型,OSFormer利用LSTMulti-level global features of encoder output,to generate shared mask features.To incorporate different contextual information,The author also incorporatesCNNThe low-level features of the trunk as supplement,to generate uniform high-resolution feature maps.
Coarse to fine fusion(CFF)The detailed structure of the module is shown in the figure above.Multilevel featuresC2、T3、T4和T5as input to cascade fusion.From the input scale to1/32的T5开始,通过3×3卷积、GN和2×双线性上采样,and add higher resolution features(T4为1/16比例).
将1/4After the fusion of proportions,Features continue1×1卷积、GN和RELU操作,to generate mask features.请注意,After the first convolution of each input feature, the channels are changed from256个减少到128个,Then in the final output it is incremented to256个通道.
Considering camouflaged edge features are harder to capture,The author designed the embeddedCFFReverse edge attention of(REA)模块,to supervise edge features in an iterative process.Unlike the previous reverse attention,本文的REAoperate on edge features instead of predicted binary masks.
此外,Edge labels for supervision are obtained by instance mask labels,No need for any manual tagging.Inspired by convolutional block attention,Input features are average pooled(AvgPool)and max pool(MaxPool)操作.然后,将它们concat并送到7×7卷积和sigmoid函数.
然后,Invert attention weights,and do an element-wise multiplication with the fused features.最后,作者使用3×3Convolution to predict edge features.假设输入特征为,每个REAThe entire process of the module can be formulated as follows:

其中,表示7×7卷积层,represents the channel axisconcat.所提出的CFFShared mask features are providedF,然后送到DCIN中,to predict the final camouflaged instance mask.
3.4 Dynamic Camouflaged Instance Normalization
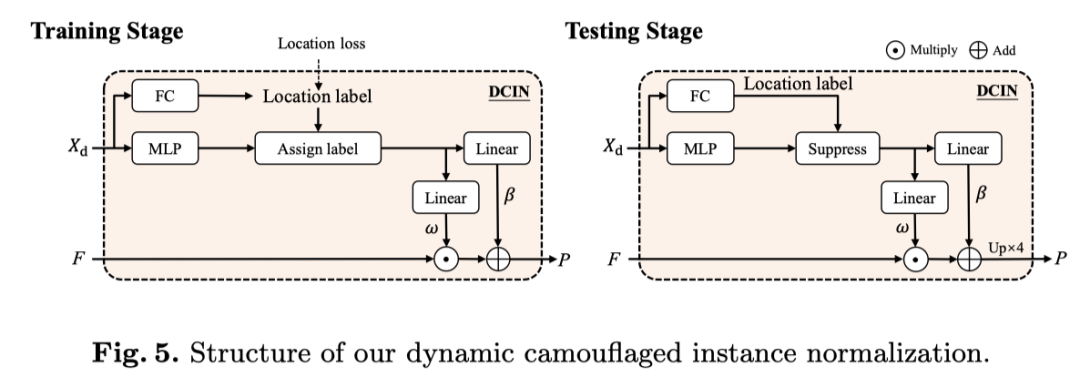
The pattern instance migration domain inspired normalized operation,The author introduces a dynamic camouflage instance normalization(DCIN)to predict the final mask.当DCIN接收从LSTdecoder to output when embedding,采用全连接层(FC)to get the location tag.
并行地,使用多层感知器(MLP)获得大小为D(即256)instance-aware parameters of.In the training phase, the authorground truthAssign positive and negative positions.Apply positive-position instance-aware parameters to generate segmentation masks.在测试阶段,The author uses the confidence value of the location label to filter(如上图所示)无效参数(例如,阈值>0.5).
随后,Operates two linear layers on the filtered position-aware parameters,to get affine weights and biases.最后,They share mask features with
used together to predict fake instances,可以描述为:
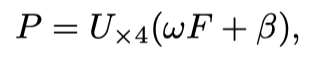
Which mask is predicted.Nis the number of predicted instances.是一个4times the upsampling operation.最后,应用矩阵NMSto get the final instance.
3.5 Loss Function
在训练期间,The total loss function can be written as:
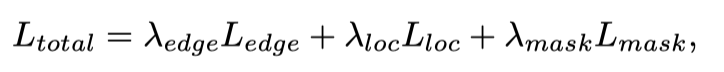
其中,is the marginal loss,用于监督CFFEdges at different levels in.The edge loss can be defined as,其中jrepresents the total level of edge features used for supervision.is the weight of the edge loss,默认设置为1.
由于CISTasks are class agnostic,The authors therefore use the confidence that the camouflage exists in each location()Compare with classification confidence in instance segmentation.此外,由Focal Loss实现,由Dice损失计算,用于分割.and are set to 1和3,to balance the total loss.
04
实验

TransformerIs the depth of influence is based onTransformerA key factor in the performance and efficiency of the model.作者在LSTVarious combinations of different numbers of encoder and decoder layers were tried in,以优化OSFormer的性能.如表所示.如上表所示,A three-layer encoder is not enough to makeOSFormer的性能最大化.APThe highest case is that the number of encoders is6,The number of decoders is 3.

The author uses fromResNet-50As a multistage extracted featuresLST的输入.To more accurately capture camouflage at different scales,同时保持模型效率,The authors combine different numbers of features in the backbone,包括C3-C5、C2-C5、C3-C6和C2-C6.在上表中,可以观察到C3-C5The combination of the fewest parameters and training memory achieves powerful performance.

Object query is intransformerArchitecture is critical for dense prediction tasks.如上表所示,Our location-guided query significantly outperforms other query designs.This illustrates that inserting supervised global features into the query is crucial for effectively regressing different camouflaged cues and locating instances.
此外,The authors also compared the learning ability of the three strategies.可以发现,The location-guided query scheme of this paper has a faster convergence rate in the early training stage,And the final convergence is also better than the other two models.它还表明,Location-guided queries can effectively utilize global features,Through the cross attention mechanism in different position to capture information disguise.

在CFF模块中,The multi-scale input features directly affect the mask features through the fusion operationF的质量.为了探索ResNet-50和LSTThe best fusion scheme encoder,The authors have made different combinations in the above table.通过将C2、T3、T4和T5馈入CFFmodule for best results.

The author visualized the input toCFFfeature and mask feature for each scale of the moduleF.

上表展示了不同Backbone下的实验结果.

为了提高OSFormer的应用价值,The author provides aOSFormer-550的实时版本.具体来说,The author adjusts the input short side to550,同时将LSTReduced to encoder layer3层.如上表所示,尽管AP值下降到36%,but the inference time increases to25.8fps,Arguments and floats are also significantly improved.
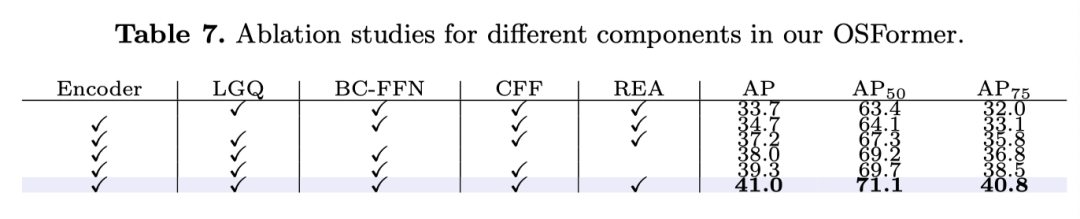
The above table shows the effectiveness of the different modules proposed in this paper.

如上表所示,尽管CIS任务具有挑战性,但本文的OSFormerOn all indicators are still better than other competitors.特别是,OSFormer的APScore significantly higher than the second-rankedSOLOv2.The ideal result should be attributed to theLST,Because it provides a higher level of global features,并与LSTInteraction of camouflage cues at different positions in the decoder.
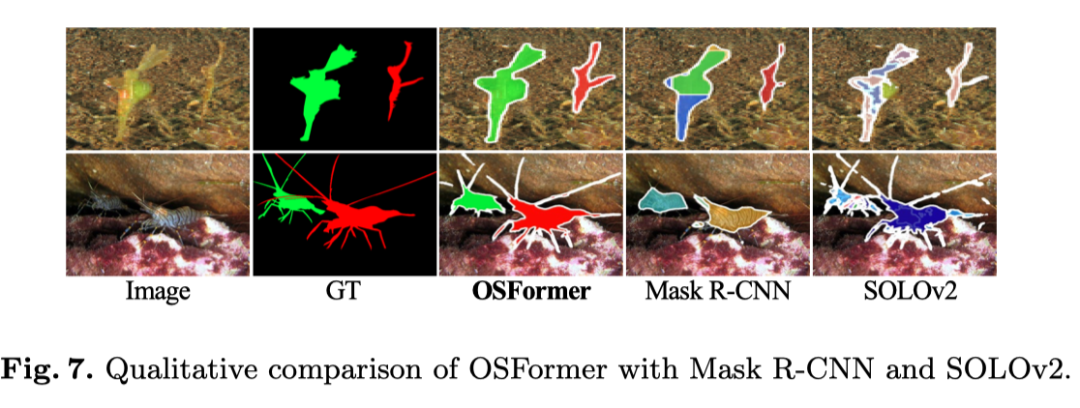
为了验证OSFormer的有效性,The author also shows two representative visualization results in the figure above.具体来说,The top sample indicates,OSFormerMasquerading can be easily distinguished across multiple instances.Bottom result shows,Our method outperforms capturing slender boundaries,This can be attributed to theREAModule enhances edge features.总的来说,Compared with the visualization results of other methods,OSFormerAbility to overcome more challenging situations and achieve good performance.
05
总结
This paper proposes a new position-aware single-stageTransformer框架,称为OSFormer,For camouflage instance segmentation(CIS).OSFormerContains a efficient location-awareTransformer,Used to capture global features and dynamically regress the location and subject of camouflaged instances.As the first phase from the bottom upCIS框架,The author further designs a fusion from coarse to fine,to integrate multi-scale features and highlight camouflage edges to generate global features.
大量实验结果表明,OSFormeroutperforms all other known models.此外,OSFormer只需要约3000张图像进行训练,并且收敛速度很快.It can be easily and flexibly extended to other downstream visual tasks with small training samples.
参考资料
[1]https://arxiv.org/abs/2207.02255
[2]https://github.com/PJLallen/OSFormer
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用.
知乎/公众号:FightingCV

END
欢迎加入「实例分割」交流群备注:分割

边栏推荐
- BM3 flips the nodes in the linked list in groups of k
- Redis综述篇:与面试官彻夜长谈Redis缓存、持久化、淘汰机制、哨兵、集群底层原理!...
- Arduino框架下STM32全系列开发固件安装指南
- pytorch lstm时间序列预测问题踩坑「建议收藏」
- leetcode: 6135. The longest ring in the graph [inward base ring tree + longest ring board + timestamp]
- uni-app中的renderjs使用
- 性能优化:记一次树的搜索接口优化思路
- 手把手教你学会部署Nestjs项目
- A few permanent free network transmission, convenient and simple (Intranet through tutorials)
- rj45 to the connector Gigabit (Fast Ethernet interface definition)
猜你喜欢

Apache EventMesh 分布式事件驱动多运行时

【论文精读】iNeRF

Qualcomm cDSP simple programming example (to query Qualcomm cDSP usage, signature), RK3588 npu usage query

Basics of ResNet: Principles of Residual Blocks

OSPFv3的基本配置

使用 Flutter 和 Firebase 制作!计数器应用程序
嵌入式开发没有激情了,正常吗?

Short-circuit characteristics and protection of SiC MOSFETs
Architecture Battalion Module 8 Homework
ReentrantLock原理(未完待续)
随机推荐
MySQL - single function
Apache EventMesh distributed event-driven multi-runtime
1161. Maximum Sum of Elements in Layer: Hierarchical Traversal Application Problems
AI 自动写代码插件 Copilot(副驾驶员)
Qualcomm cDSP simple programming example (to query Qualcomm cDSP usage, signature), RK3588 npu usage query
Three.js入门
focus on!Haitai Fangyuan joins the "Personal Information Protection Self-discipline Convention"
Cache and Database Consistency Solutions
Verilog implements a divide-by-9 with a duty cycle of 5/18
[PIMF] OpenHarmony Thesis Club - Inventory of the open source Hongmeng tripartite library [3]
[Intensive reading of the paper] iNeRF
A few permanent free network transmission, convenient and simple (Intranet through tutorials)
关注!海泰方圆加入《个人信息保护自律公约》
Thymeleaf是什么?该如何使用。
c语言解析json字符串(json对象转化为字符串)
架构师04-应用服务间加密设计和实践
JD.com searches for products by keyword API
深度学习中的batch(batch size,full batch,mini batch, online learning)、iterations与epoch
Linux环境redis集群搭建「建议收藏」
matplotlib ax bar color 设置ax bar的颜色、 透明度、label legend