当前位置:网站首页>JVM运行流程,运行时数据区,类加载,垃圾回收,JMM解析
JVM运行流程,运行时数据区,类加载,垃圾回收,JMM解析
2022-08-05 07:31:00 【囚蕤】
目录
JVM简介
JVM是Java Virtual Machine的简称,意为Java虚拟机
虚拟机是指通过软件模拟一个具有完整硬件功能,运行在一个完全隔离的环境中的完整计算机系统,
常见的虚拟机有JVM,VMwave,Virtual Box
JVM和其他两个虚拟机的区别是VMwave,Virtual Box都是通过软件模拟物理CPU指令集,物理系统中有很多寄存器;而JVM是通过软件模拟Java字节码的指令集,只保留了PC寄存器,其他的寄存器都进行了裁剪
JVM运行流程
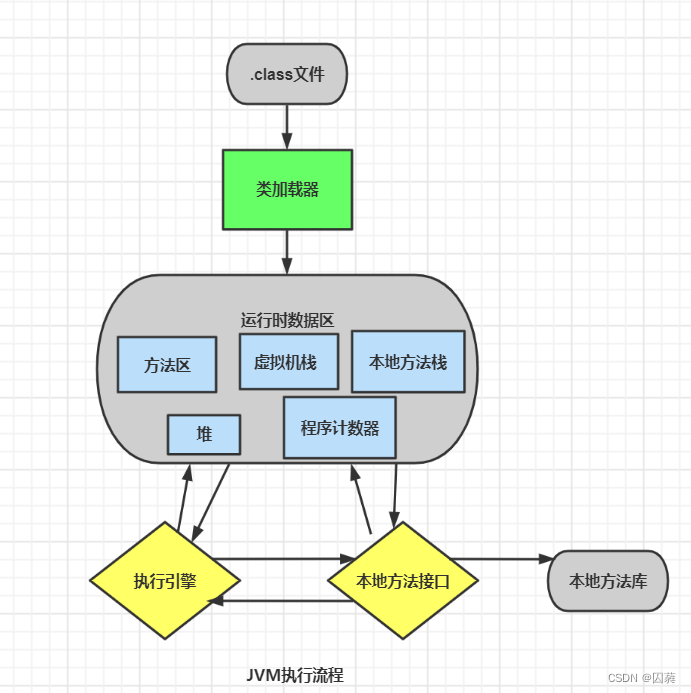
首先程序执行之前要把Java代码转译为字节码文件(.class文件),JVM用类加载器将字节码文件存储到运行时数据区,由于字节码文件是JVM一套指令规范,所以还需要执行引擎调用本地方法接口将字节码文件转换为底层指令,进而由CPU去执行相关指令.
JVM运行时数据区
JVM运行时数据区域也叫内存布局,有5部分组成:程序计数器,虚拟机栈,本地方法栈,堆,方法区.
程序计数器
程序计数器是用来记录当前线程执行到的行号.程序计数器是内存中最小的区域,用来指示吓一条应该执行的指令的地址
Java虚拟机栈
Java虚拟机栈的生命周期和线程相同.Java虚拟机栈用于描述Java方法执行的内存模型,每个方法在执行的时候都会创建一个栈帧,用以存储局部变量表,操作数栈,动态链接和方法返回地址
- 局部变量表:存放了基本数据类型和对象引用.局部变量表的大小是在编译期间决定的.简单来说存放的就是局部变量(八大数据类型以及对象引用)和方法参数
- 操作数栈:每个方法会生成一个先进后出的操作栈
- 动态链接:指向运行时常量池的方法引用
- 方法返回地址:PC寄存器的地址
本地方法栈
本地方法栈和Java虚拟机栈类似,只不过是Java虚拟机栈是给JVM使用的,而本地方法栈是给本地方法使用的.
堆
程序中创建的所有对象都存储在堆中.
堆中分为两个区域:新生代和老生代.新生代中放新建的对象,对象经过一定GC次数之后依然存活则放入老生代.新生代中又分为三部分为:Eden和两个Survivor.GC时会将Eden中存活的对象放入到一个未使用的Survivor中,然后清除掉Eden和正在使用的Survivor中的对象.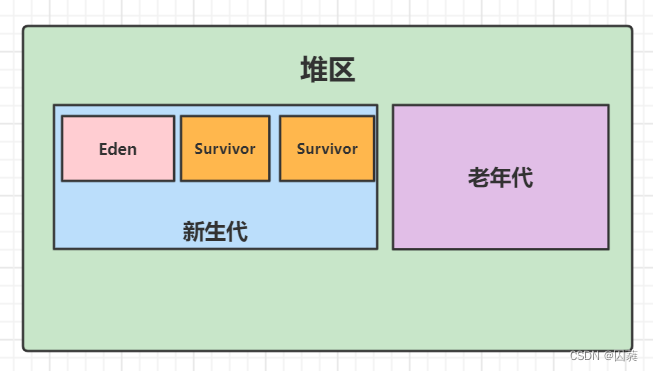
方法区
方法区用来存储被JVM加载的类信息,常量,静态变量,即时编译器编译后的代码等数据.
方法区在JDK7时被称作是永久代,JDK8中叫做元空间.
JDK8元空间中内存变成了本地内存,不再受JVM最大内存的参数影响;字符串常量由元空间移到了堆中
运行时常量池是方法区的一部分,存放字面量和符号引用(内存中符号地址变成了内存中的真是地址)
- 字面量:字符串(JDK8移到了堆中),final常量
- 符号地址:类和结构的完全限定名,字段的名称和描述符,方法的名称和描述符.
线程私有:JVM多线程是通过线程轮流切换并分配处理器执行时间的方式实现的.因此为了在切换线程后能够恢复到正确的执行位置,每条线程都需要拥有自己的程序计数器,类似于程序计数器这样的内存区域属于线程私有.
程序计数器,Java虚拟机栈,本地方法栈是线程私有的,堆,方法区是线程共享的
内存布局中的异常问题
- 堆溢出
当堆中存放的对象数量达到堆的最大数量时,就会发生堆溢出.堆溢出可能由两种原因造成,一种是内存泄露,即该对象本身应该被GC但没有被GC;一种是内存溢出,即该对象本身应该存活,则需要调整堆的最大容量设置或检查其是否生命周期过长 - 栈溢出
开辟的栈的数量过多超过了栈可开辟的最大数量或栈占用的内存超过了内存限制,前者属于StackOverFlow,后者属于OOM(Out Of Memory)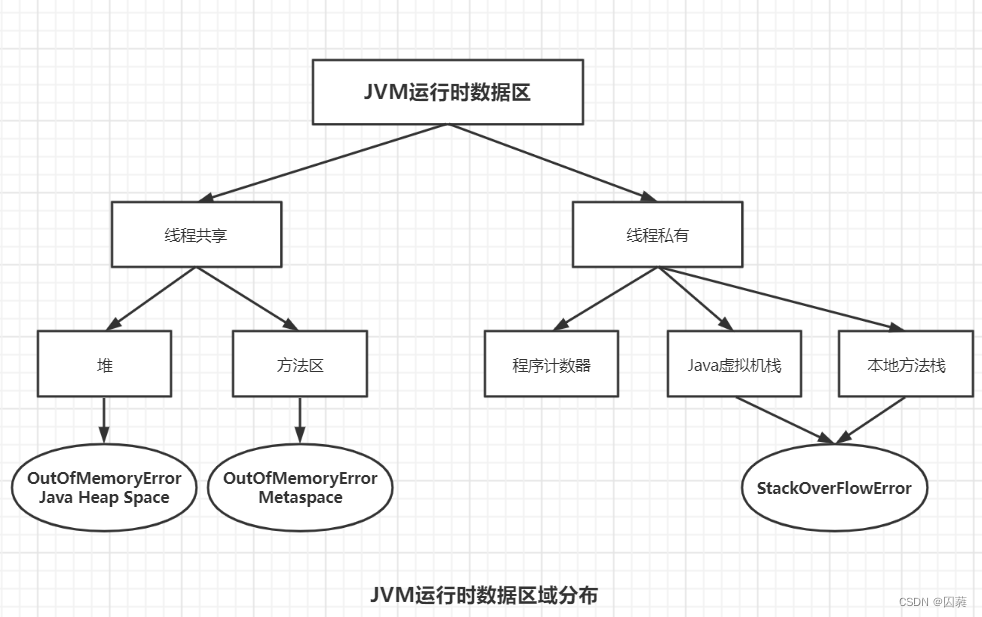
JVM类加载
类加载过程
一个类的生命周期如图: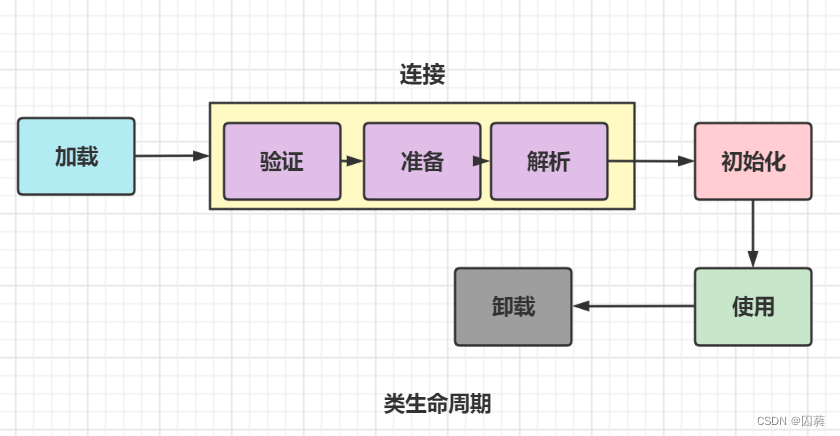
加载(Loading)
加载阶段(loading),主要完成3个部分的工作:
- 通过一个类的全限定名来获取定义此类的二进制字节流(找到某个类的.class文件)
- 将这个字节流文件所代表的的静态存储结构转化为方法区的运行时数据结构(打开.class文件并读取.class文件)
- 在内存中生成该.class文件的类对应的类对象,作为方法区中类的各种数据的访问入口(生成一个类对象)
连接(Linking)
- 验证(Verification)
确保字节流文件中的各项数据符合《Java虚拟机规范》的全部约束要求.如果不满足,类加载就会失败,并抛出异常. - 准备(Preparation)
为类中的静态变量分配内存并分配默认值. - 解析(Resolution)
将常量池中的符号引用替换为直接引用,为常量赋初始值.
符号引用:常量池中常量都有一个自己的编号,结构体中的常量在缺省下都是一个编号
直接引用:将编号替换为真正的对象中的内容.
初始化(Initializing)
JVM真正开始执行java中的代码,也就是执行类构造器的过程,真正对类对象初始化.如’static int val = 123;',val在准备阶段被赋予大小以及赋予默认值0,在初始化阶段被赋予初始值123.
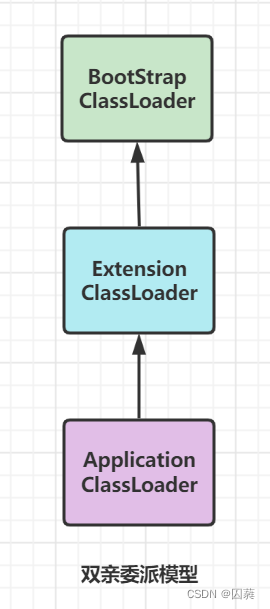
双亲委派模型
从Java虚拟机方面看,类加载器可以被分为两种:一种是启动类加载器(BoostrapClassLoader),是虚拟机自身的一部分;另一种就是其他的类加载器,独立存在于虚拟机外部.
而从开发者角度,为了更细致的进行类加载,保留了三层类加载器,双亲委派的类加载架构器.
双亲委派模型由3部分组成:启动类加载器(BootstrapClassLoader),应用程序类加载器(ExtensionClassLoader)和自定义类加载器(ApplicationClassLoader).其中启动类加载器负责加载JDK中lib目录下的核心类库,即家在标准库中的类;应用程序类加载器负责加载jdk目录中扩展的类;自定义类加载器负责加载当前项目中的类,加载的等级依次降低.而双亲委派模型则是按照加载等级从高到低加载,当父加载器加载完后仍无法加载到需要的类,才会在本加载器中查找加载.
双亲委派模型类加载过程:
- ApplicationClassLoader先判断其父类是否加载过,如果加载过就加载ApplicationClassLoader中管控的类
- ExtensionClassLoader先判断其父类是否加载过,如果加载过就加载ExtensionClassLoader中管控的类
- BootSrapClassLoader由于没有父类,则直接在自己管控中的类中查找带查找的.class文件
双亲委派模型的优点
- 避免重复加载类,即使自定义的类与标准库中的某个类重名也会优先加载标准库中的类不加载自定义的类.
2.安全:由于不会重复加载类,也就保证了Java核心API不被篡改.
破坏双亲委派模型
尽管双亲委派模型有很多优点,但在一些场景下也存在一定的问题,如Java中SPI(Server Provider Interface)机制下的JDBC实现
JDBC中的DriveManger类中的实现类loadInitialDrivers()是由线程上下文加载器加载的(属于ApplicationClassLoader),并没有向上去委派其父类类加载器,造成这种现象的原因是其父类类加载器只能加载指定路径下的类,而该实现类是由开发者实现的,其父类类加载器加载不到.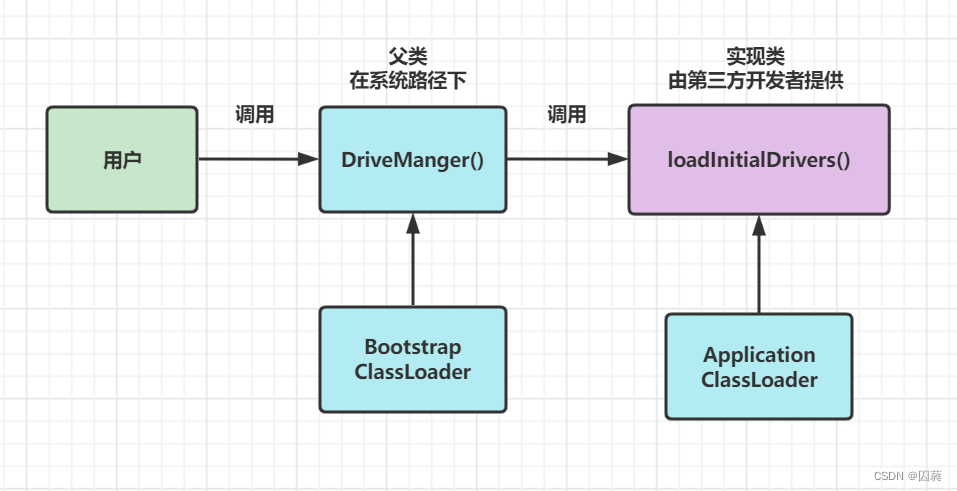
JVM垃圾回收(GC)
死亡对象判断算法
引用计数
给对象增加一个引用计数器,当指向该对象时,引用计数器加1,当计数器值变为0时,该对象死亡,可以被回收
事实上,JVM并没有采用这种方式去判断一个对象是否应该被回收,原因是这种方式无法解决循环引用的问题.
class Test{
Test test;
public static void main(String[] args){
//t1的计数器值为1,
Test t1 = new Test();
//t2的计数器值为1
Test t2 = new Test();
//t2的计数器值为2
t1.instance = t2;
//t2的计数器值为2
t2.instance = t1;
//t1,t2的计数器的值变为1,但此时应该回收t1,t2
t1 = null;
t2 = null;
}
}
可达性分析
可达性分析是JVM采用的一种判断垃圾对象的算法.它是通过一系列称为"GC Roots"的对象作为起始点,然后从该点开始以类似dfs的方式搜索内存空间,能够搜索到的对象被作上标记,全部搜索完后,没有标记的对象即为垃圾对象.
栈上的局部变量,方法区的静态成员指向的对象,常量池中引用的对象等区域中的对象通常被作为GC Roots.
垃圾回收算法
标记-清除算法
- 标记:就是可达性分析的过程
- 清除:直接将对象占用的内存回收掉
缺陷:
- 效率低:标记和清除两个过程的效率都较低
- 空间离散:标记清楚后会产生大量不连续的内存碎片,空间碎片太多导致再次为一个较大的对象分配内存时而发生异常.
复制算法
复制算法是为了解决标记-清除算法效率低的缺陷.主要是在为对象开辟内存时开辟对象大小的两倍内存,对象存放在其中一块内存中,当进行垃圾回收时,将仍活着的对象移动到另一块没有使用过的区域,而将已经使用过的内存区域全部回收.这样解决了回收内存离散的问题,且操作简单高效,缺点就是内存空间利用率低.新生代就是依据这种 方式回收垃圾的.
标记-整理算法
与标记-清除算法相似,只是在清除时不是直接将内存空间直接回收掉,而是将存活的对象向内存一端移动,然后回收掉待回收的内存区域.
分代算法
通过区域划分,在不同区域实施不同的垃圾回收策略.JVM采用的就是分代算法.JVM将堆中的对象分为新生代和老年代.在新生代中,存放的是新创建的对象,每次都会死去大量对象,所以采用复制算法;在老年代中,对象存活率较高(在新生代中熬过15次GC后的对象),空间比较少,需要采用标记-整理算法.
在新生代中,分为三块区域:Eden(伊甸区),Survivor From区,Survivor To区.新创建的对象会首先放入Eden区,当Eden区满后,会将Eden区中存活的对象移入Survivor From区,回收Eden区的内存;当Eden区再次满后,会将Eden区和Survivor From区中存活的对象移入Survivor To区,回收Eden区和Survivor From区的内存.重复这个过程,当在新生代熬过15(由JVM参数MAXTenuringThreshold参数决定)次GC扫描后存活的对象就会放入老年代.
垃圾收集器
CMS收集器
CMS收集器是一个老年代收集器,是一种获取最短回收停顿时间为目标的收集器.
CMS收集器是基于"标记-清除"算法实现的.整个过程分为4个步骤
- 初始标记
只是标记一下GC Roots能直接关联到的对象,速度很快,需要短暂的STW(Stop The World) - 并发标记
进行类似dfs遍历的GC搜索. - 重新标记
对并发标记阶段因为程序运作导致的一些标记变动的对象的标记记录,需要短暂的STW. - 并发清除
清除没有被标记的对象
CMS收集器的优缺点
优点:并发收集,低停顿.
缺点- CMS收集器对CPU敏感.虽然并发回收垃圾对象并不会造成应用程序的停顿,但仍旧会因为占用一部分线程而导致应用程序运行速度变慢.
- 当CPU数量个数在4个以上,并发回收垃圾占用的线程消耗不少于25%的CPU资源,而当CPU个数比较少时,CMS对用户的影响还是比较大的.
- CMS收集器会产生大量内存空间碎片
- CMS收集器无法处理浮动垃圾,一些垃圾对象随着用户程序的运行出现在GC扫描之后,这部分垃圾被称为"浮动垃圾",当CMS运行期间预留内存空间不够用时,会出现"Concurrent Mode Failure",这时将会采用Serial Old收集器重新收集,进而会产生较长的停顿时间.
G1收集器
G1垃圾回收器用于heap memory比较大的情况下,将内存区域分成很多小块的region块,然后并行的对其进行垃圾回收.给这些region进行了不同的标记(新生代,老年代),再扫描的时候,一次扫若干个region(尽管一轮GC不能完全扫描完,分多次来扫描),对于业务线程的影响是比较小的. G1收集器可以将STW停顿时间优化到1ms
上述垃圾收集器的核心思路是化整为零.
JMM
JVM提供了一种Java内存模型(Java Memory Model,JMM),用以屏蔽掉各种硬件和操作系统的内存访问差异.
主内存与工作内存
JMM的主要目标是定义程序中各个变量的访问规则,即在JVM中将变量存储到内存中和从内存中读取变量.此处的变量包括实例字段,静态字段和构成数组对象的元素,不包括局部变量和形参.
JMM规定了所有变量都存储到主内存中,每条线程拥有自己的工作内存,工作内存中保存了该线程使用的变量的主内存的拷贝,线程对变量的操作在工作内存中完成.不同的线程不能直接访问其他线程工作内存中的变量,而需要主内存去传递对应的变量值.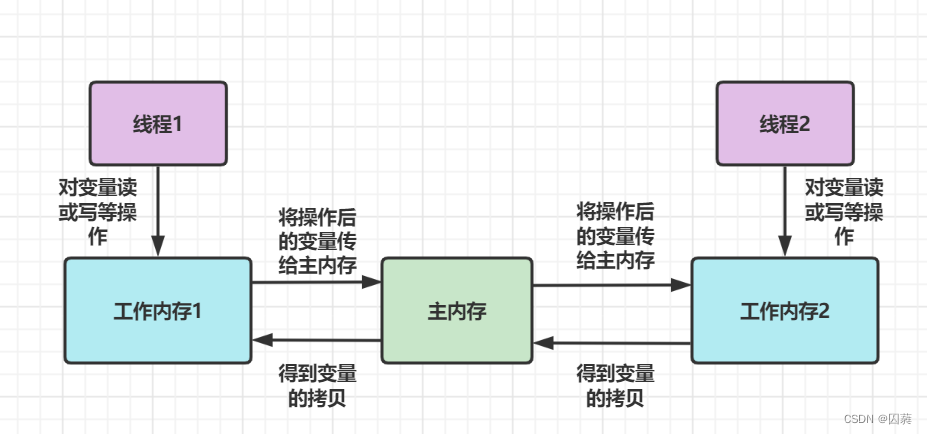
内存间交互操作
为了实现主内存和工作内存之间的交互,JMM定义了8种操作.且保证这8种操作都是原子的,不可分的.
1. lock:作用于主内存的变量,表示该变量被一个线程独占.
2. unlock:作用于主内存的变量,将一个lock态的变量释放出来.处于unlock状态的变量才可以被其他线程锁定.
3. read:作用于主内存的变量,它将一个主内存中的变量传输到工作内存中.
4. load:作用于工作内存的变量,把read操作之后的变量放入到工作内存的变量副本中.
5. use:作用于工作内存的变量,把一个工作内存中变量的值传递给执行引擎.
6. assign:作用域工作内存的变量,把执行引擎中的值传递给工作内存中对应的变量
7. store:作用于工作内存的变量,将工作内存中变量的值传递给主内存.
8. write:作用于主内存的变量,将store操作后的值放入到主内存的变量中.
JMM的三大特性
1. 原子性
2. 可见性:当一个线程修改了共享变量的值,其他线程能够立即得知这个修改.
3. 有序性:如果在本线程内观察,所有操作是有序的;如果在线程中观察另外一个线程,所有的操作是无序的.
因此,并发地执行程序,只有同时保证原子性,可见性和有序性才能保证程序正常运行,三者缺一不可.
volatile变量的特殊规则
- 保证此变量对所有线程的可见性
volatile变量在各个线程中是一致的.普通变量是无法做到这一点的,因为普通变量的值传递需要通过主内存完成. - 禁止指令重排序
- 编译器进行指令优化时,不能对volatile变量的执行语句的顺序进行重排.
2.程序执行到volatile变量的读或写操作时,在其前面的操作的更改全部执行,且对后面的操作可见,且后面的操作全部没执行.
- 编译器进行指令优化时,不能对volatile变量的执行语句的顺序进行重排.
边栏推荐
- 外企Office常用英语
- re正则表达式
- Illegal key size 报错问题
- AI + video technology helps to ensure campus security, how to build a campus intelligent security platform?
- 导出SQLServer数据到Excel中
- TRACE32——C源码关联1
- binary search tree problem
- ARM Cortex-M上的Trace跟踪方案
- 双向循环带头链表
- "Automatic Data Collection Based on R Language"--Chapter 3 XML and JSON
猜你喜欢

随机推荐
Redis数据库学习
国家强制性灯具安全标准GB7000.1-2015
C-Eighty seven(背包+bitset)
unity urp 渲染管线顶点偏移的实现
环网冗余式CAN/光纤转换器 CAN总线转光纤转换器中继集线器hub光端机
Falsely bamboo brother today and found a localization of API to use tools
Task flow scheduling tool AirFlow,, 220804,,
导出SQLServer数据到Excel中
After the firewall iptable rule is enabled, the system network becomes slow
Redis 全套学习笔记.pdf,太全了
MongoDB 语法大全
【LeetCode】235.二叉搜索树的最近公共祖先
SVG大鱼吃小鱼动画js特效
风控特征的优化分箱,看看这样教科书的操作
二叉树进阶复习1
强网杯2022 pwn 赛题解析——house_of_cat
常用的遍历map的方法
openSource 知:社区贡献
AI + video technology helps to ensure campus security, how to build a campus intelligent security platform?
MAYA大炮建模