当前位置:网站首页>ByteDance proposes a lightweight and efficient new network mocovit, which has better performance than GhostNet and mobilenetv3 in CV tasks such as classification and detection
ByteDance proposes a lightweight and efficient new network mocovit, which has better performance than GhostNet and mobilenetv3 in CV tasks such as classification and detection
2022-06-22 21:20:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This article shares papers 『MoCoViT: Mobile Convolutional Vision Transformer』, A new lightweight and efficient network is proposed by ByteDance MoCoViT, In the classification 、 Detection, etc. CV Task performance is better than GhostNet、MobileNetV3!
The details are as follows :

Thesis link :https://arxiv.org/abs/2205.12635
01
Abstract
lately ,Transformer Good results have been achieved in various visual tasks . However , Most of them are computationally expensive , Not suitable for real mobile applications . In this work , The authors propose a moving convolution vision Transformer(MoCoViT), It will pass Transfomrer Introduce mobile convolution network (mobile convolutional networks) To take advantage of these two architectures , So as to improve performance and efficiency .
Related to recent vision transformer My job is different ,MoCoViT Medium mobile transformer Modules are carefully designed for mobile devices , Very lightweight , This is accomplished through two major modifications : Mobile self attention (Mobile Self-Attention,MoSA) Module and mobile feedforward network (Mobile Feed Forward Network,MoFFN).MoSA The branch sharing scheme simplifies attention map The calculation of , and MoFFN As transformer in MLP Mobile version of , The calculation amount is further greatly reduced .
Comprehensive experimental proof , Proposed by the author MoCoViT The series is superior to... In various visual tasks SOTA Portable CNN and transformer Neural architecture . stay ImageNet In the classification , it stay 147M Floating point operation times reached 74.5% Of Top-1 precision , Than MobileNetV3 With less computation Improved 1.2%. stay COCO Target detection task ,MoCoViT stay RetinaNet Performance ratio under the framework GhostNet Higher than 2.1 AP.
02
Motivation
Vision Transformer(ViT) On various tasks , Such as image classification 、 Object detection and semantic segmentation , All ratio CNN There is a significant performance improvement . However , These performance improvements usually require high computational costs . for example , To perform image classification tasks ,DeiT Need to exceed 10G Of Mult Adds. Such high computing resource requirements exceed the capabilities of many mobile devices , For example, smart phones and autonomous vehicle . To alleviate this problem ,Swin Each one token The attention area is limited from total attention to local attention , Where the input is split into sub windows , And only execute self attention in the window .Twins A spatially separable self attention is proposed , The self attention of local groups and the attention of global subsampling are applied to two consecutive blocks . The disadvantage is that , Complexity is still too great , Unable to deploy to mobile device .
contrary , In the last few years , In designing efficient convolutional neural networks for mobile vision tasks (CNN) A lot of progress has been made . for example ,MobileNets Depth convolution and point convolution are used to approximate ordinary convolution layer , And achieved comparable performance .ShuffleNet Further proposed channel shuffle operation , To enhance the performance of the compact model .GhostNet Designed a Ghost modular , Used to generate rich feature maps from simple operations .
In this work , The author seeks to design a lightweight Transformer, And achieve a good trade-off between complexity and performance . Some researchers are trying for the first time to combine CNN and transformer A bit to develop lightweight Transformer. Previous research staff MobileNetV2 Block and transformer The blocks are connected in series , Developed MobileVit Block to learn the global representation . But with moving CNN comparison ,MobileVit Still relatively heavy .Mobile-Former yes MobileNet and Transformer Concurrent design , There is a two-way bridge between the two , For communication . Different from previous work , The author puts forward a very effective Mobile Transformer Block(MTB). This module is designed for mobile vision task , It consists of two key components , Mobile self attention (MoSA) And mobile feedforward network (MoFFN).
stay MoSA in , In the query 、 Key and value calculation , With lightweight Ghost Module replaces linear layer . Besides , During calculation , Reuse the weight by using the branch sharing mechanism . therefore ,MoSA More efficient than self attention . For multi-layer perception (MLP), Its complexity lies in Transformer Modules cannot be ignored .MoFFN To alleviate this problem . take MLP Replace the upper and lower projection linear layers in with valid Ghost modular , formation MoFFN. Use the proposed MTB, The authors propose a moving convolution vision Transformer(MoCoViT), This is a new mobile application architecture , among CNN Block and MTB The blocks are connected in series . To achieve the best tradeoff between complexity and performance ,CNN Blocks are placed at an early stage , and MTB The block is only used in the last stage .
In order to prove MoCoViT The effectiveness of the , The author conducted a series of experiments on various visual tasks , for example ImageNet-1K classification , as well as COCO Object detection and instance segmentation on . A lot of experimental results show that ,MoCoViT The performance of is better than others SOTA Lightweight of CNN Network and lightweight Transformer, Such as MobileNetV3、GhostNet and MobileFormer.

As shown in the figure above , When FLOPs The range is from 40M To 300M when ,MoCoViT Get the best results . To be specific ,MoCoViT stay ImageNet-1K In order to 147M Of FLOPs Realized 74.5% Of Top-1 precision , Than MobileNetV3 high 1.2%, Than GhostNet high 0.6%.
The work of this paper is contribution It can be summarized as follows :
This paper presents an ultra light for mobile devices Transformer block . Inside the block , Mobile self attention and mobile feedforward networks are carefully designed , Designed to achieve the best tradeoff between complexity and performance .
Put forward MoCoViT, This is an efficient structure , Combined with the CNN and Transformer The advantages of , And realized on various visual tasks SOTA performance .
03
Method
In this section , The author first introduces mobile self - attention designed for lightweight networks (MoSA) Mechanism , Compared with the ordinary self attention mechanism , This mechanism can greatly reduce the computational overhead . Then it introduces how to use more efficient operation to build mobile feedforward network (MoFFN), To replace the traditional MLP layer . Use the MoSA and MoFFN, Can constitute an efficient mobile Transformer block (MTB). Last , The author introduces how to use MTB Build a mobile winder vision Transformer(MoCoViT), This is a method using convolution neural network and vision Transformer Advantages of efficient lightweight networks .
3.1 Mobile Self-Attention (MoSA)
vanilla transformer The architecture is self - focused by many (MHSA) and MLP Layers alternate to form .LayerNorm For each block Before , Residual connections are used for each block after . Self attention mechanism as a visual Transformer The core part of the network , It has shown its effectiveness in various visual tasks . General self attention can be calculated as :

Where is the query 、 Key and value matrices , It's a query / Key channel dimension ,N yes token Count ,C yes token Channel dimension . However , In a lightweight model with limited capacity , The cost-effectiveness of self attention is lower than that of convolution layer . The computational complexity of self - attention has a quadratic relationship with spatial resolution . Three linear layers of the same level are introduced to calculate V Linear combination result of .
To alleviate the problem , The author introduced MoSA, This is a light-duty car Transformer Attention mechanism of structural design . It simplifies the self attention mechanism from two aspects .

First , In terms of fine-grained operations , The author uses more efficient Ghost Module replacement vanilla self attention Linear layer in ,Ghost Modules are commonly used in lightweight networks , It can be regarded as an effective variant of convolution operation , Generate relatively similar feature pairs at a low cost . The figure above shows Ghost Module structure .Ghost The module uses ordinary convolution , First, some inherent feature maps are generated , Then we use cheap linear operation to enhance features and increase channels . actually , Cheap linear operations are usually implemented as deep convolution , For better performance and speed tradeoffs .
then , From a macro perspective , The author proposes a branch sharing mechanism , To reuse Q、K、V Weight in calculation . As shown in the figure above , Each has the same input characteristics q、k、v The projection of . In the branch sharing mechanism of this paper , The author directly characterized V Reuse to Q and K in .
This method is mainly based on an opinion of the author :Q and K Only participate in the calculation of attention map , The end result of the self - attention mechanism is V Each of them token The linear combination of . And Q and K comparison ,V More semantic information needs to be preserved , To ensure the presentation of the final weighting and results . therefore , The results of self - attention mechanism are similar to V Strong correlation , But with Q and K Weak correlation . therefore , For small capacity mobile networks , Can be simplified Q and K The calculation of , To achieve better performance overhead balance .

among , They are calculation q、k、v The projection of . To further improve performance , The author also introduces depthwise The convolution layer acts as a reinforcing layer , To further enhance the Transformer block .MoSA The calculation of can be written as :

The computational complexity of mobile self attention proposed in this paper is :

among ,N=H×W Is the space size ,C Is the channel size . In order to demonstrate quantitatively the cost reduction , The author compares vanilla self-attention and MoSA At different resolutions FLOPs Times and parameters .

As shown in the figure above , Compared with vanilla self-attention,MoSA Of FLOPs The value is 3.6× smaller , Parameter is 2.4× smaller .
3.2 Mobile Feed Forward Network (MoFFN)
stay vanilla ViT Of Transformer In block ,MLP The layers are fully connected by the upper projection (FC) Layer and lower projection FC layers , And in MLP Apply before part LayerNorm. To deploy on mobile devices , The author uses more efficient Ghost Module replacement vanilla MLP Medium FC layer . Pictured 2 Shown , The author in MoFFN Use in batch normalization, You can merge... At deployment time . Besides , The author adopts the ReLU Activation function , Instead of using a that is unfriendly to mobile deployment GeLU Activation function .SE The module is also applied after the upper projection ghosting module .
In addition to computational efficiency ,MoFFN Better than average MLP Have a greater receptive field . In the original ViT Architecture ,MLP It focuses on extracting single through linear layer token Channel dimension information of , The information exchange of spatial dimension is mainly carried out in the part of self attention . let me put it another way ,vanilla ViT Medium MLP No sense of space , So it needs to be used after self - attention . In this paper, the MoFFN In vanilla MLP This defect is solved in . The author first passes Ghost The point by point convolution in the module is used to extract each token Channel dimensional characteristics of , And then use 3×3 Kernel depth convolution to extract spatial dimension features . Last , The output of point by point convolution and depth convolution concat get up .
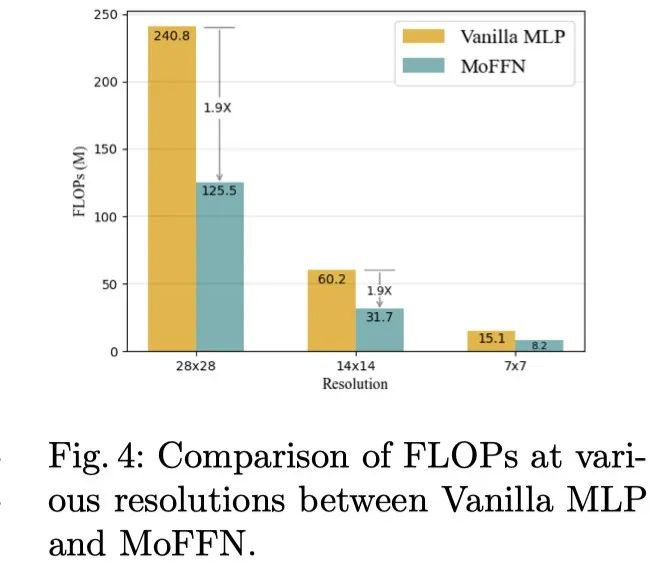
The author quantitatively analyzed MoFFN The computational overhead under different resolutions is reduced . The results are shown in the figure above . You can see ,MoFFN Of FLOPs About than vanilla MLP Small 1.9 times .
3.3 Enhancing Lightweight Networks with Mobile Self-Attention and Mobile Feed Forward Network
In this section , The author first introduces Mobile Transformer Block(MTB), It consists of MoSA and MoFFN form . Then it introduces how to use MTB Building efficient MoCoViT.
Mobile Transformer Block (MTB)
utilize MoSA and MoFFN The advantages of , The author introduces the Mobile Transformer Block. Pictured 2 Shown ,vanilla transformer block From the attention of the Bulls (MHSA) and MLP Layers alternate to form . Apply before and after each block LayerNorm(LN) Connect with the residuals .
stay MTB in , The author reserves every block Residual connection after , But with the MoSA and MoFFN Replace vanilla self attention and vanilla MLP. Besides , The author deleted attention and MLP Invalid before part LayerNormam, And replace it with Ghost Module BatchNorm(BN).BN It is a mobile friendly standardized operation , Because it can be merged with the convolution layer at deployment time .

Thanks to the MoSA and MoFFN Lightweight design for , In this paper, the MTB Than vanilla transformer block Less computational overhead . As shown in the table above ,MTB Of FLOPs About more than normal Transformer Small block 2.2 times .
Building efficient networks with Mobile Transformer Block
In this part , The author will introduce how to use MTB The combination convolution network and Transformer A lightweight network of networks MoCoViT.
Pictured 2 Shown , In this paper, the MoCoViT Adopt characteristic pyramid structure , The resolution of feature mapping decreases with the increase of network depth , The number of channels increases . The author divides the whole architecture into 4 Stages , Use only in the deepest stages MTB.
This is mainly based on two considerations : First of all , The computational complexity of self - attention and spatial resolution are quadratic . In the shallow stage , Features have high spatial resolution , This leads to large computational overhead and memory consumption . secondly , In the early stages of lightweight networks , Due to the limited representation ability of the network , Building a global representation is a relatively difficult task .transformer The advantage of block is to extract global information , and CNN Good at extracting local information . therefore , In the shallow layer of the network , Use CNN Block is helpful to improve the efficiency of feature extraction .

In this paper, the MoCoViT The structural details of the are shown in the table above . The author used at an early stage Ghost bottleneck, It is widely used in mobile devices ( Such as smart phones and autonomous vehicle ). Except that the last step in each stage is 2, all Ghost bottleneck All in steps of 1 In the case of . What this article puts forward MTB Used in the final stage . Last , Using global average pooling and convolution layer, the feature map is transformed into 1280 Dimensional feature vector for final classification .
To further improve performance , The author introduces dynamic ReLU Activate the function to build MoCoViT-D Model . The overall framework of the network is MoCoViT identical . The difference is that will transformer block and CNN block Of ReLU Instead of dynamic ReLU.
04
experiment

In the above table , The author will MoCoViT Transformer With the most advanced CNN and Transformer The architecture is compared . Lightweight with manual design CNN and Transformer comparison ,MoCoViT Can be at a lower FLOPs To achieve higher precision .

As shown in the table above , For the use of RetinaNet Target detection for ,MoCoViT exceed MobileNetV34.2% Of mAP, exceed GhostNet 2.1% Of mAP, Calculating costs is similar .

As shown in the table above , For the use of Mask R-CNN Target detection of framework ,MoCoViT Than MobileNetV3 and GhostNet It brings a similar performance improvement .
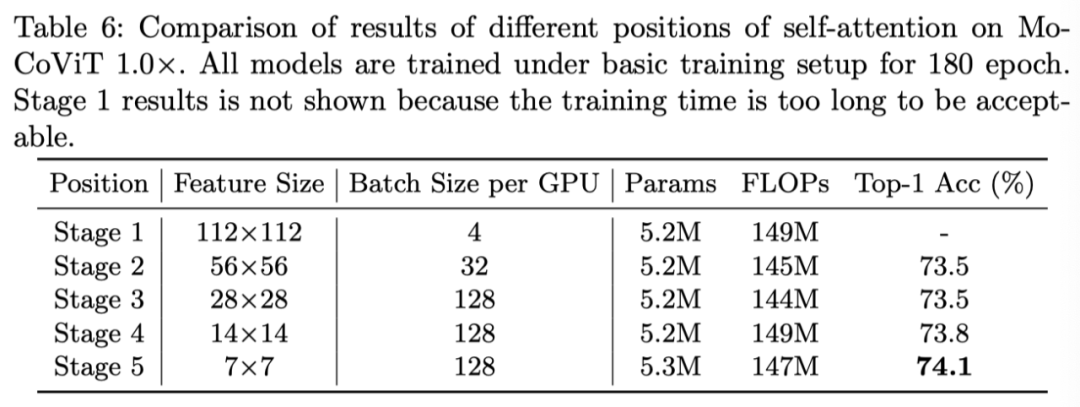
The authors compared the use of mobile at different stages Transformer Block precision , The results are shown in the table above .

In this paper, the MoCoViT Contains two important designs :MoSA and MoFFN. To prove its importance , The author set the basic training as baseline, Yes GhostNet 0.5× the 180 individual epoch Training for . then , Compare different types of self - attention mechanisms to evaluate performance , The results are shown in the table above .

Besides , The author also compares BatchNorm(BN) and LayerNorm(LN) Performance at different locations . As shown in the table above , In self - attention and MLP The module is placed after the convolution operation BN Can improve the accuracy , And it is helpful to merge at deployment time BN And convolutions , To further speed up .
05
summary
In this paper , The author designed a new type of high-efficiency mobile Transformer block (MTB). This module consists of two important modules : Mobile self attention (MoSA) And mobile feedforward network (MoFFN).MoSA The branch sharing mechanism simplifies attention map The calculation of , Avoid calculating in self - attention Q and K, And reuse V To calculate attention map.MoSA Of FLOPs Than vanilla self-attention low 3.6 times .
Besides , The proposed MoFFN It can also greatly reduce vanilla MLP Amount of computation , It can be seen as a mobile version . And vanilla Different ,MoFFN Have the perception ability of spatial dimension . It is better than vanilla MLP Have a greater receptive field . Except for extraction token Characteristics of the channel dimension , It can also perform feature fusion in the spatial dimension .
Equipped with MTB, The author constructs a combination of convolution network and Transformer The lightweight of the network Transformer The Internet MoCoViT and MoCoViT-D. A lot of experiments show that , Introduced MoCoViT The series is superior to... In various visual tasks SOTA Lightweight of CNN and transformers, At the same time, the computational efficiency is maintained .
Reference material
[1]https://arxiv.org/abs/2205.12635

END
Join in 「 Lightweight networks 」 Exchange group notes :LW

边栏推荐
- Golang learning notes - structure
- Win10 installation net3.5. docx
- How swiftui simulates the animation effect of view illumination increase
- PlainSelect.getGroupBy()Lnet/sf/jsqlparser/statement/select/GroupByElement;
- R language airpassengers dataset visualization
- es 按条件查询数据总条数
- Easyclick fixed status log window
- One line of code binds swiftui view animation for a specific state
- 大势智慧创建倾斜模型和切割单体化
- R语言penguins数据集可视化
猜你喜欢




![[redis]三种新数据类型](/img/ce/8a048bd36b21bfa562143dd2e47131.png)



![[redis]redis6 transaction operations](/img/50/639867a2fcb92082ea262a8a19bb68.png)
随机推荐
R language usarrests dataset visualization
苹果CoreFoundation源代码
R语言AirPassengers数据集可视化
R language Midwest dataset visualization
Moke 5. Service discovery -nacos
R语言 co2数据集 可视化
PHP image making
es 按条件查询数据总条数
Set up your own website (12)
Apple Objective-C source code
Use Charles to capture packets
View Apple product warranty status
94-SQL优化案例一则(用到的写法经常是被嫌弃的)
Correspondence between int and char in C language
【21. 合并两个有序链表】
R language universalbank CSV "data analysis
Overview of common loss functions for in-depth learning: basic forms, principles and characteristics
[redis] cluster and common errors
How swiftui simulates the animation effect of view illumination increase
华为云发布拉美互联网战略