当前位置:网站首页>人脸识别损失函数的汇总 | Pytorch版本实现
人脸识别损失函数的汇总 | Pytorch版本实现
2022-08-03 15:33:00 【小白学视觉】
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
这篇文章的重点不在于讲解FR的各种Loss,因为知乎上已经有很多,搜一下就好,本文主要提供了各种Loss的Pytorch实现以及Mnist的可视化实验,一方面让大家借助代码更深刻地理解Loss的设计,另一方面直观的比较各种Loss的有效性,是否涨点并不是我关注的重点,因为这些Loss的设计理念之一就是增大收敛难度,所以在Mnist这样的简单任务上训练同样的epoch,先进的Loss并不一定能带来点数的提升,但从视觉效果可以明显的看出特征的分离程度,而且从另一方面来说,分类正确不代表一定能能在用欧式/余弦距离做1:1验证的时候也正确...
本文主要仿照CenterLoss文中的实验结构,使用了一个相对复杂一些的LeNet升级版网络,把输入图片Embedding成2维特征向量以便于可视化。
对了,代码里用到了TensorBoardX来可视化,当然如果你没装,可以注释掉相关代码,我也写了本地保存图片,虽然很不喜欢TensorFlow,但TensorBoard还是真香,比Visdom强太多了...
早就想写这篇文章了,趁着五一假期终于...
具体代码在Github:github.com/MccreeZhao/F 有兴趣的话点个Star呀~虽然刚起步还没什么东西
文章里只展示loss写法
Softmax
公式推导

Pytorch代码实现
class Linear(nn.Module):
def __init__(self):
super(Linear, self).__init__()
self.weight = nn.Parameter(torch.Tensor(2, 10)) # (input,output)
nn.init.xavier_uniform_(self.weight)
def forward(self, x, label):
out = x.mm(self.weight)
loss = F.cross_entropy(out, label)
return out, lossemmm...现实生活中根本没人会这么写好吧!明明就有现成的Linear层啊喂!
写成这样只是为了方便统一框架...
可视化
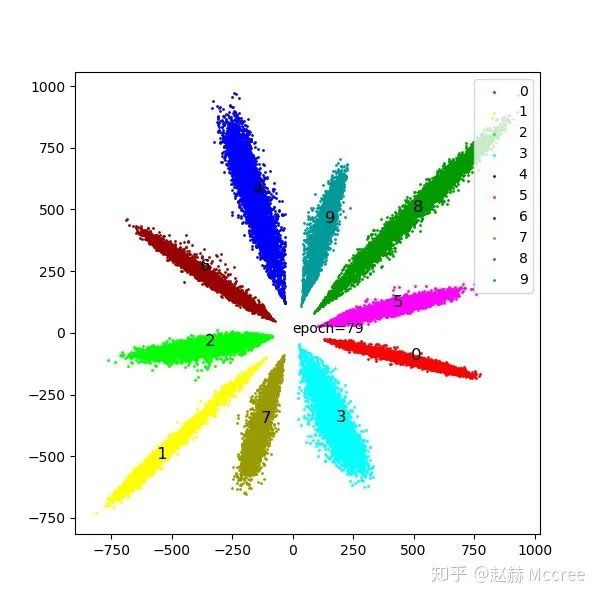
这一张图是二维化的特征,注意观察不同两类任意点之间的余弦距离和欧氏距离
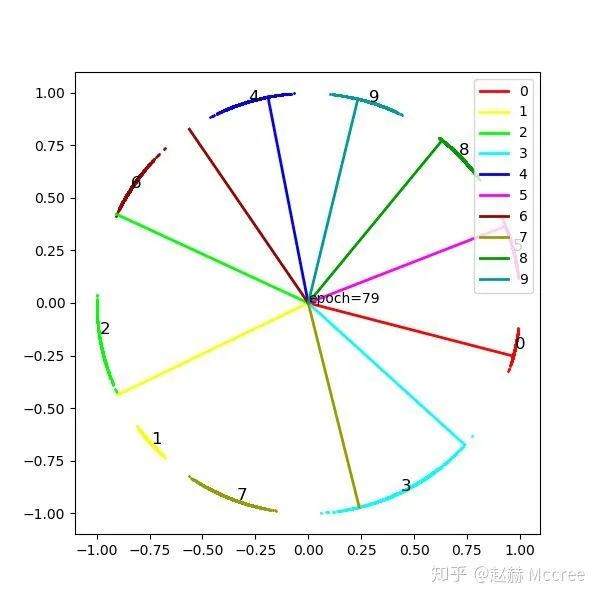
这张图是将特征归一化的结果,能更好的反映余弦距离,竖线是该类在最后一个FC层的权重,等同于类别中心(这一点对于理解loss的发展还是挺关键的)
后面的图片也都是这种形式,大家可以比较着来看
Modified Softmax
公式推导
去除了权重的模长和偏置对loss的影响,将特征映射到了超球面,同时避免了样本量差异带来的预测倾向性(样本量大可能导致权重模长偏大)
Pytorch代码实现
class Modified(nn.Module):
def __init__(self):
super(Modified, self).__init__()
self.weight = nn.Parameter(torch.Tensor(2,10))#(input,output)
nn.init.xavier_uniform_(self.weight)
self.weight.data.uniform_(-1,1).renorm_(2,1,1e-5).mul_(1e5)
#因为renorm采用的是maxnorm,所以先缩小再放大以防止norm结果小于1
def forward(self, x):
w=self.weight
ww=w.renorm(2,1,1e-5).mul(1e5)
out = x.mm(ww)
return out可视化
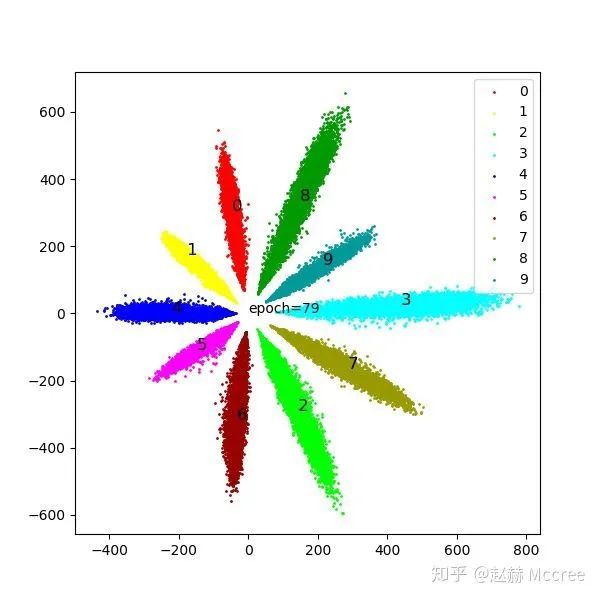
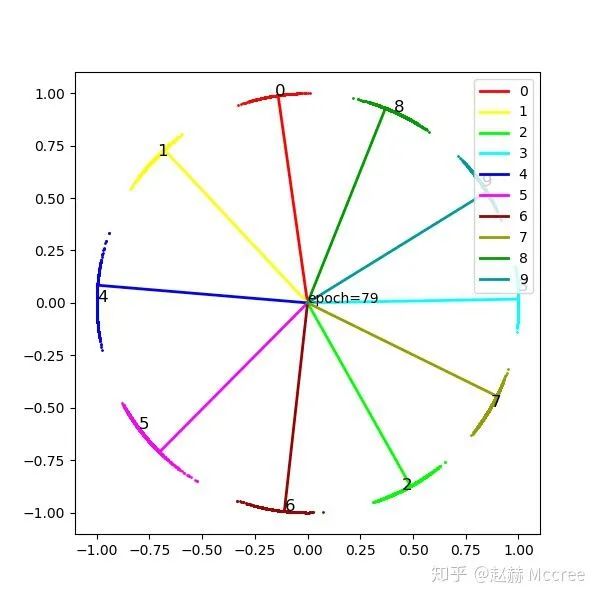
这里要提一句,如果大家留心的话可以发现,虽然modified loss并没有太好的聚拢效果,但确让类别中心准确地落在了feature的中心,这对于网络的性能是有很大好处的,但是具体原因我没想出来...希望能有大佬在评论区给解释一下...
NormFace
既然权重的模长有影响,Feature的模长必然也有影响,具体还是看文章,另外,质量差的图片feature模长往往较短,做normalize之后消除了这个影响,有利有弊,还没有达成一致观点,目前主流的Loss还是包括feature normalize的
公式推导
可视化
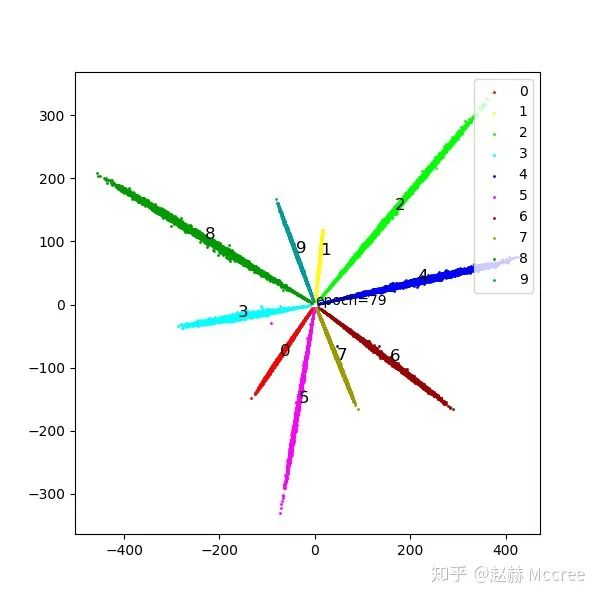
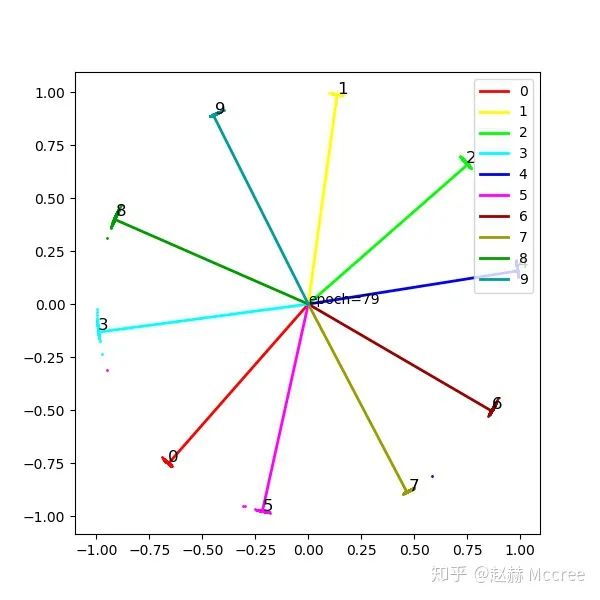
就是一个字:猛!感觉有了NormFace,后面的花式Loss都体现不出来效果了...
Pytorch代码实现
class NormFace(nn.Module):
def __init__(self):
super(NormFace, self).__init__()
self.weight = nn.Parameter(torch.Tensor(2, 10)) # (input,output)
nn.init.xavier_uniform_(self.weight)
self.weight.data.uniform_(-1, 1).renorm_(2, 1, 1e-5).mul_(1e5)
self.s = 16
# 因为renorm采用的是maxnorm,所以先缩小再放大以防止norm结果小于1
def forward(self, x, label):
cosine = F.normalize(x).mm(F.normalize(self.weight, dim=0))
loss = F.cross_entropy(self.s * cosine, label)
return cosine, lossSphereFace:A-softmax
为了进一步约束特征向量之间的余弦距离,我们人为地增加收敛难度,给两个向量之间的夹角乘上一个因子:m
公式推导
Pytorch代码实现
class SphereFace(nn.Module):
def __init__(self, m=4):
super(SphereFace, self).__init__()
self.weight = nn.Parameter(torch.Tensor(2, 10)) # (input,output)
nn.init.xavier_uniform_(self.weight)
self.weight.data.renorm_(2, 1, 1e-5).mul_(1e5)
self.m = m
self.mlambda = [ # calculate cos(mx)
lambda x: x ** 0,
lambda x: x ** 1,
lambda x: 2 * x ** 2 - 1,
lambda x: 4 * x ** 3 - 3 * x,
lambda x: 8 * x ** 4 - 8 * x ** 2 + 1,
lambda x: 16 * x ** 5 - 20 * x ** 3 + 5 * x
]
self.it = 0
self.LambdaMin = 3
self.LambdaMax = 30000.0
self.gamma = 0
def forward(self, input, label):
# 注意,在原始的A-softmax中是不对x进行标准化的,
# 标准化可以提升性能,也会增加收敛难度,A-softmax本来就很难收敛
cos_theta = F.normalize(input).mm(F.normalize(self.weight, dim=0))
cos_theta = cos_theta.clamp(-1, 1) # 防止出现异常
# 以上计算出了传统意义上的cos_theta,但为了cos(m*theta)的单调递减,需要使用phi_theta
cos_m_theta = self.mlambda[self.m](cos_theta)
# 计算theta,依据theta的区间把k的取值定下来
theta = cos_theta.data.acos()
k = (self.m * theta / 3.1415926).floor()
phi_theta = ((-1) ** k) * cos_m_theta - 2 * k
x_norm = input.pow(2).sum(1).pow(0.5) # 这个地方决定x带不带模长,不带就要乘s
x_cos_theta = cos_theta * x_norm.view(-1, 1)
x_phi_theta = phi_theta * x_norm.view(-1, 1)
############ 以上计算target logit,下面构造loss,退火训练#####
self.it += 1 # 用来调整lambda
target = label.view(-1, 1) # (B,1)
onehot = torch.zeros(target.shape[0], 10).cuda().scatter_(1, target, 1)
lamb = max(self.LambdaMin, self.LambdaMax / (1 + 0.2 * self.it))
output = x_cos_theta * 1.0 # 如果不乘可能会有数值错误?
output[onehot.byte()] -= x_cos_theta[onehot.byte()] * (1.0 + 0) / (1 + lamb)
output[onehot.byte()] += x_phi_theta[onehot.byte()] * (1.0 + 0) / (1 + lamb)
# 到这一步可以等同于原来的Wx+b=y的输出了,
# 到这里使用了Focal Loss,如果直接使用cross_Entropy的话似乎效果会减弱许多
log = F.log_softmax(output, 1)
log = log.gather(1, target)
log = log.view(-1)
pt = log.data.exp()
loss = -1 * (1 - pt) ** self.gamma * log
loss = loss.mean()
# loss = F.cross_entropy(x_cos_theta,target.view(-1))#换成crossEntropy效果会差
return output, loss可视化
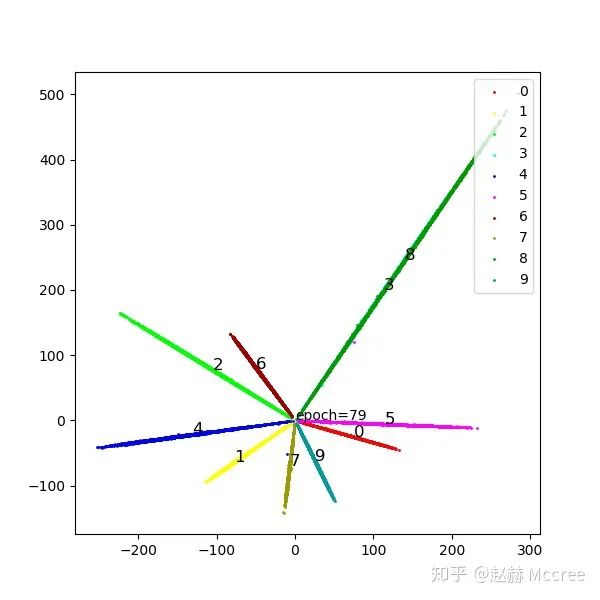
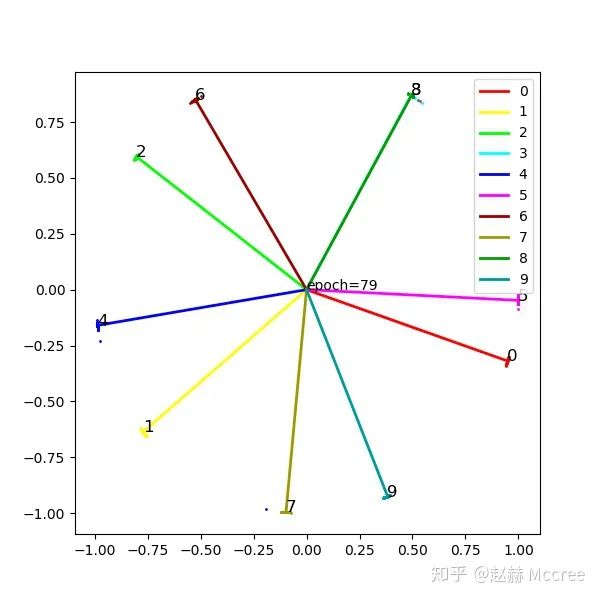
InsightFace(ArcSoftmax)
公式推导
Pytorch代码实现
class ArcMarginProduct(nn.Module):
def __init__(self, s=32, m=0.5):
super(ArcMarginProduct, self).__init__()
self.in_feature = 2
self.out_feature = 10
self.s = s
self.m = m
self.weight = nn.Parameter(torch.Tensor(2, 10)) # (input,output)
nn.init.xavier_uniform_(self.weight)
self.weight.data.renorm_(2, 1, 1e-5).mul_(1e5)
self.cos_m = math.cos(m)
self.sin_m = math.sin(m)
# 为了保证cos(theta+m)在0-pi单调递减:
self.th = math.cos(3.1415926 - m)
self.mm = math.sin(3.1415926 - m) * m
def forward(self, x, label):
cosine = F.normalize(x).mm(F.normalize(self.weight, dim=0))
cosine = cosine.clamp(-1, 1) # 数值稳定
sine = torch.sqrt(torch.max(1.0 - torch.pow(cosine, 2), torch.ones(cosine.shape).cuda() * 1e-7)) # 数值稳定
##print(self.sin_m)
phi = cosine * self.cos_m - sine * self.sin_m # 两角和公式
# # 为了保证cos(theta+m)在0-pi单调递减:
# phi = torch.where((cosine - self.th) > 0, phi, cosine - self.mm)#必要性未知
#
one_hot = torch.zeros_like(cosine)
one_hot.scatter_(1, label.view(-1, 1), 1)
output = (one_hot * phi) + ((1.0 - one_hot) * cosine)
output = output * self.s
loss = F.cross_entropy(output, label)
return output, loss可视化
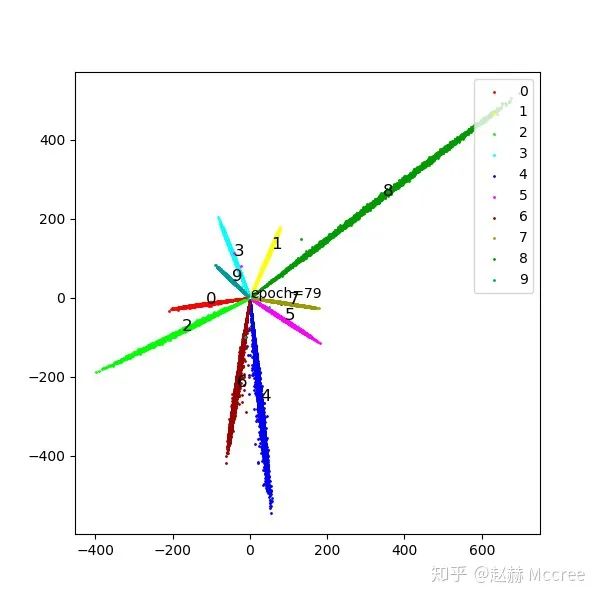
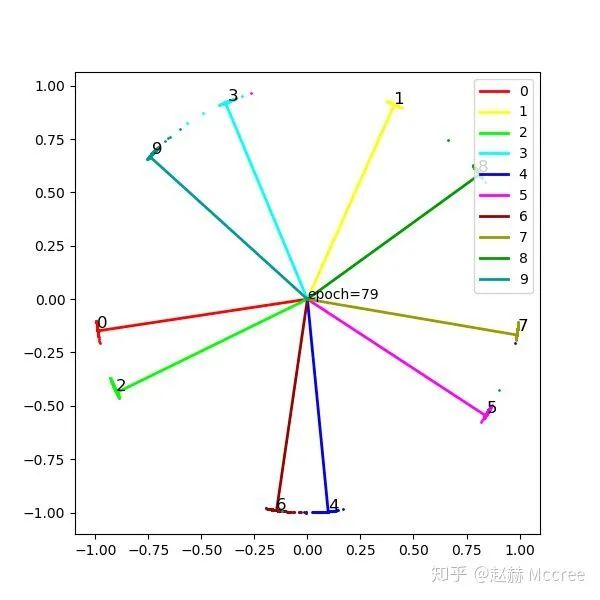
ArcSoftmax需要更久的训练,这个收敛还不够充分...颜值堪忧,另外ArcSoftmax经常出现类别在特征空间分布不均匀的情况,这个也有点费解,难道在训FR模型的时候先用softmax然后慢慢加margin有奇效?SphereFace那种退火的训练方式效果好会不会和这个有关呢...
Center Loss
乱入一个欧式距离的细作
公式推导
其中 是每个类别对应的一个中心,在这里就是一个二维坐标啦
Pytorch代码实现
class centerloss(nn.Module):
def __init__(self):
super(centerloss, self).__init__()
self.center = nn.Parameter(10 * torch.randn(10, 2))
self.lamda = 0.2
self.weight = nn.Parameter(torch.Tensor(2, 10)) # (input,output)
nn.init.xavier_uniform_(self.weight)
def forward(self, feature, label):
batch_size = label.size()[0]
nCenter = self.center.index_select(dim=0, index=label)
distance = feature.dist(nCenter)
centerloss = (1 / 2.0 / batch_size) * distance
out = feature.mm(self.weight)
ceLoss = F.cross_entropy(out, label)
return out, ceLoss + self.lamda * centerloss这里实现的是center的部分,还要跟原始的CEloss相加的,具体看github吧
可视化
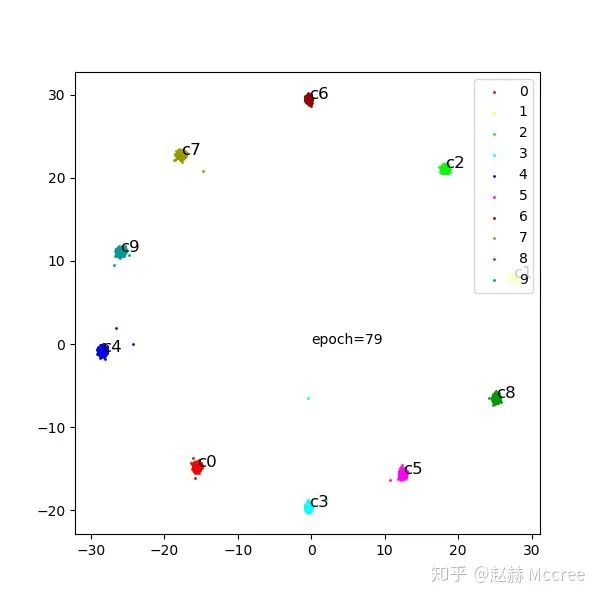
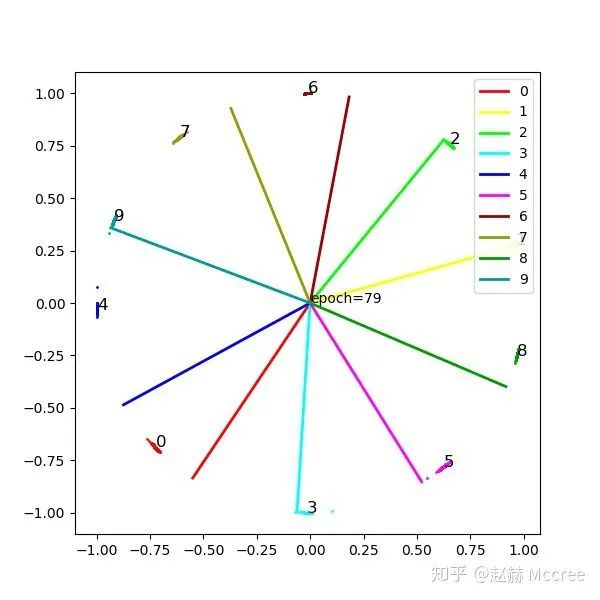
会不会配合weight norm效果更佳呢?以后再说吧...
总结
先写到这里,如果大家有兴趣可以去github点个star之类的...作为一个研一快结束的弱鸡刚刚学会使用github...也是没谁了...
参考文献:
Wang M, Deng W. Deep face recognition: A survey[J]. arXiv preprint arXiv:1804.06655, 2018.
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~边栏推荐
- 方舟开服工具、服务器教程win
- 新版本MaxCompute 的SQL支持 UDF 分区裁剪的逻辑是怎样的?
- 新一代网状网协议T-Mesh无线通信技术优势介绍
- How Navicat connects to MySQL on a remote server
- 如何用二分法搜索、查找旋转数组中是否含有某个(目标)值? leetcode 81.搜索旋转排序数组
- Js array method is summarized
- How to use binary search and find whether the rotation in the array contains a (target) value?Rotate the sorted array leetcode 81. Search
- 2021年12月电子学会图形化三级编程题解析含答案:数星星
- 2021年12月电子学会图形化四级编程题解析含答案:质数判断器
- leetcode-105 从前序与中序遍历序列构造二叉树-使用栈代替递归
猜你喜欢

随机推荐
力扣1206. 设计跳表--SkipList跳表是怎么跳的?
取消转义字符(r)
未来无法预料
夜神浏览器fiddler抓包
基于matlab的遥测信道的基本特性仿真分析
2021年12月电子学会图形化二级编程题解析含答案:消灭蝙蝠
How Navicat connects to MySQL on a remote server
劲爆!协程终于来了!线程即将是过去式
liunx服务器nohup不输出日志文件的方法
一通骚操作,我把SQL执行效率提高了10000000倍!
0 code 4 steps to experience IoT devices on the cloud
MATLAB gcf figure save image with black background/transparent background
nodeJs--跨域
问题10:注册页面的易用性测试?
Essentially a database data recovery 】 【 database cannot read data recovery case
接口测试主要测试什么?
实习路途:记录给我的第一个实习项目中的困惑
跨桌面端之组件化实践
问题8:对朋友圈进行用例设计
每日练习------有10个数字要求分别用选择法从大到小输出