当前位置:网站首页>[Wu Enda deep learning] beginner learning record 3 (regularization / error reduction)
[Wu Enda deep learning] beginner learning record 3 (regularization / error reduction)
2022-07-04 02:53:00 【Yory__】
Catalog
1. The dimensions of the matrix
2. Regularization ( Methods of reducing test error )
1) Regularization in logistic regression
3) Regularization of neural networks
4) The principle of regularization to reduce over fitting
3.dropout( Random deactivation ) Regularization
2)inverted dropout( Reverse random deactivation )
4. Other regularization methods
1. The dimensions of the matrix

The unity of dimensions allows us to reduce the number of bug, among ![n^{[i]}](http://img.inotgo.com/imagesLocal/202202/14/202202141804142270_7.gif) It means No i Number of nodes in the layer , When there are multiple samples (
It means No i Number of nodes in the layer , When there are multiple samples (![n^{[0]}](http://img.inotgo.com/imagesLocal/202202/14/202202141804142270_10.gif) ,1) Will become (,m),m Is the number of samples , That is, the size of the training set .
,1) Will become (,m),m Is the number of samples , That is, the size of the training set .
2. Regularization ( Methods of reducing test error )
1) Regularization in logistic regression

In the figure L2 refer to L2 Regularization ;L1 refer to L1 Regularization , It's usually used L2 Regularization .
2) Parameters
Parameters
among  This parameter is the regularization parameter , This parameter is usually configured using a validation set or cross validation ( Adjusting the time can avoid over fitting ).
This parameter is the regularization parameter , This parameter is usually configured using a validation set or cross validation ( Adjusting the time can avoid over fitting ).
stay python Under preparation , For the convenience of coding, we use lambd Instead of lambda Regularization parameters .
3) Regularization of neural networks

The matrix norm in the figure is called " Floribeus norm ".
4) The principle of regularization to reduce over fitting
Intuitive understanding is Increase big enough , Can make W The weight of is close to 0(W Reducing the weight is equivalent to reducing the influence of the gradient in all directions , It is equivalent to reducing the dependence on data sets , This leads to under fitting ).
Explain in another intuitive way :
With tanh Function as an example , because and W Is mutual conflict , When increase ,W Just reduce , vice versa . When W Less hours z The value of will also decrease , stay tanh in z The value of is small enough , The function image is nearly linear , I talked about it in the previous class , If each layer is linear , Then the whole network is a linear network . Even a very deep neural network , Because of the characteristics of linear activation function , Finally, only linear functions can be calculated .
So in this case , It is not suitable for very complex decisions and nonlinear decision boundaries of over fitting data sets , Pictured :
3.dropout( Random deactivation ) Regularization
1) principle :
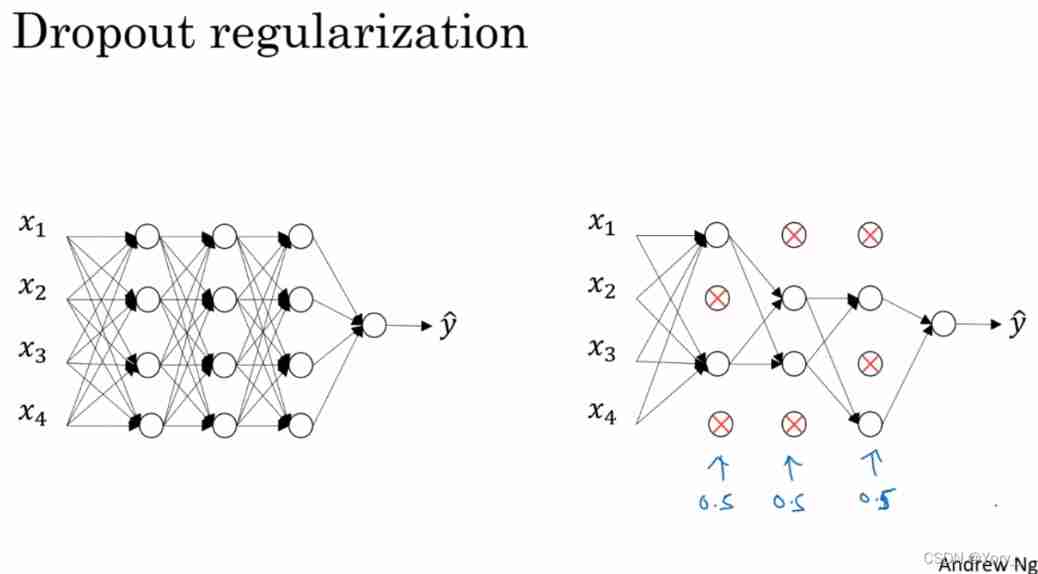
Suppose the left neural network has over fitting , Copy the neural network ,dropout Will traverse every layer of the network and Set the probability of eliminating nodes in the neural network . After setting the node probability, eliminate some nodes , Delete the relevant connection , Thus, there are fewer nodes , Smaller networks , And then use backprop The way to train .
2)inverted dropout( Reverse random deactivation )

Premise in the figure : Suppose God network layer L=3
The blue line is python Code implementation , The green line is inverted dropout The core ( bring a3 Expectations remain the same ),keep_prob Set the probability for (0.8 The meaning is 80% Retain ,20% Eliminate nodes ). When keep_prob The value is equal to the 1 when , This means that all network nodes are preserved .
inverted dropout Divided by keep-prob You can remember the operation of the previous step , The goal is to make sure that even if you don't perform during the test phase dropout To adjust the range of values , The expected result of the activation function will not change .
3) Summary
dropout It is mostly used in computer vision ( Where there is not enough data , There has always been fitting ).
shortcoming :cost function J No longer clearly defined , Every iteration will randomly remove some nodes , It is difficult to check the performance of gradient descent ( Method : take keep_prob Set to 1)
4. Other regularization methods
1) Data amplification 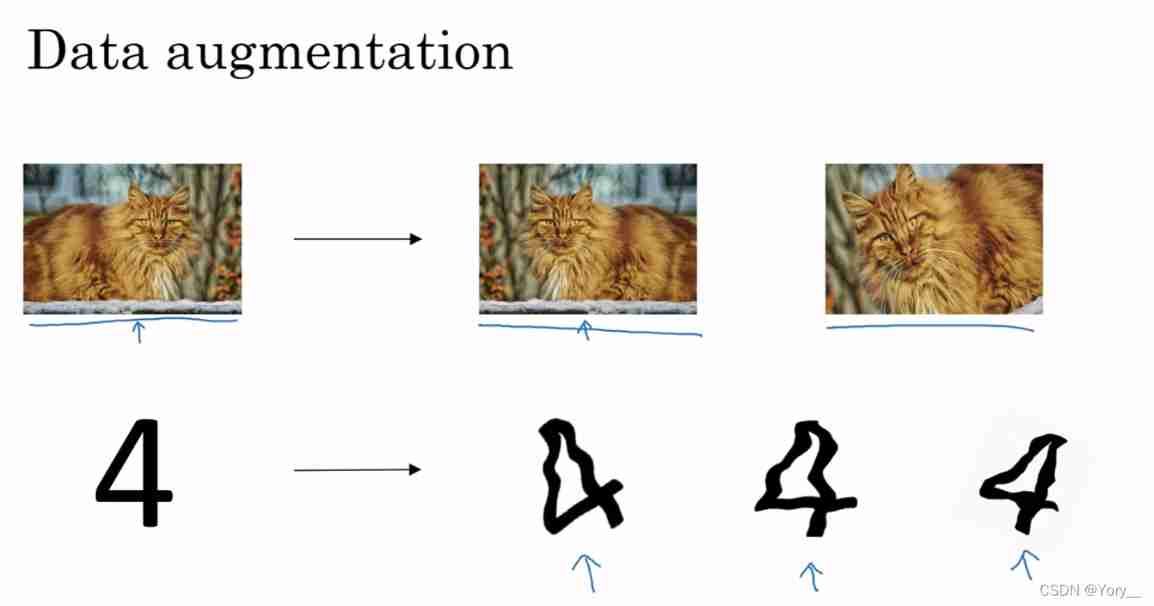
The picture above flips the cat horizontally , Zoom in and rotate the crop to double the data set , But it needs to be verified whether it is a cat
The figure below is the number 4, Deform and then expand the data set
In this way, although “ false ” Data sets , But there is no cost , The actual function is also similar to regularization .
2)early stopping
adopt early stopping We can not only plot the training error , Cost function J, You can also plot validation set errors ( The classification error of the verification set or the cost function on the verification set , Logic loss and logarithm loss, etc ).
Usually, we will find that the error of verification set will decrease first and then increase ,early stopping The function of neural network is to stop somewhere you think the neural network is good enough , Get the verification set error .
shortcoming : Cost functions cannot be handled independently J And over fitting phenomenon .
advantage : Just run it once to find W The smaller of 、 Median and larger , No need for image L2 Regularization attempts a large number of parameters value
边栏推荐
- Optimization theory: definition of convex function + generalized convex function
- Global and Chinese market of small batteries 2022-2028: Research Report on technology, participants, trends, market size and share
- Yyds dry goods inventory hand-in-hand teach you the development of Tiktok series video batch Downloader
- 150 ppt! The most complete "fair perception machine learning and data mining" tutorial, Dr. AIST Toshihiro kamishima, Japan
- On Valentine's day, I code a programmer's exclusive Bing Dwen Dwen (including the source code for free)
- 2022 examination summary of quality controller - Equipment direction - general basis (quality controller) and examination questions and analysis of quality controller - Equipment direction - general b
- Career development direction
- Global and Chinese market of handheld melanoma scanners 2022-2028: Research Report on technology, participants, trends, market size and share
- Advanced learning of MySQL -- Application -- storage engine
- A. Div. 7
猜你喜欢
Kiss number + close contact problem

17. File i/o buffer

Setting methods, usage methods and common usage scenarios of environment variables in postman

LV1 tire pressure monitoring
Unity knapsack system (code to center and exchange items)
![[Valentine's Day confession code] - Valentine's Day is approaching, and more than 10 romantic love effects are given to the one you love](/img/ab/066923f1aa1e8dd8dcc572cb60a25d.jpg)
[Valentine's Day confession code] - Valentine's Day is approaching, and more than 10 romantic love effects are given to the one you love
WP collection plug-in free WordPress collection hang up plug-in

在尋求人類智能AI的過程中,Meta將賭注押向了自監督學習

Remember another interview trip to Ali, which ends on three sides

(column 23) typical C language problem: find the minimum common multiple and maximum common divisor of two numbers. (two solutions)
随机推荐
Global and Chinese market of digital impression system 2022-2028: Research Report on technology, participants, trends, market size and share
String: LV1 eat hot pot
150 ppt! The most complete "fair perception machine learning and data mining" tutorial, Dr. AIST Toshihiro kamishima, Japan
Leetcode 110 balanced binary tree
The first spring of the new year | a full set of property management application templates are presented, and Bi construction is "out of the box"
Yyds dry goods inventory hand-in-hand teach you the development of Tiktok series video batch Downloader
Zblog collection plug-in does not need authorization to stay away from the cracked version of zblog
Create real-time video chat in unity3d
Basé sur... Netcore Development blog Project Starblog - (14) Implementation of theme switching function
ZABBIX API batch delete a template of the host
Global and Chinese markets for electroencephalogram (EEG) devices 2022-2028: Research Report on technology, participants, trends, market size and share
Contest3145 - the 37th game of 2021 freshman individual training match_ J: Eat radish
(column 23) typical C language problem: find the minimum common multiple and maximum common divisor of two numbers. (two solutions)
96% of the collected traffic is prevented by bubble mart of cloud hosting
Tsinghua University product: penalty gradient norm improves generalization of deep learning model
Solve the problem that the tabbar navigation at the bottom of vantui does not correspond to the page (window.loading.hash)
Node write API
2022 registration examination for safety production management personnel of fireworks and firecracker production units and examination skills for safety production management personnel of fireworks an
Global and Chinese market of box seals 2022-2028: Research Report on technology, participants, trends, market size and share
Contest3145 - the 37th game of 2021 freshman individual training match_ 1: Origami