当前位置:网站首页>Pourquoi Google Search ne peut - il pas Pager indéfiniment?
Pourquoi Google Search ne peut - il pas Pager indéfiniment?
2022-06-11 22:50:00 【Les Cigales se baignent dans le vent】

C'est une question très intéressante mais peu remarquée.
Quand j'utiliseGoogleRechercheMySQLQuand ce mot - clé,GoogleUniquement disponible13Résultats de recherche pour la page,J'ai modifiéurlLe paramètre de pagination de a tenté de rechercher la page14Données de page,Les messages d'erreur suivants se sont produits:

Baidu Search n'offre pas non plus de pagination illimitée,PourMySQLMots clés,Baidu Search offre76Résultats de recherche pour la page.

Pourquoi ne pas prendre en charge la pagination infinie
Plus fort queGoogleRecherche,Pourquoi ne pas prendre en charge la pagination infinie?Il y a deux possibilités:
- Je ne peux pas.
- Ce n'est pas nécessaire.
「Je ne peux pas.」C'est impossible.,La seule raison est「Ce n'est pas nécessaire.」.
Tout d'abord,,Quand1Lorsque les résultats de recherche de la page n'ont pas ce dont nous avons besoin,Nous changeons souvent les mots clés immédiatement,Au lieu de tourner la page2(En milliers de dollars des États - Unis),Sans parler de tourner vers10La page est en arrière.C'est une première raison inutile.——La demande des utilisateurs n'est pas forte.
Deuxièmement,,La fonctionnalité de pagination infinie est très coûteuse pour les moteurs de recherche.Tu pourrais te sentir bizarre.,Retourner à la page2Page et retourner à la page1000Les pages ne sont pas toutes des recherches,Quelle différence?
En fait,,L'un des effets secondaires de la conception d'un moteur de recherche à haute disponibilité et extensibilité est qu'il n'est pas efficace d'atteindre la fonctionnalité de pagination infinie,Ne pas être efficace signifie être capable,Mais c'est plus cher.,C'est un problème pour tous les moteurs de recherche,Professionnellement appelé「Page de profondeur」.C'est une deuxième raison inutile.——Coûts de réalisation élevés.
Je ne sais pasGoogleComment la recherche a - t - elle été effectuée?,Alors je vais utiliserES(Elasticsearch)Par exemple, expliquez pourquoi la pagination profonde est un problème de tête pour les moteurs de recherche.
Pourquoi prendreESExemple
Elasticsearch(Ci - après dénomméES)Fonctions réalisées etGoogleEt Baidu Search offre la même fonctionnalité,Et il y a des similitudes et des différences dans la façon d'atteindre une grande disponibilité et une grande extensibilité,Les problèmes de pagination profonde sont tous dus à ces méthodes d'optimisation très similaires.
Qu'est - ce queES
ESEst un moteur de recherche plein texte.
Qu'est - ce qu'un moteur de recherche plein texte??
Imaginez une scène,Vous avez entendu une chanson avec une mélodie particulièrement belle,Quand je suis rentré à la maison, j'ai senti le bruit.,Mais tu ne te souviens que de quelques mots d'une chanson:「Le bord du parapluie」.C'est là que les moteurs de recherche fonctionnent..
En utilisant le moteur de recherche, vous pouvez obtenir「Le bord du parapluie」Tous les résultats pour les mots clés,Il y a un terme pour ces résultats,Appelé document.Et les résultats de la recherche sont retournés après avoir été triés en fonction de la corrélation entre le document et le mot - clé.Nous avons la définition d'un moteur de recherche en texte intégral:
Le moteur de recherche plein texte estRechercher les documents pertinents en fonction du contenu du document,Et conformément àOrdre de corrélationUn outil pour retourner les résultats de la recherche
Surfer sur Internet trop longtemps,Peu à peu, nous confondons les capacités informatiques avec les capacités que nous possédons,Par exemple, nous pourrions penser à tort que notre cerveau lui - même est bon pour ce genre de recherche.Au contraire.,La fonction de recherche en texte intégral est très mauvaise pour nous.
Par exemple,,Si je te disais:Méditation nocturne.Tu pourrais le dire:La lune brille devant le lit,Je pense que c'est du gel sur le sol.Lève la tête et regarde la lune,Je pense à ma ville natale.Mais si je vous demande de dire「Mois」Vers anciens,Je suppose que vous devez faire un effort pour payer vos cotisations..
Il en va de même pour les livres que nous lisons habituellement.,Le catalogue lui - même est une structure de recherche qui correspond aux caractéristiques de notre recherche cérébrale,Nous permet d'utiliser la documentationIDOu le titre d'un document, un identificateur général pour trouver un document,Cette structure s'appelleIndex positif.

Et le moteur de recherche plein texte est l'inverse,Recherche de documents à partir du contenu du document,"Flying Flowers in Poetry Congress" est un moteur de recherche en texte intégral pour la version cerveau humain.

Les moteurs de recherche en texte intégral reposent sur des structures de données bien connuesIndex inversé(「À l'envers.」Ce mot signifie que cette structure de données est exactement l'opposé de notre façon normale de penser),Il s'agit d'une mise en oeuvre concrète de la relation d'inclusion entre un mot et un document.

Arrêtez!!On ne peut pas continuer.,Un mot pour finir.ESC'est parti.!
ESC'est unUtiliser une structure de données d'index inversée、Possibilité de trouver des documents pertinents en fonction du contenu du document,Et conformément àOrdre de corrélationMoteur de recherche plein texte qui renvoie les résultats de la recherche
Secret très disponible——Copie(Replication)
Haute disponibilitéEst un indicateur que les services au niveau de l'entreprise doivent prendre en considération,Une disponibilité élevée implique nécessairement le regroupement et la distribution,Heureusement queESMode cluster de soutien naturel,Un système distribué peut être construit très simplement.
ESLa disponibilité élevée du service exige que l'un des noeuds soit suspendu,Impossible d'affecter le Service de recherche normal.Cela signifie que les données stockées sur le noeud suspendu,Il doit êtreSauvegarde complète sur d'autres noeuds.C'est le concept de copie..

Comme le montre la figure ci - dessus,Node1En tant que noeud maître,Node2EtNode3Les mêmes données que le noeud maître ont été sauvegardées en tant que noeud de copie,De cette façon, aucun noeud suspendu n'affectera la recherche d'affaires.Répondre aux exigences de disponibilité élevée du Service.
Mais il y a un problème mortel,Échec de l'expansion du système!Même si vous ajoutez un autre noeud,L'expansion de la capacité de l'ensemble du système n'a pas non plus aidé.Parce que chaque noeud contient toutes les données du document.
Donc,,ESIntroduction du fractionnement(Shard)Le concept de.
PBLa pierre angulaire du nombre d'ordres——Fractionnement(Shard)
ESPour chaque index(ESCollection d'une série de documents,équivalent àMySQLTable in)Diviser en tranches,Les tranchesAussi moyen que possibleAssigner à différents noeuds.Par exemple, il y a maintenant une grappe3Noeud de station,L'index est divisé en5Pièce (s),Répartition approximative(Parce que la répartition dépendES)Comme le montre la figure ci - dessous.
C'est comme ça.,L'expansion latérale du cluster est très simple,Maintenant, ajoutons - le au cluster2Noeuds,EtESégalise automatiquement les tranches sur chaque noeud:
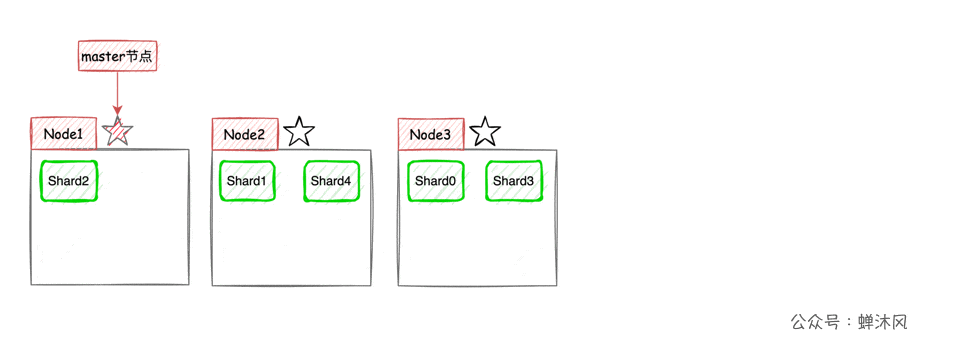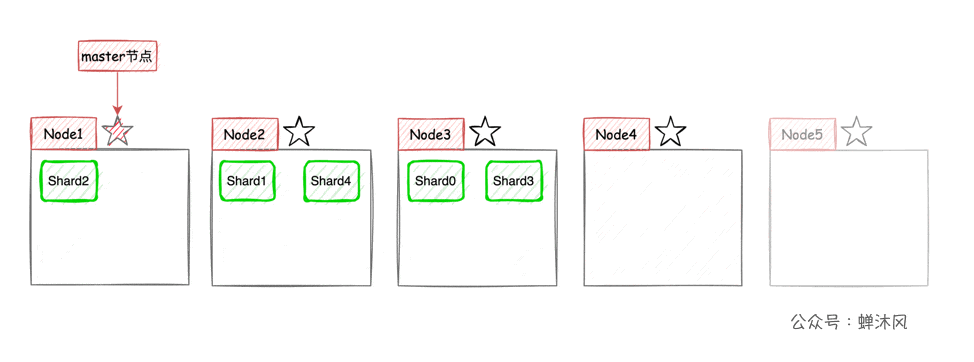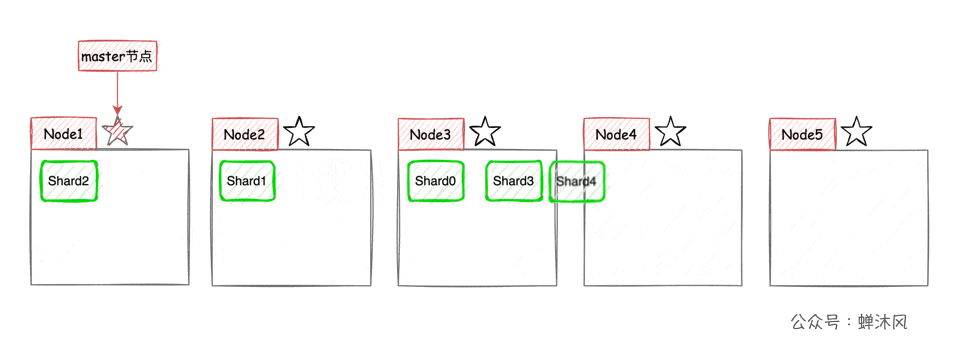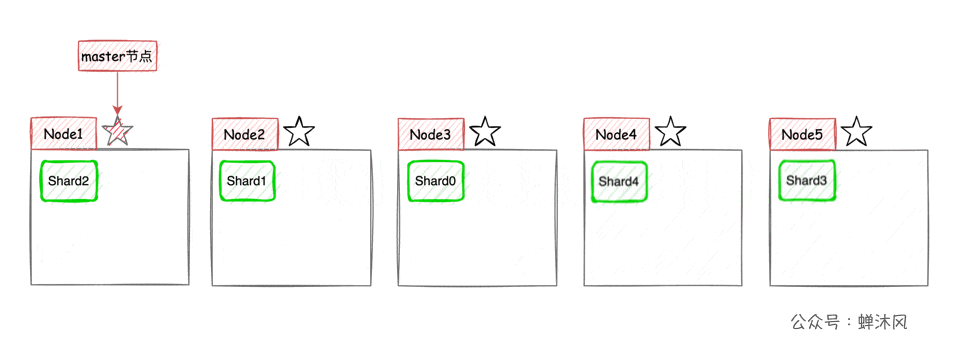
Haute disponibilité + Expansion élastique
Les fonctions de copie et de partition fonctionnent ensemble pour créerESAujourd'huiHaute disponibilitéEtSoutienPBQuantité de données de niveauDeux avantages de.
Maintenant, nous prenons3Exemples de noeuds,Montrer le nombre de pièces5,Le nombre d'exemplaires est de1Dans le cas de,ESRépartition des tranches sur différents noeuds:

Il y a un point à noter,Dans l'exemple ci - dessus, le fragment principal et le fragment de copie correspondant n'apparaissent pas sur le même noeud,Et pourquoi?,Vous pouvez penser par vous - mêmes..
Stockage distribué des documents
ESComment déterminer sur quel fragment un document doit être stocké?

Par l'algorithme de cartographie ci - dessus,ESRépartir uniformément les données du document entre les tranches,Parmi euxroutingPar défaut, le documentid.
En outre,Le contenu du fragment de copie dépend du fragment principal pour la synchronisation,La signification de l'existence du fragment de réplique est l'équilibrage de la charge、Position de la tranche principale sur le dessus qui peut être accrochée à tout moment,Devenir un nouveau fragment principal.
Les bases sont terminées.,On peut enfin faire une recherche..
ESMécanisme de recherche pour
Une image vaut mille mots:
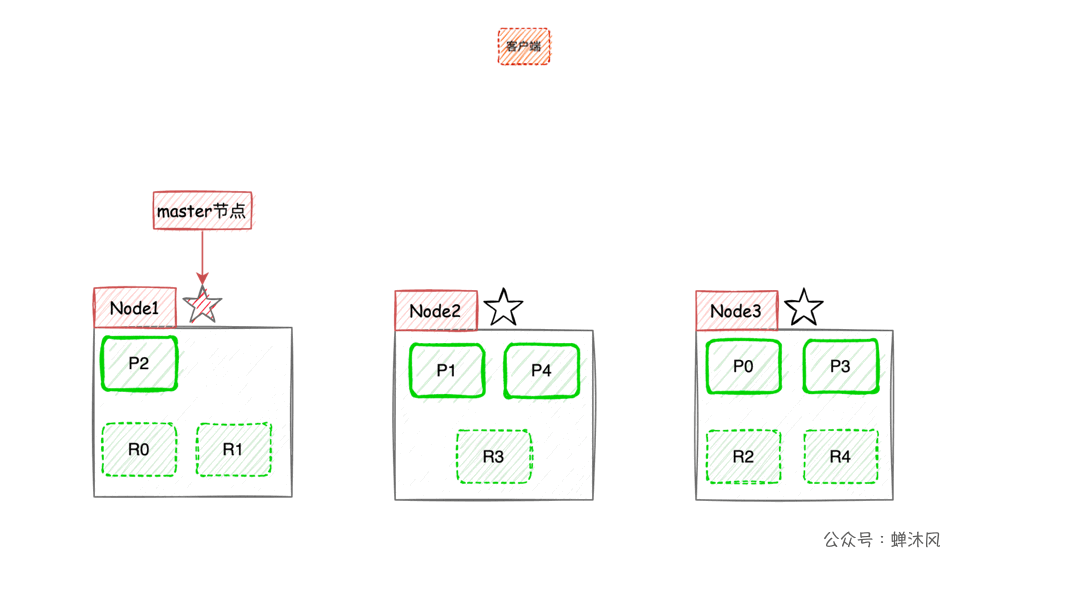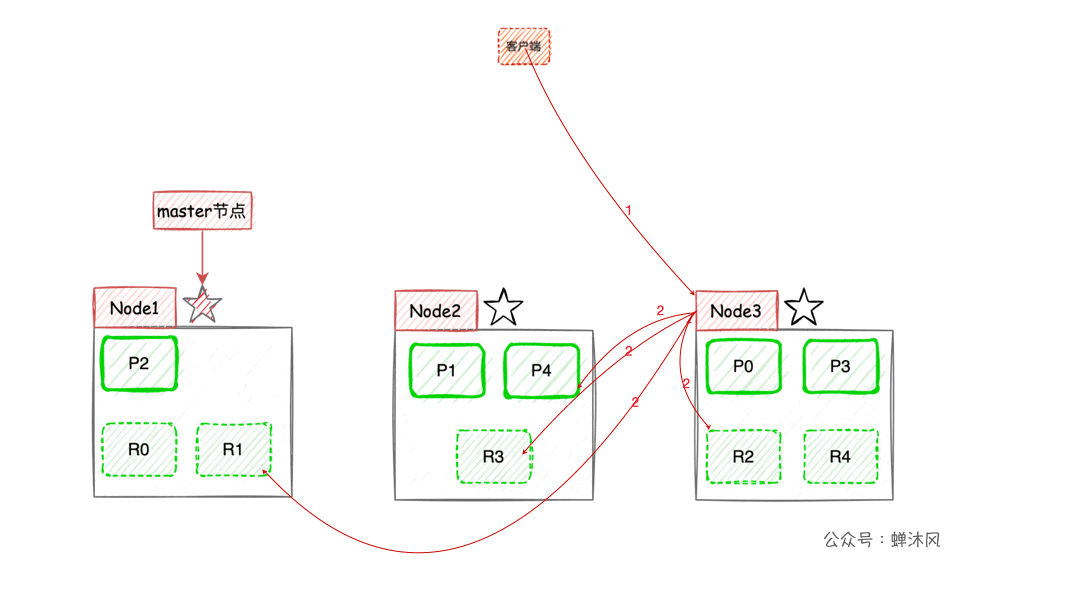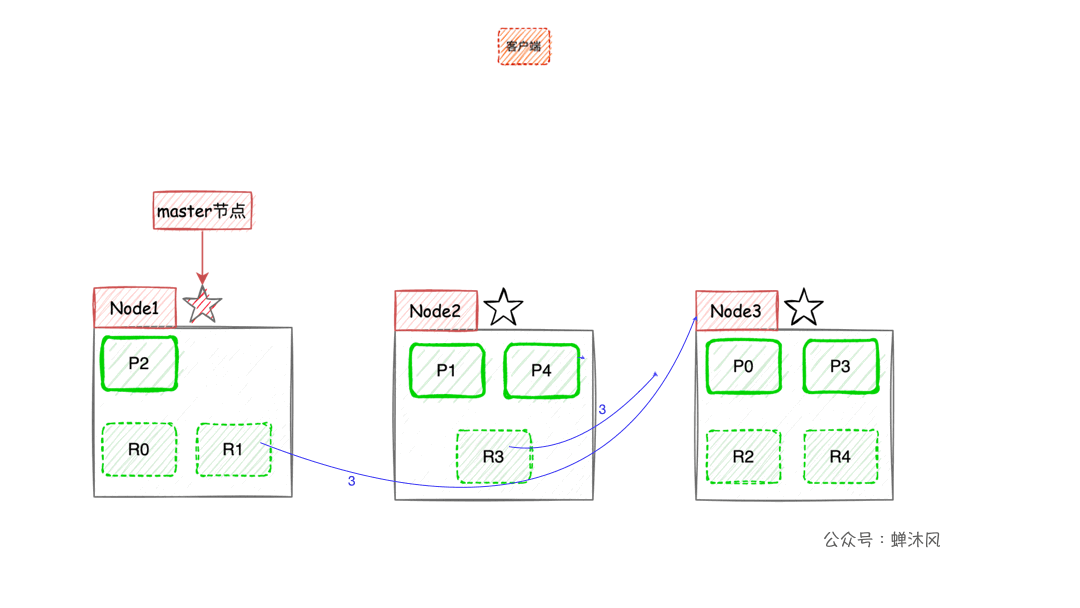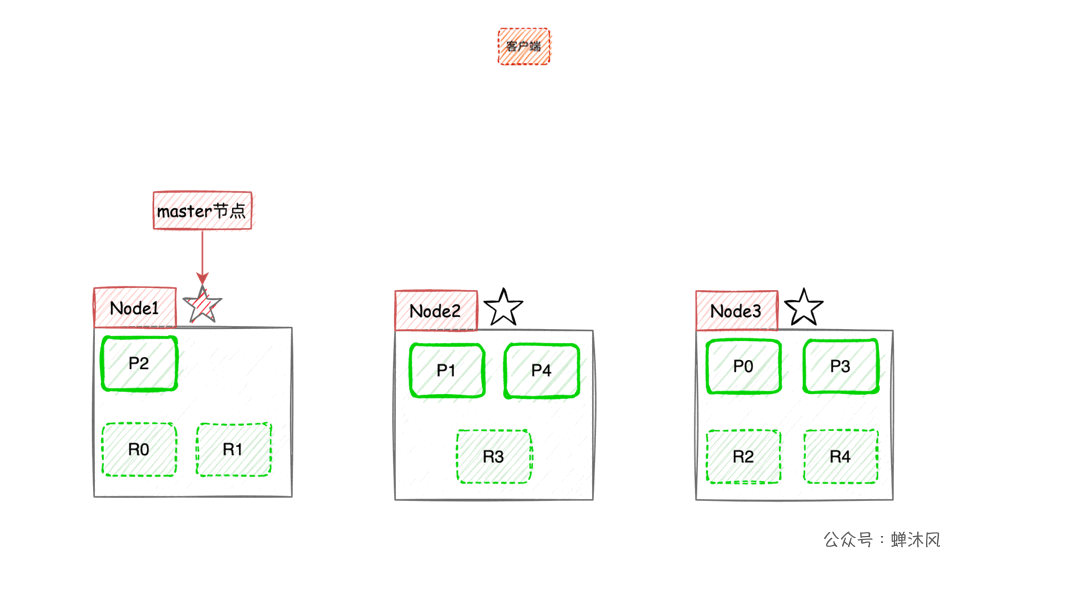
- Lorsque le client effectue une recherche par mot - clé,
ESUn noeud est sélectionné comme noeud de coordination en utilisant la politique d'équilibrage de charge(Coordinating Node)Accepter la demande,Supposons que vous choisissiezNode3Noeud; Node3Les noeuds seront10Sélection aléatoire dans les tranches principales et secondaires5Pièce (s)(Toutes les tranches doivent contenir tout le contenu,Et ne peut pas être répété),Envoyersearch request;- Sélectionné5Les résultats sont retournés à
Node3Noeud; Node3Consolidation des noeuds5Résultats retournés par tranche,Après avoir trié à nouveau, récupérez l'ensemble de résultats correspondant à la pagination et retournez - le au client.
Note::En fait,
ESLa recherche pourQueryPhaseEtFetchPhaseDeux étapes,InQueryPhaseChaque tranche renvoie un documentIdEt trier les valeurs,FetchPhaseSelon la documentationIdPour obtenir des détails sur le document,L'image et la description textuelle ci - dessus simplifient cela,Je vous en prie..
Considérez maintenant l'acquisition par le client990~1000Lorsque le document,ESComment donner les bons résultats de recherche dans le cas d'un stockage fractionné.
Accès990~1000Lorsque le document,ESBesoin d'obtenir sous chaque tranche1000Documents,Puis parCoordinating NodeRésultats de l'agrégation de toutes les tranches,Puis trier les dépendances,Enfin, l'ordre de corrélation est sélectionné dans990~1000De10Documents.

Plus le nombre de pages est profond,Plus chaque noeud traite de documents,Plus de mémoire est utilisée,Plus ça prend de temps.,C'est pourquoi les fournisseurs de moteurs de recherche n'offrent généralement pas de pagination profonde,Ils n'ont pas besoin de gaspiller des performances sur des fonctionnalités dont les clients n'ont pas besoin.
Numéro public:Les Cigales se baignent dans le vent,Concentre - toi sur moi.,Obtenez plus
Terminé..
边栏推荐
- Three years of college should be like this
- 【Uniapp 原生插件】商米钱箱插件
- Tensorflow [actual Google deep learning framework] uses HDF5 to process large data sets with tflearn
- 5. Xuecheng project Alipay payment
- Exercise 8-5 using functions to realize partial copying of strings (20 points)
- [Matlab]二阶节约响应
- 华为云、OBS、
- Basic operation of graph (C language)
- What is deadlock? (explain the deadlock to everyone and know what it is, why it is used and how to use it)
- Getting started with message queuing MQ
猜你喜欢

Tkinter study notes (II)
![[solution] solution to asymmetric and abnormal transformation caused by modifying the transform information of sub objects](/img/52/7e741154e4d6e61c5df7e8701ab177.png)
[solution] solution to asymmetric and abnormal transformation caused by modifying the transform information of sub objects

PHP+MYSQL图书管理系统(课设)
基于模板配置的数据可视化平台

volatile的解构| 社区征文

16 | floating point numbers and fixed-point numbers (Part 2): what is the use of a deep understanding of floating-point numbers?
小程序启动性能优化实践

Fastapi 5 - common requests and use of postman and curl (parameters, x-www-form-urlencoded, raw)

A simple example of linear regression in machine learning

Simple example of logistic regression for machine learning
随机推荐
[data mining time series analysis] restaurant sales forecast
习题10-1 判断满足条件的三位数 (15 分)
Exercise 9-5 address book sorting (20 points)
C# List. Can foreach temporarily / at any time terminate a loop?
Research Report on development trend and competitive strategy of global wafer recycling and OEM service industry
Stack栈的实现
Point cloud read / write (2): read / write TXT point cloud (space separated | comma separated)
Exercise 11-2 find week (15 points)
leetcode 257. Binary tree paths all paths to a binary tree (simple)
How to do investment analysis in the real estate industry? This article tells you
SequenceList顺序表的实现
IEEE floating point mantissa even round - round to double
What is deadlock? (explain the deadlock to everyone and know what it is, why it is used and how to use it)
习题8-2 在数组中查找指定元素 (15 分)
华为云、OBS、
Implementation of stack stack
The remote connection to redis is disconnected and reconnected after a while
Is it safe for qiniu business school to send Huatai account? Really?
Matlab point cloud processing (XXV): point cloud generation DEM (pc2dem)
动态规划之0-1背包问题(详解+分析+原码)