当前位置:网站首页>Cifar-10 dataset application: quick start data enhancement method mixup significantly improves image recognition accuracy
Cifar-10 dataset application: quick start data enhancement method mixup significantly improves image recognition accuracy
2022-06-25 07:48:00 【Lattice titanium Engineer】
CIFAR-10 Dataset application : Quick start data enhancement methods Mixup, Significantly improve the accuracy of image recognition
author |Ta-Ying Cheng, A doctoral student at Oxford University ,Medium Technology Blogger , Many articles have been published by the official publications of the platform Towards Data Science Included
translate | Song Xian
In recent years, with the vigorous development of deep learning , Image classification has always been one of the hottest fields . Traditional image recognition relies heavily on image expansion / Erosion or frequency domain transformation , However, the difficulty of feature extraction limits the progress space of these methods .
present Today's neural network has significantly improved the accuracy of image recognition , Because the neural network can find the relationship between the input image and the output label , And constantly adjust its identification strategy .
However , Neural networks often need a lot of data for training , High quality training data is not readily available . So now many people are studying how to realize the so-called Data to enhance (Data augmentation), That is, increase the amount of data in an existing small data set out of thin air , To achieve the effect of one against 100 .
This article will introduce you to a simple and effective data enhancement strategy Mixup, And introduce directly in PyTorch To realize Mixup Methods .
Why data enhancement is needed ?
The parameters in the neural network architecture are trained and updated according to the given data . However, because the training data only covers a certain part of the distribution of possible data , The network is likely to be distributed “ See ” Partial overfitting .
therefore , The more training data we have , In theory, the more it can cover the whole distribution , That's why Data centric AI(data-centric AI) It's very important . Of course , In the case of limited data , It's not that we have no choice . Enhance... With data , We can try to generate new data by fine tuning the original data , And use it as “ new ” Samples are sent to the network for training .
What is? Mixup?
chart 1:Mixup Simple demo of
Suppose what we need to do now is to classify the pictures of cats and dogs , And we already have a set of data marked as cat or dog ( for example [1, 0] -> Dog , [0, 1] -> cat ), that Mixup Simply put, it is to average two images and their labels into a new data .
To be specific , We can use mathematical formulas to write Mixup The concept of :
x = λ x i + ( 1 − λ ) ( x j ) , y = λ y i + ( 1 − λ ) ( y j ) , x = \lambda x_i + ( 1 - \lambda ) (x_j),\\ y = \lambda y_i + ( 1 - \lambda ) (y_j), x=λxi+(1−λ)(xj),y=λyi+(1−λ)(yj),
among ,x and y They are mixed xi( The label is yᵢ) and xⱼ( The label is yⱼ) Images and labels after , and λ Is a random number obtained from a given beta distribution .
thus ,Mixup It can provide us with continuous data samples between different data categories , Therefore, the distribution of a given training set is directly expanded , Thus, the network is more powerful in the test stage .
Mixup Versatility
Mixup In fact, it's just a data enhancement method , It is orthogonal to any network architecture used for classification . in other words , We can use... For the corresponding data set in any network for classification tasks Mixup Method .
Mixup Based on their original published papers 《Mixup: Beyond Empirical Risk Minimization》 Experiments on multiple data sets and architectures are carried out , Found out Mixup It can also reflect its powerful ability in applications other than neural networks .
Computing environment
library
We will pass PyTorch( Include torchvision) To build the whole program .Mixup Required from beta Samples generated in the distribution , We can NumPy Library . We will also use random for Mixup Look for random images . The following code can import all the libraries we need :
""" Import necessary libraries to train a network using mixup The code is mainly developed using the PyTorch library """
import numpy as np
import pickle
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
Data sets
To demonstrate , We will use the traditional image classification task to illustrate Mixup A powerful , So in this case CIFAR-10 It will be a very ideal data set .CIFAR-10 contain 10 Category 60000 A color image ( Every kind 6000 Zhang ), Press 5:1 The proportion is divided into training and test sets . These images are quite simple to classify , But more than the most basic digital recognition data set MNIST It's harder .
There are many ways to download CIFAR-10 Data sets , For example, the University of Toronto website contains relevant data sets . ad locum , I recommend you to use Titanium Of Open dataset platform , Because on this platform , If you use their SDK, You can get free dataset resources without downloading .
in fact , This public dataset platform contains hundreds of well-known high-quality datasets in the industry , Each data set has an associated author's description , And labels for different training tasks , For example, classification or target detection . Of course , You can also download other classified data sets on this platform , Such as CompCars or SVHN, To test Mixup Performance in different scenarios .

Hardware requirements
Generally speaking , We'd better use GPU( The graphics card ) To train neural networks , Because it can significantly improve the training speed . But if only CPU You can use , We can still simply test the program . If you want the program to be able to determine the required hardware , Just use the following code :
""" Determine if any GPUs are available """
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Realization
The Internet
here , Our goal is to test Mixup Performance of , Instead of debugging the network itself , So we just need to simply implement one 4 Layer convolution and 2 Convolutional neural network of layer and whole connection layer (CNN) that will do . To compare use and non use Mixup The difference between , We will use the same network to ensure the accuracy of the comparison .
We can use the following code to build the simple network mentioned above :
""" Create a simple CNN """
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# Network consists of 4 convolutional layers followed by 2 fully-connected layers
self.conv11 = nn.Conv2d(3, 64, 3)
self.conv12 = nn.Conv2d(64, 64, 3)
self.conv21 = nn.Conv2d(64, 128, 3)
self.conv22 = nn.Conv2d(128, 128, 3)
self.fc1 = nn.Linear(128 * 5 * 5, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.conv11(x))
x = F.relu(self.conv12(x))
x = F.max_pool2d(x, (2,2))
x = F.relu(self.conv21(x))
x = F.relu(self.conv22(x))
x = F.max_pool2d(x, (2,2))
# Size is calculated based on kernel size 3 and padding 0
x = x.view(-1, 128 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return nn.Sigmoid()(x)
Mixup
Mixup The stage is completed during the data set loading process , So we have to write our own data set , Instead of using torchvision.datasets The default data set provided .
The following code simply implements Mixup, And used in combination with NumPy Beta function of .
""" Dataset and Dataloader creation All data are downloaded found via Graviti Open Dataset which links to CIFAR-10 official page The dataset implementation is where mixup take place """
class CIFAR_Dataset(Dataset):
def __init__(self, data_dir, train, transform):
self.data_dir = data_dir
self.train = train
self.transform = transform
self.data = []
self.targets = []
# Loading all the data depending on whether the dataset is training or testing
if self.train:
for i in range(5):
with open(data_dir + 'data_batch_' + str(i+1), 'rb') as f:
entry = pickle.load(f, encoding='latin1')
self.data.append(entry['data'])
self.targets.extend(entry['labels'])
else:
with open(data_dir + 'test_batch', 'rb') as f:
entry = pickle.load(f, encoding='latin1')
self.data.append(entry['data'])
self.targets.extend(entry['labels'])
# Reshape it and turn it into the HWC format which PyTorch takes in the images
# Original CIFAR format can be seen via its official page
self.data = np.vstack(self.data).reshape(-1, 3, 32, 32)
self.data = self.data.transpose((0, 2, 3, 1))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
# Create a one hot label
label = torch.zeros(10)
label[self.targets[idx]] = 1.
# Transform the image by converting to tensor and normalizing it
if self.transform:
image = transform(self.data[idx])
# If data is for training, perform mixup, only perform mixup roughly on 1 for every 5 images
if self.train and idx > 0 and idx%5 == 0:
# Choose another image/label randomly
mixup_idx = random.randint(0, len(self.data)-1)
mixup_label = torch.zeros(10)
label[self.targets[mixup_idx]] = 1.
if self.transform:
mixup_image = transform(self.data[mixup_idx])
# Select a random number from the given beta distribution
# Mixup the images accordingly
alpha = 0.2
lam = np.random.beta(alpha, alpha)
image = lam * image + (1 - lam) * mixup_image
label = lam * label + (1 - lam) * mixup_label
return image, label
It should be noted that , We didn't do all the images Mixup, But about every 5 Zhang processing 1 Zhang . We also used a 0.2 Beta distribution of . You can change the distribution and the number of mixed images for different experiments , Maybe you'll get better results !
Training and evaluation
The following code shows the training process . We set the batch size to 128, The learning rate is 1e-3, The total number of times is 30 Time . The whole training was carried out twice , The only difference is whether you use Mixup. It should be noted that , The loss function needs to be defined by ourselves , Because at present BCE Loss labels with decimals are not allowed .
""" Initialize the network, loss Adam optimizer Torch BCE Loss does not support mixup labels (not 1 or 0), so we implement our own """
net = CNN().to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=LEARNING_RATE)
def bceloss(x, y):
eps = 1e-6
return -torch.mean(y * torch.log(x + eps) + (1 - y) * torch.log(1 - x + eps))
best_Acc = 0
""" Training Procedure """
for epoch in range(NUM_EPOCHS):
net.train()
# We train and visualize the loss every 100 iterations
for idx, (imgs, labels) in enumerate(train_dataloader):
imgs = imgs.to(device)
labels = labels.to(device)
preds = net(imgs)
loss = bceloss(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx%100 == 0:
print("Epoch {} Iteration {}, Current Loss: {}".format(epoch, idx, loss))
# We evaluate the network after every epoch based on test set accuracy
net.eval()
with torch.no_grad():
total = 0
numCorrect = 0
for (imgs, labels) in test_dataloader:
imgs = imgs.to(device)
labels = labels.to(device)
preds = net(imgs)
numCorrect += (torch.argmax(preds, dim=1) == torch.argmax(labels, dim=1)).float().sum()
total += len(imgs)
acc = numCorrect/total
print("Current image classification accuracy at epoch {}: {}".format(epoch, acc))
if acc > best_Acc:
best_Acc = acc
To evaluate Mixup The effect of , We conducted three controlled trials to calculate the final accuracy . In the absence of Mixup Under the circumstances , The accuracy of the network on the test set is about 74.5%, And in the Used Mixup Under the circumstances , The accuracy has been improved to about 76.5%!
Beyond image classification
Mixup The accuracy of image classification has been brought to an unprecedented height , But research shows that ,Mixup The benefits of can also be extended to other computer vision tasks , For example, the generation and defense of adversarial data . In addition, there are relevant literature in Mixup Expand to three-dimensional representation , The current results show that Mixup It is also very effective in this field , for example PointMixup.
Conclusion
thus , We use it Mixup The little experiment you did was done ! In this article , We've done a little bit of that Mixup And demonstrates how to apply it in image classification network training Mixup. A complete implementation can be found here —GitHub Warehouse Find .
【 About lattice titanium 】:
Gewu titanium Intelligent Technology Positioned as a data platform for machine learning , Committed to AI Developers build the next generation of new infrastructure , Fundamentally change the way it interacts with unstructured data . We use unstructured data management tools TensorBay And the open source dataset community Open Datasets, Help machine learning teams and individuals reduce data acquisition 、 Storage and processing costs , Speed up AI Development and product innovation , Empowering artificial intelligence with thousands of lines and industries 、 Provide a solid foundation for driving industrial upgrading .
边栏推荐
- php入门基础记录
- OAuth 2.0 one click login
- Do you know why the PCB produces tin beads? 2021-09-30
- 基于地面点稀少的LiDAR点云的茂密森林蓄积量估算
- Find out what informatization is, and let enterprises embark on the right path of transformation and upgrading
- 1742. 盒子中小球的最大数量
- WinForm实现窗口始终在顶层
- smartBugs安装小问题总结
- Function template_ Class template
- Estimation of dense forest volume based on LIDAR point cloud with few ground points
猜你喜欢

【深度学习 轻量型backbone】2022 EdgeViTs CVPR

Ca-is1200u current detection isolation amplifier has been delivered in batch

Chuantu microelectronics breaks through the high-end isolator analog chip market with ca-is3062w

What if there is no point in data visualization?
Application of point cloud intelligent drawing in intelligent construction site

微信小程序开通客服消息功能开发

Terms and concepts related to authority and authentication system

CPDA|数据分析师成长之路如何起步?
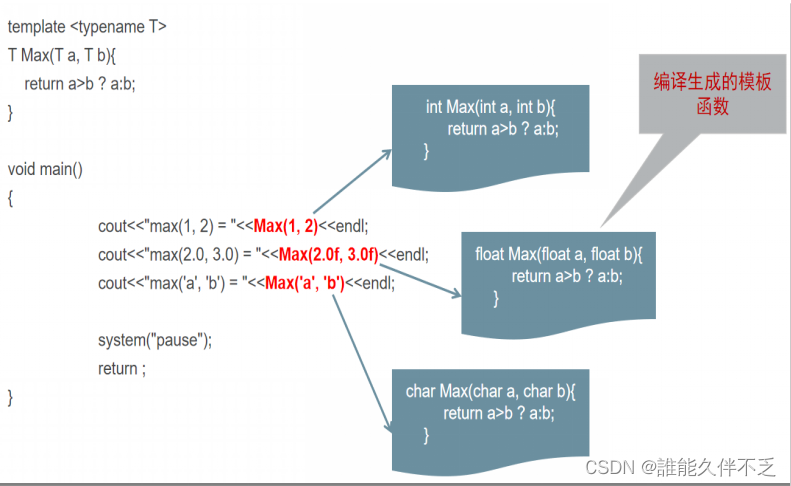
函数模板_类模板
VectorDraw Web Library 10.10
随机推荐
smartBugs安装小问题总结
【日常训练】207. 课程表
How to use printf of 51 single chip microcomputer
Tupu software digital twin 3D wind farm, offshore wind power of smart wind power
Keil and Proteus joint commissioning
Four software 2021-10-14 suitable for beginners to draw PCB
海思3559 sample解析:vio
点云智绘在智慧工地中的应用
NPM install reports an error: gyp err! configure error
Access to foreign lead domain name mailbox
Chuantu microelectronics 𞓜 subminiature package isolated half duplex 485 transceiver
npm install 报错 : gyp ERR! configure error
Application of point cloud intelligent drawing in intelligent construction site
What if there is no point in data visualization?
JDBC-DAO层实现
國外LEAD域名郵箱獲取途徑
(tool class) quickly add time to code in source insight
(tool class) use SecureCRT as the communication medium
VectorDraw Developer Framework 10.10
AttributeError: ‘Upsample‘ object has no attribute ‘recompute_ scale_ factor‘