当前位置:网站首页>Do you really understand the persistence mechanism of redis?
Do you really understand the persistence mechanism of redis?
2022-06-30 18:36:00 【Wind billows】
I am participating in the recruitment of nuggets technology community creator signing program , Click the link to sign up for submission .
2022 year 6 Some day of the month , The atmosphere in the office area is extremely depressing , At this time, Xiaobian stands behind his colleague panghu with his eyes slightly narrowed while blowing the air conditioner , I watched him sweat and import the data from the database into Redis.
After some inquiry from Xiaobian, I found out , It turns out they made it Redis Today I hung up for no reason , And because it's a new project , I will give a demonstration to the leaders later , Production environment Redis Only one node is deployed , It doesn't matter , What about the cached data ...
It happened to be this time , Xiaobian heard a loud cry from the boss' office ,“ Fat tiger , Come and show me the project ”, Five minutes later , The red faced fat tiger came out of the boss' office .
At this time, Xiaobian suddenly thought ,Redis Isn't there a persistence mechanism ? During the conversation with panghu, I found , He didn't even know Redis Persistence mechanism of , Xiaobian quietly installed a 13.
Redis Persistence
Redis There are two persistence mechanisms , One is a snapshot (RDB), The other is AOF journal .RDB It's a full backup ,AOF Log is a continuous incremental backup . Snapshot is a binary serialization of memory data , Very compact on storage , and AOF What the log records is the instruction record text of memory data modification .
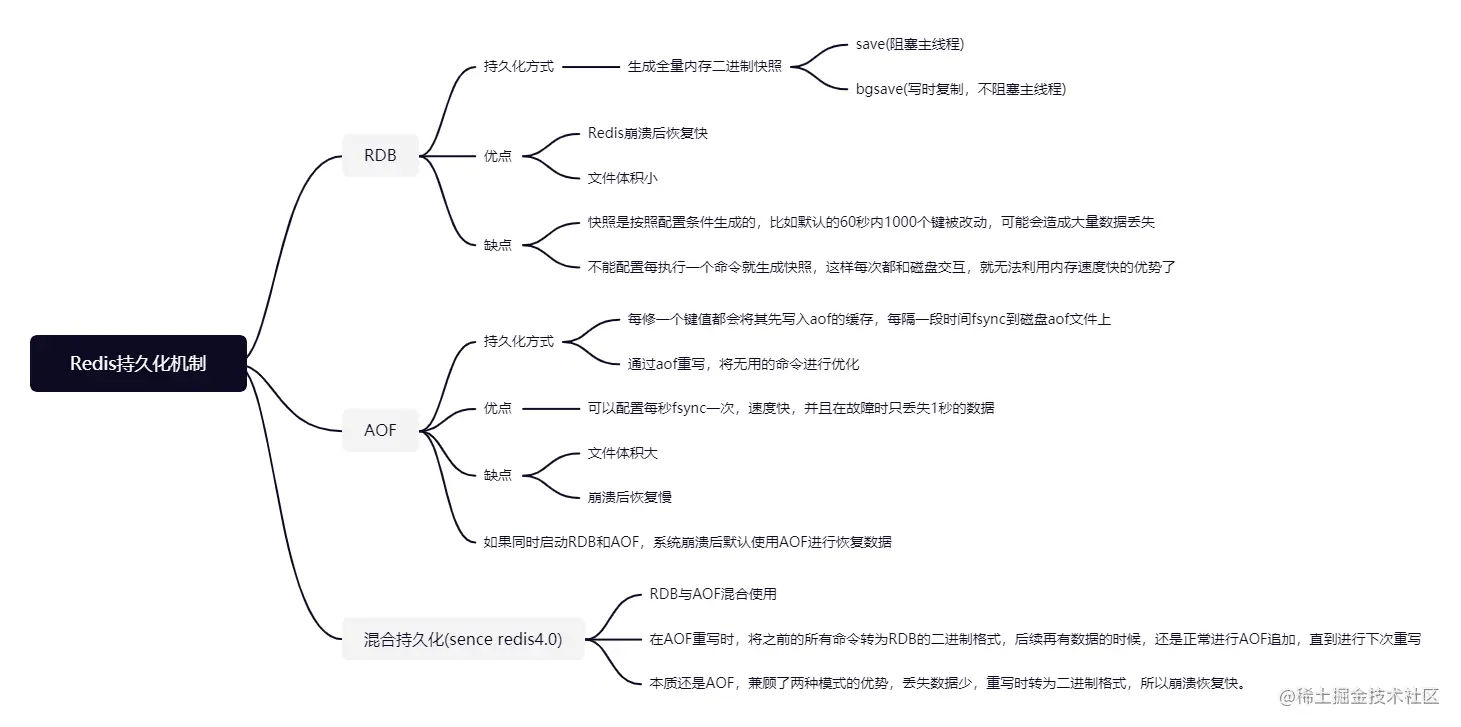
RDB snapshot
RDB Snapshot persistence is Redis On by default , It will save the memory data in a file named... According to the configuration policy dmp.rdb In the binary file of .
stay redis.conf In profile , You can configure the RDB Persistence strategy of , By default, the system has three save policies ( The three shall take effect at the same time ), as follows :
- save 900 1 900 In seconds 1 The keys change
- save 300 10 30 In seconds 10 The keys change
- save 60 10000 60 In seconds 10000 The keys change
We can also configure it according to the specific conditions of our own production environment . If we want to close RDB snapshot , Directly add the above three in the configuration file save Just comment it out .
Copy on write mechanism (COW)
Redis Provides save Command to generate snapshots , however save Command to block the main process ( The thread that executes the client command ), When the memory needed to generate snapshots is very large ( Hundreds G), It will take a long time , Even more than ten seconds , So if the main process is blocked at this time , It will make the whole service unavailable , It's not worth it .
In this case ,Redis With the help of write time replication technology provided by the operating system , Provides bgsave command ,basave Commands can be based on the main process ,fork A subprocess , Child processes share the code and data segments of the main process , This is equivalent to generating a snapshot in the background .
stay bgsave Subprocess write RDB Data time , If the main process also reads these data , that , The main process and bgsave Subprocesses don't interact with each other . however , If the main process wants to modify a piece of data , This data will be copied , Make a copy of the data . then ,bgsave The child process will write the replica data to RDB, And in the process , The main process can still modify the original data directly .
demonstration


advantage
- Redis Fast data recovery after downtime
- Binary files are small
shortcoming
- Persistence policies may result in a large amount of data loss during downtime
AOF(append-only file)

AOF Persistence can be achieved through redis.conf In the document appendonly Parameter control is on .
- appendonly no By default no, take no Change it to yes Can be opened AOF Persistence mode ,Redis Each instruction modified will be recorded in the system cache first , By default, the cache is flushed to every second appendonly.aof In the disk file When Redis On reboot , The program can be re executed by AOF The command in the file to rebuild the dataset .
demonstration
The minor editor directly modifies redis.conf In the document appendonly Parameters , And then restart redis,set A few key value pairs , Waiting for several seconds , It is found that the current directory does not generate appendonly.aof file .
Later, by directly in redis-cli perform config set appendonly yes command , Only under the current directory will appendonly.aof file .

Next we turn on appendonly.aof The file can see the key value pairs we wrote before .
*2
$6
SELECT
$1
0
*3
$3
SET
$1
1
$1
2
*3
$3
SET
$4
key1
$4
val1
*3
$3
SET
$4
3124
$3
124
*3
$3
SET
$5
key14
$4
key2
This is a kind of resp Protocol format data , The number after the asterisk represents how many parameters the command has ,$ The number after the number represents this parameter. There are several characters .
AOF Persistence strategy
- appendfsync always: Every time a new order is added to AOF Execute the document once fsync , Very slow , It's also very safe , Not recommended for use , In itself Redis With the advantage of fast memory , If you access the disk every time you operate, the advantage will be lost .
- appendfsync everysec: Per second fsync once , Fast enough , And it will only be lost in case of failure 1 Seconds of data ,AOF This configuration will be used by default .
- appendfsync no: never fsync , Give the data to the operating system to process . faster , It's also a safer option , In case of downtime , The most data is lost .
AOF rewrite
Suppose we execute two commands set key1 1 And set key1 2, In the open AOF In the case of persistence , Both commands will be logged to AOF In file , But when we restart and recover data after downtime, do we just need to execute set key1 2 That's all right. , Previous set key1 1 It doesn't matter if you ignore it when restoring data , And because AOF Files over time , It's going to get bigger and bigger , rewrite AOF It's very important .
Manually trigger background rewrite ,redis The client executes the command :bgrewriteaof
Redis Two configuration parameter controls are provided AOF Auto rewrite frequency (redis.conf).
- auto‐aof‐rewrite‐min‐size 64mb //aof Documents must at least reach 64M Will automatically rewrite , The file is too small to recover Soon
- auto‐aof‐rewrite‐percentage 100 //aof The file size has increased since it was last rewritten 100% Then trigger rewrite again
When an override is triggered Redis Will pass fork The main process , Generate a child process to do , The reason for this is that rewriting generally means a lot of I/O operation , It's very time consuming , Rewriting with the main process will cause the main process to block for a long time , influence Redis Execute client command , Even cause the service to be unavailable for a long time , But the child process to rewrite means that the main process can still receive 、 Processing client instructions , Will result in rewritten AOF The current database state of the file and the server is inconsistent .
for example : Subprocesses fork When the main process , There's only... In memory key1 This key , But when you start rewriting , There are many clients set 了 key2、key3, This leads to rewritten AOF The file and database are inconsistent .
therefore Redis stay AOF When rewriting, a AOF Rewrite buffer , When a new command is executed ,Redis Will send the command to AOF Buffers and AOF Rewrite buffer .

After performing the rewrite task , The child process sends a signal to the main process , After receiving the signal, the main process will perform the following two operations ( The following two operations block the main process ):
- take AOF Rewrite everything in the buffer to write to the new AOF In file , Promise new AOF The state of the database saved by the file is consistent with the current state of the server .
- For the new AOF Change the name of the document , Atomic coverage AOF file , Complete replacement of old and new documents
Although only the above two operations will block Redis The main process , But obviously it has minimized the performance impact of rewriting . But if you want to optimize it again , Here are two solutions .
- The service is rewritten at low peak time
- Use ssd, Improve persistence efficiency
Be careful :AOF When rewriting , To avoid client-side buffer overflow caused by command execution , The rewriter is working on the list 、 Hashtable 、 aggregate 、 The four types of ordered sets may have multiple element keys , The number of elements contained in the key will be checked first , If the number of elements exceeds redis.h/REDIS_AOF_REWRITe_ITeMS_PER_CMD Value of constant ( Default 64 Elements ), Then the rewriter will use multiple commands to record the value of the key , Instead of just using one command .
advantage
- Data integrity is higher than RDB, By default , At most 1 Seconds of data .
shortcoming
- Redis Slow data recovery after downtime
- Large file size
Mix persistence (sence redis4.0)
Redis In case of downtime and recovery , To improve the integrity of data , We usually use AOF Log recovery , But use AOF Log performance is relative RDB It's a lot slower , In this way Redis When the examples are large , It takes a long time to start . Redis4.0 To solve this problem , Launched Mix persistence , To put it bluntly , Hybrid persistence is a combination of RDB And AOF The advantages of the two persistence methods .
After the mixed mode is turned on ,AOF When rewritten AOF The data in the file is displayed in RDB The binary format of the file is written to the current AOF In file , Subsequent new writes continue with AOF File format . When redis When the machine is down and restarted , load AOF File to recover data : Load first RDB And then load the rest AOF Content , So the restart efficiency has been greatly improved .
By modifying the redis.conf The following configuration in the file enables mixed persistence ( Must be on first AOF Persistence ):
- aof‐use‐rdb‐preamble yes
summary
- RDB The file will be saved Redis All key value pairs in the
- save Generate RDB The file will block the main process
- bgsave Command background generation RDB, Does not block the main process
- RDB Small file size , Save binary data
- RDB Execute by configuring policies , Some data may be lost
- RDB The file in Redis Fast recovery after downtime
- AOF The file saves the commands executed by the client
- AOF Large file size , Slow recovery , However, the data ratio is lower by default RDB A lot
- Redis After the machine is restarted, the default is to use AOF To recover in the same way
- AOF The commands in the file are in the form of Resp Protocol format saved
- The command will be saved to the buffer first , And then periodically synchronize to AOF file
- AOF The configuration policy will be automatically configured AOF File rewriting , To reduce the file size
- AOF When rewriting fork A child process to execute , There will also be a rewrite buffer , The key used to save the modification of the main process when rewriting
- AOF When rewriting , Finally, a new one will be generated AOF file , Overwrite the original file
- Write the contents of the rewrite buffer to AOF And replace the old with the new AOF File will block the main process
- Blending persistence is RDB And AOF A combination of advantages
- The essence of mixed persistence is still used AOF file
- The premise of mixed persistence is to enable AOF Persistence
- Mixed persistence is rewriting AOF The data will be written directly as RDB Binary format , After that, the new order is still AOF file Resp Save in protocol format
attach
fsync
In order to improve the efficiency of writing files ,linux The system is performing persistence , Would call write function , First save the data to be written to the file in a memory buffer and it will be returned directly , Wait until the buffer is filled , Or the specified time limit has been exceeded ( It's usually 30 second ) after , Will write the data in the buffer to the disk .
This approach improves the writing efficiency , But if it goes down , This may result in the loss of data that has not been written to the disk in the buffer .
So ,linux Provides fsync function , It forces and blocks waiting for the system to write data to disk , So as to ensure the security of data
Subprocesses
Why? Redis Meeting fork A child process without a child thread , Because the child process can carry the data copy of the main process , It can avoid using the lock , Ensure data security .
notes : The child process is rewriting , The main process will still receive and process client commands , This will result in data inconsistency between the child process and the main process .
Reference material
Redis Design and implementation
Search on wechat : The wind billows under the clouds
First article 、 Read the serial articles
边栏推荐
猜你喜欢
Helping the ultimate experience, best practice of volcano engine edge computing

Post penetration file system + uploading and downloading files

What if the apple watch fails to power on? Apple watch can not boot solution!

Design of online shopping mall based on SSH

Sword finger offer 17 Print from 1 to maximum n digits

Research on the principle of Tencent persistence framework mmkv

Only black-and-white box test is required for test opening post? No, but also learn performance test

剑指 Offer 16. 数值的整数次方
剑指 Offer 17. 打印从1到最大的n位数

MySQL advanced - Architecture
随机推荐
MySQL advanced - index optimization (super detailed)
Dropout: immediate deactivation
Deep understanding of JVM (III) - memory structure (III)
煤炭行业数智化供应商管理系统解决方案:数据驱动,供应商智慧平台助力企业降本增效
Helping the ultimate experience, best practice of volcano engine edge computing
Multipass中文文档-设置图形界面
又一篇CVPR 2022论文被指抄袭,平安保险研究者控诉IBM苏黎世团队
电子元器件招标采购商城:优化传统采购业务,提速企业数字化升级
Force deduction solution summary 1175- prime number arrangement
The secondary menu of the magic article system v5.4.0 supports the optimization of form display
漏洞复现----38、ThinkPHP5 5.0.23 远程代码执行漏洞
Daily interview 1 question - how to prevent CDN protection from being bypassed
「经验」我对用户增长的理解『新用户篇』
Redis (V) - advanced data types
The new Post-00 Software Test Engineer in 2022 is a champion
Sign up for Huawei cloud proposition in the "Internet +" competition, and you can take many gifts!
助力极致体验,火山引擎边缘计算最佳实践
Deep understanding of JVM (II) - memory structure (II)
Post office - post office issues (dynamic planning)
国内离线安装 Chrome 扩展程序的方法总结