当前位置:网站首页>Decision tree principle and case application - Titanic survival prediction
Decision tree principle and case application - Titanic survival prediction
2022-07-27 10:11:00 【Big data Da Wenxi】
Decision tree
Learning goals
- The goal is
- Explain the formula and function of information entropy
- Explain the formula function of information gain
- Information gain is applied to reduce the uncertainty of computational features
- Understand the implementation of three algorithms of decision tree
- application
- Titanic passenger survival prediction
1、 Recognize the decision tree
The origin of decision tree thinking is very simple , The conditional branch structure in programming is if-then structure , The earliest decision tree is a kind of classification learning method using this kind of structure to segment data
How to understand this sentence ? An example of a conversation

Think about why this girl put her age at the top to judge !!!!!!!!!
2、 Detailed explanation of decision tree classification principle
In order to better understand how the decision tree is classified , Let's take an example of a problem ?

problem : How to classify and forecast these customers ? How do you divide ?
It's possible that your division is like this

So how do we know which of these features is better on top , So the division of decision tree is like this

2.1 principle
- Information entropy 、 Information gain, etc
Need to use the knowledge of information theory !!! problem : Information entropy is introduced through an example
2.2 Information entropy
Let's play a guessing game , Guess what 32 That team is the champion . And guess wrong and pay the price . Give a dollar for every wrong guess , Tell me if I guessed right , Then how much do I have to pay to know who is the champion ? ( Premise is : Don't know any team information 、 Historical game records 、 Strength etc. )

To minimize the cost , You can use dichotomy to guess :
I can number the ball , from 1 To 32, Then ask : crown The army is 1-16 No.? ? Ask... In turn , Only five times , We can know the result .
Shannon pointed out that , Its exact amount of information should be ,p The probability of winning for each team ( Suppose the probabilities are equal , All for 1/32), We don't need money to measure the price , Xiangnong pointed out using bit :
H = -(p1logp1 + p2logp2 + ... + p32log32) = - log32
2.2.1 The definition of information entropy
- H We call it information entropy , The unit is bit .
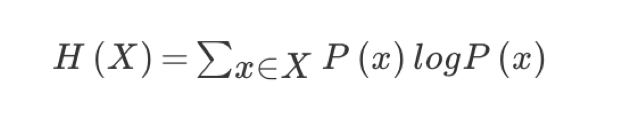
“ Who is the world cup champion ” The amount of information should be more than 5 Less bits , characteristic ( important ):
When this 32 When teams have the same chance to win , The corresponding entropy of information is equal to 5 The bit
As long as the probability changes arbitrarily , Information entropy is better than 5 Big bit
2.2.2 summary ( important )
- Information is linked to the elimination of uncertainty
When we get extra information ( Team history, game situation and so on ) The more words , So the less we guess ( The uncertainty of speculation is reduced )
problem : Back to our previous loan case , How to divide ? You can use when you know a feature ( For example, whether there is a house ) after , The amount of uncertainty we can reduce . The bigger we get, the more important we can think of this feature . How to measure the reduced uncertainty ?
2.3 One of the bases of decision tree Division ------ Information gain
2.3.1 Definitions and formulas
features A On the training data set D Information gain of g(D,A), Defined as a set D The entropy of information H(D) With the characteristics of A Given the conditions D Entropy of information condition H(D|A) The difference between the , That is, the formula is :

A detailed explanation of the formula :

notes : The information gain represents the known characteristic X The degree to which the uncertainty of information is reduced makes the class Y The extent to which information entropy is reduced
#### 2.3.2 Loan characteristics are important calculations
- We calculate by age characteristics :
```python
1、g(D, Age ) = H(D) -H(D| Age ) = 0.971-[5/15H( youth )+5/15H( middle-aged )+5/15H( The elderly ]
2、H(D) = -(6/15log(6/15)+9/15log(9/15))=0.971
3、H( youth ) = -(3/5log(3/5) +2/5log(2/5))
H( middle-aged )=-(3/5log(3/5) +2/5log(2/5))
H( The elderly )=-(4/5og(4/5)+1/5log(1/5))
```
We use A1、A2、A3、A4 For age 、 There's work 、 Have your own house and loan situation . The result of the final calculation g(D, A1) = 0.313, g(D, A2) = 0.324, g(D, A3) = 0.420,g(D, A4) = 0.363. So we choose A3 As the first feature of the division . So we can build a tree slowly
2.4 Three algorithms of decision tree
Of course, the principle of decision tree is not just information gain , There are other ways . But the principles are similar , Let's not calculate by example .
- ID3
- Information gain The biggest rule
- C4.5
- Information gain ratio The biggest rule
- CART
- Classification tree : The gini coefficient The minimum rule stay sklearn You can choose the default principle of partition
- advantage : More detailed division ( Understand from the tree display of the following example )
2.5 Decision tree API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- Decision tree classifier
- criterion: The default is ’gini’ coefficient , You can also choose the entropy of the information gain ’entropy’
- max_depth: The depth of the tree
- random_state: Random number seed
There will be some super parameters :max_depth: The depth of the tree
We'll talk about other super parameters in combination with random forest
3、 Case study : Titanic passenger survival prediction
- Titanic data
On the Titanic and titanic2 Data frames describe the survival of individual passengers on the Titanic . The data set used here was started by various researchers . Among them are the passenger lists created by many researchers , from Michael A. Findlay edit . The feature of the dataset we extract is the category of tickets , Survive , Ride , Age , land ,home.dest, room , ticket , Ship and sex .
1、 The passenger class is the passenger class (1,2,3), It's a representative of the socioeconomic class .
2、 among age Data is missing .

3.1 analysis
Choose a few features that we think are important [‘pclass’, ‘age’, ‘sex’]
Fill in missing values
Category symbol in feature , Need to carry out one-hot Encoding processing (DictVectorizer)
- x.to_dict(orient=“records”) You need to convert array features to dictionary data
Data set partitioning
Decision tree classification prediction
3.2 Code
def decisioncls(): """ Decision tree for passenger survival prediction :return: """ # 1、 get data titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt") # 2、 Data processing x = titan[['pclass', 'age', 'sex']] y = titan['survived'] # print(x , y) # Missing values need to be dealt with , Dictionary feature extraction is carried out for these features with categories among them x['age'].fillna(x['age'].mean(), inplace=True) # about x Convert to dictionary data x.to_dict(orient="records") # [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}] dict = DictVectorizer(sparse=False) x = dict.fit_transform(x.to_dict(orient="records")) print(dict.get_feature_names()) print(x) # Split training set test set x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3) # Make decision tree establishment and prediction dc = DecisionTreeClassifier(max_depth=5) dc.fit(x_train, y_train) print(" The prediction accuracy is :", dc.score(x_test, y_test)) return NoneBecause the decision tree is similar to the structure of a tree , We can save it to local display
3.3 Save the tree structure to dot file
- 1、sklearn.tree.export_graphviz() This function can be exported DOT Format
- tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
- 2、 Tools :( To be able to dot The file is converted to pdf、png)
- install graphviz
- ubuntu:sudo apt-get install graphviz Mac:brew install graphviz
- 3、 Run the command
- Then we run this command
- dot -Tpng tree.dot -o tree.png
export_graphviz(dc, out_file="./tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', ' women ', ' men '])4、 Decision tree summary
- advantage :
- A simple understanding and explanation , Tree Visualization .
- shortcoming :
- Decision tree learners can create trees that are too complex to generalize data well , This is called over fitting .
- improvement :
- Pruning cart Algorithm ( Decision tree API It has been realized , Random forest parameter tuning is introduced )
- Random forests
notes : Important business decisions , Because the decision tree has good analytical ability , It is widely used in decision-making process , You can choose features
- 1、sklearn.tree.export_graphviz() This function can be exported DOT Format
‘ men ’])
## 4、 Decision tree summary
- advantage :
- A simple understanding and explanation , Tree Visualization .
- shortcoming :
- ** Decision tree learners can create trees that are too complex to generalize data well , This is called over fitting .**
- improvement :
- Pruning cart Algorithm ( Decision tree API It has been realized , Random forest parameter tuning is introduced )
- ** Random forests **
** notes : Important business decisions , Because the decision tree has good analytical ability , It is widely used in decision-making process , You can choose features **
边栏推荐
- Overview of PCL modules (1.6)
- [cloud native • Devops] master the container management tool rancher
- NFT system development - Tutorial
- S交换机堆叠方案配置指南
- NPM common commands
- Interview JD T5, was pressed on the ground friction, who knows what I experienced?
- Final examination paper of engineering materials
- 数学推理题:张王李赵陈五对夫妇聚会,见面握手
- TFlite 的简单使用
- Shell中的文本处理工具、cut [选项参数] filename 说明:默认分隔符是制表符、awk [选项参数] ‘/pattern1/{action1}filename 、awk 的内置变量
猜你喜欢
![Flash memory usage and stm32subemx installation tutorial [day 3]](/img/ff/43ef2d0e1bdfd24fbc5c99e76455f1.png)
Flash memory usage and stm32subemx installation tutorial [day 3]
![[SCM]源码管理 - perforce 分支的锁定](/img/c6/daead474a64a9a3c86dd140c097be0.jpg)
[SCM]源码管理 - perforce 分支的锁定

Anchor free detector: centernet

3D restoration paper: shape painting using 3D generative advantageous networks and recurrent revolutionary networks
![Shell运算符、$((运算式))” 或 “$[运算式]、expr方法、条件判断、test condition、[ condition ]、两个整数之间比较、按照文件权限进行判断、按照文件类型进行判断](/img/65/a735ca2c2902e3fc773dda79438972.png)
Shell运算符、$((运算式))” 或 “$[运算式]、expr方法、条件判断、test condition、[ condition ]、两个整数之间比较、按照文件权限进行判断、按照文件类型进行判断

hdu5288(OO’s Sequence)
备战金九银十Android面试准备(含面试全流程,面试准备工作面试题和资料等)

Talk about 10 scenarios of index failure. It's too stupid

Dcgan paper improvements + simplified code

WGAN、WGAN-GP、BigGAN
随机推荐
Brush the title "sword finger offer" day03
面试京东 T5,被按在地上摩擦,鬼知道我经历了什么?
Leetcode.565. array nesting____ Violent dfs- > pruning dfs- > in situ modification
线代004
活体检测综述
Intermediate and advanced test questions ": what is the implementation principle of mvcc?
Why do microservices have to have API gateways?
QT learning (II) -- a brief introduction to QT Creator
Talk about 10 scenarios of index failure. It's too stupid
Robotframework+eclispe environment installation
找工作 4 个月, 面试 15 家,拿到 3 个 offer
[SCM]源码管理 - perforce 分支的锁定
Shell综合应用案例,归档文件、发送消息
Understand chisel language. 24. Chisel sequential circuit (IV) -- detailed explanation of chisel memory
Case of burr (bulge) notch (depression) detection of circular workpiece
Shell流程控制(重点)、if 判断、case 语句、let用法、for 循环中有for (( 初始值;循环控制条件;变量变化 ))和for 变量 in 值 1 值 2 值 3… 、while 循环
About getter/setter methods
Example of ICP registration for PCL
吃透Chisel语言.22.Chisel时序电路(二)——Chisel计数器(Counter)详解:计数器、定时器和脉宽调制
There is no CUDA option in vs2019+cuda11.1 new project