当前位置:网站首页>How to build a quasi-real-time data warehouse?
How to build a quasi-real-time data warehouse?
2022-08-02 20:43:00 【software testnet】

其中,The real-time data warehouse is subdivided into two categories:One kind is standard on the number of real-time warehouse,所有ETLprocess throughSpark或Flink等实时计算、落地;Another kind is to simplify the number of positions in real time,Even simple upgrade of offline data warehouse,This type of data warehouse is called quasi-real-time data warehouse.
接下来,This paper focuses on sorting out the application scenarios of quasi-real-time data warehouse!
简单理解,There will be delays in quasi-real-time data warehouses,Compared with offline data warehouse that only counts once a day,Quasi-real-time warehouse should be based on business needs,按照小时、minutes or seconds.这里,以5minutes are the limit,5Results every minute,可以基于Structured StreamingRealize the construction of quasi-real-time data warehouse,This is an offline operation based on streaming data,Divide batches according to time,The overall data is on the stream computing engine,也就是在Structured Streaming上面.
Real-time data warehouse projects by industry、分领域,Take news information as an example,比如今日头条、一点资讯、腾讯新闻、网易新闻、百度浏览器、360浏览器、新浪、搜狐等.What data sources are there for this type of application?一般包括用户信息、Privacy and the relevant business and user income data;There are also behavior logs left by users browsing articles;The content of the user work published log,This information will first be collectedKafka上.
之后的过程是,通过Spark Structured Streaming消费Kafka的原始数据.这里需要强调一点,采用Spark Structured Streaming有三个原因.第一,实现流批统一,Can handle batch calculations;second supportfile sink,实现端到端的一致性语义;第三,可以控制sink到HDFS的时间,比如:Set up batch data5minute node,延时低,处理速度快.
从sink到HDFS时,可以选择使用Hudi,也可以选择不使用Hudi,如果通过Spark Streaming直接写数据到HDFS时,Inevitably dealing with small file issues,There are four general treatment.第一,Increase the batch capacity,but also increases the delay;Second partition merge;Third external program integration;第四,If the file does not reach the specified size,Do not create files when writing data in the next batch,Instead, merge with existing small files.Each of these four methods has its own usage scenarios,无论采用哪种方式,Will work more.但是,如果通过Hudi写入数据,小文件的问题,Hudi会帮忙解决.
还有一个问题,Except the user behavior event log will not update,A lot of business data needs to be updated in real time,比如:用户信息的修改.但是,HDFSItself does not support updates,Lead to the need to modify the data through a complicated process,并且在整个过程中,The real-time nature of the data cannot be guaranteed,如果使用Hudi,with relatively short delays,比如分钟级别,Provide data update support,同时Hudi也支持ACID.
When the original data landed onHDFS上,You can do some data preprocessing during the landing process,比如之前在Flume InterceptorThe data processing work,之后我们可以通过HiveCreate the corresponding external table,These tables can be divided into a hierarchy,叫做ODS层的表,These tables are the most original data,It is also the first layer of the warehouse.
建立完ODS层的Hive表,You can query data according to business needs.至于,Are we going to build a higher data warehouse level?,According to the needs of the business.映射Hiveraw data layerODS后,data to analyze,分析使用的是Presto分析引擎,基于内存的计算框架,计算速度要比Hive和Spark快很多.
使用Presto查询操作完成OLAP分析处理,Will integrateSpring Boot框架,使用JDBC连接Presto,Provide external query interface,for analysts.
边栏推荐
猜你喜欢
嵌入式Qt-做一个秒表
小程序毕设作品之微信体育馆预约小程序毕业设计成品(7)中期检查报告
MySQL基本语法

How a "cloud" can bring about new changes in the industry
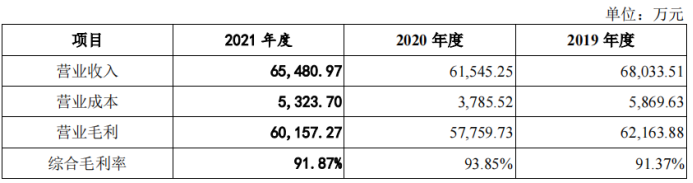
土巴兔IPO五次折戟,互联网家装未解“中介”之痛

mui中使用多级选择器实现省市区联动
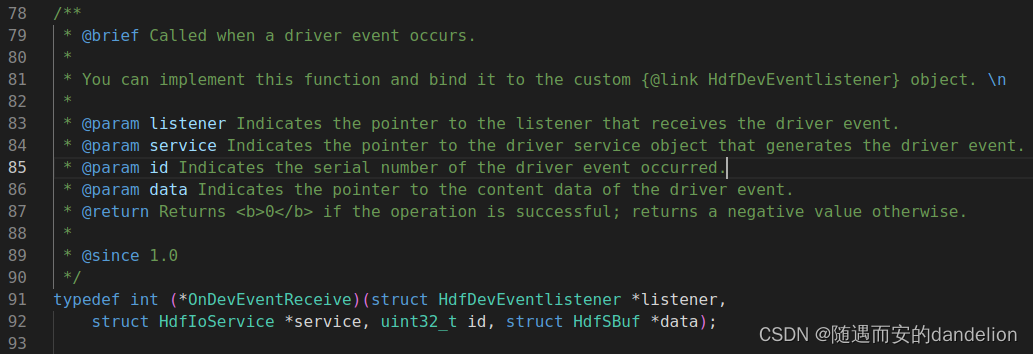
HDF驱动框架的API(1)

小程序毕设作品之微信体育馆预约小程序毕业设计成品(8)毕业设计论文模板
IDEA相关配置(特别完整)看完此篇就将所有的IDEA的相关配置都配置好了、设置鼠标滚轮修改字体大小、设置鼠标悬浮提示、设置主题、设置窗体及菜单的字体及字体大小、设置编辑区主题、通过插件更换主题
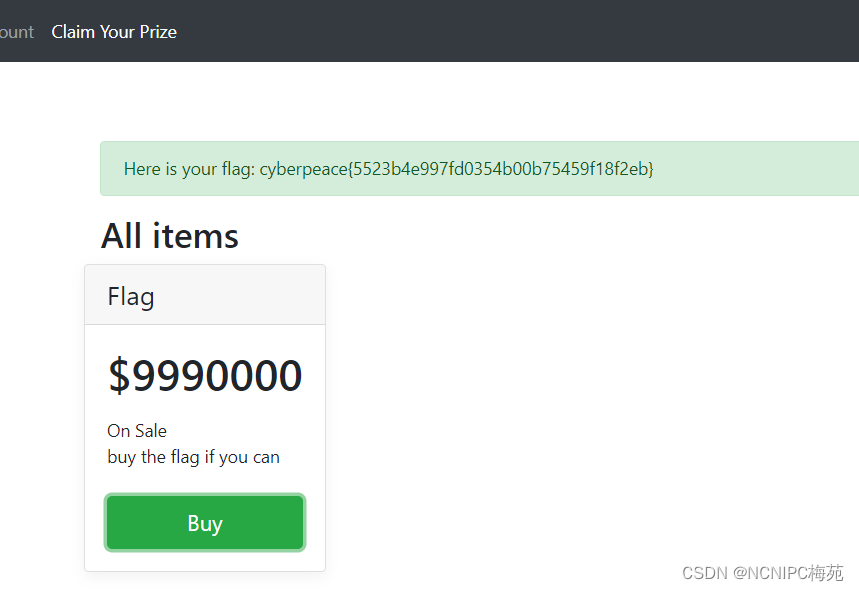
php弱类型-攻防世界lottery
随机推荐
一文看懂推荐系统:概要01:推荐系统的基本概念
mysql四种隔离级别
Google Earth Engine APP—— 一个不用写代码可以直接下载相应区域的1984-2021年的GIF遥感影像动态图
罗敏背后是抖音
小程序毕设作品之微信体育馆预约小程序毕业设计成品(7)中期检查报告
TSF微服务治理实战系列(一)——治理蓝图
阿波罗 planning代码-modules\planning\lattice\trajectory_generation\PiecewiseBrakingTrajectoryGenerator类详解
多聚体/壳聚糖修饰白蛋白纳米球/mPEG-HSA聚乙二醇人血清白蛋白纳米球的制备与研究
千万级别的表分页查询非常慢,怎么办?
NeRF: The Secret of 3D Reconstruction Technology in the Popular Scientific Research Circle
0725-面试记录
cpolar应用实例之多设备数据采集
My recursive never burst stack
基于HDF的LED驱动程序开发(1)
HDF驱动框架的API(1)
Since September, China has granted zero-tariff treatment to 98% of tax items from 16 countries including Togo
Go 语言快速入门指南: 介绍及安装
判断文件属主
golang刷leetcode动态规划(10)编辑距离
php弱类型-攻防世界lottery