当前位置:网站首页>CPU、GPU、NPU的区别
CPU、GPU、NPU的区别
2022-07-27 13:28:00 【山风wind】
CPU、GPU、NPU的区别
CPU
CPU(CentralProcessing Unit)中央处理器,是一块超大规模的集成电路,主要逻辑架构包括控制单元Control,运算单元ALU和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。简单说,就是计算单元、控制单元和存储单元。
CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计算方面受到限制,相对而言更擅长于处理逻辑控制。
CPU无法做到大量数据并行计算的能力,但GPU可以。
GPU
GPU(GraphicsProcessing Unit),即图形处理器,是一种由大量运算单元组成的大规模并行计算架构,早先由CPU中分出来专门用于处理图像并行计算数据,专为同时处理多重并行计算任务而设计。
GPU中也包含基本的计算单元、控制单元和存储单元,但GPU的架构与CPU有很大不同。
与CPU相比,CPU芯片空间的不到20%是ALU,而GPU芯片空间的80%以上是ALU。即GPU拥有更多的ALU用于数据并行处理。
GPU具有如下特点:
多线程,提供了多核并行计算的基础结构,且核心数非常多,可以支撑大量数据的并行计算,处理神经网络数据远远高效于CPU。
拥有更高的访存速度。
更高的浮点运算能力。
因此,GPU比CPU更适合深度学习中的大量训练数据、大量矩阵、卷积运算。
GPU虽然在并行计算能力上尽显优势,但并不能单独工作,需要CPU的协同处理,对于神经网络模型的构建和数据流的传递还是在CPU上进行。
但是GPU也有天生缺陷,那就是功耗高,体积大,价格贵。
性能越高的GPU体积越大,功耗越高,价格也昂贵,对于一些小型设备、移动设备来说将无法使用。
因此,一种体积小、功耗低、计算性能高、计算效率高的ASIC专用芯片NPU诞生了。
NPU
NPU (NeuralNetworks Process Units)神经网络处理单元。其针对于矩阵运算进行了专门的优化设计,解决了传统芯片在神经网络运算时效率低下的问题。NPU工作原理是在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理。相比于CPU和GPU,NPU通过突出权重实现存储和计算一体化,从而提高运行效率。
神经网络处理器(NPU)**采用“数据驱动并行计算”的架构,**特别擅长处理视频、图像类的海量多媒体数据。NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。
NPU是模仿生物神经网络而构建的,CPU、GPU处理器需要用数千条指令完成的神经元处理,NPU只要一条或几条就能完成,因此在深度学习的处理效率方面优势明显。
神经网络中存储和处理是一体化的,都是通过突触权重来体现。 冯·诺伊曼结构中,存储和处理是分离的,分别由存储器和运算器来实现,二者之间存在巨大的差异。当用现有的基于冯·诺伊曼结构的经典计算机(如X86处理器和英伟达GPU)来跑神经网络应用时,就不可避免地受到存储和处理分离式结构的制约,因而影响效率。这也就是专门针对人工智能的专业芯片能够对传统芯片有一定先天优势的原因之一。
CPU如何辅助GPU实现加速
GPU当前只是单纯的并行矩阵的乘法和加法运算,对于神经网络模型的构建和数据流的传递还是在CPU上进行。
CPU加载权重数据,按照代码构建神经网络模型,将每层的矩阵运算通过CUDA或OpenCL等类库接口传送到GPU上实现并行计算,输出结果;CPU接着调度下层神经元组矩阵数据计算,直至神经网络输出层计算完成,得到最终结果。
CPU如何辅助NPU实现加速
NPU与GPU加速不同,主要体现为每层神经元计算结果不用输出到主内存,而是按照神经网络的连接传递到下层神经元继续计算,因此其在运算性能和功耗上都有很大的提升。
CPU将编译好的神经网络模型文件和权重文件交由专用芯片加载,完成硬件编程。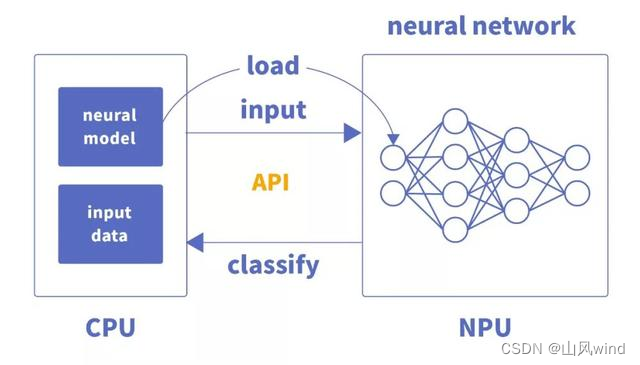
参考:https://www.cnblogs.com/liuyufei/p/13259264.html
https://blog.csdn.net/DeepAIedu/article/details/121324672
边栏推荐
- Interprocess communication
- Redis
- uniapp的request数据请求简单封装步骤
- Positive mask, negative mask, wildcard
- 融合迁移学习与文本增强的中文成语隐喻知识识别与关联研究
- Rtl8762dk environment construction (I)
- windows10 安装Sql Server 2019
- 基于GEC6818开发板的相册
- Weice biological IPO meeting: annual revenue of 1.26 billion Ruihong investment and Yaohe medicine are shareholders
- 次小生成树【模板】
猜你喜欢

Shell编程规范与变量
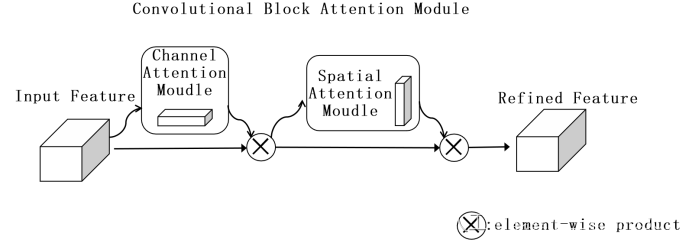
YOLOX改进之一:添加CBAM、SE、ECA注意力机制
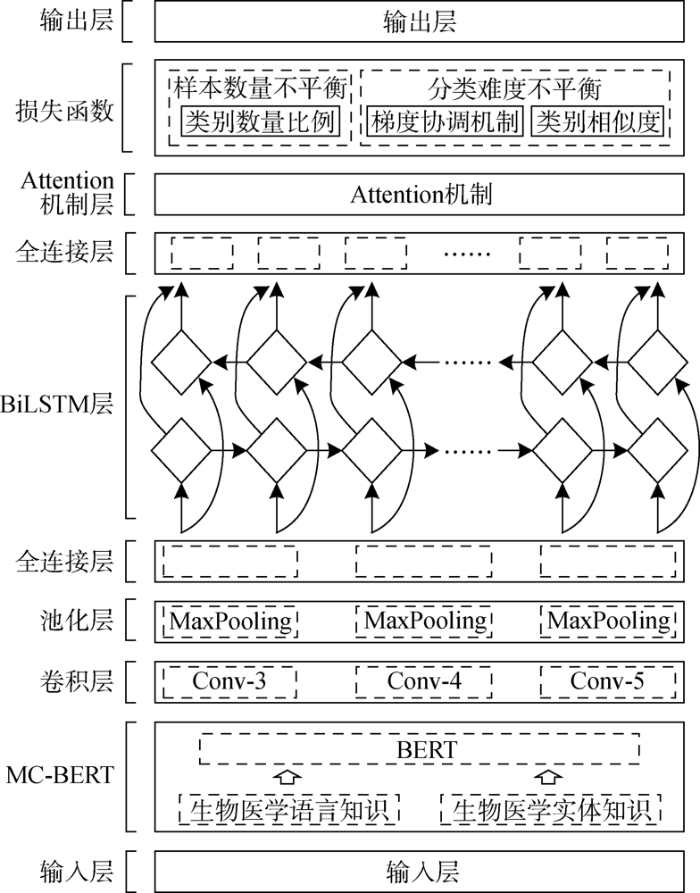
Research on automatic classification of electronic medical records based on unbalanced data

Chapter 3 business function development (add clues and remarks, and automatically refresh the added content)

大家最想要的,最全的C语言知识点总结,还不赶紧学习

机场云商sign解析
Airport cloud business sign analysis

万字详解 Google Play 上架应用标准包格式 AAB

线程知识总结

10 practical uses of NFT
随机推荐
C语言基础练习题目
How to return to the parent directory with commands
JS 疫情宅在家,学习不能停,七千字长文助你彻底弄懂原型与原型链
Weice biological IPO meeting: annual revenue of 1.26 billion Ruihong investment and Yaohe medicine are shareholders
C语言基础知识梳理总结
[intensive reading of papers] grounded language image pre training (glip)
机场云商sign解析
Hdu4496 d-city [concurrent search]
np.arange()和 range()的用法及区别
Cognition -- classic of the road to success of hardware engineers
第3章业务功能开发(查看线索明细)
Dako held a meeting for the biological IPO: the annual revenue was 837million, and Wu Qingjun and his daughter were the actual controllers
【STM32】EXTI
汉字风格迁移篇---对抗性区分域适应(L1)Adversarial Discriminative Domain Adaptation
面向流行性疾病科普的用户问题理解与答案内容组织
Group division and characteristic analysis of depression patients based on online consultation records
One of yolox improvements: add CBAM, Se, ECA attention mechanism
Schematic diagram of C measuring tool
进程间通信
Forward proxy and reverse proxy