当前位置:网站首页>Machine learning 7-Support vector machine
Machine learning 7-Support vector machine
2022-06-29 18:42:00 【Just a】
List of articles
One . SVM Basic concepts of the model
1.1 Starting from linear discrimination


If you need to build a classifier to separate the yellow dot from the blue dot in the above figure , The simplest way is to choose a line in the plane to separate the two , Make all the yellow dots and blue dots belong to the two sides of the straight line . There are an infinite number of options for such a line , But what kind of line is optimal ?
The obvious thing is , The effect of the red split line in the middle is better than that of the blue dotted line and green dotted line . as a result of , The sample points to be classified are generally far from the red line , So it is more robust . contrary , The blue dotted line and the green dotted line are close to several sample points respectively , Thus, after adding new sample points , Misclassification can easily occur .
1.2 Support vector machine (SVM) Basic concepts of
Distance from point to hyperplane
In the above classification task , In order to obtain a robust linear classifier , A very natural idea is , Find a dividing line so that the average distance between the samples on both sides and the dividing line is far enough . In European Space , Define a point 𝒙 The straight line ( Or hyperplane in high dimensional space ) 𝒘 𝑇 𝒙 + 𝑏 = 0 𝒘^𝑇 𝒙+𝑏=0 wTx+b=0 The formula for distance is :
𝑟 ( 𝑥 ) = ( ∣ 𝒘 𝑇 𝒙 + 𝑏 ∣ ) / ( ∣ ∣ 𝒘 ∣ ∣ ) 𝑟(𝑥)= (|𝒘^𝑇 𝒙+𝑏|)/(||𝒘||) r(x)=(∣wTx+b∣)/(∣∣w∣∣)
In the classification problem , If such a dividing line or plane can accurately separate the samples , For samples 𝒙 𝑖 , 𝑦 𝑖 ∈ 𝐷 , 𝑦 𝑖 = ± 1 {𝒙_𝑖,𝑦_𝑖}∈𝐷, 𝑦_𝑖=±1 xi,yi∈D,yi=±1 for , if 𝑦 𝑖 = 1 𝑦_𝑖=1 yi=1, Then there are 𝒘 𝑇 𝒙 𝒊 + 𝑏 ≥ 1 𝒘^𝑇 𝒙_𝒊+𝑏≥1 wTxi+b≥1, Conversely, if 𝑦 𝑖 = − 1 𝑦_𝑖=-1 yi=−1, Then there are 𝒘 𝑇 𝒙 𝒊 + 𝑏 ≤ − 1. 𝒘^𝑇 𝒙_𝒊+𝑏≤−1. wTxi+b≤−1.
Support vector and interval
For satisfying 𝒘 𝑇 𝒙 𝒊 + 𝑏 = ± 1 𝒘^𝑇 𝒙_𝒊+𝑏=±1 wTxi+b=±1 The sample of , They must have landed on 2 On hyperplanes . These samples are called “ Support vector (support vector)”, this 2 A hyperplane is called the maximum separation boundary . The sum of the distances between the samples belonging to different categories and the segmentation plane is
𝛾=2/(||𝑤||)
The sum of these distances is called “ interval ”

Two . SVM Objective function and dual problem of
2.1 Optimization problem of support vector machine
therefore , For completely linearly separable samples , The task of classification model is to find such hyperplane , Satisfy 
It is equivalent to solving the constrained minimization problem :
2.2 Dual problem of optimization problem
Generally speaking , When solving optimization problems with equality or inequality constraints , The Lagrange multiplier method is usually used to transform the original problem into a dual problem . stay SVM In the optimization problem of , The corresponding dual problem is :
Yes 𝐿(𝑤,𝑏,𝛼) About 𝑤,𝑏,𝛼 And let be the partial derivative of 0, Yes :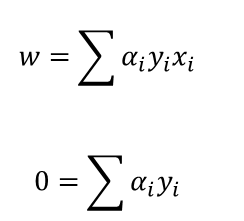
The final optimization problem turns into 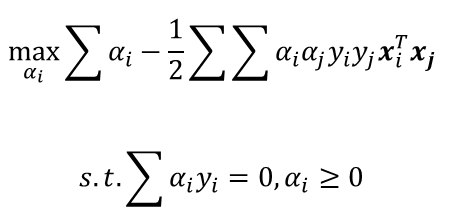
figure out 𝛼 after , Find out 𝑤,𝑏 You get the model . In general use SMO Algorithmic solution .
2.3 Support vector and non support vector
be aware , 𝑦 𝑖 ( 𝒘 𝑇 𝒙 𝒊 + 𝑏 ) ≥ 1 𝑦_𝑖 (𝒘^𝑇 𝒙_𝒊+𝑏)≥ 1 yi(wTxi+b)≥1 It's an inequality constraint , therefore a 𝑖 a_𝑖 ai Need to meet a 𝑖 ( 𝑦 𝑖 ( 𝒘 𝑇 𝒙 𝒊 + 𝑏 ) − 1 ) = 0 a_𝑖 (𝑦_𝑖 (𝒘^𝑇 𝒙_𝒊+𝑏)−1)=0 ai(yi(wTxi+b)−1)=0( This is a KKT The condition of inequality constraint in condition ). therefore , A sample that satisfies such a condition 𝒙 𝒊 , y i {𝒙_𝒊,y_i} xi,yi, or a 𝑖 = 0 a_𝑖=0 ai=0, or 𝑦 𝑖 ( 𝒘 𝑇 𝒙 𝒊 + 𝑏 ) − 1 𝑦_𝑖 (𝒘^𝑇 𝒙_𝒊+𝑏)−1 yi(wTxi+b)−1. So for SVM In terms of training samples ,
If a 𝑖 = 0 a_𝑖=0 ai=0, be ∑ 〖 a i − 1 / 2 ∑ ∑ a i a 𝑗 𝑦 𝑖 𝑦 𝑗 𝒙 𝑖 𝑇 𝒙 𝒋 ∑〖a_i−1/2 ∑∑a_i a_𝑗 𝑦_𝑖 𝑦_𝑗 𝒙_𝑖^𝑇 𝒙_𝒋 ∑〖ai−1/2∑∑aiajyiyjxiTxj The sample will not appear in the calculation of
If 𝑦 𝑖 ( 𝒘 𝑇 𝒙 𝒊 + 𝑏 ) − 1 𝑦_𝑖 (𝒘^𝑇 𝒙_𝒊+𝑏)−1 yi(wTxi+b)−1, Then the sample is on the maximum interval boundary
You can see that , Most of the training samples will not have any influence on the solution of the model , Only support vectors affect the solution of the model .
3、 ... and . Soft space
3.1 Linearly indivisible
In a normal business scenario , Linear separability can be encountered but not solved . It is more linear and indivisible , That is, it is impossible to find such a hyperplane that can completely and correctly separate the two types of samples .
To solve this problem , One way is that we allow some samples to be incorrectly classified ( But not too much !) . Intervals with misclassification , be called “ Soft space ”. therefore , The objective function is still a constrained maximization interval , The constraints are , dissatisfaction 𝑦 𝑖 ( 𝒘 𝑇 𝒙 𝒊 + 𝑏 ) ≥ 1 𝑦_𝑖 (𝒘^𝑇 𝒙_𝒊+𝑏)≥ 1 yi(wTxi+b)≥1 The fewer samples the better .
3.2 Loss function
Based on this idea , We rewrite the optimization function 
Turn it into 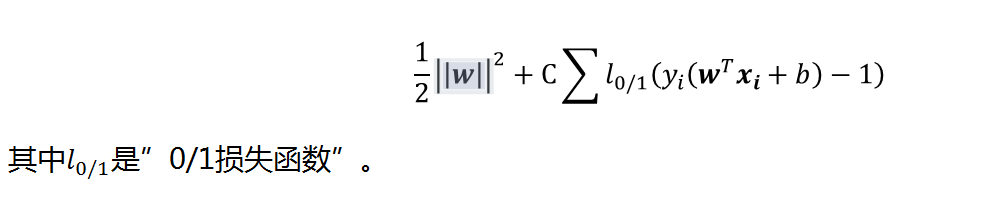
The available loss functions are :
3.3 Relax variables
When using hinge loss When , The loss function becomes 
3.4 Solve the soft interval with relaxation variable SVM
Make 𝐿(𝑤,𝑏,𝛼,𝜂,𝜇) About 𝑤,𝑏, 𝜂 The partial derivative of is equal to 0, Then there are :
3.5 Support vector and non support vector

Four . Kernel function
4.1 From low dimension to high dimension

Linearly indivisible :
Linearly separable :

4.2 Kernel function

4.3 The choice of kernel function

Some prior experience
- If the number of features is much larger than the number of samples , Just use a linear kernel
- If both the number of features and the number of samples are large , For example, document classification , Linear kernels are generally used
- If the number of features is much smaller than the number of samples , In this case, we usually use RBF
Or use cross validation to select the most appropriate kernel function
4.4 SVM Advantages and disadvantages of the model
advantage :
- Suitable for small sample classification
- Strong generalization ability
- The local optimal solution must be the global optimal solution
shortcoming :
- It takes a lot of calculation , Large scale training samples are difficult to implement
- The result is hard classification rather than probability based soft classification .SVM Probability can also be output , But the calculation is more complicated
Reference resources :
- http://www.dataguru.cn/mycourse.php?mod=intro&lessonid=1701
边栏推荐
- 【日常训练】535. TinyURL 的加密与解密
- Adobe Premiere foundation - cool text flash (14)
- 行程卡“摘星”热搜第一!刺激旅游产品搜索量齐上涨
- Cannot retrieve repository metadata processing records
- 保持jupyter notebook在终端关闭时的连接方法
- Adobe Premiere基础-炫酷文字快闪(十四)
- jdbc_ Related codes
- Shandong University project training (VI) Click event display line chart
- Travel card "star picking" hot search first! Stimulate the search volume of tourism products to rise
- Adobe Premiere Basics - general operations for editing material files (offline files, replacing materials, material labels and grouping, material enabling, convenient adjustment of opacity, project pa
猜你喜欢
Adobe Premiere foundation - batch material import sequence - variable speed and rewind (recall) - continuous action shot switching - subtitle requirements (13)

报错Failed to allocate graph: MYRIAD device is not opened.

Anfulai embedded weekly report no. 271: June 20, 2022 to June 26, 2022

Notes on spintronics - zhangshufeng

Amazing pandaverse:meta "borderless, to activate fashion attributes in the new journey of 2.0

Adobe Premiere foundation - material nesting (animation of Tiktok ending avatar) (IX)

Adobe Premiere Basics - common video effects (corner positioning, mosaic, blur, sharpen, handwriting tools, effect control hierarchy) (16)

garbage collector

The strategy of convertible bonds -- - (cake sharing, premium, forced redemption, downward revision, double low)

My first experience of remote office | community essay solicitation
随机推荐
Tag filtering and SQL filtering of rocketmq
Adobe Premiere基础-时间重映射(十)
postgis 生成 图形切割
[daily training] 535 Encryption and decryption of tinyurl
Request header field XXXX is not allowed by access control allow headers in preflight response
Sd6.22 summary of intensive training
AMAZING PANDAVERSE:META”无国界,来2.0新征程激活时髦属性
Failed to allocate graph: myriad device is not opened
Adobe Premiere基础-素材嵌套(制作抖音结尾头像动画)(九)
报错Failed to allocate graph: MYRIAD device is not opened.
Adobe Premiere foundation - cool text flash (14)
WBF: new method of NMS post filter frame for detection task?
Data warehouse model layered ODS, DWD, DWM practice
Encryption and decryption of 535 tinyurl
龙canvas动画
源码安装MAVROS
These advantages of the Institute are really fragrant! The landing rate is still very high!
MySQL enterprise development specification
【日常训练】535. TinyURL 的加密与解密
Shandong University project training (VII) add navigation bar to select city