当前位置:网站首页>CNN convolution neural network learning process (weight update)
CNN convolution neural network learning process (weight update)
2022-07-28 20:22:00 【LifeBackwards】
Convolutional neural network adopts BP Algorithm learning network parameters ,BP The algorithm is based on the gradient descent principle to update the network parameters . In a convolutional neural network , The parameters to be optimized include convolution kernel parameters k、 Lower sampling layer weight β、 Full connection layer network weights w And offset of each layer b. We take the mean square error between the expectation and output of convolutional neural network as the cost function , The aim is to minimize the cost function , So that the actual neural network output can accurately predict the input , The cost function is as follows :
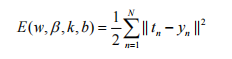
among ,N For the number of training samples ,![]() It's No n Real category labels of training samples ,
It's No n Real category labels of training samples ,![]() It's No n The prediction category labels obtained by convolution neural network learning of training samples .
It's No n The prediction category labels obtained by convolution neural network learning of training samples .
Convolution layer gradient calculation
Generally speaking, every convolution l There will be a lower sampling layer behind l+1, According to the back-propagation method , To get convolution layer l The gradient of each neural node corresponding to the weight , You need to find l The residual of each neural node of the layer δ, That is, the partial derivative of the cost function for each neural node . In order to find the residual , You need to sum up the residuals of the nodes at the next level to get ![]() , Then multiply by the weight corresponding to these connections W, Then multiply by l Input of this neural node in the layer u The activation function of f Partial derivative of , It can be obtained. l Residual of each neural node in layer
, Then multiply by the weight corresponding to these connections W, Then multiply by l Input of this neural node in the layer u The activation function of f Partial derivative of , It can be obtained. l Residual of each neural node in layer ![]() . Due to the existence of down sampling , The residual of the neural node of the sampling layer corresponds to the region of the sampling window size in the output characteristic graph of the previous layer , therefore l Each neural node of each feature graph in the layer is only associated with l+1 The layer is connected with a neural node in the corresponding characteristic graph , Calculate the residual of each pixel in the feature map to get the residual map . For calculation l Layer residuals , The residuals corresponding to the upper sampling layer and the lower sampling layer are required , And then l The partial derivative of the excitation function of the characteristic graph of the layer and the residual graph obtained by up sampling are multiplied item by item . Finally, multiply the above results by the weight β, Thus, the convolution layer is obtained l Residual of . The residual of the characteristic graph in the convolution layer is calculated by the following formula :
. Due to the existence of down sampling , The residual of the neural node of the sampling layer corresponds to the region of the sampling window size in the output characteristic graph of the previous layer , therefore l Each neural node of each feature graph in the layer is only associated with l+1 The layer is connected with a neural node in the corresponding characteristic graph , Calculate the residual of each pixel in the feature map to get the residual map . For calculation l Layer residuals , The residuals corresponding to the upper sampling layer and the lower sampling layer are required , And then l The partial derivative of the excitation function of the characteristic graph of the layer and the residual graph obtained by up sampling are multiplied item by item . Finally, multiply the above results by the weight β, Thus, the convolution layer is obtained l Residual of . The residual of the characteristic graph in the convolution layer is calculated by the following formula :
![]()
among , Symbol ο Represents the multiplication of each element ,up(·) Indicates an upsampling operation . If the sampling factor of down sampling is n, that up(·) The operation is to copy each element horizontally and vertically n Time . function up(·) It can be used Kronecker The product of ![]() To achieve . According to this residual figure , The gradient of the offset and convolution kernel corresponding to the characteristic graph can be calculated :
To achieve . According to this residual figure , The gradient of the offset and convolution kernel corresponding to the characteristic graph can be calculated :

among ,(u, v) Represents the coordinates of pixels in the feature map ,![]() To calculate
To calculate ![]() when , And
when , And ![]() Multiplied item by item
Multiplied item by item ![]() Elements .
Elements .
Gradient calculation of lower sampling layer
The parameters involved in the down sampling forward process have a multiplicative factor corresponding to each characteristic graph β And an offset b. In order to find the lower sampling layer l Gradient of , You need to find the corresponding area between the residual graph of the current layer and the residual graph of the next layer , Then the residual is propagated back . Besides , It also needs to be multiplied by the weight between the input characteristic map and the output characteristic map , This weight is the parameter of convolution kernel . The formula is as follows :
![]()
Multiplicative factor β And offset b The gradient calculation formula of is as follows :

Gradient calculation of full connection layer
The calculation of the full connection layer is similar to that of the lower sampling layer , The residual calculation formula is as follows :
![]()
The partial derivative of the cost function to the bias is as follows :
![]()
The gradient calculation formula of the weight of the whole connection layer is :

边栏推荐
- [C language] guessing numbers game [function]
- C language - question brushing column
- HSETNX KEY_ Name field value usage
- robobrowser的简单使用
- How to automatically store email attachments in SharePoint
- 读取json配置文件,实现数据驱动测试
- C language operators and input and output
- Windows系统下Mysql数据库定时备份
- Solve the kangaroo crossing problem (DP)
- LeetCode-297-二叉树的序列化与反序列化
猜你喜欢

9. Pointer of C language (2) wild pointer, what is wild pointer, and the disadvantages of wild pointer

Zfoo adds routes similar to mydog

83.(cesium之家)cesium示例如何运行

Raspberry connects EC20 for PPP dialing

Introduction to seven kinds of polling (practice link attached)

Tencent cloud deployment lamp_ Experience of building a station

Const pointer of C language and parameter passing of main function

ssm中项目异常处理
![[C language] simulation implementation of pow function (recursion)](/img/7b/ef8b3d97adc7810de249a37642c71f.png)
[C language] simulation implementation of pow function (recursion)

Implementation of strstr in C language
随机推荐
WPF--实现WebSocket服务端
Power Bi 2021 calendar DAX code
Durham High Lord (classic DP)
数据挖掘(数据预处理篇)--笔记
Representation of base and number 2
83.(cesium之家)cesium示例如何运行
Raspberry pie creation self start service
How to automatically store email attachments in SharePoint
[C language] Pointer advanced knowledge points
LeetCode_位运算_中等_260.只出现一次的数字 III
Rand function generates pseudo-random numbers
Solve the kangaroo crossing problem (DP)
为什么客户支持对SaaS公司很重要?
lattice
How can Plato obtain premium income through elephant swap in a bear market?
Maximum exchange [greedy thought & monotonic stack implementation]
C language operators and input and output
[C language] string reverse order implementation (recursion and iteration)
Simple use of robobrowser
Array method added in ES6