当前位置:网站首页>[medical segmentation] attention Unet
[medical segmentation] attention Unet
2022-07-07 16:36:00 【Coke Daniel】
summary
attention-unet The main contribution is to propose attention gate, It's plug and play , It can be directly integrated into unet In the model , The function is to suppress irrelevant areas in the input image , At the same time, highlight the remarkable characteristics of specific local areas , And it uses soft-attention Instead of hard-attention, therefore attention Weights can be learned online , And there's no need for extra label, Only a small amount of calculation is added .
details
structure
The core or unet Structure , But doing skip-connection When , In the middle there's a attention gate, After this ag after , Proceed again concat operation . because encoder There is relatively more fine-grained information in , But many are unnecessary redundancy ,ag Quite so encoder The current layer of is filtered , Suppress irrelevant information in the image , Highlight important local features .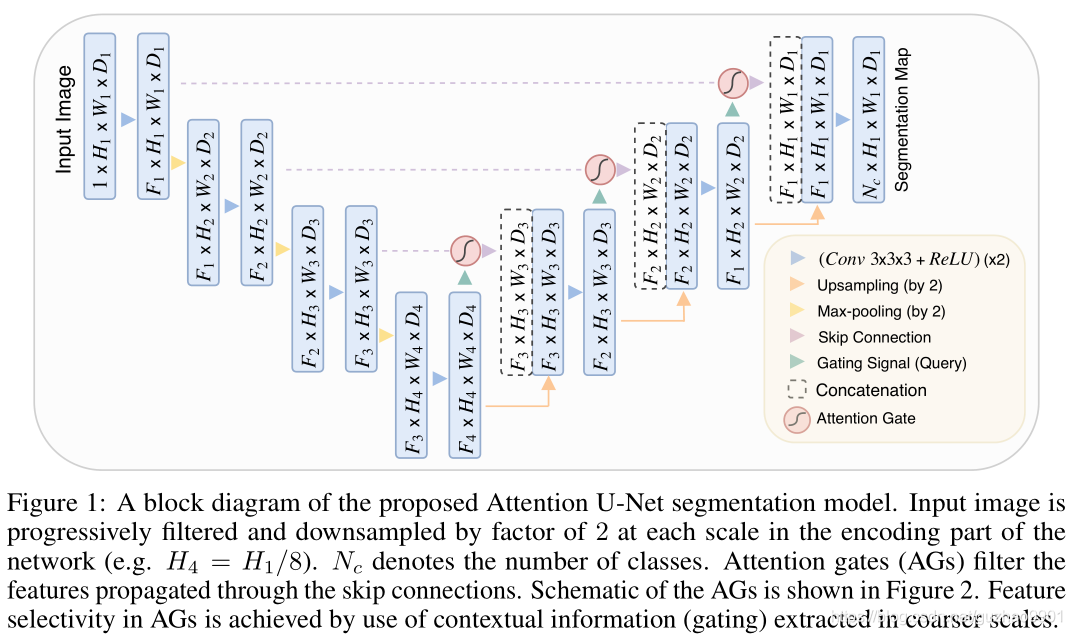
attention gate
The two inputs are encoder Current layer of x l x^l xl and decoder The next layer of g g g, They passed by 1x1 Convolution of ( After making the number of channels consistent ), Then add elements by elements , And then pass by relu,1x1 Convolution of ( Reduce the number of channels to 1) and sigmoid Get the attention coefficient , And then there's another resample The module restores the size , Finally, the attention coefficient can be used to weight the feature map .
notes : Here is 3D Of ,2D If you understand , Just remove the last dimension .
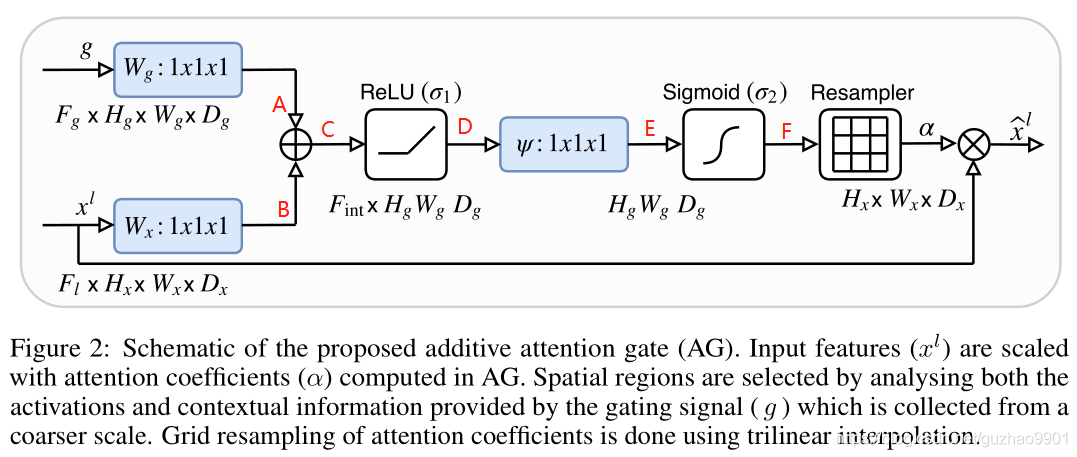
Some explanations : Why add two inputs instead of directly based on encoder The current layer of gets the attention coefficient ?
Probably because , First, two characteristic graphs with the same size and number of channels are processed , The extracted features are different . Then this operation can strengthen the signal of the same region of interest , At the same time, different areas can also be used as auxiliary , The two copies add up to more auxiliary information . Or the further emphasis on the core information , At the same time, don't ignore those details .
Why resample Well ?
because x l And g x^l And g xl And g The size of is different , obviously g g g Its size is x l x^l xl Half of , They cannot add element by element , So we need to make the two dimensions consistent , Either large down sampling or small up sampling , The experiment shows that the effect of large down sampling is good . But what you get after this operation is the attention coefficient , Want to be with x l x^l xl The weight must be the same size , So we have to re sample .
attention
Attention The essence of a function can be described as a query (query) To a series of ( key key- value value) Mapping to
In the calculation attention It is mainly divided into three steps :
- The first step is to query And each key Calculate the similarity to get the weight , The common similarity function is a little product , Splicing , Perceptron, etc ;
- The second step is usually to use a softmax Function normalizes these weights ;
- Finally, the weight and the corresponding key value value Weighted sum to get the final attention.
hard-attention: Select one area of an image at a time as attention , set 1, Others are set to 0. He can't differentiate , Standard back propagation is not possible , Therefore, Monte Carlo sampling is needed to calculate the accuracy of each back-propagation stage . Considering that the accuracy depends on the completion of sampling , Therefore, its Other technology ( For example, reinforcement learning ).
soft-attention: Each pixel of the weighted image . Multiply the high correlation area by a larger weight , Low correlation areas are marked with smaller weights . The weight range is (0-1). He is differentiable , Back propagation can be carried out normally .
边栏推荐
- 95. (cesium chapter) cesium dynamic monomer-3d building (building)
- Find tags in prefab in unity editing mode
- laravel 是怎么做到运行 composer dump-autoload 不清空 classmap 映射关系的呢?
- Sysom case analysis: where is the missing memory| Dragon lizard Technology
- 【Vulnhub靶场】THALES:1
- The differences between exit, exit (0), exit (1), exit ('0 '), exit ('1'), die and return in PHP
- Shandong old age Expo, 2022 China smart elderly care exhibition, smart elderly care and aging technology exhibition
- How to query the data of a certain day, a certain month, and a certain year in MySQL
- 面试题 01.02. 判定是否互为字符重排-辅助数组算法
- prometheus api删除某个指定job的所有数据
猜你喜欢


随机推荐
Three. JS series (3): porting shaders in shadertoy
Record the migration process of a project
spark调优(三):持久化减少二次查询
如何快速检查钢网开口面积比是否符合 IPC7525
MySQL中, 如何查询某一天, 某一月, 某一年的数据
作为Android开发程序员,android高级面试
How can laravel get the public path
Logback logging framework third-party jar package is available for free
Cesium (4): the reason why gltf model is very dark after loading
记一次项目的迁移过程
The team of East China Normal University proposed the systematic molecular implementation of convolutional neural network with DNA regulation circuit
121. The best time to buy and sell stocks
Geoserver2.18 series (5): connect to SQLSERVER database
PHP实现微信小程序人脸识别刷脸登录功能
Three. JS series (1): API structure diagram-1
Power of leetcode-231-2
Communication mode between application program and MATLAB
Usage of config in laravel
网关Gateway的介绍与使用
Logback日志框架第三方jar包 免费获取