当前位置:网站首页>Article main content extraction software [based on NLP technology]
Article main content extraction software [based on NLP technology]
2022-07-27 04:03:00 【Yangyang 2013 haha】
Use the computer to process a large number of texts , Produce simplicity 、 The process of refining content is text summarization , People can grasp the main content of the text by reading the abstract , This not only saves a lot of time , Improve reading efficiency .
One: TextRank(extract keywords and extract abstract)
TextRank The algorithm is a graph based sorting algorithm for text , Used to extract text keywords and abstracts . The basic idea comes from Google PageRank Algorithm , By dividing the text into several constituent units ( word 、 The sentence ) And build a graph model , Using voting mechanism to sort the important components in the text , Only using the information of a single document can realize keyword extraction 、 Abstract . Let's start with PageRank* Algorithm .*
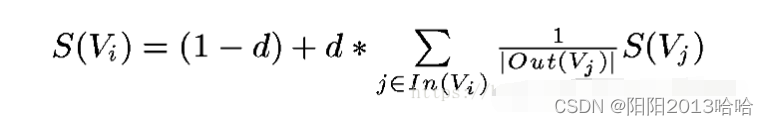
word How can documents Automatic generation Catalog And automatically extract summaries ?
The steps to automatically create a summary are as follows :
(1) single click 【 Tools 】 Menu 【 Automatically write summaries 】 A menu item .Word Just Will start automatically writing summaries , To cancel the summary being executed , Press Esc key . After the command is completed, the following figure will appear 6-41 Shown 【 Automatically write summaries 】 Dialog box .
(2) stay 【 Summary type 】 Next, select the display scheme of the document .
(3) stay 【 Equivalent to the percentage of original length 】 Box, type or select the detailed process of the summary degree .
(4) If you want to update the statistics of the document , Please check 【 Update document statistics 】 Check box .
Automatic directory generation steps :
Point format >> Style and format , A format selection box will appear on the right side of the page , You point to the top on the right >> New style >> Fill in the first level title in the name of the pop-up box , Select a paragraph from the style type , The style is based on the selected title 1, Select the text in the following paragraphs , Then set the font of the title text according to your requirements below 、 Font size 、 How many pounds are there before and after . There is also a row of options to save to template at the bottom of this window , If you plan to use this style in your future documents, click Save to template , If there will be changes in the future, don't check . Point determination , Your first level Title format is set . At this time, a style name named “ First level title ”.
Back to your article , Put the primary title of your article , Select the title of your chapter one by one in the style box on the right “ First level title ” It will be the same as what you just set .
Set your secondary and tertiary headings in the same way , Name the secondary title based on the title 2, The third level title is based on the title 3 such , And go back to the text and apply one by one .
After formatting all your titles , The cursor returns to the front of your article , Point insertion - quote - Catalog , Set the directory display level to 3, So your directory is generated , The directory includes all titles above your three-level titles .
Before generating the directory, open your document structure diagram and display it on the left , Here you can clearly see the structure of your article , This structure is the basis of your automatic directory generation , If your document structure diagram is messy , The automatically generated directory is messy .
python What libraries are there to extract text summaries
The content of an article can be in plain text , But in today's Internet era , More HTML Format . Whatever the format , Abstract It's usually an article beginning The content of , You can follow the specified Number of words To extract .
Two 、 Plain text summary
Plain text documents Is a long string , It is easy to extract its summary :
#!/usr/bin/env python.
# -*- coding: utf-8 -*-.
"""Get a summary of the TEXT-format document""".
def get_summary(text, count):.
u"""Get the first `count` characters from `text`.
>>> text = u'Welcome This is about Python The article '.
>>> get_summary(text, 12) == u'Welcome This is an article '.
True
"""
assert(isinstance(text, unicode)).
return text[0:count].
if __name__ == '__main__':.
import doctest.
doctest.testmod().
3、 ... and 、HTML Abstract
HTML file Contains a large number of flags ( Such as <h1>、<p>、<a> wait ), These characters are marking instructions , And usually appear in pairs , Simple text interception will destroy HTML The document structure of , As a result, the summary is not displayed properly in the browser .
Following HTML Document structure at the same time , And intercept the content , It needs to be resolved HTML file . stay Python in , You can use the standard library HTMLParser To complete .
One of the simplest summary extraction functions , Is to ignore HTML Tag and only extract the native text inside the tag . The following is similar to this function Python Realization :
#!/usr/bin/env python.
# -*- coding: utf-8 -*-.
"""Get a raw summary of the HTML-format document""".
from HTMLParser import HTMLParser.
class SummaryHTMLParser(HTMLParser):.
"""Parse HTML text to get a summary.
>>> text = u'<p>Hi guys:</p><p>This is a example using SummaryHTMLParser.</p>'.
>>> parser = SummaryHTMLParser(10).
>>> parser.feed(text).
>>> parser.get_summary(u'...').
u'<p>Higuys:Thi...</p>'.
"""
def __init__(self, count):.
HTMLParser.__init__(self).
self.count = count.
self.summary = u''.
def feed(self, data):.
"""Only accept unicode `data`""".
assert(isinstance(data, unicode)).
HTMLParser.feed(self, data).
def handle_data(self, data):.
more = self.count - len(self.summary).
if more > 0:.
# Remove possible whitespaces in `data`.
data_without_whitespace = u''.join(data.split()).
self.summary += data_without_whitespace[0:more].
def get_summary(self, suffix=u'', wrapper=u'p'):.
return u'<{0}>{1}{2}</{0}>'.format(wrapper, self.summary, suffix).
if __name__ == '__main__':.
import doctest.
doctest.testmod().
HTMLParser( perhaps BeautifulSoup wait ) It is more suitable for completing complex HTML Summary extraction function , For the above simple HTML Summary extraction function , In fact, there are simpler implementation schemes ( comparison SummaryHTMLParser for ):
#!/usr/bin/env python.
# -*- coding: utf-8 -*-.
"""Get a raw summary of the HTML-format document""".
import re
def get_summary(text, count, suffix=u'', wrapper=u'p'):.
"""A simpler implementation (vs `SummaryHTMLParser`)..
>>> text = u'<p>Hi guys:</p><p>This is a example using SummaryHTMLParser.</p>'.
>>> get_summary(text, 10, u'...').
u'<p>Higuys:Thi...</p>'.
"""
assert(isinstance(text, unicode)).
summary = re.sub(r'<.*?>', u'', text) # key difference: use regex.
summary = u''.join(summary.split())[0:count].
return u'<{0}>{1}{2}</{0}>'.format(wrapper, summary, suffix).
if __name__ == '__main__':.
import doctest.
doctest.testmod().
EXCEL How to extract names from irregular summaries
First copy the area to be extracted ,
Then pull the width of that column to the size of one word .
Fill at point —— full-justified , The effect is as shown in the picture .
Point data —— Dissection —— next step —— next step —— complete .
Click Find —— Location condition —— Constant —— Check only 【 Text 】
There is a long column , Right click , Then click delete —— Move the lower cell up , The effect is as shown in the picture .
Finally, widen the column that is only one word wide , The numbers are displayed .
How to extract content summary 10
If you need to write it yourself , You need to know something about pdf The infrastructure in the document ( You can refer to PDF Reference 8.8). All the information you need is catalog\info In the object . If you need help, you can add me .88998888.
Derived from UFIDA excel How to extract Department items in the Sub Ledger summary ?
Your data seems to be regular All are "-" The symbols are spaced , You can use it once .
Tool blue - data - Dissection - Separator symbol -‘ next step ’-‘ other ’- Input Separator "-"( Don't use quotation marks , I just want to emphasize ), The next step is done .
边栏推荐
- 在Golang结构体中使用tag标签
- 回归测试:意义、挑战、最佳实践和工具
- Binary tree (day 82)
- Leetcode- > 2-point search and clock in (3)
- Characteristics and experimental suggestions of abbkine abfluor 488 cell apoptosis detection kit
- 一维数组的应用
- On the first day of Shenzhen furniture exhibition, the three highlights of Jin Ke'er booth were unlocked!
- 222. Number of nodes of complete binary tree
- Will this flinkcdc monitor all tables in the database? Or the designated table? I look at the background log. It monitors all tables. If it monitors
- VR全景制作在家装行业是谈单利器?这是为什么呢?
猜你喜欢

飞腾腾锐 D2000 荣获数字中国“十大硬核科技”奖

Framework学习之旅:init 进程启动过程

222. 完全二叉树的节点个数

Specific use of multithreading

Use websocket to realize a web version of chat room (fishing is more hidden)

ApacheCon Asia 预热直播之孵化器主题全回顾
科目三: 济南章丘五号线
Feitengtengrui d2000 won the "top ten hard core technologies" award of Digital China

函数指针与回调函数

C. Cypher
随机推荐
Cocos game practice-05-npc and character attack logic
C language introduction practice (12): find the value of natural constant e
开机启动流程及营救模式
mysql中case when返回多个字段处理方案
Chapter 5 decision tree and random forest practice
C语言力扣第43题之字符串相乘。优化竖式
Plato farm has a new way of playing, and the arbitrage eplato has secured super high returns
flink cdc 到MySQL8没问题,到MySQL5读有问题,怎么办?
Feitengtengrui d2000 won the "top ten hard core technologies" award of Digital China
Chapter 4 决策树和随机森林
第六周复习
Solution to Chinese garbled code in console header after idea connects to database to query data
VR全景现在是不是刚需?看完你就明白了
A. Round Down the Price
Interview question: the difference between three instantiated objects in string class
Function pointer and callback function
Binary tree (Beijing University of Posts and Telecommunications machine test questions) (day85)
Process analysis of object creation
Day 27 of leetcode
酷雷曼VR全景为你铺设创业之路