当前位置:网站首页>Summary 1 - deep learning - basic knowledge learning
Summary 1 - deep learning - basic knowledge learning
2022-07-25 22:39:00 【III】
- 【 Notes 】 The difference between down sampling and pooling :
Pool of God explanation :
Pooling = Rising water
The process of pooling = Raise the water level ( Expand the matrix grid )
The purpose of pooling is to get the edge shape of the object . It is conceivable that the water needs to understand the three-dimensional shape of the mountain , When the water level is low, we can get the shape of the foot of the mountain , When the water level is medium, the shape of the hillside is obtained , When the water level is high, we can get the shape of the top of the mountain , At three o'clock, you can roughly draw the simple strokes of the mountain . The process of convolution is to distinguish where water is , Where is the mountain . For network structure , The upper layer looks at the lower layer passing pooling The later feature map , It's like looking down at the earth from space , All I saw were ridges and snow peaks . This is the further abstraction of features in the macro .
Pooling method :
1、max-pooling: Take the maximum value of the feature points in the neighborhood ;
2、mean-pooling: Average the feature points in the neighborhood
The role of pooling :
1、 Dimension reduction , Reduce the number of parameters the network needs to learn ;
2、 Prevent over fitting ;
3、 Expand the feeling field ;
4、 Implement invariance ( translation 、 rotate 、 Scale invariance ) - The difference between convolution and pooling : Pooling (pooling), That is, downsampling (subsample), Reduce the size of the data .
Set the input as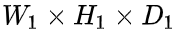 , The size of the pool layer is
, The size of the pool layer is  ,stride Step:
,stride Step:  , The size of the output matrix is
, The size of the output matrix is  , be :
, be :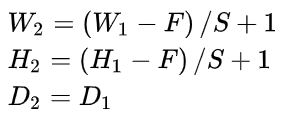
- Convolution :

Pooling :
- Relu The function of activation : In a word , Actually ,relu The function is to increase the nonlinear relationship between the layers of the neural network , otherwise , If there is no activation function , There is a simple linear relationship between layers , Each layer is equivalent to matrix multiplication , In this way, how can we complete the complex tasks we need neural network to complete .ReLU The effectiveness of is reflected in two aspects :1、 More efficient gradient descent and back propagation : The problems of gradient explosion and gradient disappearance are avoided ;2、 Simplify the calculation process , Speed up your training .
- Deep learning VGG Model core disassembly ,AlexNet and VGGNet, See this , Let me have a look first CNN The Internet .
- CNN( Convolutional neural networks ) introduction ,
- CNN Basic knowledge of —— Convolution (Convolution)、 fill (Padding)、 step (Stride)
What is called in deep learning Convolution operation (Convolution), In fact, it is called Cross correlation (cross-correlation) operation : Add the image to the matrix , From left to right , From top to bottom , Take a part of the same size as the filter , The value in each part is multiplied by the value in the filter and then summed , The final results form a matrix , There is no flipping of the nucleus .
Let's take gray image as an example to explain : From a small weight matrix , Convolution kernel (kernel) Start , Let it step by step on the two-dimensional input data “ scanning ”. Convolution kernel “ slide ” At the same time , Calculate the product of the weight matrix and the scanned data matrix , Then summarize the results into an output pixel . See the picture below .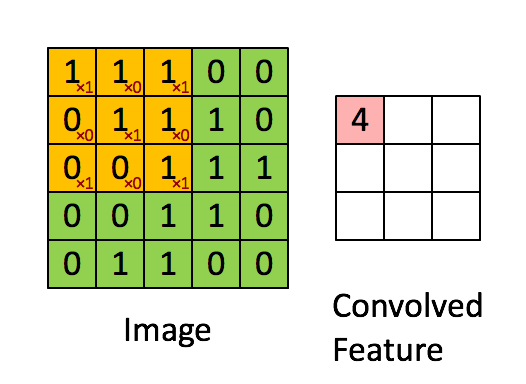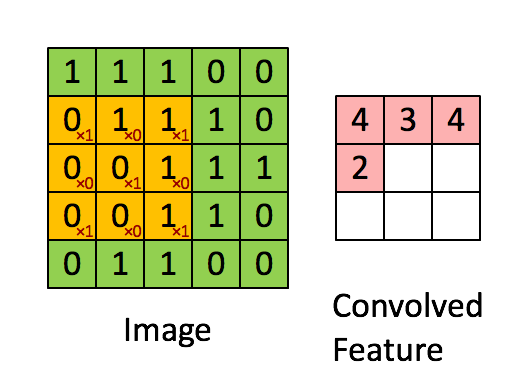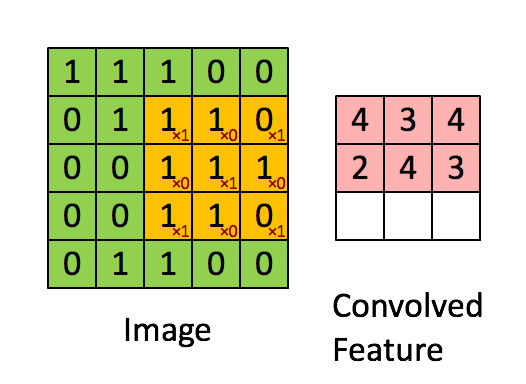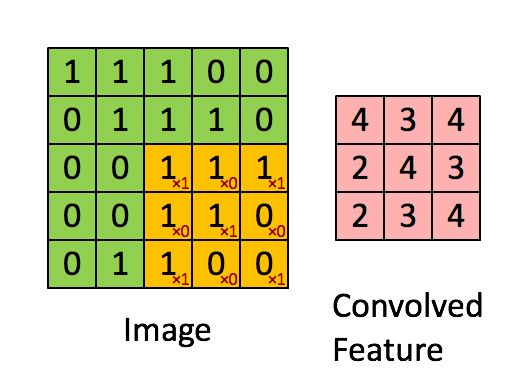
Sometimes we also hope that the size of input and output should be consistent . To solve this problem , Before the convolution operation , Boundary the original matrix fill (Padding), That is, fill in some values on the boundary of the matrix , To increase the size of the matrix , Usually “0” To fill in .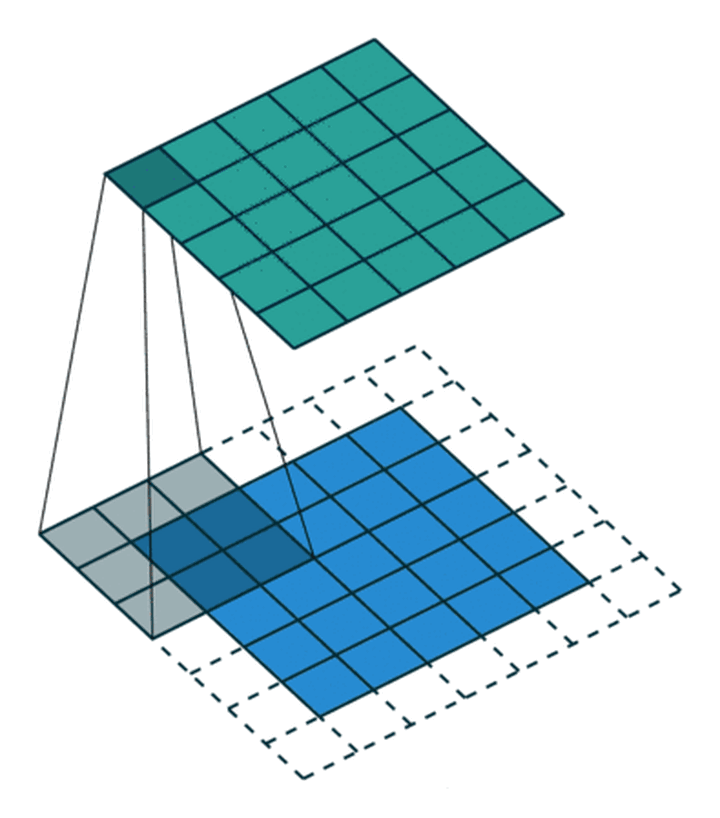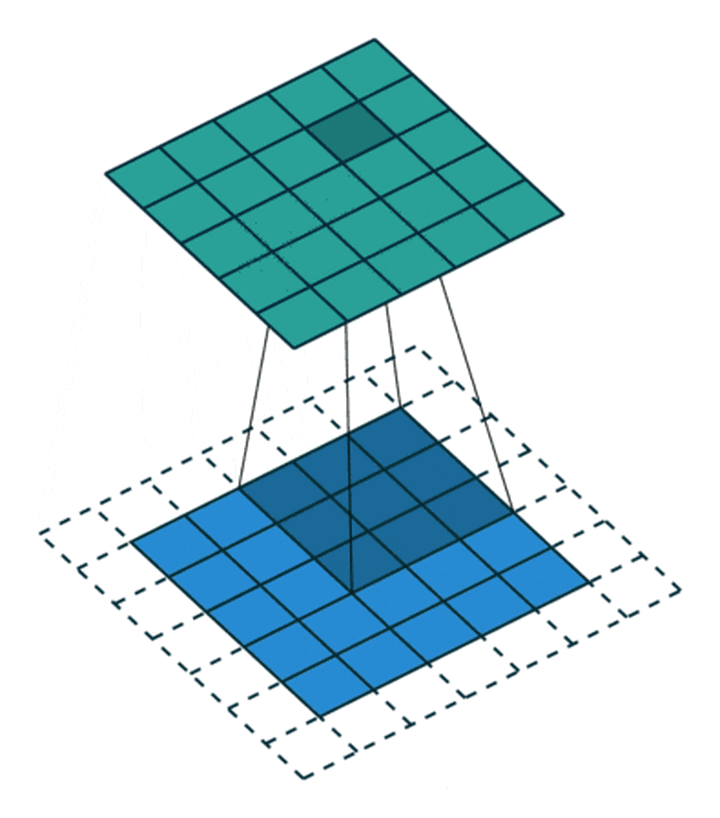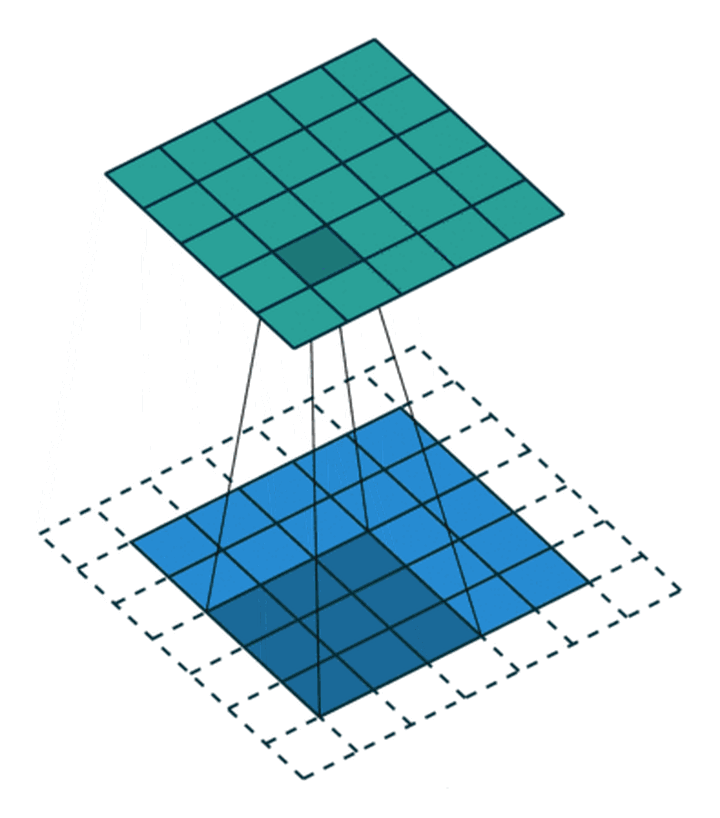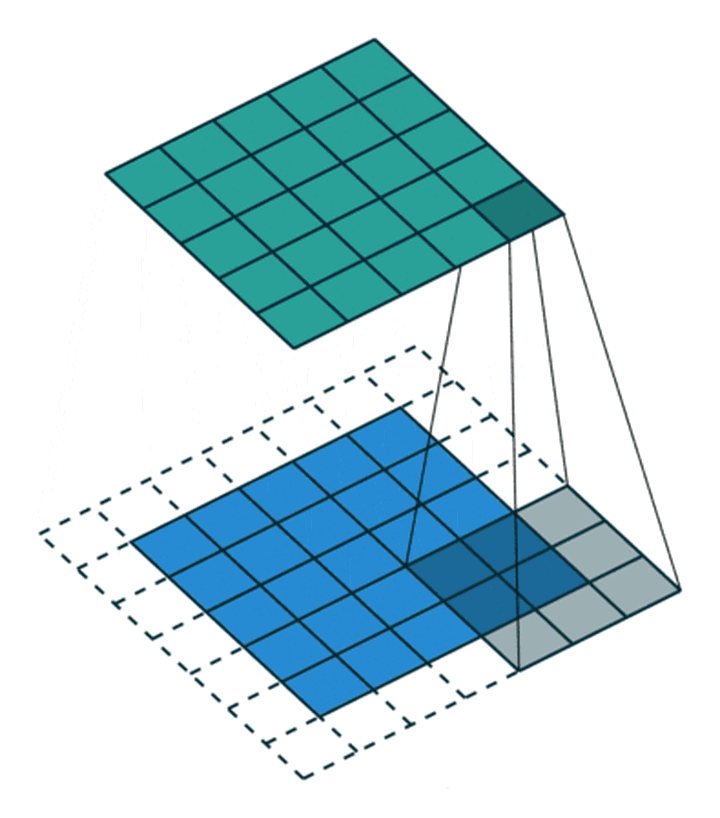
In convolution process , Sometimes need to pass padding To avoid information loss , Sometimes it is also necessary to pass the setting during convolution step (Stride) To compress some information , Or make the output size smaller than the input size .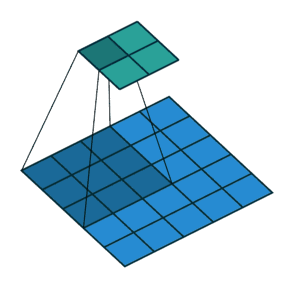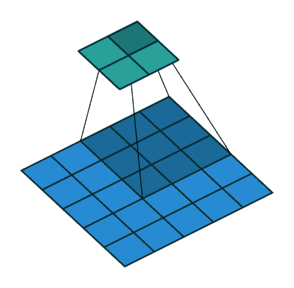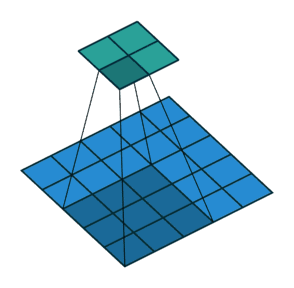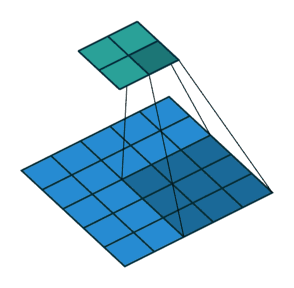
Stride The role of : Is to double the size , The value of this parameter is the specific multiple of reduction , For example, the stride is 2, The output is the input 1/2; The stride is 3, The output is the input 1/3. And so on . See the picture below .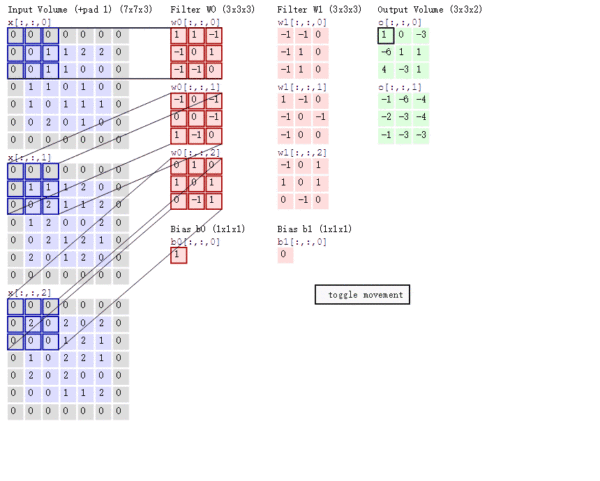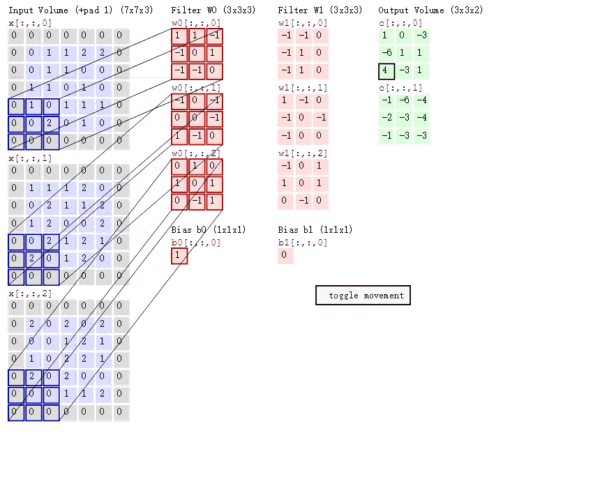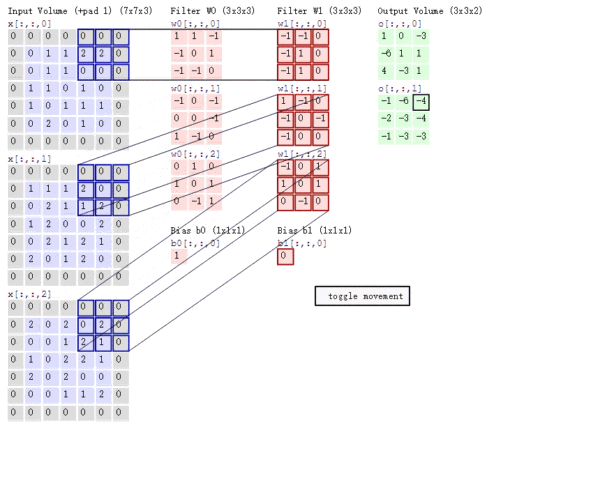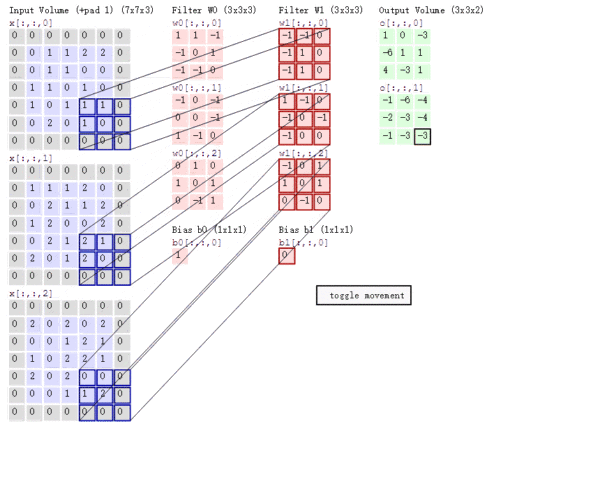
- 【 The size of convolution kernel is generally odd * Odd number 】 1*1,3*3,5*5,7*7 Are the most common . Why is that ? Why is there no even number * even numbers ?
(1) More easily padding
In convolution , We sometimes need the same size before and after convolution . We need to use padding. Suppose the size of the image , That is, the size of the convoluted object is n*n, The convolution kernel size is k*k,padding The amplitude of is set to (k-1)/2 when , The output after convolution is (n-k+2*((k-1)/2))/1+1=n, That is, the convolution output is n*n, It ensures that the size before and after convolution remains unchanged . But if k If it's even ,(k-1)/2 It's not an integer .(2) Easier to find convolution anchors
stay CNN in , When performing convolution operation, it will generally slide based on a position of the convolution kernel module , This benchmark is usually the center of the convolution kernel module . If convolution kernel is odd , Convolution anchors are easy to find , Nature is the center of the convolution module , But if the convolution kernel is even , There's no way to be sure , It doesn't seem very good to let who is the anchor . 【 Calculation formula of convolution 】
Enter the size of the picture : It's usually used
 For input image size .
For input image size . The size of the convolution kernel : It's usually used
 Represents the size of the convolution kernel .
Represents the size of the convolution kernel . fill (Padding): It's usually used
 To represent the fill size .
To represent the fill size . step (Stride): It's usually used
 To represent the step size .
To represent the step size . The size of the output picture : It's usually used
 To express .
To express .
If known 、
、  、
、  、 Can be found
、 Can be found  , The calculation formula is as follows :
, The calculation formula is as follows :
among "
 " Is the rounding down symbol , Used to round down when the result is not an integer .
" Is the rounding down symbol , Used to round down when the result is not an integer . 【 Multichannel convolution 】
The above examples contain only one input channel . actually , Most input images have RGB 3 Channels .
This is about “ Convolution kernel ” and “filter” The difference between the two terms . In the case of only one channel ,“ Convolution kernel ” Equivalent to “filter”, The two concepts are interchangeable . But in general , They are two completely different concepts . Every “filter” Actually, it happens to be “ Convolution kernel ” A collection of , In the current layer , Each channel corresponds to a convolution kernel , And this convolution kernel is unique .
The calculation process of multi-channel convolution : Convolute the matrix with each channel corresponding to the filter , Final addition , Form a single channel output , Add the offset term , We get a final single channel output . If there are multiple filter, At this time, we can combine these final single channel outputs into a total output .
We still need Be careful Some of the problems —— The number of channels of the filter 、 The number of channels to output the characteristic graph .
The number of channels of a filter = The number of channels of the characteristic graph of the upper layer . As shown in the figure above , We enter a
 Of RGB picture , So filter (
Of RGB picture , So filter (  ) There should also be three channels .
) There should also be three channels . The number of channels of the output characteristic graph of a certain layer = The number of filters in the current layer . As shown in the figure above , When there is only one filter when , Output characteristic map (
 ) The number of channels is 1; When there is 2 individual filter when , Output characteristic map (
) The number of channels is 1; When there is 2 individual filter when , Output characteristic map (  ) The number of channels is 2.
) The number of channels is 2.Classification data set : fenleiCIFAR-10 Data set description 、 Description link 2
CIFAR-10 By Hinton Of the students Alex Krizhevsky and Ilya Sutskever A small data set for identifying universal objects . It includes 10 Category RGB Color picture slice : The plane ( a Kowtow lane )、 automobile ( automobile )、 birds ( bird )、 cat ( cat )、 deer ( deer )、 Dog ( dog )、 Frogs ( frog )、 Horse ( horse )、 ship ( ship ) And trucks ( truck ). The size of the picture is 32×32 , There are... In the data set 50000 Zhang training prison film and 10000 Test pictures . CIFAR-10 The image sample of is shown in the figure .
Deep neural network (Deep Neural Networks,DNN), Reference article : Deep neural network (DNN)
although DNN It looks complicated , But for small local models , It's still the same as the perceptron , It's a linear relationship Add an activation function
Add an activation function 
CNN Introduction to the Internet , Refer to a good article 《CNN Introduction to the Internet 》
CNN( Convolutional neural networks ) introduction , Reference article 《CNN( Convolutional neural networks ) introduction 》
《 The function of full connection layer 》
What is the use of the full connection layer ? Let me talk about three points .
1、 Fully connected layer (fully connected layers,FC) In the whole convolution neural network “ classifier ” The role of . If we talk about convolution 、 Pooling layer And activate the function layer to map the original data to the hidden layer feature space , The whole connection layer plays the role of What will be learned “ Distributed feature representation ” The role of mapping to the sample marker space . In practical use , The full connection layer can be realized by convolution operation : If the front layer is fully connected, the fully connected layer can be transformed into convolution kernel 1x1 Convolution of ; The front layer is the full connection layer of the convolution layer, which can be transformed into convolution kernel hxw Global convolution of ,h and w They are the height and width of the convolution result of the previous layer ( notes 1).
2、 At present, due to the parameter redundancy of the whole connection layer ( Only the full connection layer parameters can account for the whole network parameters 80% about ), Recently, some network models with excellent performance, such as ResNet and GoogLeNet All of them are pooled by global average (global average pooling,GAP) replace FC To integrate the depth features learned , Finally still use softmax etc. Loss function As a network objective function to guide the learning process . It's important to point out that , use GAP replace FC The network usually has better prediction performance .
3、 stay FC At a time when people are less and less optimistic , Our recent research (In Defense of Fully Connected Layers in Visual Representation Transfer) Find out ,FC It can be used in the process of model representation capability migration “ A firewall ” The role of . In particular , Suppose that ImageNet The model obtained from the previous pre training is , be ImageNet Can be regarded as the source domain ( In transfer learning source domain). fine-tuning (fine tuning) It is the most commonly used transfer learning technology in the field of deep learning . For fine tuning , If the target domain (target domain) The image in is very different from the image in the source domain ( As compared ImageNet, The target domain image is not an object centered image , But the scenery , See the picture below ), Not included FC The result of network fine-tuning is worse than that of including FC Network of . therefore FC Can be regarded as a model to represent the ability of “ A firewall ”, Especially when the source domain is quite different from the target domain ,FC Large models can be maintained capacity So as to ensure the transfer of model representation ability .( Redundant parameters are not useless .)
, be ImageNet Can be regarded as the source domain ( In transfer learning source domain). fine-tuning (fine tuning) It is the most commonly used transfer learning technology in the field of deep learning . For fine tuning , If the target domain (target domain) The image in is very different from the image in the source domain ( As compared ImageNet, The target domain image is not an object centered image , But the scenery , See the picture below ), Not included FC The result of network fine-tuning is worse than that of including FC Network of . therefore FC Can be regarded as a model to represent the ability of “ A firewall ”, Especially when the source domain is quite different from the target domain ,FC Large models can be maintained capacity So as to ensure the transfer of model representation ability .( Redundant parameters are not useless .)




 , be ImageNet Can be regarded as the source domain ( In transfer learning
, be ImageNet Can be regarded as the source domain ( In transfer learning
边栏推荐
- According to the use and configuration of data permissions in the open source framework
- ML-Numpy
- Perform Jieba word segmentation on the required content and output EXCEL documents according to word frequency
- ECMA 262 12 Lexical Grammer
- Ffmpeg plays audio and video, time_ Base solves the problem of audio synchronization and SDL renders the picture
- [training Day12] min ratio [DFS] [minimum spanning tree]
- 【集训DAY15】Boring【树形DP】
- LabVIEW 开发 PCI-1680U双端口CAN卡
- Array中可以用泛型吗
- Solve several common problems
猜你喜欢

Interpretation of the source code of all logging systems in XXL job (line by line source code interpretation)

JSON object

自媒体人必备的4个资源工具,每一个都很实用

分享两个音乐播放地址
Share two music playing addresses

【集训DAY15】油漆道路【最小生成树】

Dom and events

Xiaobai programmer the next day
![[training day15] simple calculation [tree array] [mathematics]](/img/20/a5604f666ab02f47929f80c5597f0a.png)
[training day15] simple calculation [tree array] [mathematics]

Matrix of C language
随机推荐
[training Day11] Calc [mathematics]
SMART S7-200 PLC通道自由映射功能块(DO_Map)
[training day13] out race [mathematics] [dynamic planning]
The price of dividing gold bars
数据平台下的数据治理
Data type conversion
[training Day12] tree! Tree! Tree! [greed] [minimum spanning tree]
Domain oriented model programming
沃达德软件:智慧城市方案
Von Neumann architecture
关于getchar和scanf的使用示例及注意点
[training day15] good name [hash]
依法严厉打击违规自媒体运营者:净化自媒体行业迫在眉睫
Simple application of partial labels and selectors
Matrix of C language
【集训DAY11】Nescafe【贪心】
ECMA 262 12 Lexical Grammer
Compile and decompile
Using simple scripts to process data in 3dslicer
字符型常量和字符串常量的区别?