当前位置:网站首页>Emotion analysis based on IMDB comment data set
Emotion analysis based on IMDB comment data set
2022-07-01 11:39:00 【Xi Anxian】
List of articles
Preface
The main content of this paper is based on IMDB Emotional analysis of comment data sets , This article includes an introduction to the large-scale film review data set 、 Environment configuration 、 Experimental code 、 Running results and problems encountered , This experiment uses multilayer perceptron (MLP)、 Recursive neural network (RNN) And long-term and long-term memory (LSTM) The equal depth learning models were tested , Among them, the short-term and long-term memory model has the best effect , The test accuracy has reached 86.4%.
One 、 Introduction to large film review data sets
Big movie review data set (Large Movie Review Dataset): Click here to jump to download
This data set is a data set for binary emotion classification , Including positive and negative comments , It contains a lot more data than the previous benchmark dataset , Among them is 25000 Highly polar film reviews for training ,25000 Bar is used to test , There are also some unmarked data available .
The files contained in the downloaded dataset after decompression are shown in the following figure .
test The file information contained in the folder is as follows , among neg The folder contains 12500 Negative comments ,pos The folder contains 12500 A positive comment .
train The file information contained in the folder is as follows , among neg The folder contains 12500 Negative comments ,pos The folder contains 12500 A positive comment ,unsup The folder contains 50000 Unmarked comments are available .
Two 、 Environment configuration
This experiment is based on the previous experiment : be based on PyTorch Of cifar-10 Image classification Install based on the environment configuration tensorflow and keras that will do , I have installed tensorflow The version is 2.1.0,keras The version is 2.3.1, Install the version that suits your environment .
Tensorflow Is a data flow based programming (dataflow programming) Symbolic mathematics system of , It is widely used in the programming of various machine learning algorithms .Tensorflow It has a multi-level structure , It can be deployed on all kinds of servers 、PC Terminal and web page support GPU and TPU High performance numerical calculation .
Keras It's a by Python An open source artificial neural network library , It can be used as Tensorflow、Microsoft-CNTK and Theano High level application program interface of , Design of deep learning model 、 debugging 、 assessment 、 Application and visualization .Keras The code structure is written by object-oriented method , Fully modular and scalable , It attempts to simplify the implementation difficulty of complex algorithms .Keras Support the mainstream algorithms in the field of modern artificial intelligence , Neural networks including feedforward structure and recursive structure , You can also participate in the construction of statistical learning models through encapsulation . In terms of hardware and development environment ,Keras Support multiple operating systems GPU Parallel computing , Can be converted to... According to background settings Tensorflow、Microsoft-CNTK And other components under the system .
3、 ... and 、 Experimental code
This experiment uses multilayer perceptron (MLP)、 Recursive neural network (RNN) And long-term and long-term memory (LSTM) Equal depth learning model , The code is as follows .
1. Multilayer perceptron model code
The code based on the multilayer perceptron model is as follows .
# Statement : This code is not written by myself , The code source has been linked at the end of the article
import urllib.request # Download the file
import os
import tarfile # Unzip the file
import re
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.text import Tokenizer # Build a dictionary
from keras.preprocessing import sequence # cut off from the long to support the deficiency of the short
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.embeddings import Embedding
# Download the movie review data set
url = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
filepath = r"G:\PycharmProjects\aclImdb_v1.tar.gz" # The location of the data set compressed package path here varies from person to person
if not os.path.isfile(filepath): # Download if there is no file in this path
result = urllib.request.urlretrieve(url, filepath)
print('downloaded:', result)
if not os.path.exists(r"G:\PycharmProjects\aclImdb"):
tfile = tarfile.open(filepath, 'r:gz') # Extract the dataset file
result = tfile.extractall(r"G:/PycharmProjects/")
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>') # Remove html label
return re_tag.sub('', text)
def read_file(filetype): # Read the file
path = "G:/PycharmProjects/aclImdb/"
file_list = []
positive_path = path + filetype + '/pos/' # File path for positive comments
for f in os.listdir(positive_path):
file_list += [positive_path + f] # Stored in the file list
negative_path = path + filetype + '/neg/' # File path of negative comments
for f in os.listdir(negative_path):
file_list += [negative_path + f]
print('read', filetype, 'files:', len(file_list)) # Number of printed files
all_labels = ([1] * 12500 + [0] * 12500) # front 12500 It's all positive 1; after 12500 Both negative 0
all_texts = []
for fi in file_list: # Read all files
with open(fi, encoding='utf8') as file_input:
# Read the file first , Use join Connect all strings , And then use rm_tags To eliminate tag Finally, save it into the list all_texts
all_texts += [rm_tags(" ".join(file_input.readlines()))]
return all_labels, all_texts
y_train, train_text = read_file("train")
y_test, train_test = read_file("test")
y_train = np.array(y_train)
y_test = np.array(y_test)
test_text = train_test
# establish token
token = Tokenizer(num_words=2000) # The number of words in the dictionary is 2000
# establish token The dictionary
token.fit_on_texts(train_text) # Sort by word occurrence Take before 2000 individual
# Convert movie review text into a digital list ( A film review text is converted into a numerical list )
x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text)
# Operation of cutting short
x_train = sequence.pad_sequences(x_train_seq, maxlen=100)
x_test = sequence.pad_sequences(x_test_seq, maxlen=100)
# mlp perceptron
model = Sequential()
model.add(Embedding(output_dim=32, input_dim=2000, input_length=100))
# A word is used 32 Dimension word vector represents ; The number of words in the dictionary ( dimension ) by 2000; Each number list has 100 A digital , Equivalent to using 100 A number to represent a comment
model.add(Dropout(0.2))
model.add(Flatten()) # Enter “ Flatten ”, That is, the multidimensional input is unidimensional share 32*100=3200 individual
model.add(Dense(units=256, activation='relu')) # The number of neuron nodes is 256, The activation function is relu
model.add(Dropout(0.35))
model.add(Dense(units=1, activation='sigmoid')) # Output 1 Indicates a positive evaluation of ,0 A negative comment , The activation function is sigmoid
model.summary() # Model summary
# To configure
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Define the loss function 、 Optimizer and evaluation
# Training
train_history=model.fit(x=x_train, y=y_train, validation_split=0.2, epochs=10, batch_size=300, verbose=1)
# Training 10 individual epoch, Each batch of training 300 Data
# Show training results
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(train_history, 'accuracy', 'val_accuracy') # Accuracy line chart
show_train_history(train_history, 'loss', 'val_loss') # Loss function line chart
scores = model.evaluate(x_test, y_test) # assessment
print(scores)
print('Test loss: ', scores[0])
print('Test accuracy: ', scores[1])
2. Recursive neural network model code
The code based on recurrent neural network model is as follows .
# Statement : This code is not written by myself , The code source has been linked at the end of the article
import urllib.request # Download the file
import os
import tarfile # Unzip the file
import re
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.text import Tokenizer # Build a dictionary
from keras.preprocessing import sequence # cut off from the long to support the deficiency of the short
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import SimpleRNN # RNN
# Download the movie review data set
url = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
filepath = r"G:\PycharmProjects\aclImdb_v1.tar.gz"
if not os.path.isfile(filepath): # Download if there is no file in this path
result = urllib.request.urlretrieve(url, filepath)
print('downloaded:', result)
if not os.path.exists(r"G:\PycharmProjects\aclImdb"):
tfile = tarfile.open(filepath, 'r:gz') # Extract the dataset file
result = tfile.extractall(r"G:/PycharmProjects/")
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>') # Remove html label
return re_tag.sub('', text)
def read_file(filetype): # Read the file
path = "G:/PycharmProjects/aclImdb/"
file_list = []
positive_path = path + filetype + '/pos/' # File path for positive comments
for f in os.listdir(positive_path):
file_list += [positive_path + f] # Stored in the file list
negative_path = path + filetype + '/neg/' # File path of negative comments
for f in os.listdir(negative_path):
file_list += [negative_path + f]
print('read', filetype, 'files:', len(file_list)) # Number of printed files
all_labels = ([1] * 12500 + [0] * 12500) # front 12500 It's all positive 1; after 12500 Both negative 0
all_texts = []
for fi in file_list: # Read all files
with open(fi, encoding='utf8') as file_input:
# Read the file first , Use join Connect all strings , And then use rm_tags To eliminate tag Finally, save it into the list all_texts
all_texts += [rm_tags(" ".join(file_input.readlines()))]
return all_labels, all_texts
y_train, train_text = read_file("train")
y_test, train_test = read_file("test")
y_train = np.array(y_train)
y_test = np.array(y_test)
test_text = train_test
# establish token
token = Tokenizer(num_words=2000) # The number of words in the dictionary is 2000
# establish token The dictionary
token.fit_on_texts(train_text) # Sort by word occurrence Take before 2000 individual
# Convert movie review text into a digital list ( A film review text is converted into a numerical list )
x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text)
# Operation of cutting short
x_train = sequence.pad_sequences(x_train_seq, maxlen=380)
x_test = sequence.pad_sequences(x_test_seq, maxlen=380)
# RNN Model
model = Sequential()
model.add(Embedding(output_dim=32, input_dim=3800, input_length=380))
# A word is used 32 Dimension word vector represents ; The number of words in the dictionary ( dimension ) by 3800; Each number list has 100 A digital , Equivalent to using 100 A number to represent a comment
model.add(Dropout(0.35))
model.add(SimpleRNN(16)) # RNN
model.add(Dense(units=256, activation='relu')) # The number of neuron nodes is 256, The activation function is relu
model.add(Dropout(0.35))
model.add(Dense(units=1, activation='sigmoid')) # Output 1 Indicates a positive evaluation of ,0 A negative comment , The activation function is sigmoid
model.summary() # Model summary
# To configure
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Define the loss function 、 Optimizer and evaluation
# Training
train_history = model.fit(x=x_train, y=y_train, validation_split=0.2, epochs=10, batch_size=300, verbose=1)
# Training 10 individual epoch, Each batch of training 300 Data
# Show training results
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(train_history, 'accuracy', 'val_accuracy') # Accuracy line chart
show_train_history(train_history, 'loss', 'val_loss') # Loss function line chart
scores = model.evaluate(x_test, y_test) # assessment
print(scores)
print('Test loss: ', scores[0])
print('Test accuracy: ', scores[1])
3. Long and short term memory model code
The code based on the long-term and short-term memory model is as follows .
# Statement : This code is not written by myself , The code source has been linked at the end of the article
import urllib.request # Download the file
import os
import tarfile # Unzip the file
import re
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.text import Tokenizer # Build a dictionary
from keras.preprocessing import sequence # cut off from the long to support the deficiency of the short
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM # LSTM
# Download the movie review data set
url = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
filepath = r"G:\PycharmProjects\aclImdb_v1.tar.gz"
if not os.path.isfile(filepath): # Download if there is no file in this path
result = urllib.request.urlretrieve(url, filepath)
print('downloaded:', result)
if not os.path.exists(r"G:\PycharmProjects\aclImdb"):
tfile = tarfile.open(filepath, 'r:gz') # Extract the dataset file
result = tfile.extractall(r"G:/PycharmProjects/")
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>') # Remove html label
return re_tag.sub('', text)
def read_file(filetype): # Read the file
path = "G:/PycharmProjects/aclImdb/"
file_list = []
positive_path = path + filetype + '/pos/' # File path for positive comments
for f in os.listdir(positive_path):
file_list += [positive_path + f] # Stored in the file list
negative_path = path + filetype + '/neg/' # File path of negative comments
for f in os.listdir(negative_path):
file_list += [negative_path + f]
print('read', filetype, 'files:', len(file_list)) # Number of printed files
all_labels = ([1] * 12500 + [0] * 12500) # front 12500 It's all positive 1; after 12500 Both negative 0
all_texts = []
for fi in file_list: # Read all files
with open(fi, encoding='utf8') as file_input:
# Read the file first , Use join Connect all strings , And then use rm_tags To eliminate tag Finally, save it into the list all_texts
all_texts += [rm_tags(" ".join(file_input.readlines()))]
return all_labels, all_texts
y_train, train_text = read_file("train")
y_test, train_test = read_file("test")
y_train = np.array(y_train)
y_test = np.array(y_test)
test_text = train_test
# establish token
token = Tokenizer(num_words=2000) # The number of words in the dictionary is 2000
# establish token The dictionary
token.fit_on_texts(train_text) # Sort by word occurrence Take before 2000 individual
# Convert movie review text into a digital list ( A film review text is converted into a numerical list )
x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text)
# Operation of cutting short
x_train = sequence.pad_sequences(x_train_seq, maxlen=380)
x_test = sequence.pad_sequences(x_test_seq, maxlen=380)
# LSTM Model
model = Sequential()
model.add(Embedding(output_dim=32, input_dim=3800, input_length=380))
# A word is used 32 Dimension word vector represents ; The number of words in the dictionary ( dimension ) by 3800; Each number list has 100 A digital , Equivalent to using 100 A number to represent a comment
model.add(Dropout(0.2))
model.add(LSTM(32)) # LSTM
model.add(Dense(units=256, activation='relu')) # The number of neuron nodes is 256, The activation function is relu
model.add(Dropout(0.2))
model.add(Dense(units=1, activation='sigmoid')) # Output 1 Indicates a positive evaluation of ,0 A negative comment , The activation function is sigmoid
model.summary() # Model summary
# To configure
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Define the loss function 、 Optimizer and evaluation
# Training
train_history = model.fit(x=x_train, y=y_train, validation_split=0.2, epochs=10, batch_size=300, verbose=1)
# Training 10 individual epoch, Each batch of training 300 Data
# Show training results
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(train_history, 'accuracy', 'val_accuracy') # Accuracy line chart
show_train_history(train_history, 'loss', 'val_loss') # Loss function line chart
scores = model.evaluate(x_test, y_test) # assessment
print(scores)
print('Test loss: ', scores[0])
print('Test accuracy: ', scores[1])
Four 、 experimental result
1. The running result of multilayer perceptron model
The parameter training of multilayer perceptron model is shown in the following figure .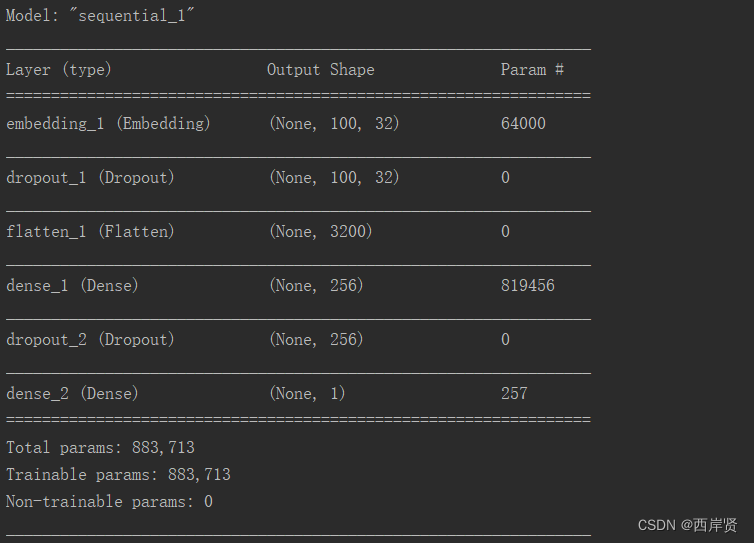
The broken line graph of the accuracy of the multilayer perceptron model changing with the learning cycle .
The broken line graph of the loss function value of the multilayer perceptron model changing with the learning cycle .
The final test loss function value and test accuracy of the multilayer perceptron model .
2. Running results of recurrent neural network model
The parameter training of recurrent neural network model is shown in the figure below .
The line graph of the accuracy of recurrent neural network model changing with the learning cycle .
The line graph of the loss function value of recurrent neural network model changing with the learning cycle .
The final test loss function value and test accuracy of recurrent neural network model .
3. Results of long-term and short-term memory model
The parameter training of long-term and short-term memory model is shown in the figure below .
The broken line graph of the accuracy of the long-term and short-term memory model changing with the learning cycle .
The broken line graph of the loss function value of the long-term and short-term memory model changing with the learning cycle .
The final test loss function value and test accuracy of the long-term and short-term memory model .
Through the experimental results of these models , The test accuracy of multilayer perceptron model is 82.01%, The test accuracy of recurrent neural network model is 82.79%, The test accuracy of the long-term and short-term memory model is 86.39%, The test accuracy of the long-term and short-term memory model is the highest among the three models .
5、 ... and 、 Problems encountered
Install... In the environment tensorflow when , It's not good to install directly with the following command ,Solving environment Keep turning , There will be no done.
conda install tensorflow
So I first use the following command to check all tensorflow edition .
anaconda show anaconda/tensorflow
The output result is shown in the figure below .
Then choose to be with yourself python Version compatible tensorflow Version to install , The order is as follows .
conda install --channel https://conda.anaconda.org/anaconda tensorflow=2.1.0
The second error is an error after running the program :Warning! HDF5 library version mismatched error
resolvent : Use the following two commands successively , To uninstall first h5py, Then install environment compatible h5py edition .
pip uninstall h5py
pip install h5py
summary
The above is based on IMDB Review all the content of emotional analysis in the data set , Finding the right open source code and configuring the right environment is the key to successfully running the code on your computer , I hope this article is helpful to your study !
Refer to the website :
TensorFlow Baidu Encyclopedia
Keras Baidu Encyclopedia
IMDb Network movie data set processing and LSTM Sentiment analysis
Reference code : Click here to jump
边栏推荐
- About keil compiler, "file has been changed outside the editor, reload?" Solutions for
- 2022/6/29学习总结
- JS日期格式化转换方法
- No statements may be issued when any streaming result sets are open and in use on a given connection
- How to set decimal places in CAD
- CANN算子:利用迭代器高效实现Tensor数据切割分块处理
- Force button homepage introduction animation
- Redis启动与库进入
- Extended tree (I) - concept and C implementation
- kafuka学习之路(一)kafuka安装和简单使用
猜你喜欢

Introduction to unittest framework and the first demo

ACLY与代谢性疾病

Redis configuration environment variables

华为HMS Core携手超图为三维GIS注入新动能
S7-1500PLC仿真

Neo4j 中文开发者月刊 - 202206期

Redis的攻击手法

2022/6/30学习总结

用实际例子详细探究OpenCV的轮廓检测函数findContours(),彻底搞清每个参数、每种模式的真正作用与含义

Y48. Chapter III kubernetes from introduction to mastery -- pod status and probe (21)
随机推荐
CANN算子:利用迭代器高效实现Tensor数据切割分块处理
Getting started with Paxos
Unittest 框架介绍及第一个demo
二叉堆(一) - 原理与C实现
想问问,证券开户有优惠吗手机开户是安全么?
名创拟7月13日上市:最高发行价22.1港元 单季净利下降19%
Acly and metabolic diseases
自定義 grpc 插件
用实际例子详细探究OpenCV的轮廓检测函数findContours(),彻底搞清每个参数、每种模式的真正作用与含义
Comment Nike a - t - il dominé la première place toute l'année? Voici les derniers résultats financiers.
Kernel synchronization mechanism
Neo4j 中文开发者月刊 - 202206期
TEMPEST HDMI泄漏接收 3
力扣首页简介动画
Value/list in redis
深入理解 grpc part1
Can servers bundled with flask be safely used in production- Is the server bundled with Flask safe to use in production?
openinstall:微信小程序跳转H5配置业务域名教程
redis中value/set
ACLY与代谢性疾病